


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

python实现简单的子域名扫描脚本
 木尤
木尤- 关注
python实现简单的子域名扫描脚本
声明:本脚本仅用于学习交流,请勿用于非法途径,造成的任何后果与本人无关
使用三方库:requests,threadpool,socket
测试目标:自己的博客网站
使用的字典自己去hub上面找找
程序原理:
函数将字典读入到lists里面,然后多线程取出每个域名前缀,用requests库请求,如果返回响应码为200则表示网站存在,当然,表示网站存在的响应码不止有200。
程序运行结果:
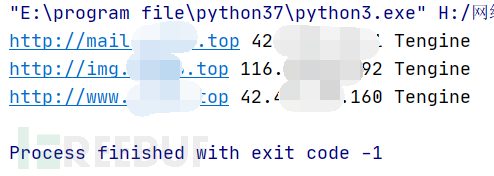
这里会把域名对应的ip和空间也同时输出,怎么实现呢,ip输出是利用socket.gethostbyname()这个函数将域名转成ip,输出域名的空间是通过调用返回头中的SERVER的值。
代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
'''
作者:木尤
声明:本脚本仅用于学习交流,请勿用于非法途径,造成的任何后果与本人无关
要点:需要安装requests,threadpool,socket这三个库
'''
import requests,threadpool,socket
url1="http://"
#url2是你需要爆破的主域名,前面必须加.
url2=".域名"
ff=open("./success.txt.txt",'w+')
lists=[]
##下面的gc.txt是你的子域名的字典,将字典的内容加载到lists
def zd():
f=open("./sub_full.txt",'r')
for d in f:
dir=d.strip()
lists.append(dir)
#调用字典的域名访问,看是否为200
def bp(str):
try:
res=requests.get(url1+str+url2,timeout=3)
if res.status_code==200:
ff.write(url1+str+url2+'\n')
print(url1+str+url2,socket.gethostbyname(str+url2),res.headers['Server'])
except:
pass
zd()
#这个是线程数,一次调用字典的50个执行
pool=threadpool.ThreadPool(50)
reqs=threadpool.makeRequests(bp,lists)
[pool.putRequest(req) for req in reqs]
pool.wait()
免责声明
1.一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
本文为 木尤 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
 python
python
相关推荐





木尤 LV.1
这家伙太懒了,还未填写个人描述!
- 4 文章数
- 7 关注者
python实现简单的端口扫描器
2021-01-04
python实现简单的目录扫描工具
2021-01-04
ASPCMS2.0漏洞利用带exp
2020-12-15