


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
0x00 前言
渗透测试的第一步是信息收集。我们常常使用dirsearch等工具对网站进行扫描,探测是否存在敏感路径或者隐藏路径。在一些情况下,网站发布者将网站的源码压缩包放在网站的路径下面。此时我们输入正确的文件名称就能将其下载下来。
网站源码压缩包可能是常见的www、test、wwwroot,也有可能是存在一定规律的名称,比如按照公司的域名起名字。因此,本文会写一个根据域名猜测源码名称的python脚本。如果师傅们有更好的办法欢迎指导。
0x01 分析
以www.baidu.com为例,其压缩包的可能名称是www、baidu、com、baidu.com、com.baidu、baiducom、combaidu。压缩包的后缀一般是常见的zip、gz、tar.gz、rar、
0x02 脚本编写
import itertools
# 常用压缩文件后缀
yasuo = [".zip", ".rar", ".tar.gz", ".gz"]def dkr_pinjie(qianzhui:list, houzhui:list):
result01 = []
for x in itertools.product(qianzhui, houzhui):
temp = ""
for i in x:
temp = temp + i
result01.append(temp)
return result01# 分析域名
def domain_analyse(domain_name:str ,deep:int):
"""
只对短域名
:param domain_name: 域名字符串,例如www.baidu.com
:param deep: 压缩包的前缀的长度 1,2,3
:return: 生成的域名列表
"""
qianzhui = []
lis1 = domain_name.split(".")
qianzhui.extend(lis1)
if deep == 1:
return dkr_pinjie(qianzhui, yasuo)# 笛卡尔乘积 n*n
for x in itertools.product(lis1, lis1):
if len(set(x)) == 1:
continue
# print(x)
temp = ""
temp01 = ""
for i in x:
temp = temp + i
temp01 = temp01 + "." + i
qianzhui.append(temp)
qianzhui.append(temp01[1:])
if deep == 2:
return dkr_pinjie(qianzhui, yasuo)# 笛卡尔乘积 n*n*n
if len(lis1) > 2:
for x in itertools.product(lis1, lis1, lis1):
if len(set(x)) < 3:
continue
# print(x)
temp = ""
temp01 = ""
for i in x:
temp = temp + i
temp01 = temp01 + "." + i
qianzhui.append(temp)
qianzhui.append(temp01[1:])
if deep == 3:
return dkr_pinjie(qianzhui, yasuo)
return 0def writeToTxt(filename, lis1:list):
if lis1[0][-1] != "\n":
for i in range(len(lis1)):
lis1[i] = "/" + lis1[i] + "\n"
with open(filename, 'a') as f:
f.writelines(lis1)if __name__ == '__main__':
domain_name = "www.baidu.com"
output = "test.txt"
result = domain_analyse(domain_name, 3)
writeToTxt(output, result)
以www.baidu.com为例,主要函数是domain_analyse,它有两个参数,第一个参数是域名,第二个参数是需要的长度,有1,2,3三种选择。

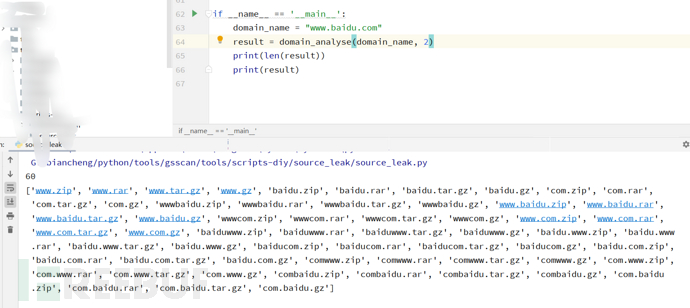
deep=3

通常设置为2即可。
输出的txt文件:
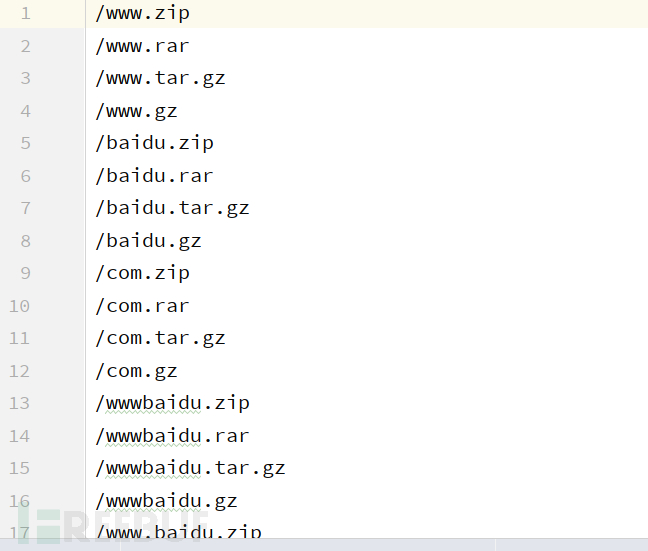
之后将导出的路径与常用的路径合并去重即可。
常用的压缩包名字典:https://github.com/saucer-man/penetration-script/blob/master/source_leak/dictionary.txt
合并的代码参考:
然后用dirsearch或者使用burpsuite跑均可。
扫描的脚本:https://github.com/saucer-man/penetration-script/blob/master/source_leak/source_leak_check.py
使用帮助
python3 source_leak_check.py -h
python3 source_leak_check.py --help
扫描单个url
python3 source_leak_check.py -u www.baidu.com
python3 source_leaf_check.py --url=www.baidu.com
批量扫描url文本:
python3 source_leak_check.py -l target.txt
python3 source_leak_check.py -list=target.txt
0x03 参考链接
https://github.com/saucer-man/penetration-script/tree/master/source_leak
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者