


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 Todreaming
Todreaming- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
一. 信息收集的两个维度
我们要想进行更加详细的信息收集首先要清楚,一个正常网站都是由哪些要素组成的(如图1),知道这些元素之后我们就可以更详细的进行信息收集。
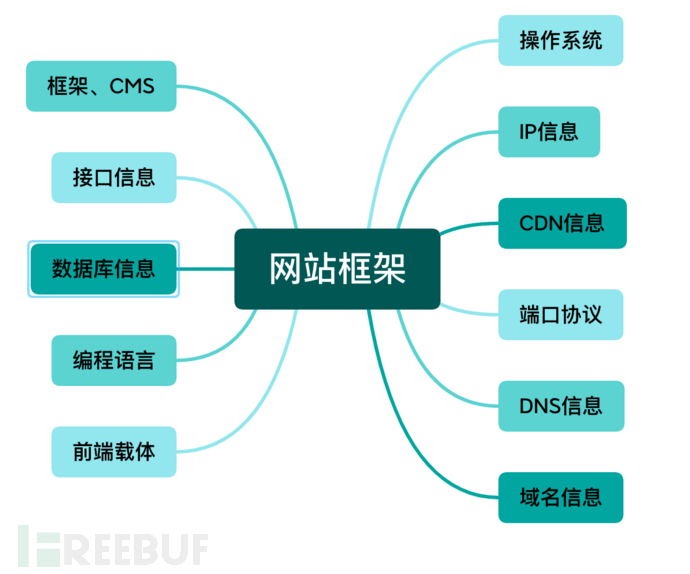
图1
上面的图1,只是对一个系统网站的信息收集,那么我们提高一个维度,我们企业有很多系统,我们如何更全面收集到这些系统呢(如图2)
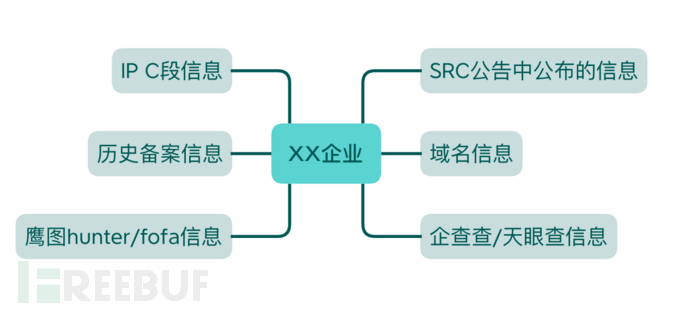
图2
二. 高纬度广域下的企业信息收集
1. SRC公告信息
测试范围信息

漏洞活动公告信息
龙湖src

爱奇艺src


2. 域名信息
这里的域名信息是在高纬度下的域名信息和子域名信息,在SRC漏洞挖掘过程中从旁站查找漏洞会容易一点,一般主站的防御会比较好。所以子域名信息收集很重要,接下来讲一下是如何快速大量的发现域名和子域名信息.
子域名指二级域名,二级域名是顶级域名(一级域名)的下一级。比如
mail.lenovvo.com和www.lenovvo.com是lenovvo.com的子域,而lenovvo.com则是顶级域名.com的子域。
2.1. 知识产权
在企查查(https://www.qcc.com/),天眼查(https://www.tianyancha.com/),小蓝本(https://sou.xiaolanben.com/pc)输入企业都可以查看知识产权信息,会有一些域名信息
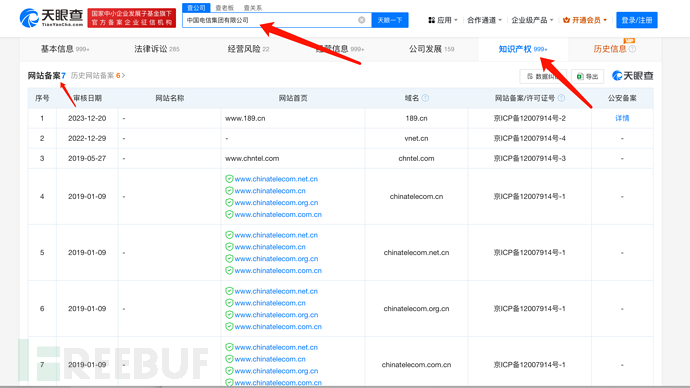
自动化工具部分将在 "3. 子分公司及股权分布" 模块详细列出
2.2. JS中进行域名搜集
推荐一个挺不错的工具,可以自动化的提取js中的敏感信息(例如vul框架的app.js)
https://github.com/Threezh1/JSFinder
#常用语法 直接将结果输出到控制台,查找api接口也非常好用
python JSFinder.py -u http://xxxxx/xxx.js -cli
#参数用法
usage: JSFinder.py [-h] [-u URL] [-c COOKIE] [-f FILE] [-ou OUTPUTURL]
[-os OUTPUTSUBDOMAIN] [-j] [-d]
optional arguments:
-h, --help show this help message and exit
-u URL, --url URL The website
-c COOKIE, --cookie COOKIE
The website cookie
-f FILE, --file FILE The file contains url or js
-ou OUTPUTURL, --outputurl OUTPUTURL
Output file name.
-os OUTPUTSUBDOMAIN, --outputsubdomain OUTPUTSUBDOMAIN
Output file name.
-j, --js Find in js file
-d, --deep Deep find
-cli 输出到命令行
Example: python JSFinder.py -u http://www.baidu.com2.3. SSL证书中进行域名搜集
SSL证书颁发机构在颁发证书时会将其域名和子域名公开,利用网上查询接口就可以查询
查询网站: crt.sh

也可以使用如下脚本呢进行查询:
python3 subdomain.py -D baidu.com
import requests
import concurrent.futures
import argparse
parser = argparse.ArgumentParser(description="利用透明SSL证书查询子域名,使用在线接口:https://crt.sh/?q=cdutetc.cn")
parser.add_argument('-D','--domain',required=True,help="输入域名,不带任何子域,如 baidu.com")
args = parser.parse_args()
def fetch_from_crtsh(domain):
try:
url = f"https://crt.sh/?q=%.{domain}&output=json"
response = requests.get(url)
if response.status_code == 200:
return set(cert['name_value'] for cert in response.json() if 'name_value' in cert)
except Exception as e:
print(f"Error fetching from crt.sh: {e}")
return set()
def fetch_from_certspotter(domain):
try:
url = f"https://api.certspotter.com/v1/issuances?domain={domain}&expand=dns_names"
response = requests.get(url)
if response.status_code == 200:
return set(name for cert in response.json() for name in cert['dns_names'])
except Exception as e:
print(f"Error fetching from CertSpotter: {e}")
return set()
def main(domain):
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [
executor.submit(fetch_from_crtsh, domain),
executor.submit(fetch_from_certspotter, domain)
]
results = set().union(*[future.result() for future in concurrent.futures.as_completed(futures)])
print(f"Found {len(results)} unique subdomains for {domain}:")
for subdomain in sorted(results):
print(subdomain)
if __name__ == "__main__":
print("正在查询{}相关域名".format(args.domain))
domain = args.domain
main(domain)
2.4. 子域名收集工具 OnForAll
OnForAll github下载地址
https://github.com/shmilylty/OneForAll
#常用参数(其他参数请查看github文档)
python3.8 oneforall.py --brute True --alive True --target baidu.com run
#常用爆破参数
python3.8 brute.py --target domain.com --word True --wordlist subnames.txt run
#使用自定义大字典(字典要绝对路径)
python3.8 brute.py --target domain.com --word True --wordlist xxx.txt run自用大字典下载地址:
https://wordlists-cdn.assetnote.io/data/manual/best-dns-wordlist.txt
优化了配置文件 config/setting.py:
https://github.com/aaqiqi1/onforall_config/blob/main/setting.py
配置config/api.py完成配置,可以搜索更多的子域名
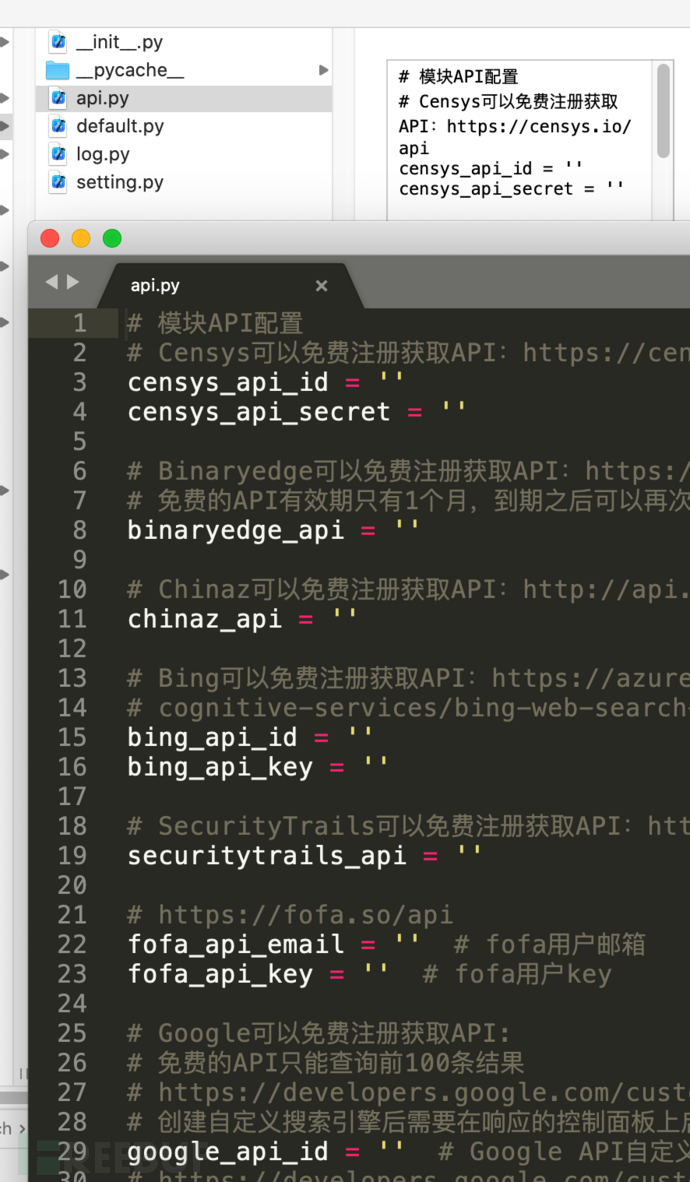
2.5. 灯塔ARL
ARL(Asset Reconnaissance Lighthouse)资产侦察灯塔系统,不仅仅是域名收集。
旨在快速侦察与目标关联的互联网资产,构建基础资产信息库。 协助甲方安全团队或者渗透测试人员有效侦察和检索资产,发现存在的薄弱点和攻击面。
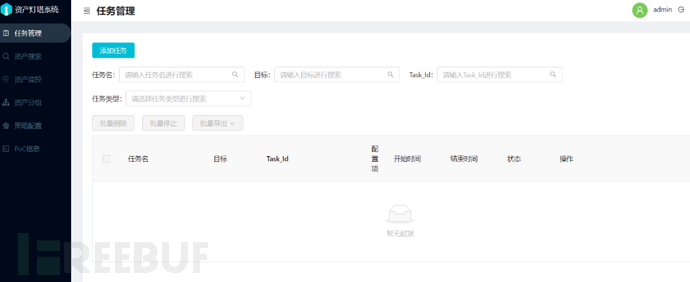
下载地址:
灯塔打包环境下载123网盘不限速下载:
https://www.123pan.com/s/qqJfTd-mhrh.html
提取码:dtos3. 子分公司及股权分布
企业信息查询网站
- 企查查 (www.qcc.com)
- 天眼查(www.tianyancha.com/)
- 启信宝(www.qixin.com/)
- 小蓝本(https://sou.xiaolanben.com/)
企查查、天眼查淘宝都有那种一天的会员。 对于我们信息收集其实已经够用,个人更喜欢用小蓝本,因为它能一键导出域名,还可以直接查看企业关联的子公司,比较方便。
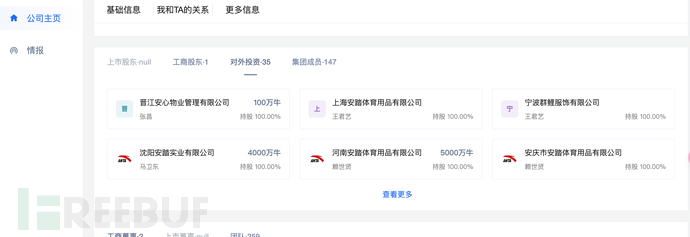
主要查询的信息:
- 一般大的src都有许多子公司,企查查可以在所属集团中查看该集团下子公司,并且可以导出。
- 查看同电话企业基本都是子公司。
- 查看股份穿透图,一般来说控股超过50%的子公司的漏洞SRC收录的可能性都比较大。
- 查看企业下的app、小程序、还有品牌的资产,直接在搜索引擎里搜索品牌可能会有意想不到的收获。(找到一些平常收集不到的资产)
PS:一般来说100%的全资子公司src漏洞是一定会收的,其他子公司资产可能需要与src审核沟通(扯皮)。
信息整理
当我们通过各种手段对挖掘的企业进行信息收集后,我们大致能得到以下有用的信息
- 主公司及分公司、子公司下所有归属的网站域名信息;
- 主公司及分公司、子公司下所有的专利品牌和开发的一些独立系统。
- 主公司及分公司、子公司下所有的app资产和微信小程序。
之后我们需要对这些信息进行归纳和整理,比如哪些是该公司的主资产,哪些是边缘资产,哪些资产看上去比较冷门,我们是可以重点关注和进行深入挖掘的。
自动化工具推荐
#使用技巧
#创建配置文件(添加cookie、token信息)
./enscan -v
#默认公司信息 (网站备案, 微博, 微信公众号, app)
./enscan -n 小米
#对外投资占股100%的公司 获取孙公司(深度2)
./enscan -n 小米 -invest 100 -deep 2
#组合筛选:大于51%控股公司、供应商、分支机构,只要ICP备案信息,并且批量获取邮箱信息
./enscan -n 小米 -field icp --hold --supplier --branch --email 
4. 网络空间测绘平台信息收集
网络空间测绘引擎
- Hunter (https://hunter.io)
- Censys (https://censys.io)
- ZoomEye (https://www.zoomeye.org)
- BinaryEdge (https://www.binaryedge.io)
- FOFA (https://fofa.so)
4.1. Hunter使用技巧
由于笔者Hunter使用的比较多,这里主要列出Hunter的使用技巧
使用语法:
web.title=“北京” 从网站标题中搜索“北京”
web.body=“网络空间测绘” 搜索网站正文包含”网络空间测绘“的资产
web.similar=“baidu.com:443” 查询与baidu.com:443网站的特征相似的资产
web.icon=“22eeab765346f14faf564a4709f98548” 查询网站icon(图标)与该icon相同的资产
web.tag=“登录页面” 查询包含资产标签"登录页面"的资产
domain=“qianxin.com” 搜索域名包含"qianxin.com"的网站
domain.suffix=“qianxin.com” 搜索主域为"qianxin.com"的网站
header.server==“Microsoft-IIS/10"搜索server全名为“Microsoft-IIS/10”的服务器
app.name=“小米 Router” 搜索标记为”小米 Router“的资产
app.vendor=“PHP” 查询包含组件厂商为"PHP"的资产
app.version=“1.8.1” 查询包含组件版本为"1.8.1"的资产子域名信息收集
domain_suffix=baidu.com #查找主域为baidu.com的资产。
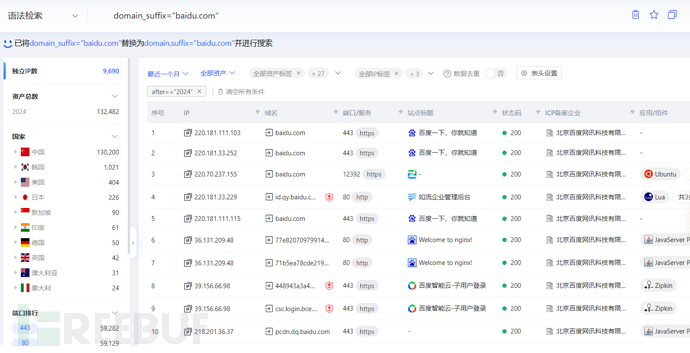
icon图标信息收集
畅读付费文章
 已在FreeBuf发表 3 篇文章
已在FreeBuf发表 3 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 利器
利器
 漏洞管理
漏洞管理





- 3 文章数
- 9 关注者