


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

信息收集之利用Python批量判断CDN
 海龙6666
海龙6666- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
信息收集之利用Python批量判断CDN
简介
在平时的安全测试中,信息收集是非常重要的一部分,信息收集之前少不了最重要的一步,就是判断网站是否使用了CDN。在测试过程中,如果目标使用了CDN 服务,将会影响到后续的安全测试过程。
方法
判断CDN的方法有很多种,在这里主要来讲解用nslookup判断并实现批量判断的目的。
使用nslookup,如果目标有CDN服务的话,那么将会返回多个IP地址(>=2个)。
nsllokup www.xxxx.com
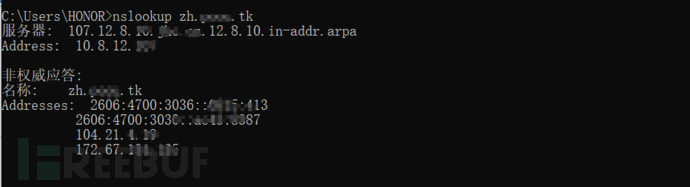
可以清楚的看到该域名返回了两个地址,可以判断该域名使用了CDN服务。
我们的目的就是用python来判断返回ip的条目,在该图中,如果ip条目>=3条,那么就存在CDN
代码实现
主要用到的库为os,re,主要方法为正则表达式。
这里我们首先看一下如何提取出来nslookup里面的ip地址
\d\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}这个表达式的意思是提取出以x.x.x.x形式的内容
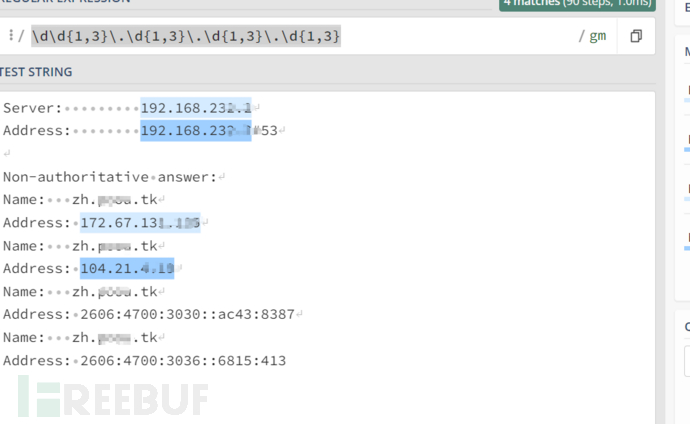
可以看到在有CDN的情况下ip条目为至少四条
再来看看没有CDN的情况
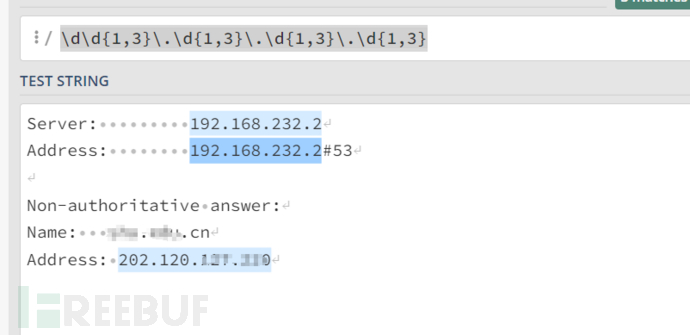
在没有CDN的情况下ip条目为三条
再来看一下不存在ip地址的情况
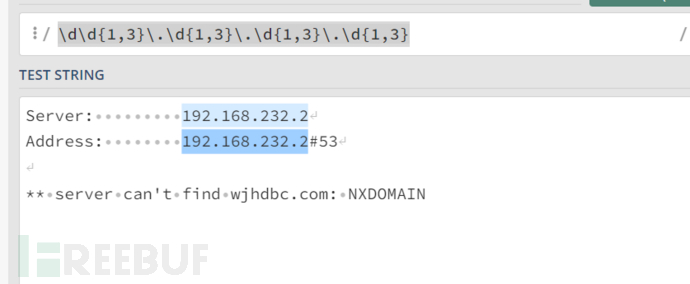
不存在时,ip条目为两条,综上所述,基本的代码原理也就出来了。
简易代码如下:(liunx上运行)
import os
import re
domain=open("./url.txt")
#判断CDN
for domains in domain:
domains = domains.strip("\n")
result=os.popen("nslookup " + domains).read()
results=re.findall(r'\d\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}',result,re.S)
if len(results)==2:
print(domains + " 没有ip地址")
if len(results)==3:
print(domains + " 不存在CDN")
print(results[-1])
if len(results)>3:
print(domains + " 存在CDN")代码实现的效果图

免责声明
1.一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
本文为 海龙6666 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
相关推荐





海龙6666 LV.2
这家伙太懒了,还未填写个人描述!
- 4 文章数
- 5 关注者
内网靶场—多层内网渗透
2023-01-30
ms17_010的几种打法
2022-11-19
shiro漏洞工具简单配置
2022-07-05
文章目录