


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 gingingg
gingingg- 关注
 本文由
gingingg 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
gingingg 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
一.爬虫拓展
1.BeautifulSoup
bs其实就是py中的一个库,但是其简单运用的方法,成为了爬虫的一大利器,只需要很简单的语句就可以从网页中爬取相应的信息,也不用考虑转码的问题,bs自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。
以下是简单的bs语句:
from bs4 import BeautifulSoup as e
import urllib.request
data=urllib.request.urlopen("目标网站").read().decode("utf-8",ignore)
bs1=bs(data)
#格式化输出
#print(bs1.preetify())
#获取标签:bs对象.标签名
bs.title
#获取标签中的文字:bs对象.标签名.string
bs1.title.string
#获取标签名:bs对象.标签名.name
bs1.title.name
#获取属性列表:bs对象.标签名.attrs
bs1.a.attrs
#获取某个属性对应的值:bs对象.标签名[属性名] 或 bs对象.标签名.get(属性名)
bs1.a["class"]
bs1.a.get("class")
#提取某个节点的内容:bs对象.find_all('标签名') bs对象.find_all(['标签名1','标签名2'......'标签n'])
bs1.find_all('a')
bs1.find_all(['a','ul'])
#提取所有字节点:bs对象.标签.contents bs对象.标签.children
k1=bs1.ul.contents
k2=bs1.ul.children
allulc=[i for i in k2]
当我们使用提取子节点的时候,有两种方法:利用contents直接输出,或者利用children建成对象输出。


对bs感兴趣的兄弟可以去官方文档查看:http://beautifulsoup.readthedocs.io/zh_CN/latest/
2.PhantomJS
PhantomJS俗称为无界面的浏览器,PhantomJS是一个基于webkit的JavaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。任何你可以在基于webkit浏览器做的事情,虽然PhantomJS搜索效率并不是很高,但是通过PhantomJS可以解决很多反爬问题,通常可以将难点交给PhantomJS去处理,之后将数据交给urllib或Scrapy进行后续处理。
例如有时我们进行爬虫会需要首先触发网页之后才能进行下一步的爬取,此时利用PhantomJS就可以很好的应对反爬,之后将返回的数据转交给爬虫模块进行处理即可。
首先访问phantomjs官网进行下载:
之后到bin目录就可以找到exe直接使用了;
利用pip 命令安装selenium模块;
利用代码(附注释):
import time
from selenium import webdriver
browser = webdriver.PhantomJS() #调用webdriver中的phantomjs来生成浏览器
browser.get("http://www.baidu.com") #模拟浏览器访问百度
a=browser.get_screenshot_as_file("图片目录") #将访问的浏览器界面截图爬取出来
browser.find_element_by_xpath('//*[@id="kw"]').clear() #利用xpath表达式找出搜索框并利用clear将其清空
browser.find_element_by_xpath('//*[@id="kw"]').send_keys("爬虫") #将所搜索的数据利用send_keys输入
browser.find_element_by_xpath('//*[@id=su]').click() #利用click点击搜索按钮
time.sleep(5) #等待时间5
a=browser.get_screenshot_as_file("图片目录") #将搜索结果界面截图保存可以查看是否成功
data=browser.page_source #将本界面内的源代码保存
browser.quit() #关闭浏览器
print(len(data)) #查看data(爬取网页源码的长度)验证是否爬取成功
import re
title=re.compile("<title>(.*?)</title>").findall(data) #提取data中title的数据
print(title)
注:get_screenshot_as_file是很常用的,来验证我们运行的操作是否成功,可以没进行一步操作添加一个截图来验证。
***clear,send_key(),click()***三个参数也是browser中很常用的,应该理解意思,常用就可以熟练了
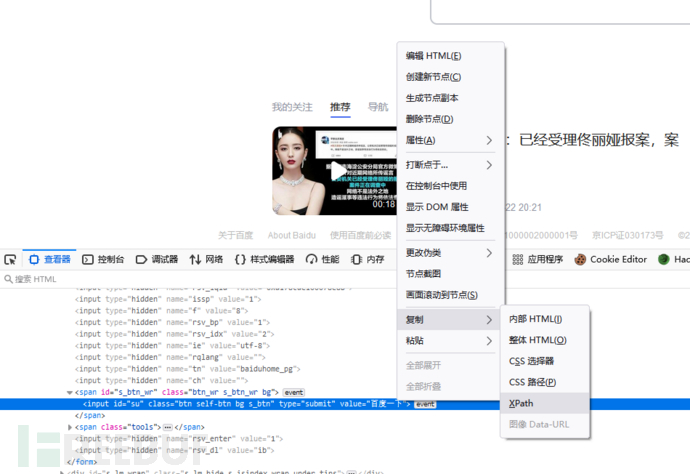
另外,在查看xpath语句的时候,也可以f12之后利用查看器选择对应的部位,右键copy就可以选择直接提取xpath语句了。
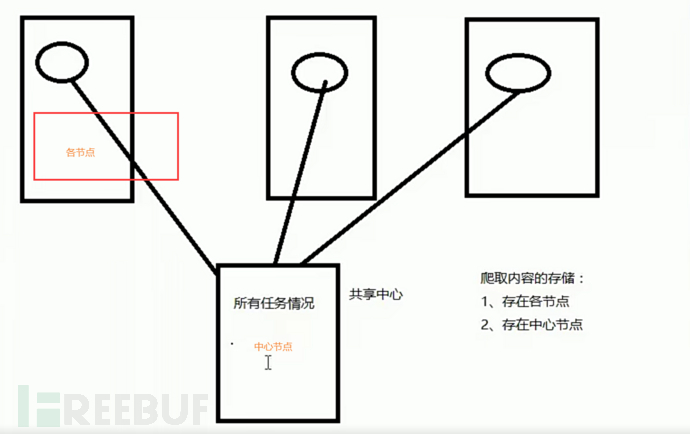
二.分布式爬虫讲解
利用多台机器同时进行实现爬虫任务,这么多个爬虫,整体称为分布式爬虫,可知,分布式爬虫时区别于单机爬虫的一种架构。
分布式爬虫难点在于多个爬虫之间的通信,其实应用的技术与之前学习的爬虫无区别,但是就是应用的环境不同,效率不同。
1.常见分布式爬虫架构技术
1.多台真实机器+爬虫(如Urllib,scrapy等)+任务共享中心
2.多台虚拟机器(或者部分虚拟部分真实)+爬虫(如Urllib,Scrapy等)+任务共享中心
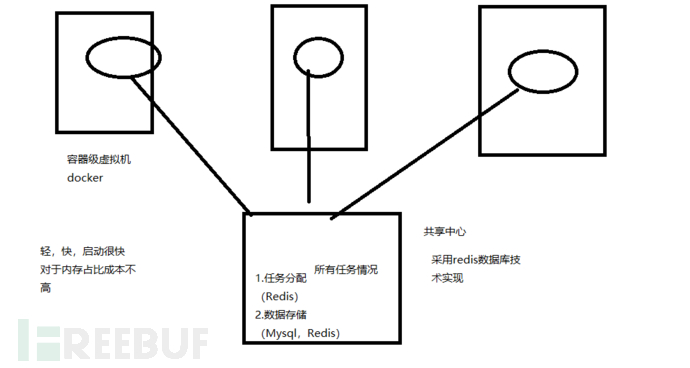
3.多台容器级虚拟化机器(或者部分真实机器)+爬虫(如Urllib,Scrapy等)+任务共享中心
常见任务共享中心可以采用redis技术进行实现;
存储数据时,也可以存储在节点中或者直接存储到中心机器的数据库中;
进行虚拟容器技术选择的时候也可以使用我们最熟悉的docker进行实现。
所以常见的实现技术手段有:
1.Docker+Redis+Urllib+(Mysql)
2.Docker+Redis+Scrapy-Redis+(Mysql)
容器技术+共享中心技术+爬虫框架+数据库技术
当我们利用多台机器进行爬虫的时候,任务共享中心会对于任务进行情况进行统计,执行一个任务的时候会查看其他任务执行情况与此任务执行效果。
使用多个机器进行分布式爬虫 :
使用虚拟容器进行分布式爬虫构建(对于内存占比相对于较低):
对于爬虫的学习就暂时告一段落了,本来想详细讲一下分布式爬虫的实现方法的,但是一想可能我们平时用不太上,毕竟不用爬虫去找工作,所以大型的爬虫项目也不会做,所以做一下原理性的讲解即可,兄弟们知道原理即实现方法就行了,多余不多做讲解,其他的文章我也放到了我的专辑中,兄弟们多多捧场。这个系列就到这里。感谢大家的支持。
已在FreeBuf发表 13 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 好玩的爬虫
好玩的爬虫





- 13 文章数
- 17 关注者