


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0x00 背景
以往在解MISC题时会遇到了编码或者是加密后的字符串,只能凭借个人对各种编码和密码学的熟悉程度去判断密文的类型,
以base16/32/64编码为例,区分这三种base系列的编码常常是与其密码(字母)表的范围去判断识别,base16是0-9a-f,base32是2-7A-Z,base64是A-Za-z0-9+/
若假设密文是 MZWGCZ33GEZDGNBVGZ6Q====,根据前面说的内容可以很轻松的得知这段密文是base32编码后的结果,解码可以得到明文为 flag{123456}
如果是在自身知识储备不足的情况下,没有系统地学习过各种编码解码和密码学的理论和知识,在遇到那些多重嵌套加密的密文就容易傻眼,到了关键部分不会分析密文,判断不了密文类型,也没办法解密得到flag。
那能不能根据前面说的,用判断字母表的方式去做个自动分析密文类型的工具呢?
于是,TomatoTools来了!
0x01 能做什么
TomatoTools 拥有CTF杂项中常见的编码密码算法的加密和解密方式,还具有自动提取flag的能力,以及异常灵活的插件模块。
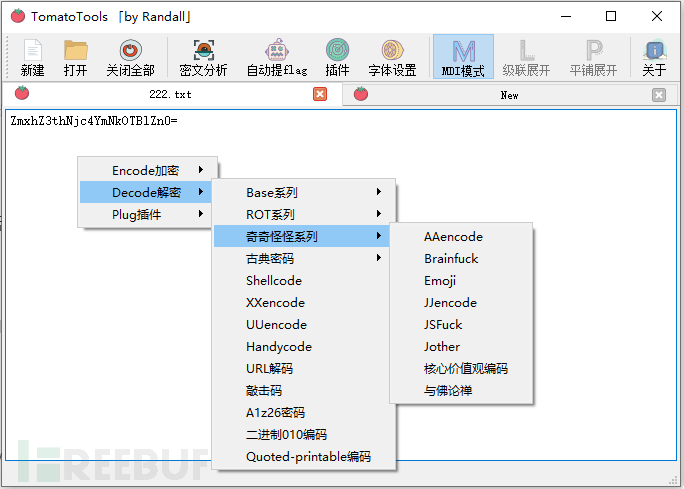
目前支持36种编码和密码算法的加密和解密,包括
Base16/32/36/58/62/64/85/91/92
ROT5/13/18/47
AAencode / XXencode / UUencode / JJencode
Brainfuck / JSFuck / Jother
Emoji
核心价值观编码 / 与佛论禅
莫斯密码 / 培根密码 / 云影密码 / 埃特巴什码 / 波利比奥斯方阵密码 / 凯撒密码 / 栅栏密码
Shellcode / Handycode / URL
敲击码 / A1z26密码 / Quoted-printable编码
二进制010编码
其中支持31种密文的分析
Base16/32/36/58/62/64/85/91/92
XXencode/UUencode/JJencode
Brainfuck/JSFuck/Jother
Emoji
核心价值观编码/与佛论禅(佛曰)/与佛论禅(如是我闻)
莫斯密码(空格)/莫斯密码(斜杠)/培根密码/云影密码/波利比奥斯方阵密码
Shellcode/Handycode/URL
敲击码/A1z26密码/Quoted-printable编码
二进制010编码
0x02 密文分析
密文分析过程可看下面的流程图
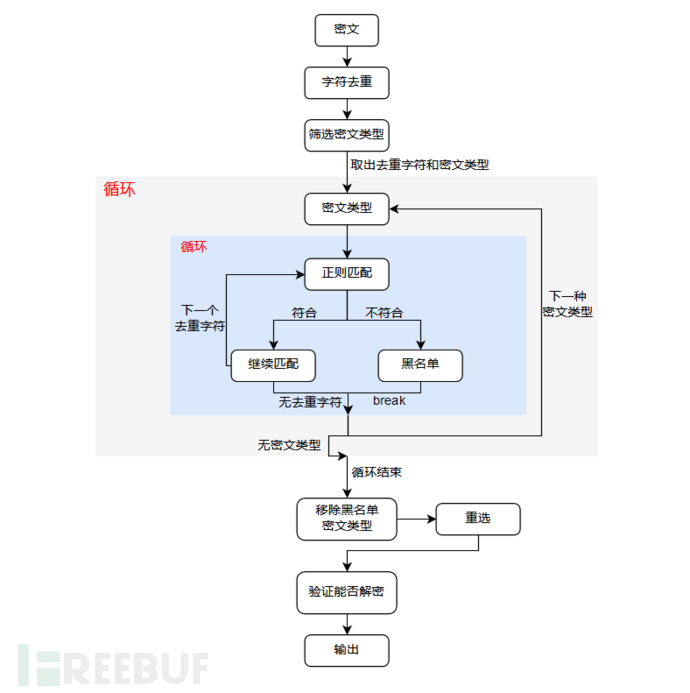
在密文分析时先从配置文件中加载各种密文类型的配置信息,包括函数名、密码表的正则范围,密码表的字符总个数等,然后进入密文类型筛选流程,判断该种密文类型的密码表的字符总个数和密文去重后的总个数之间谁更大些,若前者小于后者 的话,则将前者除去,其余的密文类型则进入下一轮的正则匹配阶段,
密文分析的核心是对经过某种加密/编码方式后密文的密码表进行正则匹配分析,对那些只针对密文中特定字符进行编码/加密的密文类型并没有很好的识别能力,以ROT5为例,ROT5的原理是明文中的数字向后移动5位,明文为 flag{a123bcd45ef},则ROT5编码过后的密文为 flag{a678bcd90ef},此时变化的只有数字,那么在密文分析中,ROT5的密码表正则范围该如何确定?
*[0-9]*肯定是不合适的,在正则匹配的第一个阶段,遇到 f后就将ROT5拉入黑名单了,那么只剩下一个办法了,使用 *[\w]*去匹配所有的字符,乍一看可行,也确实是能匹配到了,因为只要密文中存在数字,ROT5也就能被成功解密输出到密文分析的结果里,但ROT5也因此成了常客,而在后面的自动化提取flag中,由于密码表正则范围 *[\w]*过大,反复调用ROT5将会使其陷入一个永远也跳不出去的死循环。
0x03 自动提取flag
在解题时用TomatoTools去做密文分析,然后再加以手工解密的话,虽然和以往的人脑分析相比是快了一些,但是感觉还是不够快, 没有那种一秒出flag的惊喜与快感,既然已经有了密文分析和对应的解密算法,那么为什么不尝试做个“一键日(拿)卫星(flag)”呢?2333333
于是在密文分析的基础上追加了个“自动提flag”的功能,大致流程图如下
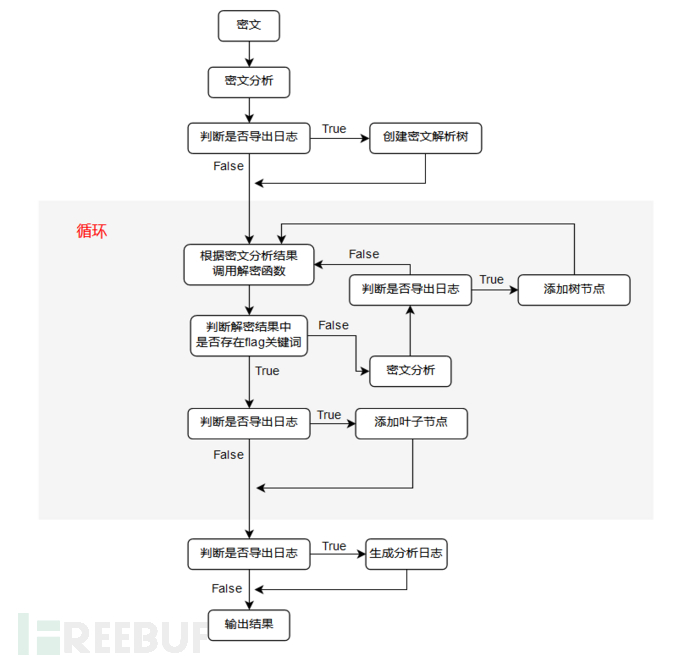
在自动提flag中增加“导出分析日志”是为了方便后期写WP,在无法解密的情况下,也可以根据日志来判断是哪一步出了问题,能给后面的手动分析带来一定的帮助,
以 *ZmxhZ3thNjc4YmNkOTBlZn0=*为例,这是一个经过base64编码后的密文,在这里使用自动提flag功能来尝试获得flag,
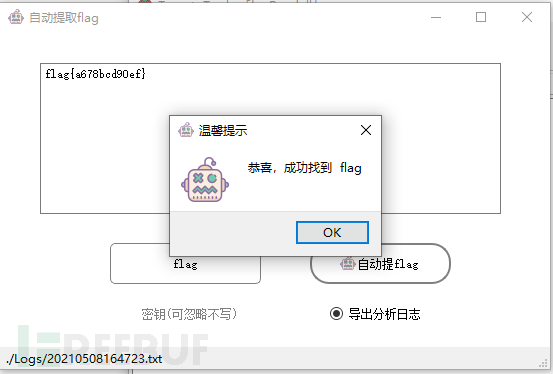
可见导出的日志如下
flag关键词:flag
密钥:
初始密文:ZmxhZ3thNjc4YmNkOTBlZn0=
解析树:
Path
└── Base64
└── flag{a678bcd90ef}
最长解密链:
Path -> Base64 -> flag{a678bcd90ef}
最终密文:
flag{a678bcd90ef}
最终解密结果:
flag{a678bcd90ef}
0x04 插件编写规范
插件的功能给TomatoTools带来了很强的灵活性,可以在插件管理页面去添加或删除自定义的插件,
这里有一点很重要,用户添加的解密插件是会同步到密文分析模块的,所以添加的解密插件在写法和定义上必须要严谨些,也要更慎重些,因为一旦添加了一个前面说的ROT5这样的插件,又或者是一个存在语法错误的插件,将有可能导致密文分析出错或者无法运行。

插件里的 dicts是要添加到 config.json中的,而下边定义的函数 abcdefg则是在加解密时调用的函数
编写插件必须遵守以下几点:
1.文件名、dicts里的 crypto_name和 定义的 函数名,三者必须一致
2.函数只能 return**bytes类型的结果
在自定义的插件函数里,如果需要传入密钥的话,插件函数需接收 cryptostr和 key两个值,否则只需接收 cryptostr一个值,而在函数返回值时,不能返回 str类型的值,需用 *str.encode()*变成 bytes类型后再return结果。
以下为 dicts内各个键的详解,
name # 添加的插件名称
crypto_name # 函数的名称
range # 密码表范围,必须用正则来表示,base16是[0-9a-f]
alphabet_num # 密码表的字符个数,base32[A-Z2-7=]是33个,rot5[0-9]是10个
key # (这里的key可以直接删掉,删掉后默认为False,也可以直接写 False)
# 针对某些需要输入密钥的才能解密的密文,比如rabbit,此时key的值需为 True
Demo1:
需要输入密钥 key的插件,
若用户不输入密钥,则调用该函数时,函数接收到的密钥 key为空字符串
# filename: abcdefg.py
dicts={
"name":"abcdefg加密",
"crypto_name":"abcdefg",
"range":"[1-8]",
"alphabet_num":"8",
"key":"True"
}
def abcdefg(cryptostr,key):
#key= ''
aa = "12345678"
return aa.encode()
Demo2:
不需要输入密钥 key的插件
# filename: test.py
dicts={
"name":"test解密",
"crypto_name":"test",
"range":"[1-8]",
"alphabet_num":"8",
"key":"False"
}
def test(cryptostr):
aa = "12345678"
return aa.encode()
0x05 Challenges
1. BugKu Crypto 贝斯家族
题目为: @iH<,{bdR2H;i6Tm,Wx2izpx2!*
TomatoTools进行密文分析可得知为base91
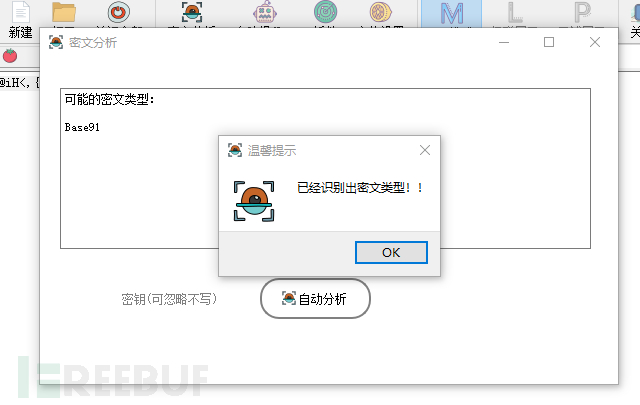
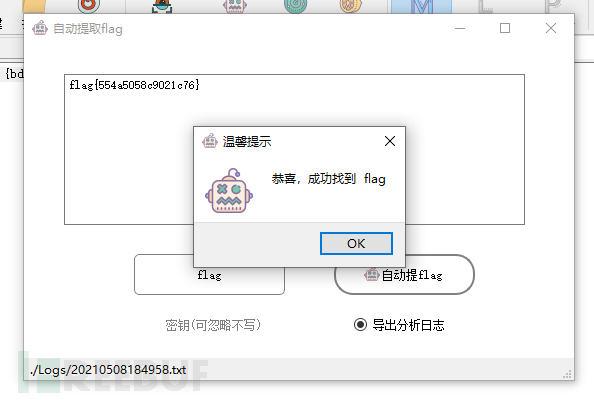
然后使用自动提flag获取最终 flag为 flag{554a5058c9021c76},并导出日志
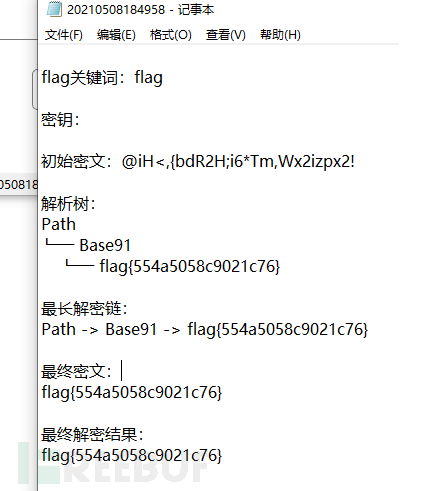
2. 攻防世界 混合编码
打开文件后发现密文如下,有经验的一看就知道是base64了
JiM3NjsmIzEyMjsmIzY5OyYjMTIwOyYjNzk7JiM4MzsmIzU2OyYjMTIwOyYjNzc7JiM2ODsmIzY5OyYjMTE4OyYjNzc7JiM4NDsmIzY1OyYjNTI7JiM3NjsmIzEyMjsmIzEwNzsmIzUzOyYjNzY7JiMxMjI7JiM2OTsmIzEyMDsmIzc3OyYjODM7JiM1NjsmIzEyMDsmIzc3OyYjNjg7JiMxMDc7JiMxMTg7JiM3NzsmIzg0OyYjNjU7JiMxMjA7JiM3NjsmIzEyMjsmIzY5OyYjMTIwOyYjNzg7JiMxMDU7JiM1NjsmIzEyMDsmIzc3OyYjODQ7JiM2OTsmIzExODsmIzc5OyYjODQ7JiM5OTsmIzExODsmIzc3OyYjODQ7JiM2OTsmIzUwOyYjNzY7JiMxMjI7JiM2OTsmIzEyMDsmIzc4OyYjMTA1OyYjNTY7JiM1MzsmIzc4OyYjMTIxOyYjNTY7JiM1MzsmIzc5OyYjODM7JiM1NjsmIzEyMDsmIzc3OyYjNjg7JiM5OTsmIzExODsmIzc5OyYjODQ7JiM5OTsmIzExODsmIzc3OyYjODQ7JiM2OTsmIzExOTsmIzc2OyYjMTIyOyYjNjk7JiMxMTk7JiM3NzsmIzY3OyYjNTY7JiMxMjA7JiM3NzsmIzY4OyYjNjU7JiMxMTg7JiM3NzsmIzg0OyYjNjU7JiMxMjA7JiM3NjsmIzEyMjsmIzY5OyYjMTE5OyYjNzc7JiMxMDU7JiM1NjsmIzEyMDsmIzc3OyYjNjg7JiM2OTsmIzExODsmIzc3OyYjODQ7JiM2OTsmIzExOTsmIzc2OyYjMTIyOyYjMTA3OyYjNTM7JiM3NjsmIzEyMjsmIzY5OyYjMTE5OyYjNzc7JiM4MzsmIzU2OyYjMTIwOyYjNzc7JiM4NDsmIzEwNzsmIzExODsmIzc3OyYjODQ7JiM2OTsmIzEyMDsmIzc2OyYjMTIyOyYjNjk7JiMxMjA7JiM3ODsmIzY3OyYjNTY7JiMxMjA7JiM3NzsmIzY4OyYjMTAzOyYjMTE4OyYjNzc7JiM4NDsmIzY1OyYjMTE5Ow==
使用TomatoTools去自动提取flag看看,提取后发现不能直接获得flag
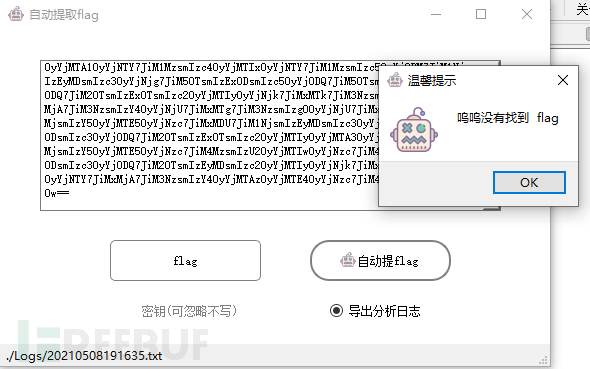
看下分析日志,看是哪里出了问题
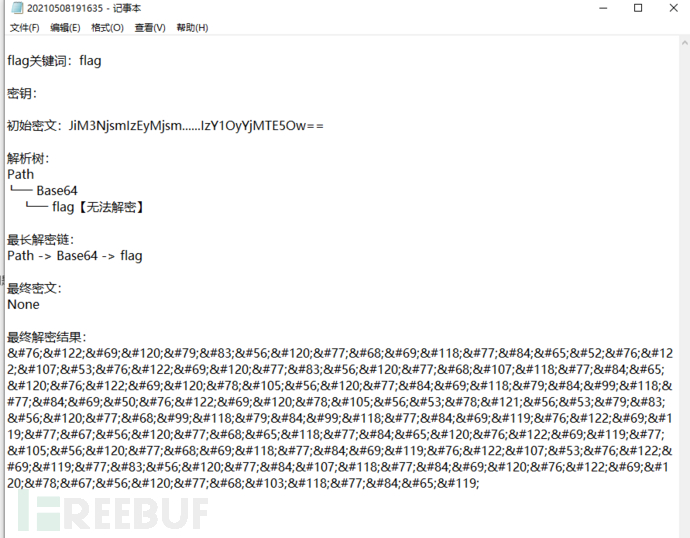
发现经过Base64解码后密文变成了HTML实体编码,而工具识别不了HTML实体编码,所以写个小插件来解码
# filename: htmlunescape.py
import html
dicts={
"name":"HTML实体编码",
"crypto_name":"htmlunescape",
"range":"[0-9#&;]",
"alphabet_num":"13",
"key":"False"
}
def htmlunescape(cryptostr):
result = html.unescape(cryptostr)
return result.encode()
添加HTML实体编码插件
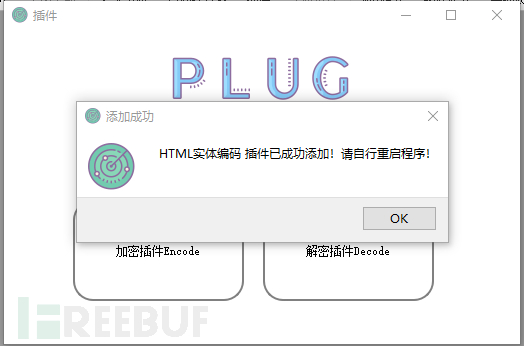
然后用刚刚添加的HTML实体编码插件解密一下
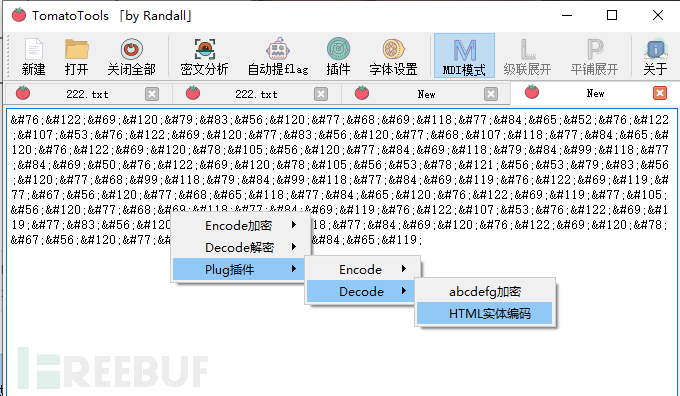
HTML实体编码解码后的一个base64的字符串如下
LzExOS8xMDEvMTA4Lzk5LzExMS8xMDkvMTAxLzExNi8xMTEvOTcvMTE2LzExNi85Ny85OS8xMDcvOTcvMTEwLzEwMC8xMDAvMTAxLzEwMi8xMDEvMTEwLzk5LzEwMS8xMTkvMTExLzExNC8xMDgvMTAw
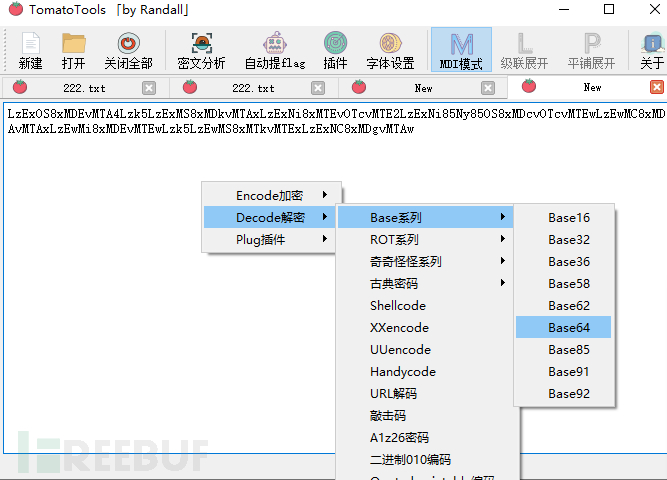
解码后得到下面的字符串
/119/101/108/99/111/109/101/116/111/97/116/116/97/99/107/97/110/100/100/101/102/101/110/99/101/119/111/114/108/100
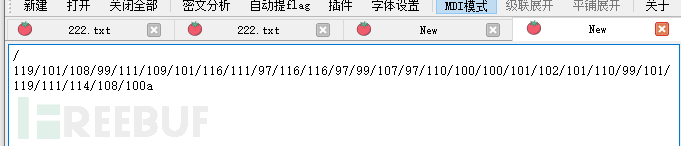
推测是ASCII编码,再写个小插件
#filename: slashASCII.py
dicts={
"name":"斜杠ASCII码转换",
"crypto_name":"slashASCII",
"range":"[0-9/]",
"alphabet_num":"11",
"key":"False"
}
def slashASCII(cryptostr):
cc = cryptostr.rsplit("/")
flag = ''
for i in cc[1:]:
flag += chr(int(i))
return flag.encode()
添加插件后使用这个插件解密
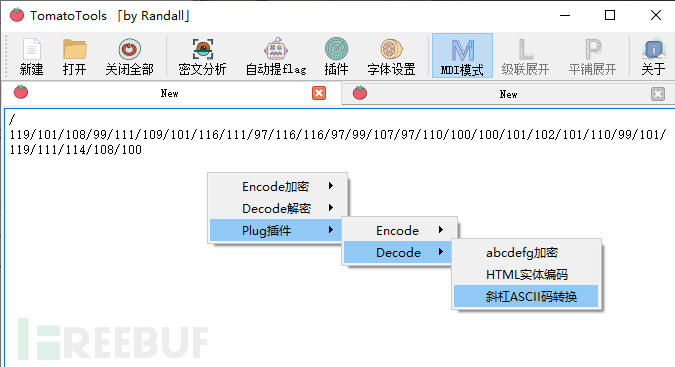
得到flag为 welcometoattackanddefenceworld
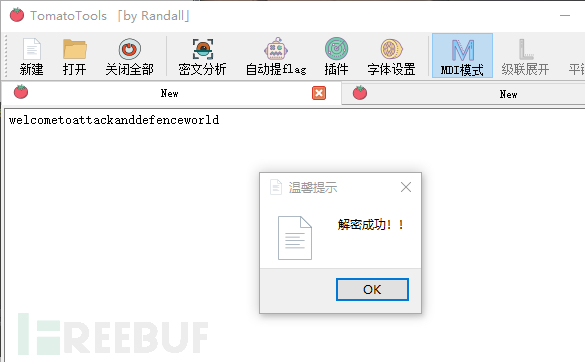
另外,两个插件都添加进去,也就是说现在可以用 自动提flag来体验一步到位的快乐了,
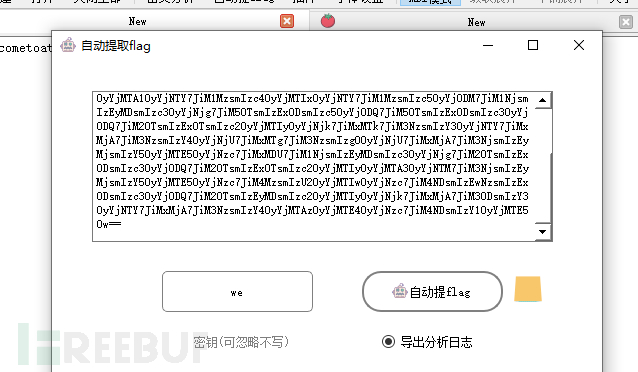
提示找到了 we ,flag也被找出来了
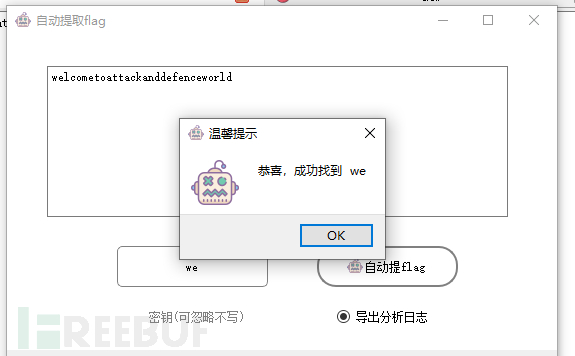
接着看下分析日志

0x06 写在最后
TomatoTools已经开源,项目地址如下
https://github.com/ht0Ruial/TomatoTools
欢迎各位师傅Star!

如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 渗透实战优质工具
渗透实战优质工具
 tool
tool







- 1 文章数
- 5 关注者