


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
随着AI技术的发展,语音克隆技术也受到越来越多的关注。目前,AI语音克隆技术已经可以实现模拟出一个人的声音,包括音色、语言习惯和情绪等。
本文将介绍我们调研并复现的一些语音克隆开源项目,分析各个项目的优缺点,记录复现过程需要注意的问题,并在此基础上实现简易的语音克隆。
MockingBird
项目介绍
MockingBird是一个文本转语音项目,使用深度学习模型生成语音。作者提供预训练的语音合成模型,方便针对性的微调,可用于语音助手、有声书等。此外,该项目提供多种可视化方法,方便使用。
环境搭建

note: 原项目提供桌面版和web版(streamlit)页面,并提供docker部署,这里复现的是web版。
使用
该项目可视化页面使用streamlit框架。
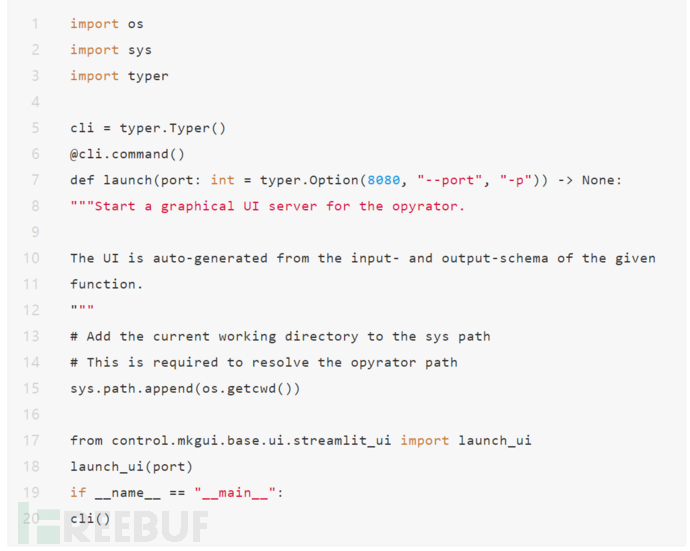
把streamlit的相关代码写到临时文件再执行。
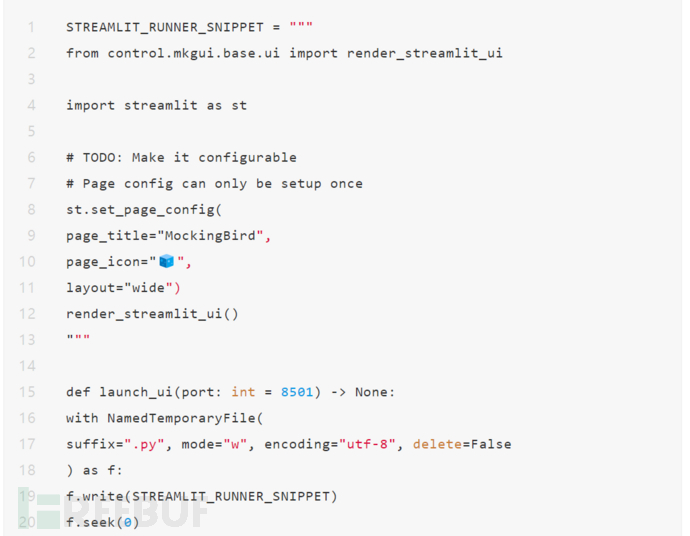
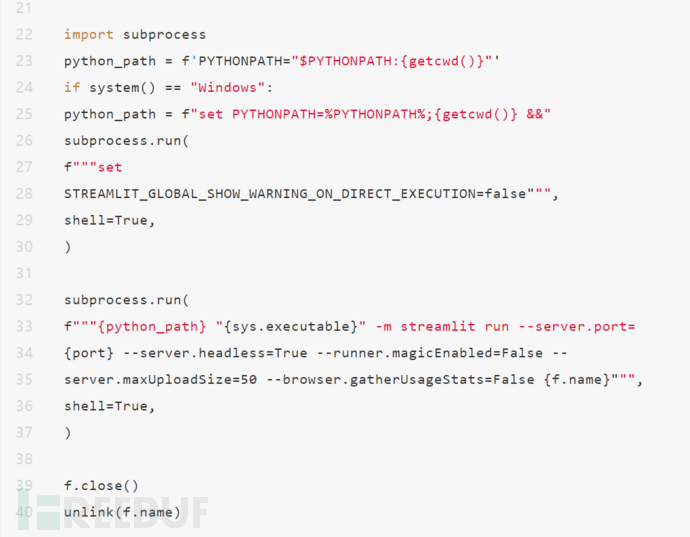
python web.py启动web页面,如下图所示。左侧为输入部分,包括文本内容、被克隆的语音和语音合成的模型,右侧为语音合成的结果,包括语音和梅尔谱图。
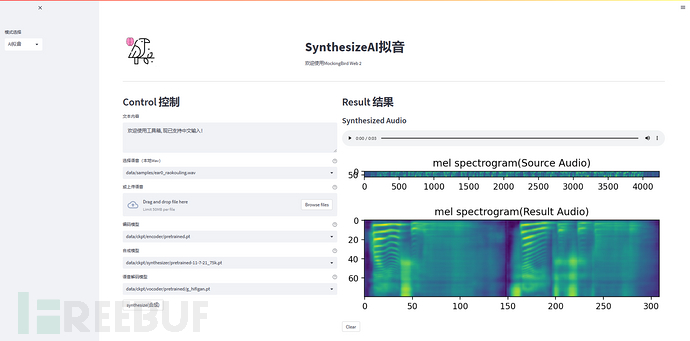
经过测试发现,模型可抽取的特征有限,因此输入音频的长度不是越长越好,最好在3s到8s之间。输入音频的说话声最好是平调,不要包含太多的情绪,确保输入音频只有一个人声,这能够帮助实现更好的生成效果。
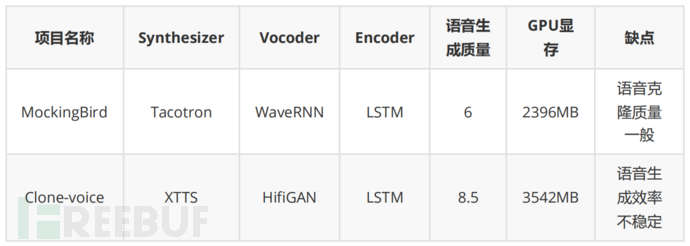
目前MockingBird比较广泛的应用场景是整理某个人的音频数据集,在一个声音上做微调,语音生成质量(杂音、吐字清晰度)和音色会好一些。如果应用在加载简短的录音或实时语音克隆,生成的效果会差一些。
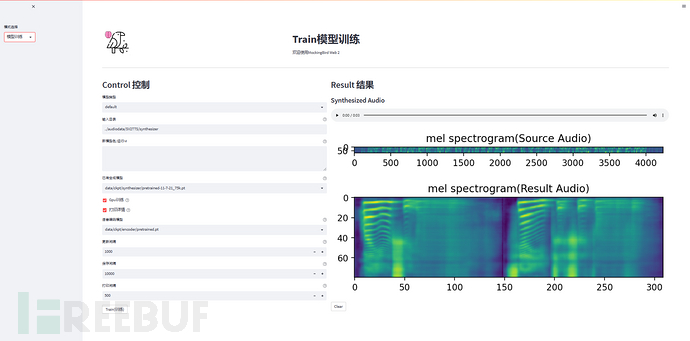
除此之外,该项目提供可视化的训练页面和数据集预处理程序,预处理数据集(17.5G)单核需要6h左右,按项目默认的超参数训练大概需要5000MB显存。
微调流程
该项目的整体架构包括三个部分,分别是encoder、synthesizer和vocoder。encoder用于捕捉音频的特征,提高泛化能力,synthesizer使用Tacotron 2架构完成序列到序列的任务,vocoder使用WaveNet生成音频内容。这里微调的是synthesizer模型,作者认为微调vocoder对最终语音合成的效果影响不大,我们也认为合成任务比vocoder任务难,最需要优化synthesizer合成语音的特征。
微调首先需要整理自己的数据集,对音频切片,使用工具生成音频对应的文本内容,运行数据集预处理程序,包括使用libsora对音频文件预处理和使用encoder生成embedding,接着就可以使用对应的训练代码微调。
微调也可以在开源语音数据集上进行,如aidatatang_200zh、magicdata、aishell3等。
相关训练参数:

问题记录
下载checkpoint之后,在项目根目录下的data/ckpt中新建synthesizer文件夹,把pt文件放到该文件夹下。
Clone-voice
项目地址:
https://github.com/jianchang512/clone-voice
项目介绍
这是一个声音克隆工具,可使用任何人类音色,将一段文字合成为使用该音色说话的声音,或者将一个声音使用该音色转换为另一个声音。该项目支持中英日韩四种语言,可在线麦克风录制声音使用。
环境

使用
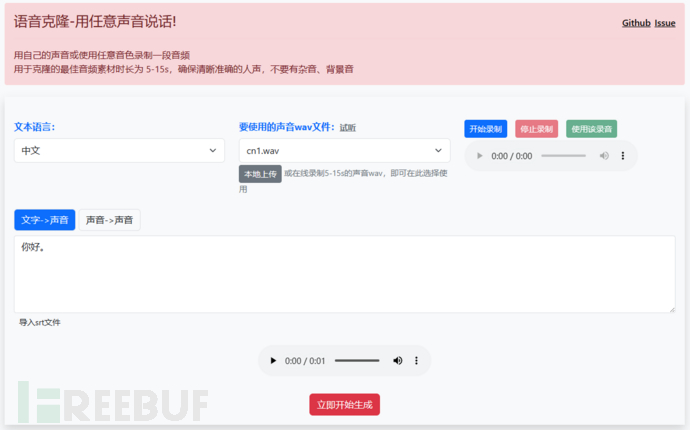
该项目提供web页面如上图所示,文本语言处可以选择四种语言,被克隆的语音可以选择已有的语音,也可以直接录制声音,作者建议语音录制时长为5s到20s之间,发音准确,尽量不要存在背景噪声,支持文本转语音和语音转语音,使用XTTS生成语音,但由于项目实现的原因,合成的速度不稳定,偶尔会出现一两分钟合成一句话的情况。
Coqui XTTS
- 项目地址:https://github.com/coqui-ai/TTS
- 文档:https://docs.coqui.ai/en/dev/models/xtts.html
- huggingface:https://huggingface.co/coqui/XTTS-v2
- paper:https://arxiv.org/abs/2112.02418
项目介绍
XTTS是一款文字转语音模型,可以通过几秒的音频片段实现语音克隆。XTTS基于Tortoise开发,对模型进行了重要修改,使跨语言语音克隆和多语言语音生成变得简单,减少训练所需的数据和资源。
使用

上述代码展示了XTTS如何初步使用,我们在此基础上实现了一个TTS demo,web界面如下,左侧是相关输入,能够选择已有的音频文件,也可以上传或录制音频,右侧表示语音克隆的结果。
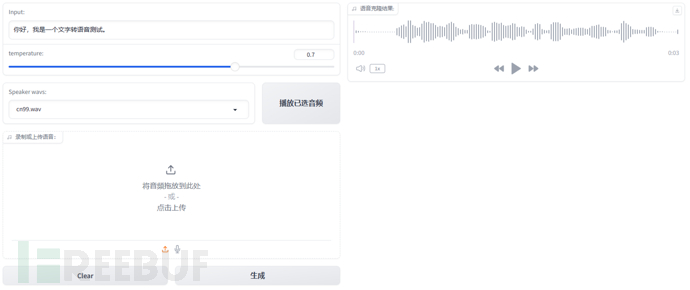
XTTS是一个端到端的zero-shot语音克隆模型,不需要提前对语音微调即可实现零样本语音合成,该模型使用一个小的GPT2和hifigan完成语音克隆任务。加载完整的模型需要2672MB显存,当文本输入为”你好,我是一个文字转语音测试。“,在4090上推理需要的内存为3700MB,时间为2s,如果使用CPU合成,生成速度大概会慢一倍。在语音克隆的效果上,能够明显听出所需的音色,但偶尔会出现停顿不自然、噪声问题,进一步的工作可以尝试在预训练的模型上使用中文数据集微调。
代码






问题记录
1. 模型位置
问题描述:直接用tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device),会默认下载到~/.local/share,由于网络问题,可能存在不能从huggingface下载模型的情况。
解决方法:可以手动下载然后放到项目文件夹或./loacl/share中,如果放在项目文件夹中,必须设置os.environ['TTS_HOME']=ROOT_DIR,具体原因如下述代码所示,如果环境变量没有设置,仍然会去默认地址中检查是否已下载。

2. 环境兼容
问题描述:pydantic和gradio的版本兼容问题。
报错:
1、If you got this error by calling handler() within __get_pydantic_core_schema__ then you likely need to call handler.generate_schema() since we do not call__get_pydantic_core_schema__ on otherwise to avoid infinite recursion.
2、gradio 4.10.0 requires pydantic>=2.0, but you have pydantic 1.10.13 which is incompatible.
解决方法:如果需要使用pydantic,使用v1版本,gradio使用4.0之前的版本,并且需要修改demo中显示已有音频文件部分的代码。
3. 临时域名访问
当通过临时域名访问的时候,录音并连续生成会报错,可能是由于gradio的audio组件和网络问题,可以使用队列缓解这个问题。
4. 长文本输入
如果需要使用较长文本的语音克隆,可以参考XTTS文档中的流式输入和enable_text_splitting参数修改代码,也可以尝试配置deepspeed加速推理。
总结与思考
语音合成任务通常包括文本语音预处理、语音合成和语音后处理三个步骤,早期的方法更多地结合音频任务本身的特点优化语音合成效果,随着深度学习技术的发展,模型能够学习到更多的信息,当前主流的模型有wavenet、tacotron2、wavernn等,深度学习方法可以实现端到端的语音克隆,降低使用门槛。
从我们的实践来看,语音生成效果已经取得长足的进步,zero-shot语音克隆的效果也基本满意,但由于语音模型预训练数据分布的问题,大规模、高质量的中文开源预训练数据集较少,因此与英文相比,实时中文语音克隆的效果会差一些。此外,流式语音克隆是大势所趋,实时的输入音频,即时地生成语音,需要进一步优化推理所需的资源和生成语音的延迟。
- 0 文章数
- 0 关注者