


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
在日常开发工作中,我遇到过一个让人心惊胆战的情况。
当时,我们的团队正忙着处理用户反馈,一个客户报告说他们的服务器上运行的代码遭受了异常的攻击迹象。
经过深入调查,我们发现问题的根源在于代码中对eval函数的不当使用,这暴露了系统的巨大风险。
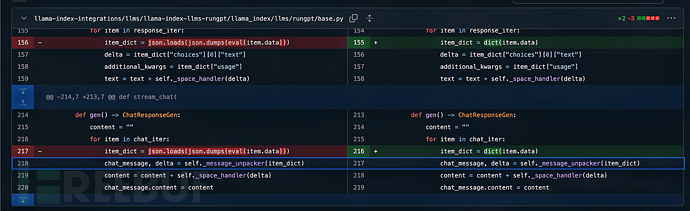
类似的问题也出现在了llama_index库(版本0.9.47)中的RunGptLLM类中,该类存在一个命令注入漏洞。
这个库被JinaAI的RunGpt框架用来连接语言学习模型(LLM)。
该漏洞的产生是由于不正确地使用了eval函数,这种错误的使用使得恶意或被攻陷的LLM托管服务商可以在客户端机器上执行任意命令。
这个问题已经在版本0.10.13中得到了修复。如果这个漏洞被利用,托管服务商可以获得对客户端机器的完全控制权限。
下面是一个类似的代码示例,用以说明漏洞的基本原理:
import json
import os
# 模拟用户输入的数据
data = "__import__('os').system(\"echo '# Hello, Markdown!' > hello.md\")"
def main():
# 直接在 eval 中使用用户可控的数据
item_dict = json.loads(json.dumps(eval(data)))
if __name__ == "__main__":
main()
在以上代码中,我们用到了eval函数直接执行用户输入的内容,这是一种非常危险的做法。
eval函数会将传入的字符串作为代码执行,这意味着如果用户输入包含恶意命令,例如上例中的__import__('os').system(...),它会执行任意命令。
在这个示例中,攻击者可以在你的系统中创建、删除文件甚至运行其它系统命令,完全控制机器。
为了避免这种情况,应避免直接使用eval来处理用户输入的数据。如果必须执行类似功能,可以考虑使用更为安全的库或采取严格的输入验证和限制。
总结来说,eval函数虽然强大,但也非常危险,它常常成为安全漏洞的根源。
在安全开发中,我们应尽量避免这种不安全的做法,替代方案包括使用专门的解析库、明确的数据验证以及安全沙箱环境等方法,确保代码在任何情况下都不会被恶意利用。
这个漏洞也被官方定义为CVE-2024-4181,
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者