


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
语音控制系统以语音识别和说话者识别作为关键的支持技术。虽然它们给日常生活带来了巨大变化,但其安全性已成为一个日益受到关注的问题。现有的研究已经证明了使用恶意制作的扰动来操纵语音或说话者识别的可行性。虽然这些攻击在目标和技术上各不相同,但它们都需要添加噪声扰动。这些扰动通常受到Lp范数的限制,但添加的噪声不可避免地会留下可识别的不自然痕迹,并可用于防御。为了解决这一局限性,本研究引入了一种新的对抗音频攻击—语义相关对抗音频攻击(SMACK,Semantically Meaningful Adversarial Audio Attack),其中固有语音属性(如韵律)将被修改,以使它们仍然在语义上表示相同的语音并保持语音质量。相关代码已开源:https://semanticaudioattack.github.io/ 。
0x01 简介
语音识别正在推动语音控制系统(VCS,Voice Controllable System)的快速发展。 VCS 的应用无处不在,从打电话到控制家庭安全系统。VCS 的关键功能 - 自动语音识别 (ASR,Automatic Speech Recognition) 和说话者识别 (SR,Speaker Recognition) 由深度神经网络 (DNN) 驱动,这些功能已被证明容易受到对抗样本的影响 。 对抗性音频攻击领域的现有工作侧重于通过向原始音频添加小扰动来制作对抗样本,受干扰的音频可用于误导 ASR 进行恶意命令注入,或欺骗 SR 将攻击者误识别为注册用户。 在这些攻击中,对抗样本生成被建模为约束优化问题,并限制扰动的大小。虽然现有的攻击在方法和目标上各不相同,但扰动通常是基于 Lp 有界范数进行优化的,并且人为引入的噪声通常不可避免地会给人类和算法留下可区分的人工痕迹。
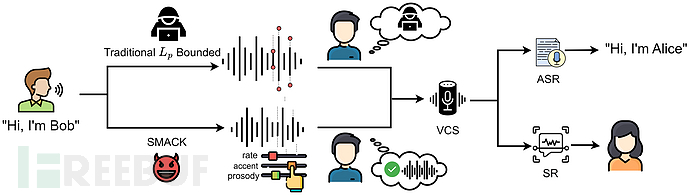
为了解决这一限制,本研究提出语义扰动来修改固有的语音属性,如上图所示。与传统的以最小粒度(图像域的像素和音频域的样本点)引入的扰动相比,语义保留扰动对搜索空间施加了额外的约束,以实现更好的自然性。图像领域中针对人脸验证系统的语义对抗样本是操纵固有属性(例如微笑、胡须)以最大限度地保留面部特征。 类似地,可以仅扰乱语音的固有属性,以最大限度地保留语音质量(自然性)。 在本文中探索了对韵律(一种代表性语义属性)的操作来生成对抗性音频样本。 从安全角度来看,这种自然性有可能显着提高对抗样本的隐蔽性。 此外,语义扰动可以更好地逃避现有的检测机制,该机制检查 Lp 范围内的对抗性扰动中的人工痕迹。
0x02 语义对抗样本
图像领域中的语义对抗攻击:语义属性的概念首先在图像领域中引入,作为一种数据增强方法来减轻过度拟合。 关键的直觉是沿着语义方向转换线性化特征空间中的数据样本,从而产生与具有相同类别标识但不同语义的另一个样本相对应的特征表示。 语义属性的示例包括眼镜、胡须以及不断变化的面部表情和化妆。 后来出现了很多对图像的语义对抗攻击,仅操纵更高级别的特征(例如,在面部添加眼镜)来欺骗图像识别算法。保留语义的视觉修改是有效的,但对语义相关的音频扰动却知之甚少。 图像和音频表现出不同的语义原则:图像中的语义属性(例如眼镜)由像素表示,这些像素需要与层次对象关联和颜色描述相关的空间相关性,而音频波形的语义属性(例如韵律)采用时间序列的格式 具有时间依赖性。 由于图像中的空间语义扰动可以用来攻击识别模型,因此时间语义修改是否可以产生类似的效果仍然未知。
音频领域的语义属性:虽然音频领域的一些现有工作提出了用于数据增强的语义属性的概念,包括韵律、重音和词序,但将它们用于对抗样本生成的可行性尚未被探索。 对于用于隐秘对抗攻击的语义特征,它必须满足三个关键要求:
(i)固有属性:在音频领域,固有属性是指不应该依赖于语音内容或说话者身份而是应该广泛存在于几乎所有语音中的属性。 典型的固有属性包括情感、语速、口音、韵律等。
(ii)身份内容保留:另一个要求在于从人类的角度保留原始标签。 对于 ASR 系统,语义对抗性音频样本的内容(即转录)应该与人类的原始内容相同。研究者不认为用同义词替换单词即可满足此要求。 对于SR系统,语义对抗性音频样本和原始音频的身份信息应该相同。
(iii)自然性:自然性(或真实性)也是一个重要的要求。 除了保留原始身份之外,还强调语义扰动的自然性。 直观上,虽然语义属性是人类语音的固有属性,但对其进行较大程度的修改会产生人工痕迹,使语音对人类来说听起来不正常。 例如,语速不能太快。
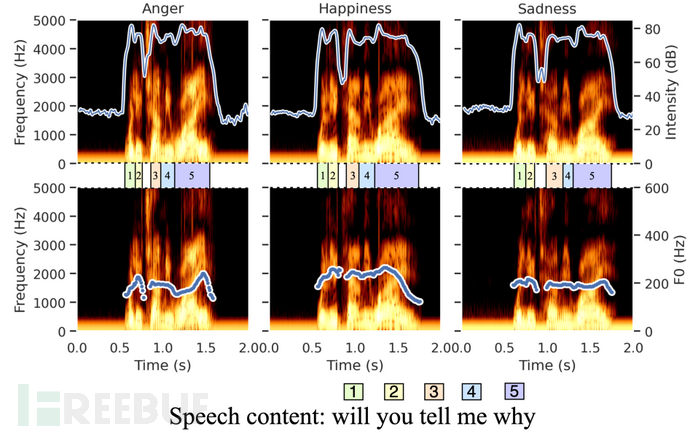
韵律作为语义属性:在这项研究中利用韵律作为代表性的语义属性。 韵律通常被描述为语调和节奏—语音的音乐品质和旋律。 它包含语音的多个特征,包括语音的音高轮廓或语调、音节的长度、单词的响度等。 与图像域中的像素级空间修改相比,音频域中的扰动通常是时间修改。 下图显示了对来自 SAVEE 数据集的三个语音片段的韵律定量分析。 这三个音频片段包含相同的语音内容(“Will you tell me why?”),但以三种类型的韵律说出:愤怒、快乐和悲伤。 顶部的三个数字描绘了语音的频谱和强度,其中强度以每个时刻的分贝 (dB) 为单位进行测量。 下面三个数字表示基频 (F0),即浊音中声带振动的频率。 在心理声学模型中,F0 频率通常被人类感知为声音的音高。 此外,每个单词的持续时间在中间指示,代表语速。 据观察,具有不同韵律的语音具有不同的持续时间,因此语速也不同。 例如,愤怒中的第三个单词(“tell”)的持续时间为 167 毫秒,明显短于快乐中的(186 毫秒)和悲伤的(225 毫秒)。 因此,韵律是由多种频域和时域描述符描述的复杂属性。
选择韵律是因为它满足语义对抗样本生成的三个要求。 首先,韵律是人类语音最重要的固有特征之一,已在多个领域得到广泛研究,包括情感识别、语音合成和语言研究。 其次,与口音和词序等其他语言特定特征不同,韵律不仅限于语音内容,而且具有普遍适用性。 第三,韵律可以通过每个帧中的细粒度特征来表示,并且在语义上限制韵律的操纵可以保留内容和自然性。 为了实现韵律的连贯操作,建立在生成模型的现有工作的基础上。
与其他攻击的相关性:生成模型广泛应用于不同的应用中,包括对抗性攻击。 一个相关的概念是音频DeepFake,攻击者旨在通过生成目标说话者的声音来冒充攻击目标。 虽然 DeepFake 和 SMACK 有相似之处,例如使用生成模型和针对 VCS,但它们的攻击目标和技术有所不同。 首先,DeepFake 的合成语音被设计为听起来像人类和计算机系统的受害者。 然而,SMACK 遵循对抗性音频生成的研究路线,旨在创建难以察觉的音频样本,这些样本对于人类来说根本不像攻击目标,只会误导识别算法。 其次,虽然两者都使用生成模型,但 DeepFake 利用它们来学习和模仿受害者语音的特征,这通常需要付出不小的努力来收集攻击目标的语音进行训练。 相比之下,SMACK 使用生成模型在原始音频上创建扰动,而不需要攻击目标的声音。 由于 SMACK 的目的是误导识别模型,因此它依赖于设计的多目标函数,结合了对抗性损失和人类感知能力,而 DeepFake 通常不包括对抗性损失。
0x03 威胁模型
攻击目标:攻击者旨在对 ASR 或/和 SR 系统进行有针对性的攻击。 在针对 ASR 的攻击中,对抗性音频应被转录为与人类解释不同的单词/句子。 对于对 SR 系统的攻击,攻击者的目的是制作和播放对抗性音频,以便 SR 算法将其误识别为来自一位已注册的说话者。
攻击者假设:假设攻击者仅拥有黑盒知识(既无法访问目标模型的架构,也无法访问目标模型的参数),并且对音频源的访问有限。 对于 ASR 攻击,假设攻击者只能访问转录,因此它被认为是硬标签黑盒攻击。 对于 SR 攻击,假设攻击者有权访问最终结果(接受/拒绝)和置信度得分,还假设攻击者无权访问系统中注册用户的语音样本,因此他无法使用 DeepFake 创建听起来像受害者的音频样本。
目标系统假设:假设ASR和SR系统被配置为提供最佳的识别率,并且识别模型随着时间的推移保持不变,还假设商业API和VCS为同一平台提供的服务是相似的。
对抗样本生成和交付:对抗性音频样本提前生成,并且可以通过 API 在线传送到目标或通过播放传输到 ASR/SR 设备。假设攻击者可以播放整个对抗性音频样本而不是其中的一部分。
0x04 SMACK概述
SMACK 旨在操纵原始音频的韵律,导致 ASR 和 SR 系统的错误分类,这存在三个关键技术挑战。
(i)韵律是一个包含多种特征的复杂属性,包括语速、语调、响度、音节长度等。这种复杂性带来了在给定语音中有效建模和控制它的挑战。 为了解决这个问题,设计了一个用于逐帧细粒度韵律控制的自适应生成模型。 韵律不仅涉及语音的时间特征,还涉及特征向量之间的相互作用。为了解决缺乏具体数学公式的问题并能够准确操纵语音韵律,采用了最新的语音生成模型。 为了进一步保留原始语音,修改生成模型以包含应进行韵律修改的原始音频,从而允许修改语音而不是直接合成。
(ii)在现有的通过生成模型进行韵律操作的方法下,韵律向量通常具有固定的维度。 然而,当语音具有不同的长度和措辞时,它需要由韵律控制向量的维度控制的适当水平的操作粒度。 为了确保生成的对抗样本的自然性,本文提出了一个两阶段优化框架,结合一个新颖的 InsDel 算子,以实现韵律向量的可变长度搜索。
(iii)与其他针对 ASR 的黑盒攻击不同,SMACK 基于韵律操作,这对如何添加扰动设置了额外的限制。 为了便于更准确地计算梯度,开发了一种新的基于音素的损失函数。此外,设计了一种算法从而更有效地攻击 SR 系统,即利用每个查询的结果和置信度得分来迭代估计说话者识别中使用的阈值。
A. 韵律建模与控制
由于韵律的复杂性,其控制仍然是一个开放的研究问题。 在没有具体的分析解决方案的情况下,建立在生成模型的现有进展之上,以实现对韵律的细粒度操作,其中它适合用作音频样本语义编辑的转换函数。下图显示了生成模型设计的架构,包含四个主要组件:内容网络、韵律网络、韵律内容交叉注意力模块和解码器网络。
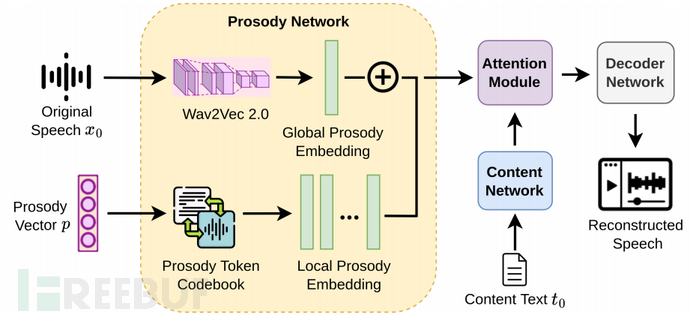
内容网络:它使用原始语音的文本来约束重构语音的内容(即语义对抗性音频样本)与原始语音相同。
韵律网络:生成的音频的韵律由两个组件定义:
(i)全局韵律代表了每个说话者独特的语气,因此表征了说话者的身份。 它由通过 Wav2Vec 2.0特征提取器从原始音频中提取的全局韵律嵌入来表示。 为了满足身份保留要求,SMACK 中的全局韵律嵌入保持不变。
(ii)局部韵律侧重于帧级韵律特征,它是由可变长度输入韵律向量(即攻击者旨在优化
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者