


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 CDra90n
CDra90n- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
虽然基于渲染文本的视觉机器学习模型已经能够抵御各种现有的攻击,但它们仍然难易防范编码为文本的视觉对抗样本。通过使用变音符号组合(diacritical mark)的 Unicode功能来操作编码文本,可以在渲染文本时出现小的视觉扰动。 本研究展示了如何使用遗传算法在黑盒设置中生成视觉对抗样本,并进行用户研究以确定欺骗模型的对抗样本可以欺骗用户。 通过攻击Facebook、Microsoft、IBM 和 Google 发布的生产模型,展示了这些对抗样本的有效性。所有实验代码和结果均位于: https://github.com/nickboucher/diacritics
0x01 简介
针对文本编码的难以察觉的扰动攻击利用不常见的 Unicode 编码来破坏文本模型,且欺骗用户的视觉感受。 现有的编码攻击防御措施通过统一视觉和编码管道来实现防护; 具体来说,视觉Transformer (ViT,Vision Transformer) 架构可用于构建强大的新模型,光学字符识别 (OCR,Optical Character Recognition) 则可用于对现有模型进行防御改造。 此类防御旨在确保视觉上相同的文本输入在受保护模型中产生相同的输出。
但是这些防御措施是不够的,本研究提出了一种对文本扰动进行编码的技术,一旦渲染,渲染文本的图像将包含绕过视觉防御的对抗性扰动。 这些对抗样本在视觉文本域中运行,意味着视觉输入完全由渲染文本生成,因此不可能扰乱任意像素值。 然而,通过利用 Unicode 规范中的组合符号,可以制作在文本渲染图像上的小型、有针对性的视觉扰动。 虽然这些符号在视觉上的重要性不足以影响人类读者对文本的理解,但渲染文本的图像域中被操纵的像素可以对模型输出进行有针对性的攻击。
0x02 背景
视觉差距:传统上,处理自然语言等文本的机器学习模型直接对输入文本的编码进行操作。 这可以采用输入嵌入的形式作为表示单词、字符或通过解析 Unicode 输入创建的学习子词组件的向量。 然而,与模型不同的是,人类并不直接使用编码文本。 相反,文本被渲染,然后以视觉方式呈现给人类用户。在这里出现了安全设计缺陷:编码文本和呈现文本之间的关系不是双射的。也就是说,视觉呈现可以由许多独特的文本编码来表示。形式化地,
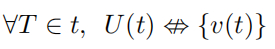
其中 T 是所有可能的文本序列的集合,U 是生成文本的所有可能的 Unicode 表示形式的集合的函数,v 是文本的视觉呈现。对于不可见字符,例如 Unicode 的零宽度空间 (ZWSP,Zero-Width Space); 这些字符对大多数文本的呈现没有影响,但会改变编码表示。 视觉上相同的字符(称为同形文字)也可以互换使用,控制字符可用于删除和重新排序字符。当文本编码与视觉呈现存在差异时,可用于生成针对特定形式文本输入操作的模型的对抗样本,从而提高利用拼写错误或释义的攻击隐蔽性。 视觉差距如下图所示。

视觉防御:为了防御利用视觉差距的对抗样本,模型设计者必须寻求统一文本编码和可视化管道。 也就是说设计人员必须寻求构建或增强模型:
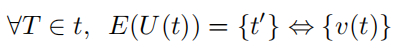
其中 E 生成作为输入的编码值的嵌入集。
在现有模型上实现此目的的一种简单但有效的方法是渲染文本输入并通过 OCR 处理生成的图像,作为模型推理之前的预处理步骤。 实际上,这提供了一个自动化系统,将固定的视觉渲染映射到公共编码输入。 此设置中的推理管道为:编码输入→渲染图像→文本→模型。
对于全新模型而言,对于全新模型而言,Vision Transformers 可能是首选的防御方法,因为不需要计算密集型的预处理模型。 ViT 将图像作为输入进行操作,并直接将渲染图像作为嵌入进行操作,可以产生良好的性能,并通过设计来对利用视觉差距的攻击进行防御。 此设置中的推理管道为:编码输入→渲染图像→模型。
最后,神经编码器为新的 NLP 模型提供了针对 Unicode 扰动的鲁棒性。 尽管神经编码器不在视觉领域中运行,但神经编码器是一种学习嵌入的形式,它映射 Unicode 字符之间的关系,使得渲染后看起来相似的编码值应该产生相似的嵌入。 此设置中的推理流程为:编码输入→神经嵌入→模型。
0x03 攻击方法
在图像领域,对抗样本通常是通过稍微扰动通常通过基于梯度的方法识别的关键像素的值来制作的。 虽然这种方法理论上适用于 ViT 和 OCR 模型,但视觉文本域具有额外的约束,即输入图像是通过渲染文本生成的
畅读付费文章
 已在FreeBuf发表 44 篇文章
已在FreeBuf发表 44 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 44 文章数
- 51 关注者