


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 CDra90n
CDra90n- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
公开可用的软件漏洞和漏洞利用代码经常被恶意行为者滥用,对易受攻击的目标发起网络攻击。组织不仅必须将他们的软件更新到最新版本,而且还必须进行有效的补丁管理并优先考虑与安全相关的补丁。除了计算机应急响应小组 (CERT) 警报、网络安全新闻、国家漏洞数据库 (NBD) 和商业网络安全供应商等情报来源之外,社交媒体是促进早期情报收集的另一个有价值的来源。为了基于互联网上公开可用的资源及早发现未来的网络威胁,本文提出了一个动态漏洞威胁评估模型来预测常见漏洞暴露中列出的漏洞条目的被利用趋势,并分析社交媒体内容,如 Twitter提取有意义的信息。该模型考虑了从不同来源收集的漏洞的多个方面。功能范围从配置文件信息到有关这些漏洞的上下文信息。对于社交媒体数据,本研究利用了专门针对 Twitter 的机器学习技术,这有助于过滤掉与网络安全无关的推文,并标记每条推文的主题类别。当应用于预测漏洞利用并分析现实世界的社交媒体讨论数据时,它显示出具有良好预测准确性的纯化社交媒体情报。此外,支持 AI 的模块已部署到威胁情报平台中以供进一步应用。
0x01 Introduction
在互联网论坛上经常发现有关安全漏洞的出版物和讨论,社交媒体已成为此类信息交流的主要平台。本研究的目的是利用 Twitter 上有关漏洞的消息来评估漏洞在现实世界中被利用的可能性。除了 Twitter 上的消息外,还采用了 NVD、CVE Details、VulDB、ExploitDB 和 Symantec 等漏洞数据库来提取特征来描述漏洞。恶意行为者使用公共漏洞信息开发漏洞代码,作为网络杀伤链的一部分。然后他们尝试利用这些漏洞并在目标服务器或设备上触发恶意代码。当前的安全措施通常会在发生违规行为后启动对恶意活动的分析。这种被动的方法对保护关键基础设施无效。这被认为是当前网络防御架构中的一个主要理论缺陷。
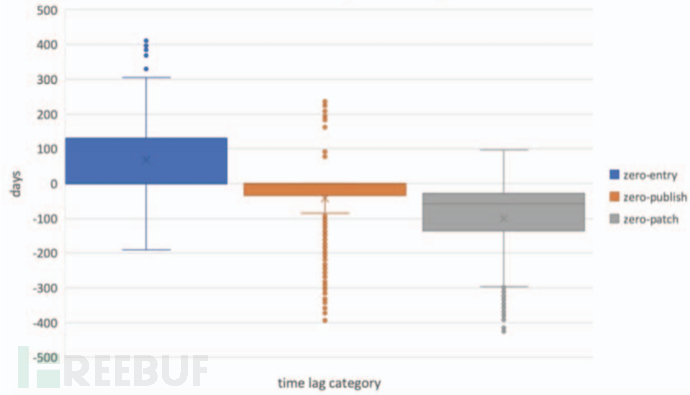
Twitter 等社交媒体提供信息以预测潜在的零日威胁。例如,上图显示了 2018 年不同安全措施的时滞统计,即:
1)zero-entry=exploit_date(即漏洞利用代码可用)- CVE_entry_date(即 CVE 编号给定日期)
2)zero-publish=exploit_date - CVE_publish_date(即CVE全信息发布)
3)zero-patch=exploit_date - CVE_patch_date。
在线漏洞讨论可以帮助安全专业人员获得第一手信息,以预防、阻止和应对潜在的网络攻击。现有的方法利用监督机器学习方法,即随机森林,基于从漏洞利用数据库 (ExploitDB) 获得的漏洞利用的基本事实和赛门铁克攻击特征 的描述来构建预测模型。此外,一个早期漏洞预警框架通过利用 Twitter 和暗网等非常规公共数据传感器生成当前网络威胁的警告。他们的系统监控一些著名的安全研究人员、分析师和白帽黑客的社交媒体提要,扫描与漏洞利用、漏洞和其他相关网络安全主题相关的帖子(推文)。之后,他们应用文本挖掘技术来识别重要术语并删除不相关的术语。Twitter 数据被视为一个很好的情报来源,因为漏洞利用通常在 Twitter 上讨论,然后才向公众披露。据报道,安全专家的 Twitter 活动是预测网络威胁的重要来源。
0x02 Methodology
在本节中提出了一个动态漏洞威胁评估模型来预测每个漏洞(即 CVE)的利用趋势。所提出模型的框架如下图所示。提出的方法的新颖之处在于它收集了开源威胁情报,并集成了机器学习和主题挖掘技术,以促进预测软件漏洞利用。提议的方法的结果包括 CVE 被利用的警报以及相关的社交媒体讨论。
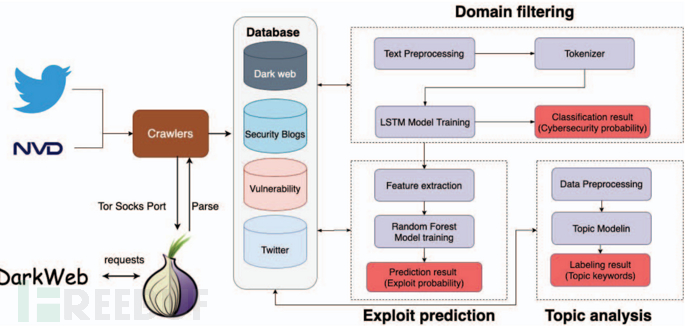
A. 利用预测
利用从多个来源收集的漏洞信息作为输入特征,例如 CWE 编号、CVSS 分数和零日漏洞的价格。此外,还收集所有带有 CVE 编号的漏洞的 Twitter 数据,以建立漏洞利用预测模型。例如,下图显示了提到的有关 CVE 的示例推文。

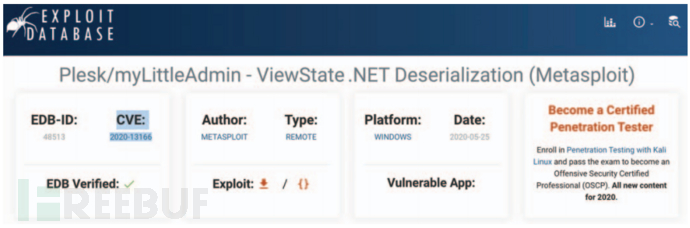
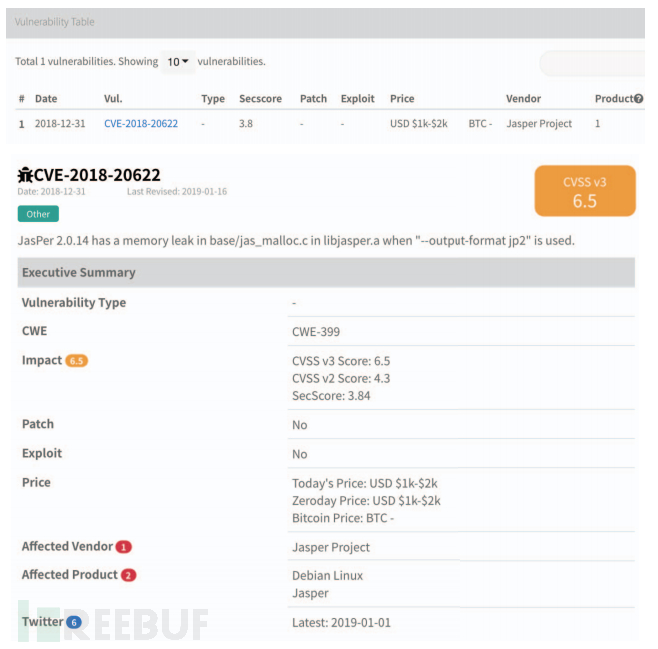
对于所有关于某个漏洞的推文,将保留的网络安全相关关键字字典的频率作为特征向量的一部分。一个表示为词频数字向量的漏洞,该漏洞的真实标签被手动标记为 1(表示已利用)和 0(表示未利用)。将 1999 年至 2018 年作为训练期,将 2019 年作为测试期。为防止数据过度不平衡,漏洞利用样本与非漏洞利用样本的比例设置为 1:3。从 ExploitDB(漏洞利用代码)和赛门铁克(Symantec 攻击签名)收集 CVE 漏洞利用证据。这些来源报告了已被利用的漏洞,并作为标记漏洞的基本事实。下图显示了在利用DB网站中发现的一个被利用的CVE的例子。
采用随机森林(RF)作为预测模型,因为与 SVM 相比,RF 擅长处理数值和分类数据。 RF的现代实践的基础包括:(1)使用袋外误差来估计泛化误差; (2) 通过排列测量变量的重要性。对于 Twitter 漏洞提及数据,将网络安全相关术语的频率计为模型输入特征的一部分,其中一些术语是从历史推文训练的潜在狄利克雷分配 (LDA) 模型 的结果。
B. 主题分析
对于主题分析功能,采用潜在狄利克雷分配(LDA)。 LDA 是一种概率模型(贝叶斯模型),它通过代表从文本本身推断出的主要主题的变量将文档和单词联系起来。文档被认为是主题 (z) 的混合,由概率分布表示,在给定这些主题的情况下,可以在文档中生成单词。给定平滑参数α和β,主题混合 θ 的联合分布,LDA 的思想是确定概率分布并生成由一组单词组成的一组主题 T,w = (w^1 ,.. ,w^S)。后验概率 p(zx|θ) 可以用随机变量 θi 表示。θi是文档 i 的主题分布,然后使用统计技术来学习每个文档的主题成分和混合系数。
C. 域过滤
对于域过滤功能,实现了一个深度学习模型——长短期记忆(LSTM)网络,用于将推文分为两类(网络安全相关,非网络安全相关)。 LSTM 是一种用于深度学习领域的人工循环神经网络 (RNN) 架构。与标准的前馈神经网络不同,LSTM 具有反馈连接。它不仅可以处理单个数据点,还可以处理整个数据序列。使用预训练的词嵌入转换将上下文数据转换为向量,并使用这些数值数据来训练 LSTM 模型。具体来说,嵌入可以看作是从词上下文共现空间到嵌入空间的线性变换。
0x03 Experimental Results
A. 数据收集和特征选择
漏洞的特征是从国家漏洞数据库 (NVD)、常见漏洞和暴露详细信息 (CVE 详细信息)、漏洞数据库 (VulDB) 和推特数据中提取的。收集的数据涵盖 1999 年至 2019 年。漏洞情报来源包括 NVD、CVE-Detail、VulDB、Exploit DB、0day.today、ICS-CERT 和 Twitter。通过开发爬虫或使用 API 从多个来源收集漏洞情报,然后附加由 CVE 编号索引的不同特征。这提供了 CVE 信息的不同视角,例如完整的时间线、受影响的供应商、补丁信息、受影响的行业、漏洞利用代码、CVE 价值和社交媒体流行度。
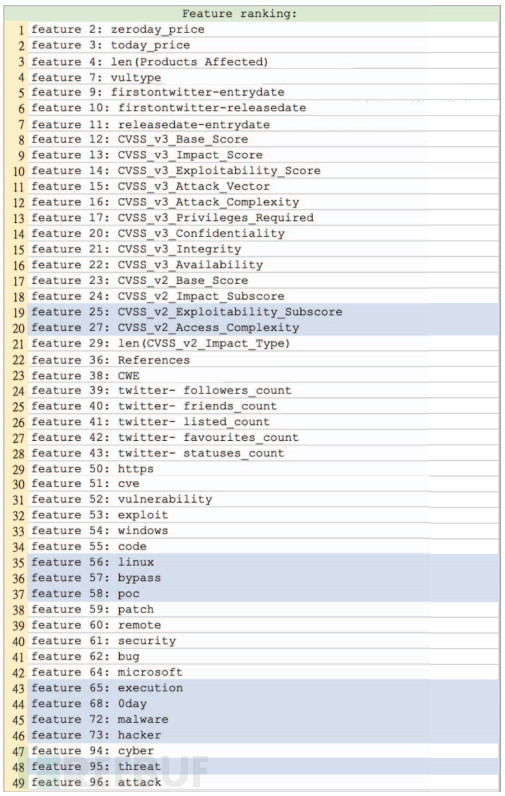
使用 RF 的特征重要性来进行特征选择。对于特征选择,随机选取 90% 作为训练数据,其余 10% 用于测试。在 98 个特征中,选择 RF 生成的变量重要性得分最高的 49 个特征作为 5 次实验运行后的输入特征。上表显示了实验中选择的 49 个特征。可以看到这些关键词都是与网络安全相关的术语,其中一些提到了特定的漏洞、利用和黑客攻击人员。
B. 漏洞利用预测性能
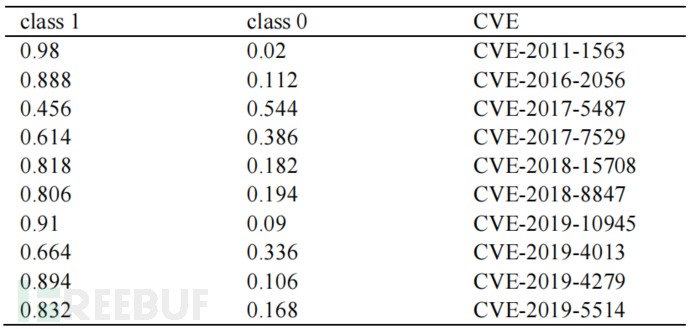
使用 1999 年至 2018 年发布的数据作为训练数据,使用 2019 年发布的数据作为测试数据。为了防止数据过度失衡,将利用样本和非利用样本的比例设置为 1:3。得到了 98.06% 的准确率,其中第1类错误为 1.8%,第2类错误为 6.56%。下表显示了 2019 年提到的被利用的 CVE。第 1 类表示预测为已利用,第 2 类表示预测为未利用。目前,将 0.5 设置为漏洞利用和非漏洞利用类的阈值。在下表中,除了 CVE-2017-5487 的 0 类分数高于其 1 类分数并且这两个分数都非常接近 0.5,其他 CVE 被正确预测为 1 类(被利用)。 RF与主题模型的分类准确率(98.06%)优于SVM模型的分类准确率(92.81%)。因此,所提出的漏洞威胁预测模型可以成功地提高对高风险漏洞的警报。
该漏洞利用预测方案作为分析功能之一部署到威胁情报平台中。下图显示了有关漏洞情报的系统 UI。名为“SecScore”的预测风险评分以及 CVSS v2、CVSS v3 和其他相关信息可以为组织提供决策支持,以确定其漏洞修补计划的优先级。
C. 域过滤性能
在 2019 年收集推文并准备 9099 条推文,并将它们手动标记为两类:网络安全相关和非网络安全相关。随机选择 80% 的数据进行训练,剩下的 20% 用于测试。下图显示了实验结果。
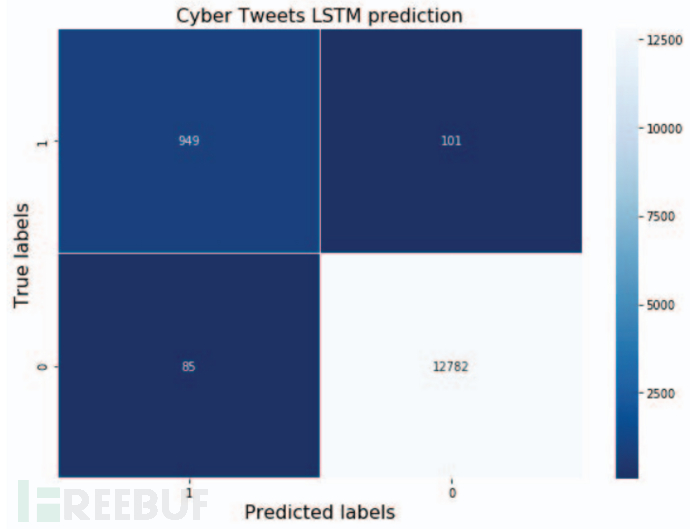
根据图 7,LSTM 模型可以得到 98.66% 的准确率、91.78% 的召回率、90.38% 的准确率和 0.9107 的 F1-Score。结果表明,所提出的方法在区分与网络安全相关的推文和其他噪音方面很有前景。下图顶部显示了与网络安全相关的推文示例,底部显示了不相关的推文示例。

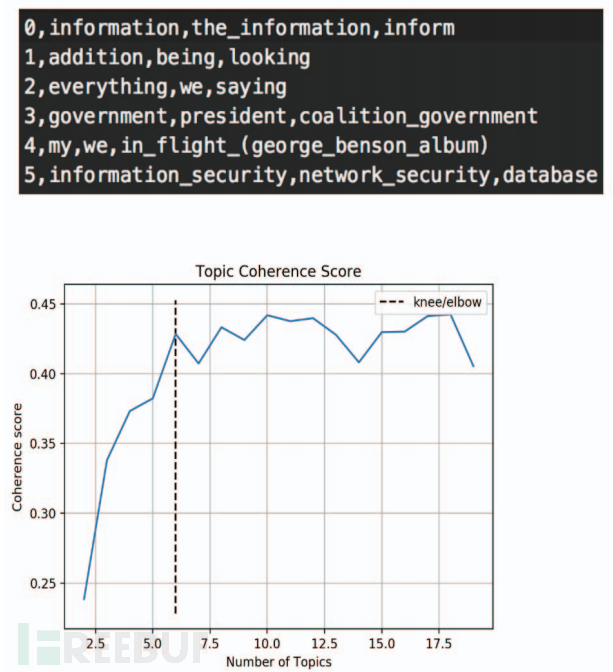
下图显示了主题标注功能的结果,根据主题连贯性得分图将主题编号设置为 6。对于 6 个主题,每个主题都分配有几个主题词来表示其主题。例如,主题 5 具有三个主题词:information_security、network_security 和 database。这些术语可以代表与网络安全和 IT 相关的主题,并帮助用户快速掌握推文的主要关注点。下图显示了主题标记结果的系统 UI,表明网络安全分数 (SecScore) 等于 1.0,建议的关键字(主题)是 google、恶意软件和黑客。
0x04 Conclusion
在这项研究中提出了一个动态漏洞威胁评估模型来预测将在不久的将来被利用的漏洞,以及一个用于信息过滤和分类的社交媒体内容分析模型。这项工作的新颖之处在于解决网络威胁预防和缓解的痛点,即信息优先级、信息净化和分类。首先将机器学习和主题挖掘技术相结合,以促进预测软件漏洞利用。此外,提出的方法还可以检索社交媒体上相关的网络威胁讨论以供进一步参考。
未来的工作包括以下几个方面。 (1) 改进模型的可持续性,部署移动窗口机制以提供每月 CVE 威胁评估; (2) 除了预测 CVE 的威胁级别外,还为没有 CVE 编号的黑客论坛或暗网市场上共享的漏洞代码创建威胁评估模型; (3) 应用所提出的主题标签技术来监控更广泛的网络安全相关 Twitter 数据以进行主题建模; (4) 将提议的方法应用于其他内容,例如新闻媒体和从黑客论坛收集的内容。
参考链接:https://ieeexplore.ieee.org/document/9343128/
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 在线社交网络安全
在线社交网络安全





- 44 文章数
- 51 关注者