


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
一、Apache Dubbo简介
Apache Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用、智能容错和负载均衡、以及服务自动注册和发现。Dubbo RPC是Apache Dubbo体系中最核心的一种高性能、高吞吐量的远程调用方式,主要用于两个Dubbo系统之间远程调用。在Dubbo RPC中,支持多种序列化方式,如dubbo序列化、hessian2序列化、kryo序列化、json序列化、java序列化等等。
从CVE官网可以了解到,2020年Apache Dubbo总共收录两个漏洞:CVE-2020-11995及CVE-2020-1948,主要均是针对默认的hessian2反序列化方式的利用。随着Dubbo的不断升级,大部分利用点已被修复,然而还是存在可被利用的风险。本文主要分析Dubbo框架曾经爆出的反序列化漏洞利用原理及补丁绕过的手段,并介绍Dubbo在使用非默认序列化配置时可能存在的安全风险,希望通过本文起到抛砖引玉的效果,帮助大家发现Dubbo其他潜在的安全问题,做好Dubbo框架的安全防护。
二、历史漏洞与修复绕过
首先我们回顾下Apache Dubbo 默认的hessian2反序列化漏洞利用与补丁绕过的过程。
2.1 Dubbo Version <= 2.7.6
在Dubbo2.7.6及以下版本中,Dubbo服务端不会对客户端传入的调用服务名及参数进行检查,即使在服务端未找到对应的服务名,也会对客户端传入的参数进行反序列化操作。参考marshalsec工具给出的Hessian反序列化构造链,结合Dubbo客户端调用规范,可以使用如下方法传入恶意对象对Dubbo服务端进行反序列化后的JNDI注入攻击(关于Hessian反序列化方式的利用链,marshalsec项目工具提供了四种,包括resin、rome、spring-aop、xbean。下面给出的是rome链。相关分析网上很多,感兴趣的同学可以自行复现其他利用链)。

分析下漏洞产生原理,查看Dubbo V2.7.6的源码,找到其解析请求体的代码DecodeableRpcInvocation#decode(Channel channel, InputStream input):
decode函数在解析Dubbo请求参数时先通过path获取服务描述信息serviceDescriptor,然后通过函数名及参数寻找服务中对应的方法methodDescriptor。即便所提供的服务中不包含对应的服务名,Dubbo服务端也会根据客户端传入的参数类型进行反序列化操作:in.readObject(pts[i]),这里in默认对应的是Hessian2ObjectInput。
可以看到,Dubbo客户端调用服务端时,可以通过将恶意序列化数据通过函数入参的形式传入,而服务端并不关心被调接口是否真实存在,只会依据客户端传入的参数类型进行反序列化操作,从而触发恶意调用链,对应的调用堆栈如下图所示:
另外,该处还存在一个后反序列化攻击点:DecodeableRpcInvocation#decode(Channel channel, InputStream input)函数在解析完pts和args参数后,会分别赋值给当前对象的parameterTypes属性和arguments属性,然后将当前DecodeableRpcInvocation作为参数返回。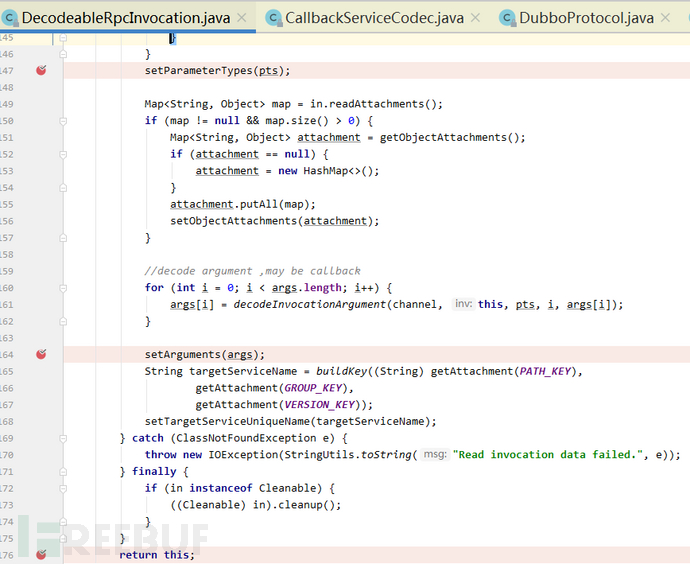
返回到DecodeHandler#received(Channel channel, Object message)方法后,继续调用HeaderExchangeHandler#received(Channel channel, Object message)方法处理请求信息: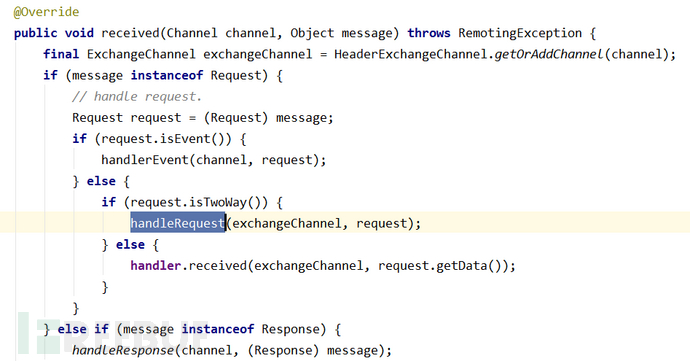
跟进handleRequest(final ExchangeChannel channel, Request req)方法,进入DubboProtocol#getInvoker(Channel channel, Invocation inv)函数,如果客户端传入的path在服务端不存在,此处会抛出一个RemotingException。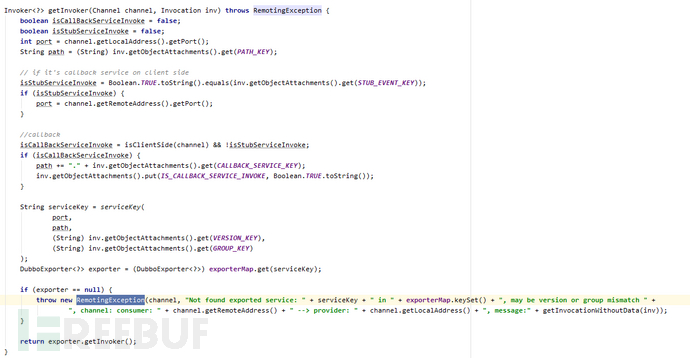
抛异常处将唤起org.apache.dubbo.rpc.RpcInvocation类的toString()函数。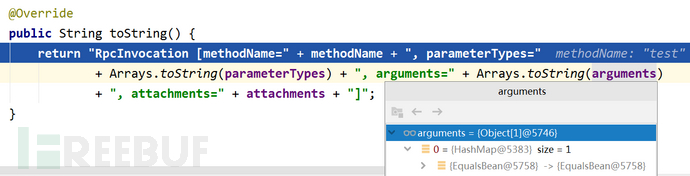
可以看到RpcInvocation类的arguments属性为前述步骤设置的args参数,其中包含有恶意的EqualsBean对象,通过Arrays.toString()方法,最终将触发EqualsBean的hashcode()方法,进而触发JNDI注入攻击,整个调用链如下:
2.2 DubboVersion2.7.7
到2.7.7版本,Dubbo官方针对上述问题做了个修复。当服务端找不到客户端指定的调用函数时,在DecodeableRpcInvocation#decode(Channel channel, InputStream input)中增加了isGenericCall与isEcho判断: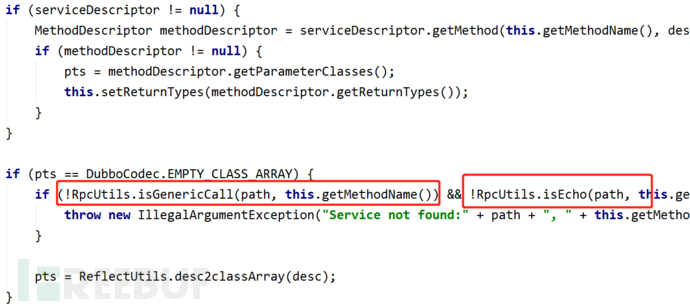 跟进isGenericCall与isEcho函数:
跟进isGenericCall与isEcho函数:

其实就是对调用的方法名进行判断,绕过这个判断的限制非常容易,只要调用的函数名为 "$invoke"、 "$invokeAsync"、"$echo"三者之一,即可继续向下执行,对客户端传入的参数进行反序列化,从而触发恶意调用链,例如将2.1节的客户端调用改为如下形式即可:
2.3 DubboVersion2.7.8
至2.7.8版本,Dubbo官方增强了isGenericCall与isEcho函数的判断逻辑,增加了对参数类型的判断,只有参数类型为"Ljava/lang/Object;"或"Ljava/lang/String;[Ljava/lang/String;[Ljava/lang/Object;"时,才能继续进行反序列化操作。
上述特定参数类型是无法构造恶意调用链的,所以这条路被堵上了。但是还可以“另辟蹊径”,参考threedr3am师傅的git项目:(https://github.com/threedr3am)。针对默认的Hessian2反序列化,还有两种有意思的利用方法。
方法一:
关注点还是放在DecodeableRpcInvocation#decode(Channel channel, InputStream input)函数上。服务端在调用readUTF()方法获取dubboVersion信息时。
会进入Hessian2Input#readString()函数以读取一个String。
如果此处传入的数据流不是String,则会在readString()函数中抛出异常。
跟进异常处理函数 该函数中调用了Hessian2Input#readObject()方法,该方法会根据客户端传入的实际数据类型生成对应的Deserializer类。
该函数中调用了Hessian2Input#readObject()方法,该方法会根据客户端传入的实际数据类型生成对应的Deserializer类。 如果客户端在本该传输dubboVersion的地方更改为传输恶意的HashMap类,上图中reader会对应赋值MapDeserializer来反序列化客户端传入的Map对象,这样便可以成功触发恶意调用链。
如果客户端在本该传输dubboVersion的地方更改为传输恶意的HashMap类,上图中reader会对应赋值MapDeserializer来反序列化客户端传入的Map对象,这样便可以成功触发恶意调用链。
整体调用栈如下图所示: 利用代码参考如下:
利用代码参考如下: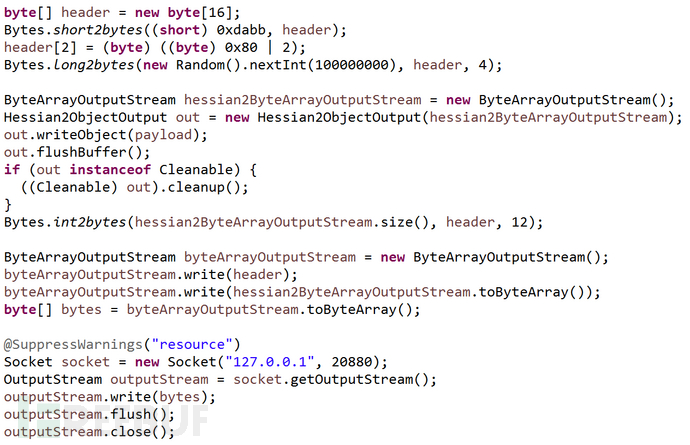
方法二:
前述利用方式,利用的反序列化入口点都在DecodeableRpcInvocation#decode(Channel channel, InputStream input)函数中。这个函数的作用主要是对dubbo协议中的Body信息进行还原,包括还原dubboVersion、调用路径path、调用函数methodName、调用函数的参数desc等等。但在调用这个函数之前,Dubbo服务端会使用ExchangeCodec#decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header)函数解析dubbo协议,dubbo协议格式参考下图。在解析dubbo协议的过程中也藏着反序列化的利用点。 Dubbo协议格式如上图所示,开头的magic位类似java字节码文件里的魔数,用来判断是不是dubbo协议的数据包,魔数是常量0xdabb,用于判断报文的开始。ExchangeCodec#decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header)函数在解析dubbo协议时先判断请求头是否是魔术字0xdabb,
Dubbo协议格式如上图所示,开头的magic位类似java字节码文件里的魔数,用来判断是不是dubbo协议的数据包,魔数是常量0xdabb,用于判断报文的开始。ExchangeCodec#decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header)函数在解析dubbo协议时先判断请求头是否是魔术字0xdabb, 当魔术头校验通过后,进入ExchangeCodec#decodeBody(Channel channel, InputStream is, byte[] header)函数获取flag标志位,一共8个地址位。低四位用来表示消息体数据用的序列化类型(默认hessian),高四位中,第一位为1表示是request请求,第二位为1表示双向传输(即有返回response),第三位为1表示是心跳事件。当服务端判断接收到的为心跳事件时,会调用相应的反序列化函数对数据流进行反序列化操作。
当魔术头校验通过后,进入ExchangeCodec#decodeBody(Channel channel, InputStream is, byte[] header)函数获取flag标志位,一共8个地址位。低四位用来表示消息体数据用的序列化类型(默认hessian),高四位中,第一位为1表示是request请求,第二位为1表示双向传输(即有返回response),第三位为1表示是心跳事件。当服务端判断接收到的为心跳事件时,会调用相应的反序列化函数对数据流进行反序列化操作。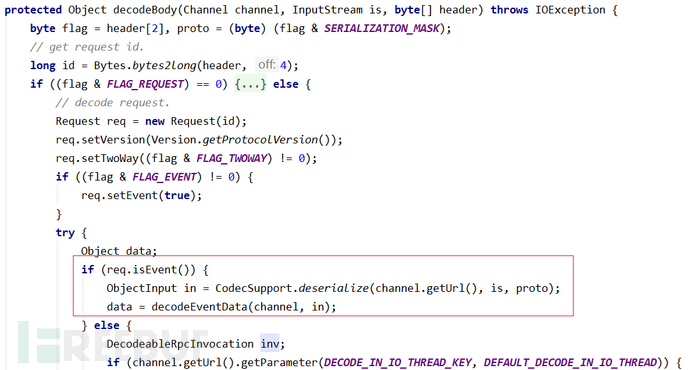 其中decodeEventData(Channel channel, ObjectInput in)函数会触发ObjectInput的readEvent()方法。
其中decodeEventData(Channel channel, ObjectInput in)函数会触发ObjectInput的readEvent()方法。 进而触发Hessian2ObjectInput的readObject()方法,使得恶意调用链被执行。此种利用方式payload的构造与方法一类似,注意将协议头的flag标志位置event事件类型即可,服务端对应的调用堆栈如下图所示。
进而触发Hessian2ObjectInput的readObject()方法,使得恶意调用链被执行。此种利用方式payload的构造与方法一类似,注意将协议头的flag标志位置event事件类型即可,服务端对应的调用堆栈如下图所示。
2.4 DubboVersion2.7.9
到Dubbo 2.7.9版本,服务端对心跳事件设置了默认的长度限制,参考DubboCodec#decodeEventData(Channel channel, ObjectInput in, byte[] eventBytes)函数: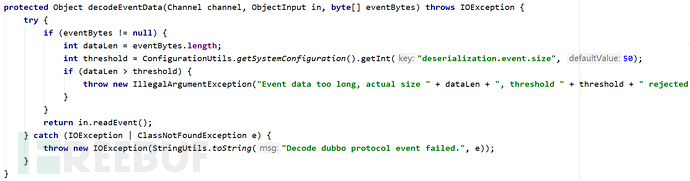 其中判断了待反序列化的数据长度是否超过配置的阈值(默认为50),如超过则抛出异常,不再继续反序列化。而能利用的恶意序列化payload都较长,导致2.3节介绍的第二种攻击方式失效,不过方法一在该版本仍然是有效的。
其中判断了待反序列化的数据长度是否超过配置的阈值(默认为50),如超过则抛出异常,不再继续反序列化。而能利用的恶意序列化payload都较长,导致2.3节介绍的第二种攻击方式失效,不过方法一在该版本仍然是有效的。
三、Dubbo Kryo序列化漏洞
Dubbo默认使用hessian来序列化反序列化数据,但因为各种各样的原因,一些开发团队也会修改默认配置,使用其他的序列化方式来传输数据,而配置其他的序列化方法是否是安全的呢?答案并不尽然。以Dubbo配置Kryo序列化方式为例,该种方式下也存在反序列化漏洞。
先简单介绍下Kryo:Kryo是一种快速高效的序列化方式,其序列化出来的结果是二进制的,速度更快,使用它可以序列化或反序列化任何Java类型。
Dubbo服务端采用何种方式来反序列化数据,完全取决于客户端传入的flag值。如客户端指定Kyro反序列方式,且服务端引用了Kyro相关的jar包,则服务端会使用对应的KryoObjectInput来处理传入的数据流。参考DecodeableRpcInvocation#decode(Channel channel, InputStream input)中的如下代码段: 当客户端指定序列方式为kryo时,dubbo服务端对应生成KryoObjectInput来处理后续数据流。
当客户端指定序列方式为kryo时,dubbo服务端对应生成KryoObjectInput来处理后续数据流。
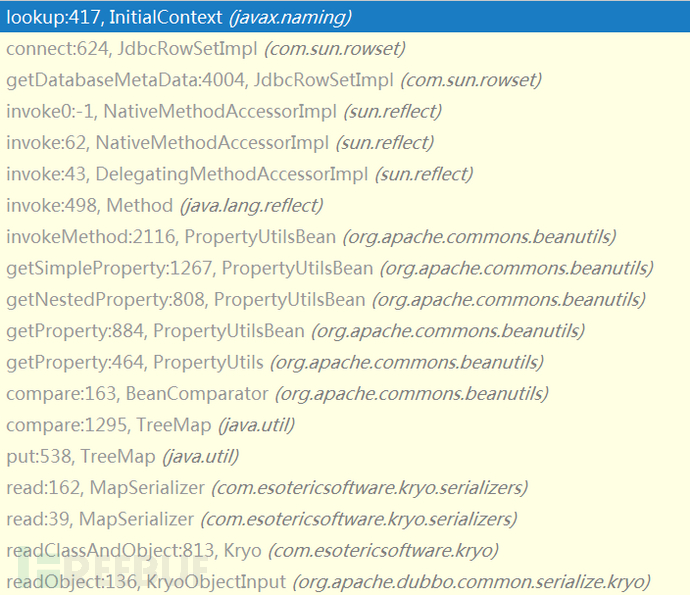
老版的kryo组件(Version<5.0.0)存在反序列化漏洞,参考marshalsec,给出了SpringAbstractBeanFactoryPointcutAdvisor、CommonsBeanutils两条利用链,均是利用的JNDI注入攻击,对应的调用链分别如下:
 比较有意思的是,原生的kryo在反序列化类时,如遇到无法获取对应的定制类序列化器时,会使用默认的com.esotericsoftware.kryo.serializers.FieldSerializer<T>来反序列化类:
比较有意思的是,原生的kryo在反序列化类时,如遇到无法获取对应的定制类序列化器时,会使用默认的com.esotericsoftware.kryo.serializers.FieldSerializer<T>来反序列化类: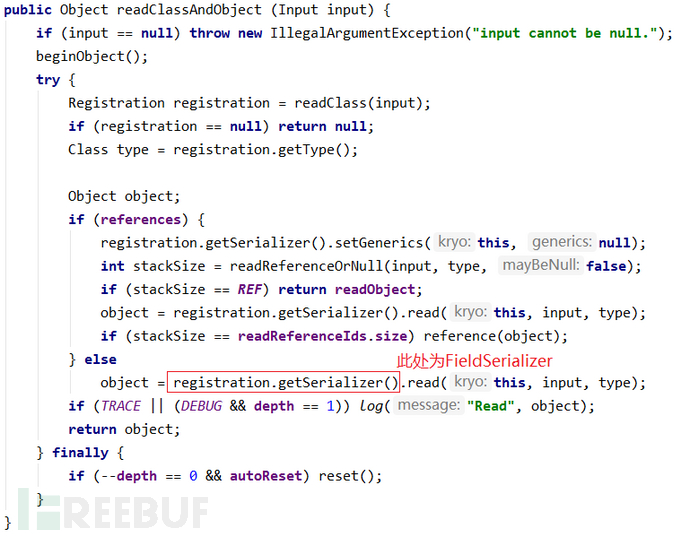 而FieldSerializer在反序列化类时,要求该类有一个无参数的构造函数,否则抛出类创建异常,导致反序列化失败。所以一些在Hessian序列化方式中可用的利用链(如Rome链)在Kryo中就不能使用了。
而FieldSerializer在反序列化类时,要求该类有一个无参数的构造函数,否则抛出类创建异常,导致反序列化失败。所以一些在Hessian序列化方式中可用的利用链(如Rome链)在Kryo中就不能使用了。
但是,Dubbo对原生的Kryo序列化做了部分改动,参考Dubbo源码中的org.apache.dubbo.common.serialize.kryo.CompatibleKryo#getDefaultSerializer(Class type)方法: 当被反序列化的类不存在默认的无参构造函数时,返回com.esotericsoftware.kryo.serializers.JavaSerializer作为默认的序列化处理类而不是FieldSerializer,这个操作可以令Dubbo用户更加容易的序列化那些不包含零参构造函数的类,但同时也带来了更多被利用的可能,比如原来rome链中由于com.rometools.rome.feed.impl.EqualsBean类缺乏无参构造函数导致反序列化失败的问题就被解决了,相当于有更多的利用链可以被用于攻击。
当被反序列化的类不存在默认的无参构造函数时,返回com.esotericsoftware.kryo.serializers.JavaSerializer作为默认的序列化处理类而不是FieldSerializer,这个操作可以令Dubbo用户更加容易的序列化那些不包含零参构造函数的类,但同时也带来了更多被利用的可能,比如原来rome链中由于com.rometools.rome.feed.impl.EqualsBean类缺乏无参构造函数导致反序列化失败的问题就被解决了,相当于有更多的利用链可以被用于攻击。
另外,查看kryo的git提交记录,可以看到从5.0.0版本后,kryo整体进行了较大的重构,其中一个重大的改造是将com.esotericsoftware.kryo.Kryo类的registrationRequired属性默认设置为true。相当于开启了白名单,只有注册过的类才能被序列化和反序列化。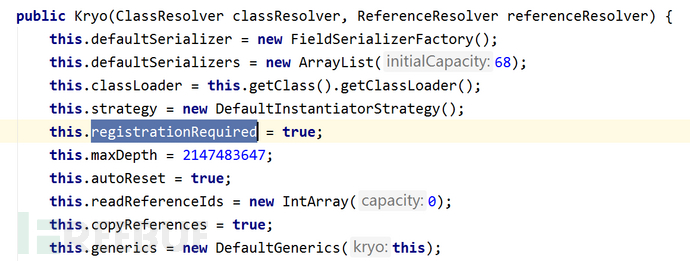 然而dubbo并不支持配置高版本Kryo组件。因为在org.apache.dubbo.common.serialize.kryo.KryoObjectOutput初始化时,会用到org.apache.dubbo.common.serialize.kryo.utils.KryoUtils #get()函数来获取实例化后的Kryo。
然而dubbo并不支持配置高版本Kryo组件。因为在org.apache.dubbo.common.serialize.kryo.KryoObjectOutput初始化时,会用到org.apache.dubbo.common.serialize.kryo.utils.KryoUtils #get()函数来获取实例化后的Kryo。 跟进KryoUtils #get()函数:
跟进KryoUtils #get()函数: 发现该函数调用了org.apache.dubbo.common.serialize.kryo.utils.AbstractKryoFactory类的getKryo()方法,而AbstractKryoFactory这个抽象类需要实现原生kryo包中的com.esotericsoftware.kryo.pool.KryoFactory接口。
发现该函数调用了org.apache.dubbo.common.serialize.kryo.utils.AbstractKryoFactory类的getKryo()方法,而AbstractKryoFactory这个抽象类需要实现原生kryo包中的com.esotericsoftware.kryo.pool.KryoFactory接口。 重构之后的高版本Kryo组件不再包含该类,导致Dubbo无法兼容最新的Kryo包,只能配置风险更高的低版本。
重构之后的高版本Kryo组件不再包含该类,导致Dubbo无法兼容最新的Kryo包,只能配置风险更高的低版本。
可以说,当使用的dubbo版本在2.7.9之下,且服务端引入了kryo配置,同时服务端包含可用于构造利用链的第三方依赖包的前提下,是可能产生远程命令执行的风险的。反序列化执行的入口点与Hessian模式下类似:一个是模拟客户端调用服务端,将恶意的序列化参数作为函数参数发往服务端。另一个是通过心跳事件发送恶意的序列化参数。
四、防御修复建议
可以看到,Dubbo不论是使用默认的Hessian2序列化,或配置Kryo序列化,均存在可被利用的风险。对于该类漏洞的防御,笔者也给出几点建议作为参考:
严格限制出网
由于目前已知的利用链大多利用JDNI注入攻击实现RCE,该种攻击要求远程加载恶意类,所以建议在不影响业务的前提下,将服务器配置出外网限制。
限制Dubbo服务端的访问
建议采用白名单IP或关闭公网访问端口的方式限制外部对Dubbo服务端的访问,减小风险暴露面。
为序列化/反序列化类设置白名单/黑名单
为Dubbo序列化协议设置白名单或黑名单,限制恶意类的反序列化,但是需要注意,黑名单的方式可能存在被绕过的风险。
本文分析了Dubbo序列化反序列化机制的安全性,希望通过本文的介绍能够帮助大家发现其更多的潜在的安全问题,从而完善他。如有不对或者不详尽的地方,也欢迎大家讨论指正。
- 0 文章数
- 0 关注者