


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
背景
之前一直使用的是BurpSuite 2023版,最近终于升级到了最新版本。升级后,我发现了一个新增加的“Bambdas mode”过滤Tab,这个功能允许用户通过Java代码块的方式来过滤日志。
奇怪的是,整个互联网关于这个新功能的介绍寥寥无几,几乎找不到相关的文章。然而我觉得这个功能还蛮好用的,可以用较低的内存占用就能完全实现我之前开发的burpsuite的过滤插件,因此感觉非常值得进一步深入研究一下。
注意:
⚠️ 由于Bambdas 可以运行任意代码。因此建议不要使用任意不了解的 Bambdas 语句
使用介绍
使用步骤
1.在Proxy > HTTP history选项卡 中,单击过滤栏以打开HTTP history filter窗口。
2.更改过滤器设置(如有必要)。
3.在HTTP HTTP history filter窗口 的顶部,单击转换为 Bambda。
如下图所示:

此外 Burpuite 还提供一个“Convert to Bambda”功能,可以将Settings mode 转为bambda代码。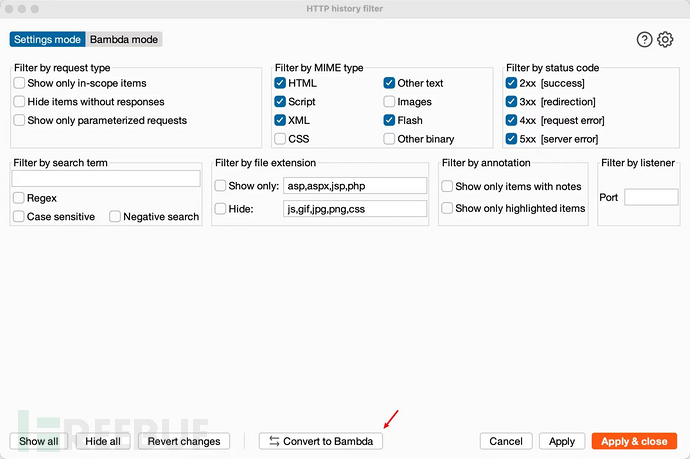
Bambdas模式与Settings模式的比较
| 特性 | Bambdas模式 | Settings模式 |
|---|---|---|
| 灵活性 | 高度自定义,支持复杂逻辑 | 基于简单配置,功能有限 |
| 过滤方式 | 支持多种自定义条件(如正则、数组等) | 通常只支持简单的IP、域名或方法过滤 |
| 代码支持 | 支持编写Java/Python代码进行处理 | 无法编写自定义代码 |
| 场景适用性 | 适用于复杂的渗透测试需求 | 适用于简单的请求筛选或过滤 |
| 用户知识要求 | 需要用户具有一定编程背景 | 不需要编码知识,配置简单 |
代码解释
在日常使用中,经常会遇到想忽略的的 HTTP 方法,例如 OPTIONS 、 HEAD 等方法。或者只想查看特定的方法。
String[] methodExclude = {"OPTIONS", "HEAD"};String method = requestResponse.request().method();return Arrays.stream(methodExclude).noneMatch(it -> method.contains(it));
代码解释:
String[] methodExclude = {"OPTIONS", "HEAD"};
定义需要排除的 HTTP 方法
通过定义字符串数组 methodExclude(可随机命名),包含了两个 HTTP 方法:"OPTIONS" 和 "HEAD"
String method = requestResponse.request().method();
获取请求方法
从 requestResponse 对象中获取当前 HTTP 请求的方法并将其存储在 method 变量中。
return Arrays.stream(methodExclude).noneMatch(it -> method.contains(it));
排除HTTP方法
Java 的流(Streams)API 来遍历 methodExclude 数组。
•Arrays.stream(methodExclude) 创建一个流,用于处理 methodExclude 数组中的元素。
•noneMatch(it -> method.contains(it)) 检查 method 字符串中是否不包含任何一个methodExclude 中的元素 it 。这里会依次判断 method 中是否包含 "OPTIONS" 或 "HEAD"。如果都不包含,noneMatch 将返回 true ,如果包含任一元素,则返回 false 。
使用场景示例
简单场景
1. 处理HTTP方法
1.过滤 OPTIONS 、 HEAD 方法
String[] methodExclude = {"OPTIONS", "HEAD"};
String method = requestResponse.request().method();
return Arrays.stream(methodExclude).noneMatch(it -> method.equals(it));
2.只看 POST 、GET 方法
//方式一
String[] methodInclude = {"POST", "GET"};
String method = requestResponse.request().method();
return Arrays.stream(methodInclude).anyMatch(it ->it.equalsIgnoreCase(method));
//方式二
String me//方式一thod =requestResponse.request().method();
return "POST".equalsIgnoreCase(method) || "GET".equalsIgnoreCase(method);
2. 过滤特殊站点
1.常规过滤
String[] domainExclude = {"baidu.com", "example.com", "mozilla.com"};
String host = requestResponse.request().httpService().host();
boolean isExcluded =
Arrays.stream(domainExclude).anyMatch(it -> it.equalsIgnoreCase(host));
return !isExcluded;
2.正则过滤
String[] domainExclude = {
"^baidu\\..*$", // 匹配以 baidu. 开头的任何域名
".*\\.example\\.com$", // 匹配任何以 example.com 结尾的域名
".*mozilla.*" // 匹配包含 mozilla 的任何域名
};
String host = requestResponse.request().httpService().host();
boolean isExcluded = Arrays.stream(domainExclude)
.map(Pattern::compile)
.anyMatch(pattern -> pattern.matcher(host).find());
return !isExcluded;
3.文件过滤
当我们需要过滤的域名太多了的时候,可以通过专门起一个 本地文件去记录,这样也方便后续的直接维护,此方法同时支持 正则域名、常规域名
baidu.com.*.wanyi.com.*.mozilla..*
List<Pattern> patterns = new ArrayList<>();
BufferedReader br = new BufferedReader(new FileReader("path/to/domainPatterns.txt"));
String line;
while ((line = br.readLine()) != null) {
line = line.trim();
if (!line.isEmpty() &- 0 文章数
- 0 关注者