


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

freebuf快速同步语雀文章
- 关注
freebuf快速同步语雀文章
1. 背景
日常笔记使用语雀记录文章,想要快速同步内容至freebuf,寻找已有工具无果,遂写了个工具方便快速同步文章。
2. 工具
# coding=gbk
import re
import requests
from urllib.parse import urlparse, parse_qs
import os
import urllib3
import time
# 禁用所有 SSL 相关的警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def uploadImg(imgFile):
upUrl = 'https://www.freebuf.com/fapi/frontend/upload/image'
#配置auth认真
auth = "Bearer eyY2FiMGMyMmJhMyIsInVpZCI6Mzc2Nzk1g2Wlw"
headers = {
"Accept":"application/json, text/plain, */*",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.0 Safari/537.36",
"X-Client-Type":"web",
"Origin":"https://www.freebuf.com",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://www.freebuf.com/write",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9"
# "Authorization" :auth
}
headers['Authorization'] = auth
# 配置上传流量到burp
# proxies = {"http":"http://127.0.0.1:8080","https":"http://127.0.0.1:8080"}
files = {'file':open(imgFile,'rb')}
rep = requests.post(upUrl, headers=headers,verify=False,files=files)
# rep = requests.post(upUrl, headers=headers,proxies=proxies,verify=False,files=files)
print(f"已完成图片{imgFile}的上传")
return(rep.json().get('data').get('url'))
def replaceImg(imgUrl):
rep = requests.get(imgUrl)
fileName = getFileName(imgUrl)
fileAllName = "./files/"+fileName
with open(fileAllName, 'wb') as file:
for chunk in rep.iter_content(chunk_size=8192): # 每次读取 8 KB 数据
file.write(chunk)
print(f"文件{fileAllName}已完成下载")
return(uploadImg(fileAllName))
def getFileName(imgUrl):
parsed_url = urlparse(imgUrl)
path = parsed_url.path
filename = os.path.basename(path)
return filename
def replaceMd(mdFile):
f = open(mdFile,'r',encoding='utf-8')
content = f.read()
urls = re.findall(r'https://cdn.nlark.com/yuque[\w/-]+.png', content)
for url in urls:
#配置延时避免速率太快被拦截
time.sleep(1)
replaceUrl = replaceImg(url)
content = re.sub(url,replaceUrl,content)
fo = open(mdFile+'_modify.md',"w")
fo.write(content)
fo.close()
f.close()
print(f"已完成图片上传,复制新md内容至freebuf即可{mdFile+'_modify.md'}")
#配置markdown名
replaceMd('upload.md')
3.开发思路
1.对语雀到处markdown文件进行分析,发现语雀文档内容缓存在cdn.nlark.com。直接粘贴至freebuf的markdown编辑器不解析图片。于是怀疑对域名做了过滤。
2.因此想的是,只需要把链接替换成freebuf地址或者其他存储桐即可。这里由于存储桶需要另外花钱,因此pass。于是开始分析freebuf上传接口。任意上传一张图片并且抓包
功能点:
请求包:
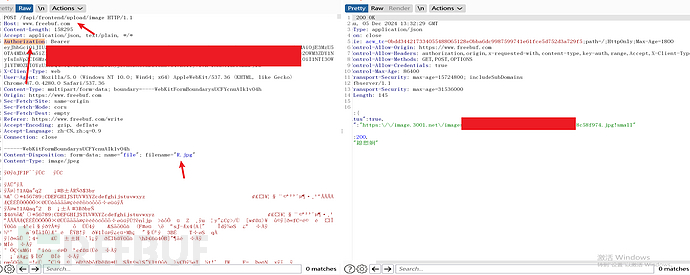
3.经过分析得出,上传认证只需要Authorization即可,利用该接口即可把本地图片传到云端。故而脚本开发流程如下:
- 正则匹配md内语雀资源url获取url列表
- 依次下载url资源至本地并且命名不变
- 使用freebuf上传接口依次上传图片,并且抓取返回的新url(这里暂时叫做new_url)
- 依次替换md中的url为new_url并且报错内容为xx_modify.md。
4.使用过程
1.语雀选择文章,点击导出Markdown格式
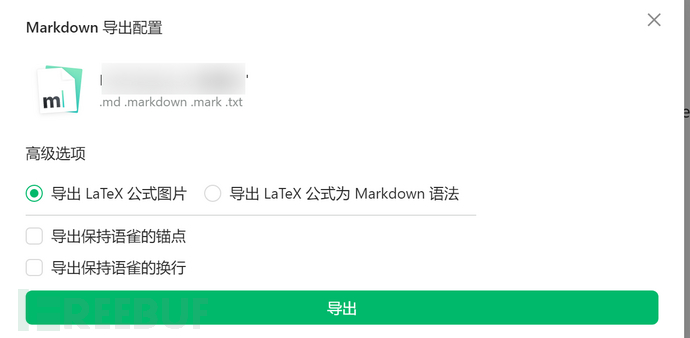
2.生产后把md文件放到freebuf.py同一个目录。并且本地创建一个files目录
3.配置py脚本,需要配置
auth="Bearer" #登录freebuf后,F12打开浏览器NETWORK并刷新,点击请求包即可获取请求头部参数。
replaceMd('upload.md')
4.python3 freebuf.py生成新的xx_modify.md文件,并且把新生成的md文件粘贴复制进入freebuf markdown编辑器即可。
备注
有的人可能文档资源在本地,也可以在该脚本基础上删除下载资源函数,并且修改正则匹配方法,即可获得本地上传脚本,这里就不多赘述了。
本文为 独立观点,未经允许不得转载,授权请联系FreeBuf客服小蜜蜂,微信:freebee2022
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
相关推荐
- 0 文章数
- 0 关注者