


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文主要知识点:
Bollte单文件模块框架
用sqlmapapi启动扫描的核心引擎engine_start()
在sqlmap/lib/utils/api.py的58行和60行处,我们可以发现从第三方插件thirdparty库中导入了发送get和post请求的库
from thirdparty.bottle.bottle import get
from thirdparty.bottle.bottle import post
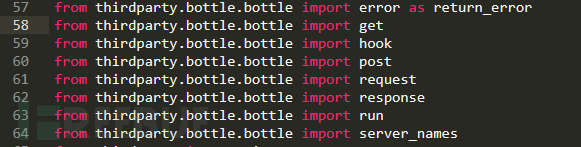
第三方插件bottle是Python的一个快速,简单和轻巧的WSGI微Web框架。它是个单文件模块bottle.py且不依赖其他Python标准库,它是构建静态和动态HTTP请求的关键所在,这个框架还是相对比较冷门的,不过够经典,在一些应用程序规模比较小的情况下可以实现快速简洁地开发。可惜相对于那些大型的web应用,Bottle还是显得有些无力,与Pylons(类似于Django和TurboGears)这类框架相比Bottle的优势就很难体现出来。
我们可以看到在sqlmap/lib/utils/api.py中,有相当多基于HTTP协议的接口,另外利用装饰器给各种函数提供了一个可靠的交互接口。
先用一段代码来快速地介绍这个单文件模块框架到底有多方便快捷。
from bottle import route, run, template
@route('/test/<name>')
def index(name):
return template('<b>各位大佬好,name接口参数为: {{name}}</b>!', name=name)
run(host='127.0.0.1', port=8888)
保存执行后即可看到效果,非常简单。
我们可以再用Bollte来实现简单登录业务。
@get('/login') #这里其实可以用 @route('/login')
def login():
html='''
<form action="/login" method="post">
Username: <input name="username" type="text" />
Password: <input name="password" type="password" />
<input value="Login" type="submit" />
</form>
'''
return html
@post('/login') #或者用 @route('/login', method='POST')
def do_login():
username = request.forms.get('username')
password = request.forms.get('password')
if check_login(username, password):#check_login()是一个用于检查密码正确性的自定义函数
return "<p>Your login information was correct.</p>"
else:
return "<p>Login failed.</p>"
可以发现整个代码非常的简洁就实现了登录界面,它的大致流程是**/login绑定了两个回调函数,一个回调函数响应GET请求,一个回调函数响应POST请求。如果浏览器使用GET请求访问/login,则调用login_form()函数来返回登录页面,浏览器使用POST方法提交表单后,调用login_submit()函数来检查用户有效性,并返回登录结果。**
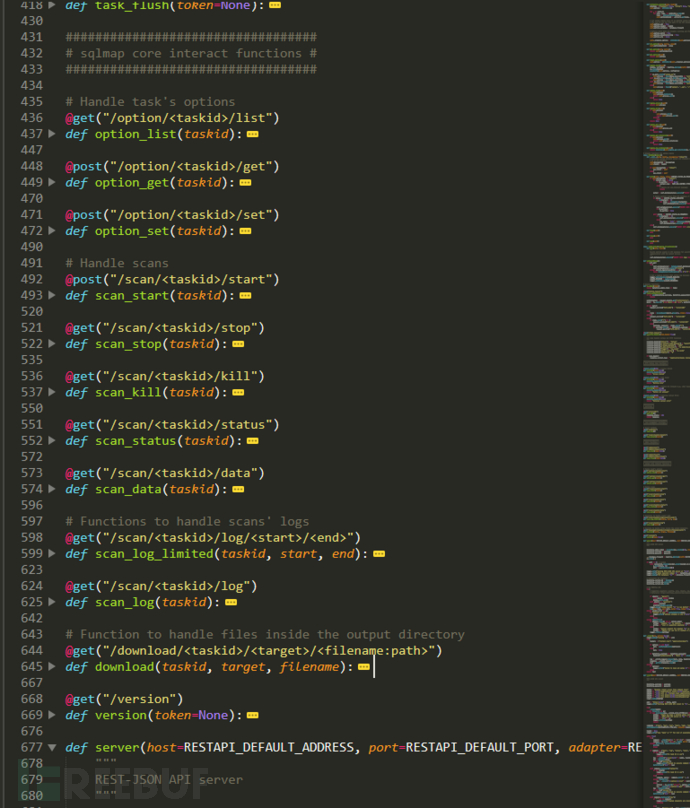
我们根据sqlmapapi提供的http交互接口可以知道用于启动扫描的接口是第492行的/scan//start,这个接口它绑定了一个回调函数scan_start()用于启动引擎来扫描注入。大概流程就是 user发送包含url等参数的post请求包给/scan//start接口(是从sqlmapapi中第369行@get("/task/new")的想拥抱中获取的),该接口调用scan_start(taskid)来启动扫描。
从上面我们不难得知:sqlmapapi发起扫描的关键就在于这个scan_start函数。
@post("/scan/<taskid>/start")
def scan_start(taskid):
"""
Launch a scan
"""
if taskid not in DataStore.tasks:
logger.warning("[%s] Invalid task ID provided to scan_start()" % taskid)
return jsonize({"success": False, "message": "Invalid task ID"})
if request.json is None:
logger.warning("[%s] Invalid JSON options provided to scan_start()" % taskid)
return jsonize({"success": False, "message": "Invalid JSON options"})
for key in request.json:
if key in RESTAPI_UNSUPPORTED_OPTIONS:
logger.warning("[%s] Unsupported option '%s' provided to scan_start()" % (taskid, key))
return jsonize({"success": False, "message": "Unsupported option '%s'" % key})
# Initialize sqlmap engine's options with user's provided options, if any
for option, value in request.json.items():
DataStore.tasks[taskid].set_option(option, value)
# Launch sqlmap engine in a separate process
DataStore.tasks[taskid].engine_start()
logger.debug("(%s) Started scan" % taskid)
return jsonize({"success": True, "engineid": DataStore.tasks[taskid].engine_get_id()})
jsonize是从第34行from lib.core.convert import jsonize过来的,追到sqlmap/lib/core/convert.py中看看
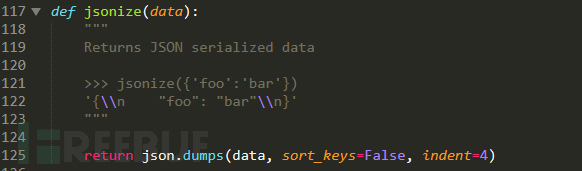
有点编程常识的一眼都能看出来,就是把data的数据当作json数据导出。
整个流程我翻译给各位讲一遍:
- 将接口中含有的(从get请求/task/new接口获取的)taskid作为scan_start函数的参数传入。
- 如果taskid不存在于DataStore.tasks这个字典里,输出警告日志“[taskid] 提供给 scan_start() 的任务 ID 无效”,并返回json数据{"success": False, "message": "Invalid task ID"}
- 如果请求包里的json数据为空,输出警告日志“[taskid] 提供给 scan_start() 的 JSON 选项无效”,并返回json数据{"success": False, "message": "Invalid JSON options"}
- 遍历请求包中的key,如果key在RESTAPI_UNSUPPORTED_OPTIONS(第52行 from lib.core.settings import RESTAPI_UNSUPPORTED_OPTIONS)中,则输出警告日志“"[taskid] 不支持的选项 key 提供给 scan_start()”,并返回json数据{"success": False, "message": "Unsupported option '%s'" % key}
- 遍历请求包中的键值,将参数作为选项存储到DataStore类中的字典tasks中。
- 将DataStore类中的字典tasks中存储的taskid用engine_start()方法启动
- 日志输出taskid扫描启动
- 返回json数据{"success": True, "engineid": DataStore.tasks[taskid].engine_get_id()}
不难看处,第5步之前一堆的if,在正确传入参数的情况下是不用考虑的
而在第6步可以明显的一个类方法engine_start(),启动引擎,应该就是整个sqlmapapi的核心了。
在166行处发现了engine_start,是作为类的方法运作的
def engine_start(self):
handle, configFile = tempfile.mkstemp(prefix=MKSTEMP_PREFIX.CONFIG, text=True)
os.close(handle)
saveConfig(self.options, configFile)
if os.path.exists("sqlmap.py"):
self.process = Popen([sys.executable or "python", "sqlmap.py", "--api", "-c", configFile], shell=False, close_fds=not IS_WIN)
elif os.path.exists(os.path.join(os.getcwd(), "sqlmap.py")):
self.process = Popen([sys.executable or "python", "sqlmap.py", "--api", "-c", configFile], shell=False, cwd=os.getcwd(), close_fds=not IS_WIN)
elif os.path.exists(os.path.join(os.path.abspath(os.path.dirname(sys.argv[0])), "sqlmap.py")):
self.process = Popen([sys.executable or "python", "sqlmap.py", "--api", "-c", configFile], shell=False, cwd=os.path.join(os.path.abspath(os.path.dirname(sys.argv[0]))), close_fds=not IS_WIN)
else:
self.process = Popen(["sqlmap", "--api", "-c", configFile], shell=False, close_fds=not IS_WIN)
不难看出,其实整个sqlmapapi的核心运行机制还是通过调用系统命令行去调用sqlmap发起注入扫描。
用三句话总结sqlmapapi对整体结构的处理机制:有条不紊,有条不紊,还是tmd有条不紊。
真的从哪都看不出sqlmapapi的开发者对于整个环境有特别着急处理的地方,反而运用了如Bottle单文件模块框架,环境判断机制,交叉引用,json响应包等来优化整体的兼容性和移动性以及合理性,并没有说像一些项目开发者毛毛躁躁地处理各类环境以及运行环节,这对开发者的要求还是比较高的。
sqlmapapi的分析差不多就到这,值得一说的是,分析sqlmap的时候还会略带分析一下sqlmapapi。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者