


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
简介
平时应急响应的时候可以利用一些小工具来使得工作事半功倍,看网上有一些比较优秀的web日志分析工具。用过一次奇安信的360星图日志分析工具,该款工具会根据内置的一些攻击规则生成分析报告。
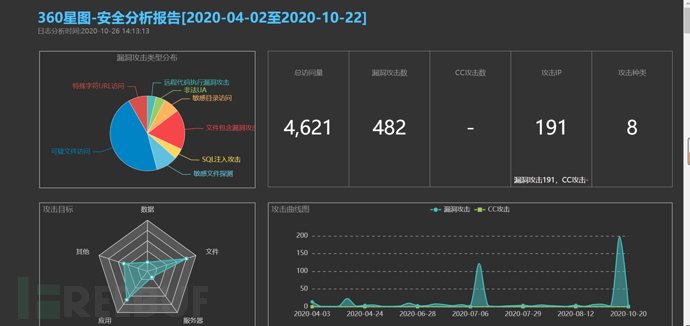
但是这个工具个性化还是有欠缺的,比如我想搜索网站日志状态码为404的,请求体中带有phpinfo的,所有就突发奇想写了一款自定义搜索网站日志功能小工具。
程序编写
程序编写总体思路分三部分,读取web日志文件、分析日志内容、根据分析结果生成对应报表。
读取日志
在读取日志时候我们时候使用sys.argv函数,该函数是从程序外部读取参数,程序在运行前将日志文件路径带入,增加程序易用性。使用open函数打开日志文件。
import re,sys,xlwt,requests weblog_dir=sys.argv[1] weblog = open(weblog_dir)
到这里我们已经完成日志文件读取操作了
日志分析
下面是一条web日志记录,日志内容的字段信息依次代表着:访问者来源ip、访问时间、http请求方法、请求地址、http状态码、本次请求的字节大小、refer信息、客户端ua标识。
162.158.187.123 - - [03/Apr/2020:10:43:01 +0800] "GET /phpMyAdmin/index.php HTTP/1.1" 404 263 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0"
因为生成的数据每条格式都一样,我们可以使用正则表达式来提取关键字段,python中可以使用re模块来实现正则功能。通过下面代码就可提权关键字段ip、time、request、status、bytes、referer、ua
reobj=re.compile(r'(?P<ip>.*?) - - \[(?P<time>.*?)\] "(?P<request>.*?)" (?P<status>.*?) (?P<bytes>.*?) "(?P<referer>.*?)" "(?P<ua>.*?)"')
处理数据的时候需要定义一个函数,函数需要传递2个参数,一个是搜索的字段,一个是要搜索的值。使用for x in y循环将y里面多行内容依次循环读出赋给x。使用正则表达模块中match函数进行匹配,groupdit函数是将结果生成字典。
def search(search_key,search_value):
for line in weblog:
re_result=reobj.match(line)
re_arry=re_result.groupdict()
if search_key == 'request':
if search_value in re_arry['request']:
print(re_arry)
else:
if re_arry[search_key]==search_value:
print(re_arry)
生成报告
可以将以上运行的结果存放到excel表格中,可以使用xlwt模块实现该功能。
xlwt.Workbook是创建excel表格函数,add_sheet函数是创建sheet工作表的函数。
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet("LessSafe安全团队web日志分析")程序多次调用写excel操作,所以可以定义一个write_xls函数。write是xlwt模块写入数据函数,带入的三个参数分别代表行、列、数据
def write_xls(re_ipadd,ip,time,request,status,bytes,referer,ua,row):
worksheet.write(row, 0, re_ipadd)
worksheet.write(row, 1, ip)
worksheet.write(row, 2, time)
worksheet.write(row, 3, request)
worksheet.write(row, 4, status)
worksheet.write(row, 5, bytes)
worksheet.write(row, 6, referer)
worksheet.write(row, 7, ua)总结
本项目整体代码地址:https://github.com/lesssafe/WebLogAnalysis
在平时应急响应的时候可以根据自己业务特点进行代码修改、扩展,本文章只提供一个思路,在后期可以增加很多功能,比如根据业务特点写一个IDS库。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者