


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 Alpha_h4ck
Alpha_h4ck- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9

功能介绍
SourceWolf是一款功能强大的针对源代码安全的快速响应式爬虫工具,该工具基于Python语言开发,因此具备良好的跨平台性。该工具的当前版本拥有以下功能:
通过发送请求或从本地响应文件(如果有)爬取隐藏节点;
可根据源代码中爬取的数据创建JavaScript变量列表;
从网站中提取所有社交媒体链接,以识别潜在的坏链;
使用字典文件爆破主机;
获取URL列表的状态代码/从主机列表中筛选出活动域;
值得一提的是,上述提到的这些功能都能够以非常快的速度执行。首先,SourceWolf使用了requests库中的Session模块,这也就意味着,它能够复用TCP连接,以实现速度提升。其次,SourceWolf提供的选项可以帮助我们爬取本地响应文件,这样就无需向终端节点发送请求了。第三,终端节点的信息非常完整,比如说工具提供的是https://example.com/api/admin,而非/api/admin,这一点对于扫描主机列表来说非常实用。
工具安装
首先,广大研究人员可以通过下列命令将项目源码克隆至本地:
git clone https://github.com/micha3lb3n/SourceWolf.git
或者直接点击【这里】获取该工具的最新发布版本。
接下来,切换到本地项目目录:
cd SourceWolf/
最后,使用下列命令安装工具的依赖组件:
pip3 install -r requirements.txt
工具使用
> python3 sourcewolf.py -h
-l LIST, --list LIST List of javascript URLs
-u URL, --url URL Single URL
-t THREADS, --threads THREADS
Number of concurrent threads to use (default 5)
-o OUTPUT_DIR, --output directory-name OUTPUT_DIR
Store URL response text in a directory for further analysis
-s STATUS_CODE_FILE, --store-status-code STATUS_CODE_FILE
Store the status code in a file
-b BRUTE, --brute BRUTE
Brute force URL with FUZZ keyword (--wordlist must also be used along with this)
-w WORDLIST, --wordlist WORDLIST
Wordlist for brute forcing URL
-v, --verbose Verbose mode (displays all the requests that are being sent)
-c CRAWL_OUTPUT, --crawl-output CRAWL_OUTPUT
Output directory to store the crawled output
-d DELAY, --delay DELAY
Delay in the requests (in seconds)
--timeout TIMEOUT Maximum time to wait for connection timing out (in seconds)
--headers HEADERS Add custom headers (Must be passed in as {'Token': 'YOUR-TOKEN-HERE'}) --> Dictionary format
--cookies COOKIES Add cookies (Must be passed in as {'Cookie': 'YOUR-COOKIE-HERE'}) --> Dictionary format
--only-success Only print 2XX responses
--local LOCAL Directory with local response files to crawl for
--no-colors Remove colors from the output
--update-info Check for the latest version, and update if requiredSourceWolf提供了三种运行模式,分别对应的是该工具的三大核心功能。
爬取响应模式
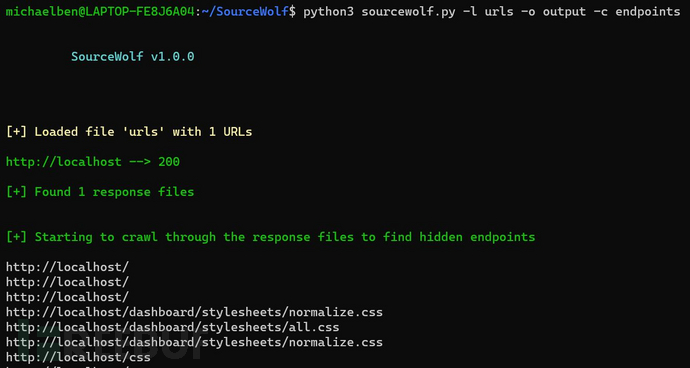
完整使用:
python3 sourcewolf.py -l domains -o output/ -c crawl_output
domains是待爬取的目标URL列表,其格式如下:
https://example.com/ https://exisiting.example.com/ https://exisiting.example.com/dashboard https://example.com/hitme
output/是存储输入文件对应响应文件的目录,存储格式output/2XX、output/3XX、output/4XX和output/5XX,其中output/2XX对应的是2XX响应状态码,其他以此类推。
-c参数指定的crawl_output可以用来存储爬取输出结果,SourceWolf生成的HTTP响应文件爬取结果将存储在该路径下。
crawl_output/目录中包含下列内容:
终端节点:所有爬取到的终端节点; JavaScript变量:所有爬取到的JavaScript变量;
扫描单一URL:
python3 sourcewolf.py -u example.com/api/endpoint -o output/ -c crawl_output
这里,只需要用-u参数替换刚才的-l参数即可,其他保持不变。
爆破模式
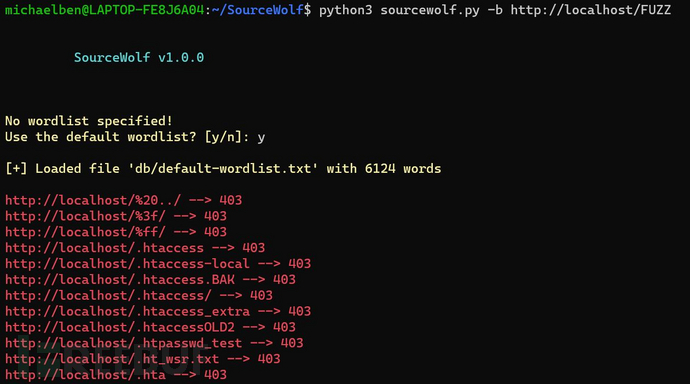
python3 sourcewolf.py -b https://hackerone.com/FUZZ -w /path/to/wordlist -s status
-w参数是一个可选项,如果不指定,它将使用默认字典(包含6124个单词)。
使用-b参数,SourceWolf将会替换掉FUZZ关键词并发送请求,这样将允许我们对GET参数值进行爆破。
-s参数将会把输出数据存储在一个名为status的文件中。
探测模式
python3 sourcewolf -l domains -s live
domains文件可以包含子域名、终端节点和JavaScript文件。
-s参数会将响应写入live文件中。
SourceWolf同样支持多线程运行,所有模式下的默认线程数为5,我们也可以使用-t参数来增加线程数。
如果你需要将所有的响应存储到一个目录(比如说responses/)中,可以运行下列命令:
python3 sourcewolf.py --local responses/
工具更新
广大研究人员可以直接在命令行终端更新SourceWolf,而无需重新克隆项目源码。SourceWolf能够在每次运行之间自动检测版本更新,并提醒用户是否需要更新:
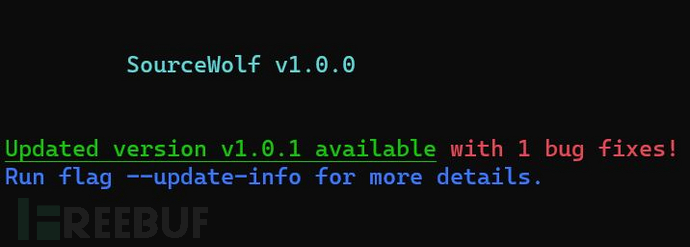
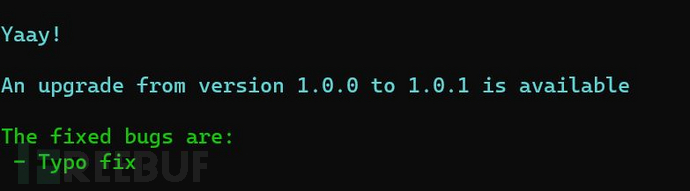
或者,也可以使用下列命令查看更新详情:
python3 sourcewolf.py --update-info
许可证协议
本项目的开发与发布遵循MIT开源许可证协议。
项目地址
SourceWolf:【GitHub传送门】
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 渗透实战优质工具
渗透实战优质工具





- 2359 文章数
- 1020 关注者