


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
前言:脚本和文档都是老早就写好的,这周发现fofa新版出来了,就把旧版的薅羊毛完整脚本分享给大家。文章主要是介绍这种脚本的编写思路,给编程新手提供一个思路参考,比起 requests+re 我更推荐大家使用 requests+bs4 获取信息。
脚本语言:python2.7
白嫖与付费
付费肯定有更好的服务,但是就是喜欢薅羊毛的快乐。能付费尽量付费吧,如果你付费了这个脚本使用起来更安逸。
非api原因
根据网站vip功能介绍,可以看到“注册用户”和“普通会员”使用api都是亏本买卖,如果想用api就开svip才最安逸

Fofa与BeautifulSoup
Fofa的搜索语法
返回头 header="200"
国家 country="CN"
页面内容 body="phpweb"
网页头 title="公司"
端口 port="443"
网站年份 after="2020-01-01"
BeautifulSoup库
注:一般搭建好网站不会轻易更改网页标签类型,所以使用标签提取比正则匹配能让脚本“活得更久”
定位网页标签
soup.find(name="input", attrs={"id": "total_entries"}) soup.find_all(name="div", attrs={"class": "list_mod"})获取标签值
yourdiv.attrs['value']获取ul内的li值
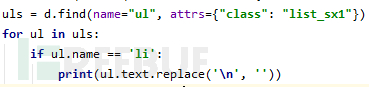
执行搜索操作
打开fofa官网https://fofa.so/,搜索热门关键字,可以看到url请求为
https://fofa.so/result?qbase64=xxx
其中qbase64的值就是搜索字符串“base64编码+url编码”的结果,这里需要注意中文问题,需要将中文先gbk解码,再用base64库编码(我本机是gbk编码,所以输入的中文也是gbk编码,如果你的机器是utf-8编码就改为utf-8,没测)
code = key.decode()
code = urllib.quote(base64.b64encode(code))这里遇到个问题一直没整明白,上面那种方式可以成功,但是下面这种使用方式却失败了,如果有人知道原因请留言或私信给我。
code = urllib.quote(base64.b64encode(key.decode('gbk')))代码
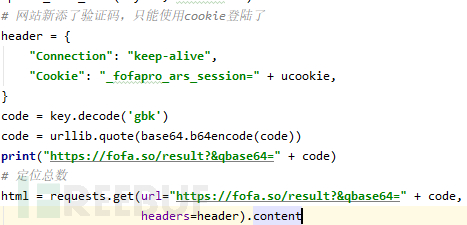
获取页面搜索结果
使用浏览器自带调试功能查看html框架,可以看到我们搜索结果都在“<div>”标签下,每一个“<divclass="list_mod">”标签是一条信息
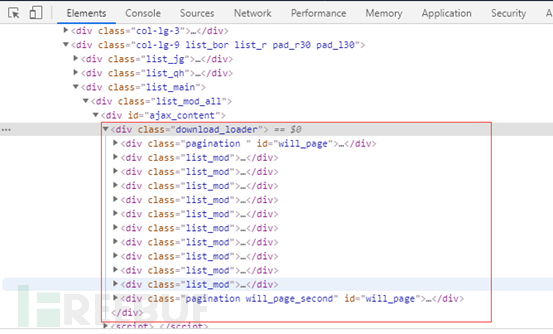 一个list_mod标签包含一个目标的全部信息
一个list_mod标签包含一个目标的全部信息
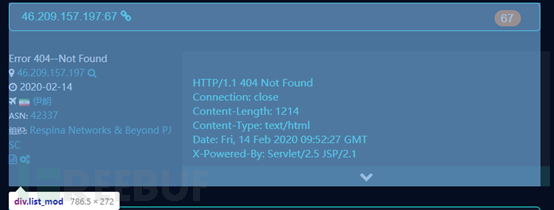 代码,其中divs就是全部目标列表
代码,其中divs就是全部目标列表

定位单条目标信息
选取单个目标的标签点开分析,可以看到标签有list_mod_t和list_mod_c两个子标签
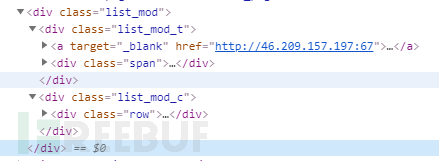 而元素a就是可以直接跳转的链接,从这里提取到目标的url或者IP
而元素a就是可以直接跳转的链接,从这里提取到目标的url或者IP

 而目标下面的介绍其实是一个ul列表,这部分信息也比较重要,所以我也提取了
而目标下面的介绍其实是一个ul列表,这部分信息也比较重要,所以我也提取了
代码
 其中列表信息没做详细分类提取,也没有把他写入到文件,内存里长这样
其中列表信息没做详细分类提取,也没有把他写入到文件,内存里长这样
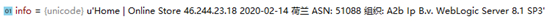
关于URL存活状态
在单个目标的右边有他的响应码,我是根据这个来确定的存活,当然你也可以自己请求一下提取的URL来判断存活,如果只需要200的网站就在查询时使用header="200";代码中获取的是右侧整个字符串,大家根据需要自行修改代码就行
 代码
代码
翻页问题
我们知道目标总数除以10后加1就是页数,所以要提取目标总数,依旧是根据网页标签定位提取数据
 代码如下
代码如下

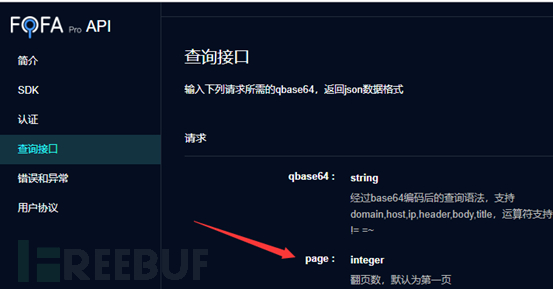
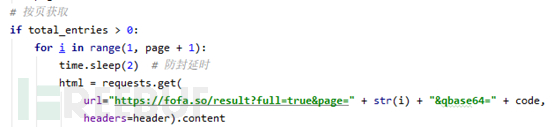
知道总页数怎么翻页呢?
通过api规则知道请求中的page参数决定当前页面(或者看网页【下一页】的链接),测试中发现有请求频率限制,做下防封延时就行

 代码如下
代码如下
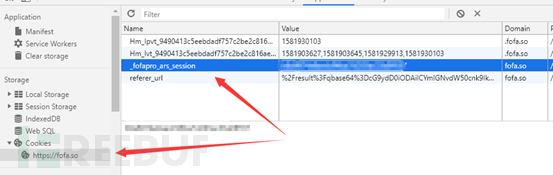
网站cookie
Fofa现在登陆需要进行验证了,无法直接用户名密码登陆,所以我使用的cookie验证身份。
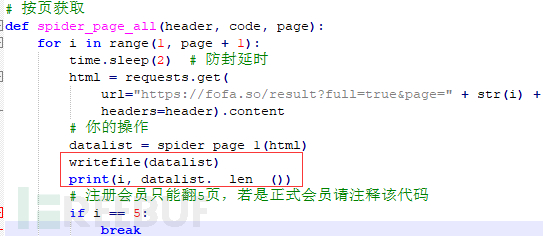
自定义数据输出
在按页获取函数中修改数据处理方式,解除注册会员限制
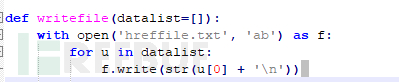
 脚本中是将链接追加到指定txt文件中,其它信息只是获取了,并没有输出
脚本中是将链接追加到指定txt文件中,其它信息只是获取了,并没有输出
脚本使用
使用命令参数输入关键字和cookie,会输出总数,提示每页有多少条存活,其他信息输出自行修改脚本
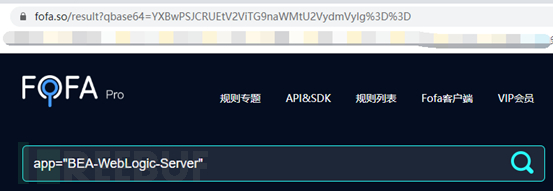
注意titile、app等使用方法,如果网页搜索栏是这样的
app="BEA-WebLogic-Server"
那么命令行这样输入
"app=\"BEA-WebLogic-Server\""
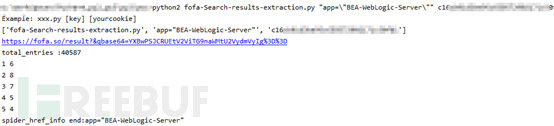 输出总数和网页搜索总数一致(没有带国家参数)
输出总数和网页搜索总数一致(没有带国家参数)
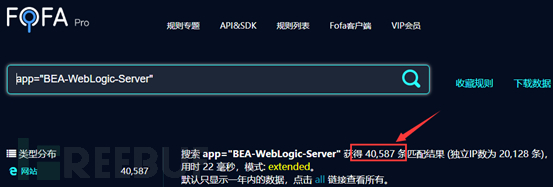 Hreffile.txt内容
Hreffile.txt内容
完整代码
代码已上传 aHR0cHM6Ly9naXRodWIuY29tL21veXV3YS9mb2ZhLXNlYXJjaC1yZXN1bHQtcmVx
注册会员,通过城市枚举和搜索条件定义,能薅200~400条数据吧,足够大家学习完漏洞后做实践了,相关漏洞差不多能有1/15的存在比例。
其实有想过获取页面左侧的城市信息,但是太麻烦了就无脑枚举了,后续大家可以做做”url去重“和”自定义存活确认(有的url访问过去就是网站自定义404页面)“。
*本文作者:难再见,转载请注明来自FreeBuf.COM
- 0 文章数
- 0 关注者