


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 madneal
madneal- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
madneal 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
madneal 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
Zeek (Bro) 是一款大名鼎鼎的开源网络安全分析工具。通过 Zeek 可以监测网络流量中的可疑活动,通过 Zeek 的脚本可以实现灵活的分析功能,可是实现多种协议的开相机用的分析。本文主要是将 Zeek 结合被动扫描器的一些实践的介绍,以及 Zeek 部署的踩过的一些坑。
安装
Zeek 的安装还是比较简单的,笔者主要是在 Mac 上以及 Linux 上安装。这两个操作系统的安装方式还是比较类似的。对于 Linux 而言,需要安装一些依赖包:
sudo yum install cmake make gcc gcc-c++ flex bison libpcap-devel openssl-devel python-devel swig zlib-devel
这里我有遇到一个问题就是可能你的 Redhat 镜像源里面没有包含 libpcap-devel,因为这个包在可选的范围内,而内网的服务器又没有互联网连接。可以通过手工下载相应版本的 libpcap 以及 libpcap-devel 即可。
Mac 上需要的依赖更少一点,首先需要确保安装了 xcode-select,如果没有安装,可以通过 xcode-select --install 来进行安装。Mac 上只需要安装依赖 cmake, swig, openssl, bison 即可,可以通过 Homebrew 来进行安装。
依赖包安装完毕之后就可以安装 Zeek,其实是可以通过包管理工具来进行安装的,不过这里我推荐使用基于源码的安装方式,安装比较简单而且还容易排查问题。从 Zeek 的 Github Release 即可下载源码包,目前我安装的是 3.0.0 版本,注意一点是,如果使用最新的版本,可能需要 7.0 以上版本的 cmake,因为需要 C++17 的语言特性。而一般镜像源默认的 cmake 版本是4+版本,所以如果你的服务器也无法上互联网,建议可以安装 3.0.0 版本。
./configure & make & make install
安装使用上面的命令就可以了,不过 make 的时间还是比较长的,这个取决于你机器的性能,不过一般安装还是需要半个小时到一个小时,这也是因为 C++ 编译速度比较慢的原因。
集群安装
集群安装的方式和单机的方式不太一样。之前在测试环境使用的都是单机模式,集群则可以管理多个实例,后来我也尝试了通过集群的方式来进行安装。如果需要配置集群的话,建议安装 PF_RING,PF_RING 可以加速网络包的速度。对于 Zeek 集群上的每个 worker 都是需要安装 PF_RING,但只需要在 manager 上安装 Zeek 就可以了,可以通过 zeekctl 在其它 worker 上安装 Zeek。不过需要确保可以通过 ssh 到其它 woker 机器上,可以通过公钥的形式来实现,将 manager 的公钥放到其它 worker 的 authorized_keys 中。
PF_RING 的安装步骤相对来说多了一些,但也是按照说明安装即可。和上面的单机安装方式不同的是集群安装的方式的时候,安装 Zeek 需要配置前缀。
安装 PF_RING
tar xvzf PF_RING-5.6.2.tar.gz
cd PF_RING-5.6.2/userland/lib
./configure --prefix=/opt/pfring
make install
cd ../libpcap
./configure --prefix=/opt/pfring
make install
cd ../tcpdump-4.1.1
./configure --prefix=/opt/pfring
make install
cd ../../kernel
make
make install
modprobe pf_ring enable_tx_capture=0 min_num_slots=32768
安装 Zeek
./configure --with-pcap=/opt/pfring
make
make install
确保 Zeek 正确关联到了 PF_RING 中的 libpcap 库中
ldd /usr/local/zeek/bin/zeek | grep pcap
libpcap.so.1 => /opt/pfring/lib/libpcap.so.1 (0x00007fa6d7d24000)
接着就是通过 PF_RING 来进行 Zeekctl 的配置,Zeek 的安装路径一般都在 /usr/local/zeek。通过 /usr/local/zeek/etc/node.cfg 来进行集群结点的配置,在集群配置中,manager, proxy 以及 worker 是必须的,如果不设置 logger,默认将 manager 作为 logger。
[worker-1]
type=worker
host=10.0.0.50
interface=eth0
lb_method=pf_ring
lb_procs=10
pin_cpus=2,3,4,5,6,7,8,9,10,11
接下来只需要通过 zeekctl install 就会在其它实例上来进行安装了。如果安装过程中出现了问题,可以通过 zeekctl diag woker-1 来排查具体的原因。
Zeek 结合被动扫描器的玩法
上面讲的都是 Zeek 的安装,下面聊一下 Zeek 和被动扫描器的结合。被动扫描器的效果往往取决于流量的质量和数量,在我们的实际实践中,发现通过 Zeek 获取的流量占我们被动扫描器测试流量的绝大一部分。Zeek 对于 http 解析的日志都会存储在 /usr/local/zeek/logs 中。如果 Zeek 是启动状态,那么 http.log 的路径会在 /usr/local/zeel/logs/current 中,而历史日志则会被打包。如果使用 Zeek 去捕获流量的时候,日志往往会占很大的存储,所以要记得修改 Zeek 日志的存储路径,否则很容易就把系统盘塞满。
通过脚本自定义 http.log
http.log 中其实已经包含了丰富的字段,常见的一些字段如下:
# ts uid orig_h orig_p resp_h resp_p
1311627961.8 HSH4uV8KVJg 192.168.1.100 52303 192.150.187.43 80
不过里面还有一些信息是缺失的,比如一些 http 请求头以及 POST 请求的请求体,为了添加这些字段,可以通过自定义 Zeek 脚本来实现,Zeek 脚本的能力真的非常强大,通过脚本其实有很多更高级的玩法。
添加请求头
@load base/protocols/http/main
module HTTP;
export {
redef record Info += {
header_host: string &log &optional;
header_accept: string &log &optional;
header_accept_charset: string &log &optional;
header_accept_encoding: string &log &optional;
header_accept_language: string &log &optional;
header_accept_ranges: string &log &optional;
header_authorization: string &log &optional;
header_connection: string &log &optional;
header_cookie: string &log &optional;
header_content_length: string &log &optional;
header_content_type: string &log &optional;
};
}
event http_header(c: connection, is_orig: bool, name: string, value: string) &priority=3
{
if ( ! c?$http )
return;
if ( is_orig )
{
if ( log_client_header_names )
{
switch ( name ) {
case "HOST":
c$http$header_host = value;
break;
case "ACCEPT":
c$http$header_accept = value;
break;
case "ACCEPT-CHARSET":
c$http$header_accept_charset = value;
break;
case "ACCEPT-ENCODING":
c$http$header_accept_encoding = value;
break;
case "ACCEPT-LANGUAGE":
c$http$header_accept_language = value;
break;
case "ACCEPT-RANGES":
c$http$header_accept_ranges = value;
break;
case "AUTHORIZATION":
c$http$header_authorization = value;
break;
case "CONNECTION":
c$http$header_connection = value;
break;
case "COOKIE":
c$http$header_cookie = value;
break;
case "CONTENT-LENGTH":
c$http$header_content_length = value;
break;
case "CONTENT-TYPE":
c$http$header_content_type = value;
break;
}
}
}
}
添加 POST 请求体
export {
## The length of POST bodies to extract.
const http_post_body_length = 200 &redef;
}
redef record HTTP::Info += {
postdata: string &log &optional;
};
event log_post_bodies(f: fa_file, data: string)
{
for ( cid in f$conns )
{
local c: connection = f$conns[cid];
if ( ! c$http?$postdata )
c$http$postdata = "";
# If we are already above the captured size here, just return.
if ( |c$http$postdata| > http_post_body_length )
return;
c$http$postdata = c$http$postdata + data;
if ( |c$http$postdata| > http_post_body_length )
{
c$http$postdata = c$http$postdata[0:http_post_body_length] + "...";
}
}
}
event file_over_new_connection(f: fa_file, c: connection, is_orig: bool)
{
if ( is_orig && c?$http && c$http?$method && c$http$method == "POST" )
{
Files::add_analyzer(f, Files::ANALYZER_DATA_EVENT, [$stream_event=log_post_bodies]);
}
}
通过上述的脚本就可以添加一些请求头以及 POST 请求的请求体,完整的脚本可以参考 http-custom。脚本编写完毕,需要通过 zeekctl 部署才能生效,步骤也非常简单。
mv http-custom /usr/local/bro/share/bro/base/protocols
echo '@load base/protocols/http-custom' >> /usr/local/bro/share/bro/site/local.bro
zeekctl deploy
对于被动扫描器,我们目前的方案是通过 Filebeat 去采集日志然后输出给 Logstash 做处理,处理完毕之后再输出到 Kafka。
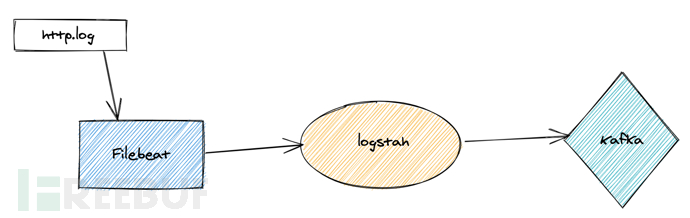
Filebeat 加 Logstash 适用于多种场景,在日常的各种日志采集场景都能派上用场。通过 Logstash 可以完成日志灵活的处理,因为 Logstash 里面包含了各种丰富的插件,几乎可以完成对于日志的任何操作。比如为了保证 POST 请求体保证传输的正确性,可以通过 base64 来进行编码。通过 logstash-filter-base64 可以遍历地实现字段的编码或者解码。通过 filter 中的 mutate 插件可以增加字段或者删除字段。
base64 {
field => "postdata"
action => "encode"
}
通过这种方案还有一个优势就是我们还可以将我们的日志输出到别的地方,比如 es,这个也可以方便后续排查日志问题。
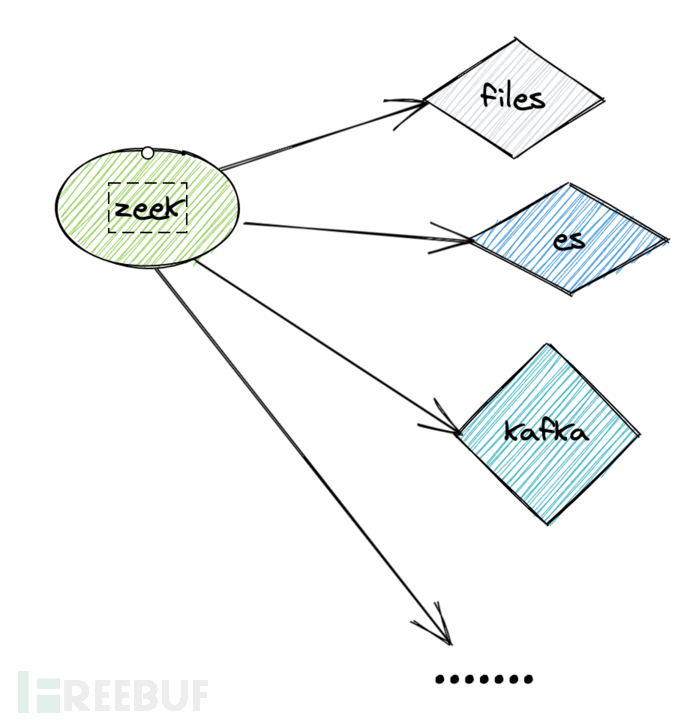
不过我在后面又发现了一种新的方案,可以通过 Zeek 的插件,将 http.log 直接输出到 Kafka,这个方案的优点主要是更高效,同时也节省了一些成本,毕竟 Logstash 需要的机器性能还是比较大的。对于这个方案主要是两个问题,第一个问题是首先需要处理好日志的格式,这样保证后续处理地便利性;第二个问题是如何将日志直接从 Zeek 输出到 Kafka。其实我是先解决了第一个问题再解决第二个问题的,因为第二个问题的处理的方式更灵活,得益于 Zeek 脚本的便利性,肯定是可以实现的。
metron-bro-plugin-kafka 是 Apache 官方的一个 Bro 的插件,不过因为 Zeek3.0.0 是可以兼容的,所以这个插件是可以使用的。这个插件有两种安装方式,一种是通过 bro-pkg (Bro 的官方包管理工具)来进行安装,另外一种则是通过手工安装。由于网络的原因,我更推荐使用手工安装的方式,我尝试通过 bro-pkg 的方式来进行安装,速度特别慢。
安装 librdkafka
curl -L https://github.com/edenhill/librdkafka/archive/v0.11.5.tar.gz | tar xvzcd librdkafka-0.11.5/
./configure --enable-sasl
make
sudo make install
安装插件
./configure --bro-dist=$BRO_SRC
make
sudo make install
这里有一个坑就是安装文档根本就没有说 $BRO_SRC 是哪个路径,所以安装的时候总是报错,后来才弄清楚这个路径其实就是当初 Zeek 解压后的路径,即 Zeek 安装包的路径。
验证结果
zeek -N Apache::Kafka
Apache::Kafka - Writes logs to Kafka (dynamic, version 0.3)
接着就是将 http 的日志进行处理,因为在原始的 http.log 中有还多字段是我们并不需要的。在研究了官方文档之后,可以通过 Filters 可以定义一个新的日志文件,可以拷贝其它的日志输出到新的文件,可以自定义字段,方式比较灵活。另外还可以通过 Writer 可以将日志写入到 sqlite 数据库中。不过,这里我们主要是通过插件将日志写入到 Kafka。
我们的目标是获取 http.log 中的部分字段,所以可以通过 Filters 来实现日志文件的复制并且对日志字段进行过滤,基于 KafkaWriter 将日志文件直接写入到 Kafka 中。为了定义 Filter,在 /usr/local/zeek/share/zeek/base/protocols/http/main.zeek 的 zeek_init 函数中进行定义:
event zeek_init() &priority=5
{
Log::create_stream(HTTP::LOG, [$columns=Info, $ev=log_http, $path="http"]);
Analyzer::register_for_ports(Analyzer::ANALYZER_HTTP, ports);
local filter: Log::Filter =
[
$name="kafka-http",
$include=set("host","id.resp_p","uri"),
$writer=Log::WRITER_KAFKAWRITER
];
Log::add_filter(HTTP::LOG, filter);
}
另外,记得在 /usr/local/zeek/share/zeek/site/local.zeek 中定义 Kafka 的 topic 和 Broker:
redef Kafka::topic_name = "bro-test";
redef Kafka::kafka_conf = table(
["metadata.broker.list"] = "127.0.0.1:9092"
);
最后记得使用 zeekctl deploy 重新部署一下,这样脚本就生效了,日志就可以直接写入到 Kafka 中,大大提高效率。
总结
其实 Zeek 有很多高级玩法,你完全可以将 Zeek 改造成一个 IDS 产品。Zeek 脚本的强大能力赋予其无限的可能性,比如在流量中发现 sql 注入。本文主要就是就 Zeek 的安装部署以及结合被动扫描器的一些用法的介绍。后续如果更进一步地探索,会做更多的分享。
*本文作者:madneal@平安银行应用安全团队,转载 请注明来自FreeBuf.COM
已在FreeBuf发表 7 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 渗透测试
渗透测试
 冷兵器
冷兵器





- 7 文章数
- 17 关注者