


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

前言
本人是一名立志安全开发的大学生,有一年安全测试经验,有时在刷src的时候,需要检查所有target的web业务系统是否泄露敏感目录、文件,工作量十分庞大,于是Dirmap诞生了~
知名的web目录文件扫描工具有很多,如:御剑1.5、DirBuster、Dirsearch、cansina。
其他开源的各种轮子,更是数不胜数。
这次我们不造轮子,我们需要造的是一辆车!open source的那种XD

需求分析
何为一个优秀的web目录扫描工具?
经过大量调研,总结一个优秀的web目录扫描工具至少具备以下功能:
并发引擎
能使用字典
能纯爆破
能爬取页面动态生成字典
能fuzz扫描
自定义请求
自定义响应结果处理...
功能特点
你爱的样子,我都有,小鸽鸽了解下我吧:
支持n个target*n个payload并发
支持递归扫描
支持自定义需要递归扫描的状态码
支持(单|多)字典扫描
支持自定义字符集爆破
支持爬虫动态字典扫描
支持自定义标签fuzz目标url
自定义请求User-Agent
自定义请求随机延时
自定义请求超时时间
自定义请求代理
自定义正则表达式匹配假性404页面
自定义要处理的响应状态码
自定义跳过大小为x的页面
自定义显示content-type
自定义显示页面大小
按域名去重复保存结果
扫描效果
递归扫描
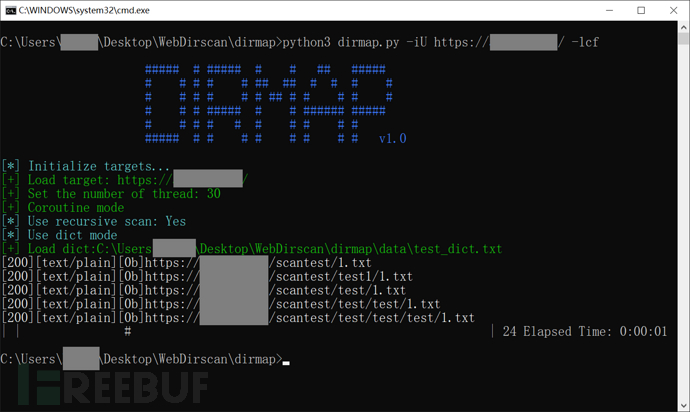
字典模式
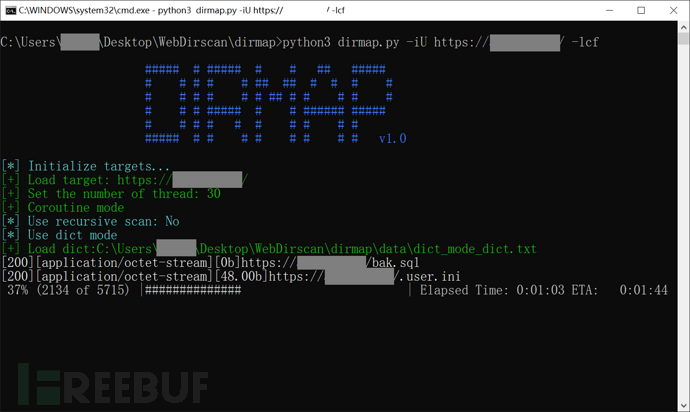
爆破模式
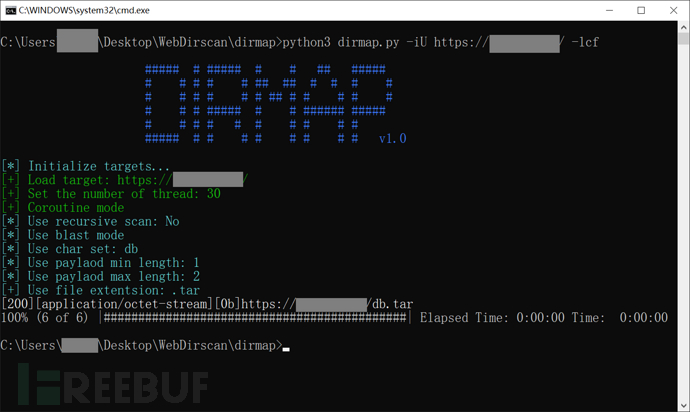
爬虫模式
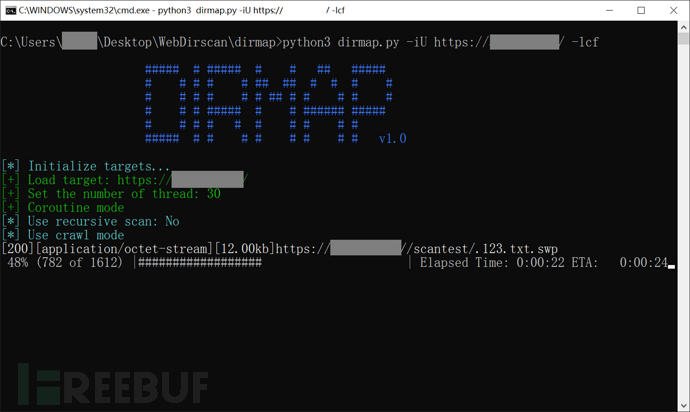
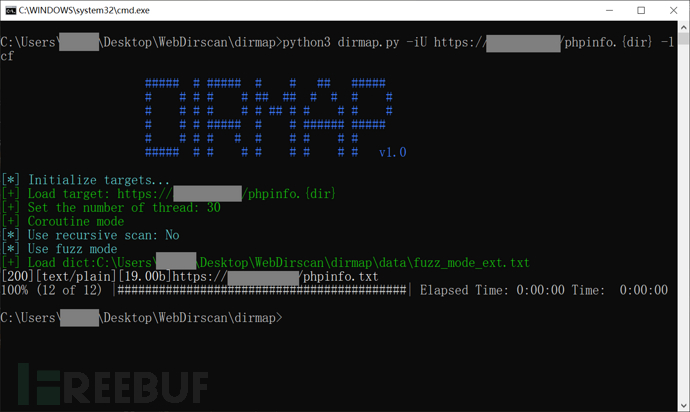
fuzz模式
Q:这么棒棒呀!那Dirmap该怎么使用呢?
A:啊哈,你往下滑。
使用方法
环境准备
git clone https://github.com/H4ckForJob/dirmap.git && cd dirmap && python3 -m pip install -r requirement.txt
快速使用
单个目标
python3 dirmap.py -iU https://target.com -lcf
多个目标
python3 dirmap.py -iF urls.txt -lcf
Q:哎呀,扫描结束了,我的结果呢qwq?
A:莫慌自动保存的呀。
结果保存
结果将自动保存在项目根目录下的output文件夹中,每一个目标生成一个txt,命名格式为目标域名.txt。结果自动去重复,不用担心产生大量冗余。
Q:矮油,不错呦,但是我还想学习下高级用法呢。
A:好嘞,这就来,屏住呼吸,往下看。
高级使用
自定义dirmap配置,开始探索dirmap高级功能,暂时采用加载配置文件的方式进行详细配置,不支持使用命令行参数进行详细配置!
编辑项目根目录下的dirmap.conf,进行配置。
dirmap.conf配置详解:
#递归扫描处理配置
[RecursiveScan]
#是否开启递归扫描:关闭:0;开启:1
conf.recursive_scan = 0
#遇到这些状态码,开启递归扫描。默认配置[301,403]
conf.recursive_status_code = [301,403]
#设置排除扫描的目录。默认配置空。其他配置:e.g:['/test1','/test2']
#conf.exclude_subdirs = ['/test1','/test2']
conf.exclude_subdirs = ""
#扫描模式处理配置(4个模式,1次只能选择1个)
[ScanModeHandler]
#字典模式:关闭:0;单字典:1;多字典:2
conf.dict_mode = 1
#单字典模式的路径
conf.dict_mode_load_single_dict = "dict_mode_dict.txt"
#多字典模式的路径,默认配置dictmult
conf.dict_mode_load_mult_dict = "dictmult"
#爆破模式:关闭:0;开启:1
conf.blast_mode = 0
#生成字典最小长度。默认配置3
conf.blast_mode_min = 3
#生成字典最大长度。默认配置3
conf.blast_mode_max = 3
#默认字符集:a-z。暂未使用。
conf.blast_mode_az = "abcdefghijklmnopqrstuvwxyz"
#默认字符集:0-9。暂未使用。
conf.blast_mode_num = "0123456789"
#自定义字符集。默认配置"abc"。使用abc构造字典
conf.blast_mode_custom_charset = "abc"
#自定义继续字符集。默认配置空。
conf.blast_mode_resume_charset = ""
#爬虫模式:关闭:0;开启:1
conf.crawl_mode = 0
#解析robots.txt文件。暂未实现。
conf.crawl_mode_parse_robots = 0
#解析html页面的xpath表达式
conf.crawl_mode_parse_html = "//*/@href | //*/@src | //form/@action"
#是否进行动态爬虫字典生成:关闭:0;开启:1
conf.crawl_mode_dynamic_fuzz = 0
#Fuzz模式:关闭:0;单字典:1;多字典:2
conf.fuzz_mode = 0
#单字典模式的路径。
conf.fuzz_mode_load_single_dict = "fuzz_mode_dir.txt"
#多字典模式的路径。默认配置:fuzzmult
conf.fuzz_mode_load_mult_dict = "fuzzmult"
#设置fuzz标签。默认配置{dir}。使用{dir}标签当成字典插入点,将http://target.com/{dir}.php替换成http://target.com/字典中的每一行.php。其他配置:e.g:{dir};{ext}
#conf.fuzz_mode_label = "{ext}"
conf.fuzz_mode_label = "{dir}"
#处理payload配置。暂未实现。
[PayloadHandler]
#处理请求配置
[RequestHandler]
#自定义请求头。默认配置空。其他配置:e.g:test1=test1,test2=test2
#conf.request_headers = "test1=test1,test2=test2"
conf.request_headers = ""
#自定义请求User-Agent。默认配置chrome的ua。
conf.request_header_ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
#自定义请求cookie。默认配置空,不设置cookie。其他配置e.g:cookie1=cookie1; cookie2=cookie2;
#conf.request_header_cookie = "cookie1=cookie1; cookie2=cookie2"
conf.request_header_cookie = ""
#自定义401认证。暂未实现。因为自定义请求头功能可满足该需求(懒XD)
conf.request_header_401_auth = ""
#自定义请求方法。默认配置get方法。其他配置:e.g:get;head
#conf.request_method = "head"
conf.request_method = "get"
#自定义每个请求超时时间。默认配置3秒。
conf.request_timeout = 3
#随机延迟(0-x)秒发送请求。参数必须是整数。默认配置0秒,无延迟。
conf.request_delay = 0
#自定义单个目标,请求协程线程数。默认配置30线程
conf.request_limit = 30
#自定义最大重试次数。暂未实现。
conf.request_max_retries = 1
#设置持久连接。是否使用session()。暂未实现。
conf.request_persistent_connect = 0
#302重定向。默认False,不重定向。其他配置:e.g:True;False
conf.redirection_302 = False
#payload后添加后缀。默认空,扫描时,不添加后缀。其他配置:e.g:txt;php;asp;jsp
#conf.file_extension = "txt"
conf.file_extension = ""
#处理响应配置
[ResponseHandler]
#设置要记录的响应状态。默认配置[200],记录200状态码。其他配置:e.g:[200,403,301]
#conf.response_status_code = [200,403,301]
conf.response_status_code = [200]
#是否记录content-type响应头。默认配置1记录
#conf.response_header_content_type = 0
conf.response_header_content_type = 1
#是否记录页面大小。默认配置1记录
#conf.response_size = 0
conf.response_size = 1
#自定义匹配404页面正则
#conf.custom_404_page = "fake 404"
conf.custom_404_page = ""
#自定义匹配503页面正则。暂未实现。感觉用不着,可能要废弃。
#conf.custom_503_page = "page 503"
conf.custom_503_page = ""
#自定义正则表达式,匹配页面内容
#conf.custom_response_page = "([0-9]){3}([a-z]){3}test"
conf.custom_response_page = ""
#跳过显示页面大小为x的页面,若不设置,请配置成"None",默认配置“None”。其他大小配置参考e.g:None;0b;1k;1m
#conf.skip_size = "0b"
conf.skip_size = "None"
#代理选项
[ProxyHandler]
#代理配置。默认设置“None”,不开启代理。其他配置e.g:{"http":"http://127.0.0.1:8080","https":"https://127.0.0.1:8080"}
#conf.proxy_server = {"http":"http://127.0.0.1:8080","https":"https://127.0.0.1:8080"}
conf.proxy_server = None
#Debug选项
[DebugMode]
#打印payloads并退出
conf.debug = 0
#update选项
[CheckUpdate]
#github获取更新。暂未实现。
conf.update = 0
Q:我倒,配置文件这么多,终于看完了,可是我还想了解下默认的字典,还有怎么添加自己的字典?
A:哦呼,这里有默认字典文件介绍。还有添加自定义字典,需要将你的字典放入data文件夹,并修改dirmap.conf就可以使用了。
默认字典文件
字典文件存放在项目根目录中的data文件夹中:
dict_mode_dict.txt “字典模式”字典,使用dirsearch默认字典;
crawl_mode_suffix.txt “爬虫模式”字典,使用FileSensor默认字典;
fuzz_mode_dir.txt “fuzz模式”字典,使用DirBuster默认字典;
fuzz_mode_ext.txt “fuzz模式”字典,使用常见后缀制作的字典;
dictmult该目录为“字典模式”默认多字典文件夹,包含:BAK.min.txt(备份文件小字典),BAK.txt(备份文件大字典),LEAKS.txt(信息泄露文件字典);
fuzzmult该目录为“fuzz模式”默认多字典文件夹,包含:fuzz_mode_dir.txt(默认目录字典),fuzz_mode_ext.txt(默认后缀字典)。
Q:哇哦~
A:hhh,怎么啦?还有其他问题吗?
Q:嘻嘻,Dirmap看来是有点像小车车啦,话说完成这个项目,你参考了多少个轮子呀?
A:有很多很多,大多数都是gayhub上找到的项目,这里对这些项目贡献者表示感谢~!
致谢声明
dirmap在编写过程中,借鉴了大量的优秀开源项目的模式与思想,特此说明并表示感谢。
Sqlmap(架构参考)
POC-T(架构参考)
Saucerframe(架构参考)
gwhatweb(并发参考)
dirsearch(递归扫描实现参考)
cansina(解析header参考)
weakfilescan(爬虫动态字典模式参考)
FileSensor(爬虫动态字典模式参考)
BBscan(并发参考)
werdy(纯爆破模式参考)
还有很多开源的小脚本(字典模式参考)
还有很多的互联网文献资料(debug参考)
*本文作者:H4ckForJob,转载请注明来自FreeBuf.COM
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 喜欢
喜欢
 信息收集
信息收集






- 1 文章数
- 9 关注者