


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

SubDomainizer:用于查找页面Javascript文件中隐藏子域的工具
- 关注
SubDomainizer:用于查找页面Javascript文件中隐藏子域的工具
前言
SubDomainizer是一款用于查找隐藏在页面的内联和引用Javascript文件中子域的工具。除此之外,它还可以为我们从这些JS文件中检索到S3 bucket,云端URL等等。这些对你的渗透测试可能有非常大的帮助,例如具有可读写权限的S3 bucket或是子域接管等。
云存储服务支持
SubDomainizer可以为我们找到以下云存储服务的URL:
1. Amazon AWS services (cloudfront and S3 buckets)
2. Digitalocean spaces
3. Microsoft Azure
4. Google Cloud Services
5. Dreamhost
6. RackCDN
使用截图
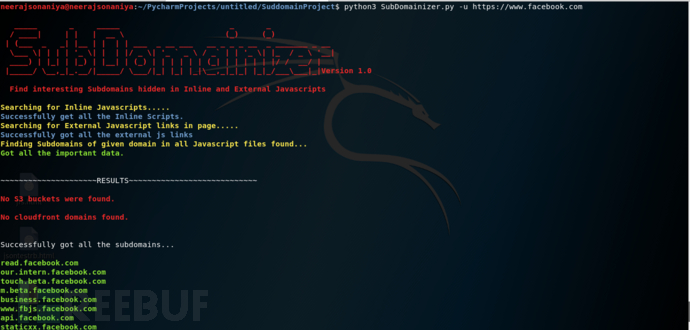
安装
从git克隆SubDomainzer:
git clone https://github.com/nsonaniya2010/SubDomainizer.git更改目录:
cd SubDomainizer安装依赖项:
sudo apt-get update
sudo apt-get install python3-termcolor python3-bs4 python3-requests python3-htmlmin python3-tldextract使用
| 简易格式 | 完整格式 | 描述 |
|---|---|---|
| -u | --url | 你想要查找(子)域的URL。 |
| -l | --listfile | 需要被扫描的包含URL列表的文件。 |
| -o | --output | 输出文件名即保存输出结果的文件。 |
| -c | --cookie | 需要随请求发送的Cookie。 |
| -h | --help | 显示帮助信息并退出。 |
| -cop | --cloudop | 需要存储云服务结果的文件名。 |
| -d | --domain | 提供TLD(例如,www.example.com,你必须提供example.com)以查找给定TLD的子域。 |
使用示例
显示帮助信息:
python3 SubDomainizer.py -h查找给定单个URL的子域,S3 bucket和云端URL:
python3 SubDomainizer.py -u http://www.example.com从给定的URL列表(给定文件)中查找子域:
python3 SubDomainizer.py -l list.txt将结果保存在(output.txt)文件中:
python3 SubDomainizer.py -u https://www.example.com -o output.txt随请求发送cookies:
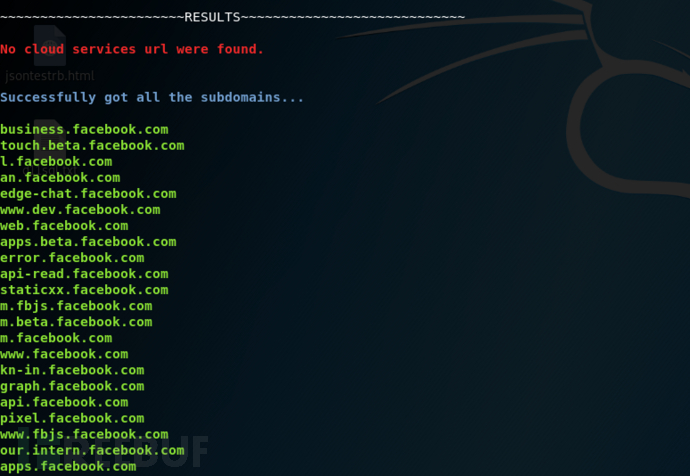
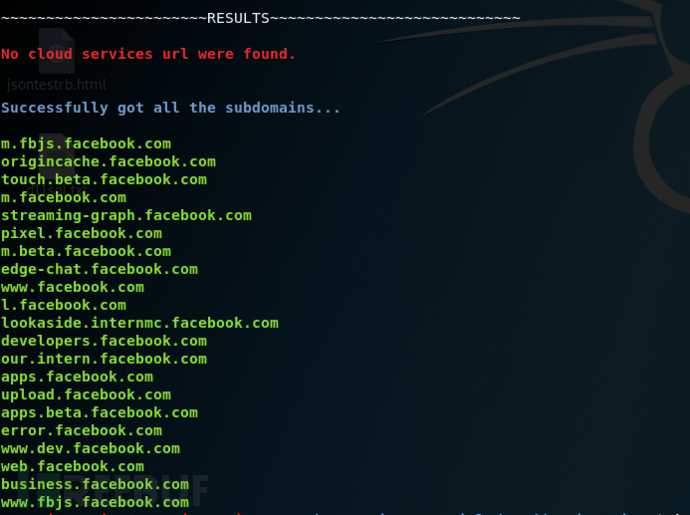
python3 SubDomainizer.py -u https://www.example.com -c "test=1; test=2"结果差异(在facebook.com上使用cookies和不使用cookies):
不使用cookies:
使用cookies:
*参考来源:GitHub,FB小编secist编译,转载请注明来自FreeBuf.COM
本文为 独立观点,未经允许不得转载,授权请联系FreeBuf客服小蜜蜂,微信:freebee2022
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
相关推荐
- 0 文章数
- 0 关注者