


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 京东云技术团队
京东云技术团队- 关注
作者:京东科技 蔡欣彤
本文参与神灯创作者计划 - 前沿技术探索与应用赛道
内容背景
随着大模型应用不断落地,知识库,RAG是现在绕不开的话题,但是相信有些小伙伴和我一样,可能会一直存在一些问题,例如:
•什么是RAG
•上传的文档怎么就能检索了,中间是什么过程
•有的知道中间会进行向量化,会向量存储,那他们具体的含义和实际过程产生效果是什么
•还有RAG = 向量化 + 向量存储 + 检索 么?
•向量化 + 向量存储 就只是RAG 么?
为了解决这些困惑,我查找了langchain的官方文档,并利用文档中提供的方法进行了实际操作。这篇文章是我的学习笔记,也希望为同样存在相同困惑的伙伴们能提供一些帮助。
最后代码都上传到coding了,地址是: https://github.com/XingtongCai/langchain_project/tree/main/translatorAssistant/basic_knowledge
一. RAG的基本概念
检索增强生成(Retrieval Augmented Generation, RAG) 通过将语言模型与外部知识库结合来增强模型的能力。RAG 解决了模型的一个关键限制:模型依赖于固定的训练数据集,这可能导致信息过时或不完整。
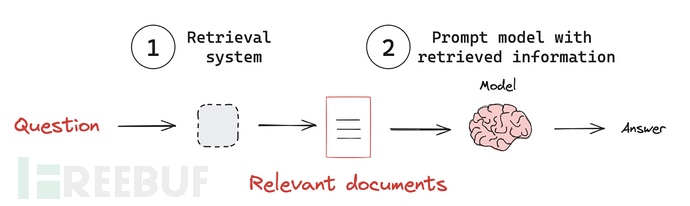
RAG大致过程如图:
•接收用户查询 (Receive an input query)
•使用检索系统根据查询寻找相关信息(Use the retrieval system to search for relevant information based on the query.)
•将检索到的信息合并到提示词,然后发送给LLM(Incorporate the retrieved information into the prompt sent to the LLM.)
•模型利用提供的上下文生成对查询的响应(Generate a response that leverages the retrieved context.)
二. 关键技术
示例代码地址: rag.ipynb,用jupyter工具可以直接看并且调试
一个完整的 RAG流程通常包含以下核心环节,每个环节都有明确的技术目标和实现方法:
•文档加载和预处理
•文本分割
•数据向量化
•向量存储与索引构建
•内容检索
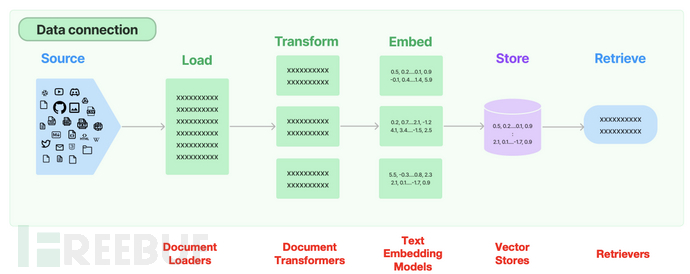
2.1 Document Loaders 数据加载
具体文档: document_loaders
整个langchain支持多种形式的数据源加载,这里面以加载pdf为例尝试:
# document loader
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./DeepSeek_R1.pdf")
pages = []
# 异步加载前 11 页
i = 0 # 手动维护计数器
async for page in loader.alazy_load():
if i >= 11: # 只加载前 11 页
break
pages.append(page)
i+=1
print(f"{pages[0].metadata}\n") // pdf的信息
print(pages[0].page_content) // 第一页的内容2.2 Text splitters 文本分割
参考文档: Text splitters
文本分割器将文档分割成更小的块以供下游应用程序使用。
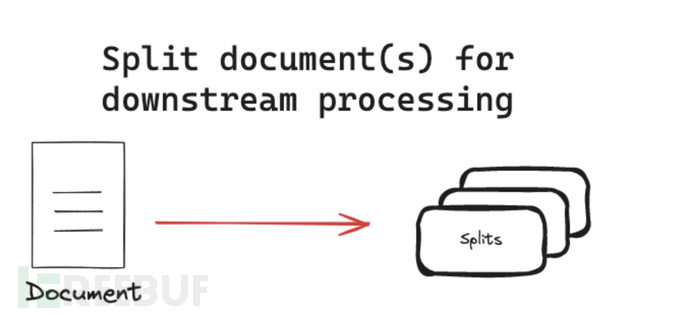
2.2.1 分割策略 - 基于长度(Length-based)
基于长度的分割是最直观的策略是根据文档的长度进行拆分。它的分割类型如下:
•Token-based :Splits text based on the number of tokens, which is useful when working with language models.
•Character-based: Splits text based on the number of characters, which can be more consistent across different types of text
常见CharacterTextSplitter用法,
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=20, chunk_overlap=0
)
texts = text_splitter.split_text(pages[0].page_content)
print(texts[0])扩展补充: token和character的区别: token 是语言模型处理文本时的基本单位,通常是一个词、子词或符号。 Character 是文本的最小单位,例如英文字母、中文字符、标点符号等。 # 示例 from transformers import GPT2Tokenizer tokenizer = GPT2Tokenizer.from_pretrained("gpt2") text = "Hello,world!" tokens = tokenizer.tokenize(text) print(tokens) # ['Hello', ',', 'world', '!'] chunk_size = 5 chunks = [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)] print(chunks) # ['Hello', ',worl', 'd!']
2.1.2 分割策略 - 基于文本结构(Text-structured based )
文本自然地被组织成层次化的单元,例如段落、句子和单词。可以利用这种固有结构来指导分割策略,创建能够保持自然语言流畅性、在分割中保持语义连贯性并适应不同文本粒度级别的分割。RecursiveCharacterTextSplitter 支持这个方式。
fromlangchain_text_splitters importRecursiveCharacterTextSplitter
text_splitter =RecursiveCharacterTextSplitter(chunk_size=1000,# 每个片段的最大字符数chunk_overlap=100,# 片段之间的重叠字符数separators=["\n\n","\n"]# 分割符(按段落、句子、标点等))chunks =text_splitter.split_documents(pages)print(f"文档被分割成 {len(chunks)} 个块")# 文档被分割成 37 个块2.1.3 分割策略 - 基于文档结构(Document-structured based)
某些文档具有固有的结构,例如 HTML、Markdown或 JSON文件。在这些情况下,基于文档结构进行分割是有益的,因为它通常自然地分组了语义相关的文本。
# Markdown 文档的分割fromlangchain_community.document_loaders importUnstructuredMarkdownLoader
fromlangchain.text_splitter importMarkdownHeaderTextSplitter
# 加载 Markdown 文档loader =UnstructuredMarkdownLoader("example.md")documents =loader.load()# 使用 MarkdownHeaderTextSplitter 分割splitter =MarkdownHeaderTextSplitter(headers_to_split_on=["#","##","###"])chunks =splitter.split_text(documents[0].page_content)# 打印分割结果forchunk inchunks:print(chunk)2.1.4 分割策略 - 基于语义的分割(semantic-based splitting)
与之前的方法不同,基于语义的分割实际上考虑了文本的内容。虽然其他方法使用文档或文本结构作为语义的代理,但这种方法直接分析文本的语义。核心方法是基于NLP模型,使用句子嵌入(Sentence-BERT)计算语义边界,通过文本相似度突变检测分割点
2.3 Embedding 向量化
参考文档: Embedding models
嵌入模型(embedding models)是许多检索系统的核心。嵌入模型将人类语言转换为机器能够理解并快速准确比较的格式。这些模型以文本作为输入,生成一个固定长度的数字数组。嵌入使搜索系统不仅能够基于关键词匹配找到相关文档,还能够基于语义理解进行检索。主要应用之一是rag.
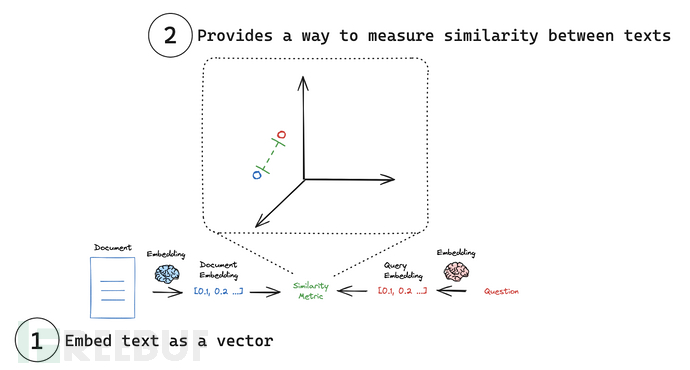
LangChain 提供了一个通用接口,用于与嵌入模型交互,并为常见操作提供了标准方法。这个通用接口通过两个核心方法简化了与各种嵌入提供商的交互:
•embed_documents:用于嵌入多个文本(文档)。
•embed_query:用于嵌入单个文本(查询)。
fromlangchain_openai importOpenAIEmbeddings
# 初始化 OpenAI 嵌入模型embeddings =OpenAIEmbeddings(model="text-embedding-ada-002")# 这里取第一个片段进行embedding,省tokendocument_embeddings =embeddings.embed_documents(chunks[0].page_content)print("文档嵌入:",document_embeddings[0])# 文档嵌入: [0.0063153719529509544, -0.00667550228536129,...]print(len(document_embeddings))# 935# 单个查询query ="这篇文章介绍DeepSeek的什么版本"# 使用 embed_query 嵌入单个查询query_embedding =embeddings.embed_query(query)print("查询嵌入:",query_embedding)# 查询嵌入:[-0.0036168822553008795, 0.0056339893490076065,...]2.4 Vector stores 向量存储
参考文档: Vector stores
其实langchain支持embedding和vector 的种类有很多,具体支持类型见 full list of LangChain vectorstore integrations.
其中, 向量存储(Vector Stores)是一种专门的数据存储,支持基于向量表示的索引和检索。这些向量捕捉了被嵌入数据的语义意义。
向量存储通常用于搜索非结构化数据(如文本、图像和音频),以基于语义相似性而非精确的关键词匹配来检索相关信息。主要应用场景之一是rag。
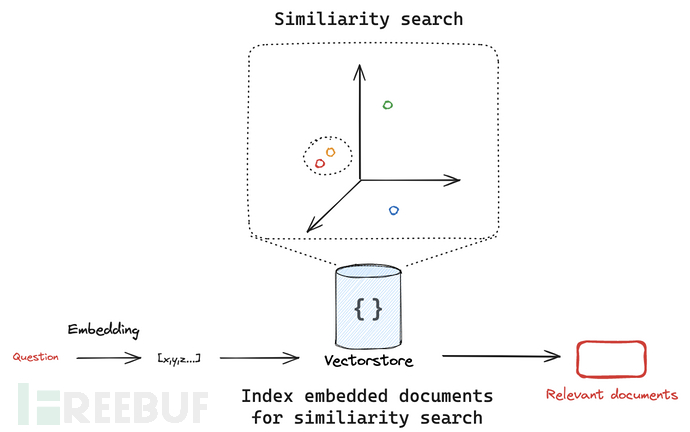
•
LangChain提供了一个标准接口,用于与向量存储交互,使用户能够轻松切换不同的向量存储实现。
该接口包含用于在向量存储中写入、删除和搜索文档的基本方法。
关键方法包括:
1.add_documents:将一组文本添加到向量存储中。
2.delete:从向量存储中删除一组文档。
3.similarity_search:搜索与给定查询相似的文档。
# vector storefromlangchain_core.vectorstores importInMemoryVectorStore
# 实例化向量存储vector_store =InMemoryVectorStore(embeddings)# 将已经转为向量的文档存储到向量存储中ids =vector_store.add_documents(documents=chunks)print(ids)# ['b5b11014-7702-45f6-aa0d-7272042c5d4d', '93ed319a-5110-40ac-8bf4-117a220ed0cb', '63b92a2f-bf47-4a10-b66b-cd39776995f7',...]vector_store.delete(ids=["93ed319a-5110-40ac-8bf4-117a220ed0cb"])vector_store.similarity_search('What is the model introduced in this paper?',k=4)额外补充一句:
向量化嵌入和向量存储不仅限于检索增强生成(RAG)系统,它们有更广泛的应用场景:
其他应用领域包括:
1.语义搜索系统 - 基于内容含义而非关键词匹配的搜索
2.推荐系统 - 根据内容或用户行为的相似性推荐项目
3.文档聚类 - 自动组织和分类大量文档
4.异常检测 - 识别与正常模式偏离的数据点
5.多模态系统 - 连接文本、图像、音频等不同模态的内容
6.内容去重 - 识别相似或重复的内容
7.知识图谱 - 构建实体之间的语义关联
8.情感分析 - 捕捉文本的情感特征
RAG是向量嵌入技术的一个重要应用,但这些技术的价值远不止于此,它们为各种需要理解内容语义关系的AI系统提供了基础。2.5 Retriever检索
参考文档: retrievers
目前存在许多不同类型的检索系统,包括 向量存储(vectorstores)、图数据库(graph databases)和 关系数据库(relational databases)。
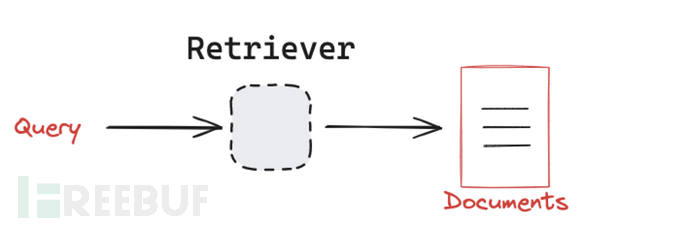
LangChain提供了一个统一的接口,用于与不同类型的检索系统交互。LangChain 的检索器接口非常简单:
•输入:一个查询(字符串)。
•输出:一组文档(标准化的 LangChain Document 对象)。
而且LangChain的retriever是runnable类型,runnable可用方法他都可以调用,比如:
docs = retriever.invoke(query)
2.5.1 基础检索器的几种类型说明
在 LangChain 中,as_retriever()方法的 search_type参数决定了向量检索的具体算法和行为。以下是三种搜索类型的详细解释和对比:
retriever =vector_store.as_retriever(search_type="similarity",# 可选 "similarity"|"mmr"|"similarity_score_threshold"search_kwargs={"k":5,# 返回结果数量"score_threshold":0.7,# 仅当search_type="similarity_score_threshold"时有效"filter":{"source":"重要文档.pdf"},# 元数据过滤"lambda_mult":0.25# 仅MMR搜索有效(控制多样性)})search_kwargs: 搜索条件
search_type可选 "similarity"|"mmr"|"similarity_score_threshold"
•similarity(默认)-标准相似度搜索
原理:直接返回与查询向量最相似的 k 个文档(基于余弦相似度或L2距离)
特点:
◦结果完全按相似度排序
◦适合精确匹配场景
•mmr-最大边际相关性
原理:在相似度的基础上增加多样性控制,避免返回内容重复的结果
核心参数:
◦lambda_mult:0-1之间的值,越小结果越多样
▪接近1:更偏向相似度(类似similarity)
▪接近0:更偏向多样性
特点:
◦检索结果需要覆盖不同子主题时
◦避免返回内容雷同的文档
similarity_score_threshold-带分数阈值的相似度搜索
•原理:只返回相似度超过设定阈值的文档
•关键参数:
◦score_threshold:相似度阈值(余弦相似度范围0-1)
◦k:最大返回数量(但实际数量可能少于k)
•特点:
◦适合质量优先的场景
◦结果数量不固定(可能返回0个或多个)
| 类型 | 核心目标 | 结果数量 | 是否控制多样性 | 典型应用场景 |
|---|---|---|---|---|
similarity | 精确匹配 | 固定k个 | ❌ | 事实性问题回答 |
mmr | 平衡相关性与多样性 | 固定k个 | ✅ | 生成综合性报告 |
similarity_score_threshold | 质量过滤 | 动态数量 | ❌ | 高精度筛选 |
2.5.2 高级检索工具
1.MultiQueryRetriever- 提升模糊查询召回率
设计目标:通过查询扩展提升检索质量 核心思想:
•对用户输入问题生成多个相关查询(如同义改写、子问题拆解)
•合并多查询结果并去重
关键特点:
•提升模糊查询的召回率
•依赖LLM生成优质扩展查询(需控制生成成本)
2.MultiVectorRetriever -多向量检索
设计目标:处理单个文档的多种向量表示形式 核心思想:
•对同一文档生成多组向量(如全文向量、摘要向量、关键词向量等)
•通过多角度表征提升召回率
关键特点:
•适用于文档结构复杂场景(如技术论文含正文/图表/代码)
•存储开销较大(需存多组向量)
3.RetrievalQA
设计目标:端到端的问答系统构建 核心思想:
•将检索器与LLM答案生成模块管道化
•支持多种链类型(stuff/map_reduce/refine等)
使用方法:
# 构建一个高性能问答系统fromlangchain.chains importRetrievalQA
fromlangchain.retrievers.multi_query importMultiQueryRetriever
fromlangchain.retrievers.multi_vector importMultiVectorRetriever# 1. 多向量存储
# 假设已生成不同视角的向量
vectorstore = FAISS.from_texts(documents, embeddings)
mv_retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=standard_docstore, # 存储原始文档
id_key="doc_id" # 关联不同向量与原始文档
)
# 2. 多查询扩展
mq_retriever = MultiQueryRetriever.from_llm(
retriever=mv_retriever,
llm=ChatOpenAI(temperature=0.3)
)
# 3. 问答链
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0),
chain_type="refine",
retriever=mq_retriever,
chain_type_kwargs={"verbose": True}
)
# 执行
answer = qa.run("请对比Transformer和CNN的优缺点")4.TimeWeightedVectorStoreRetriever- 时间加权检索
•设计目标:专门用于在向量检索中引入时间衰减因子,使系统更倾向于返回近期文档
• 典型使用场景
1. 新闻/社交媒体应用 -优先展示最新报道而非历史文章
2. 技术文档系统 - 优先推荐最新API文档版本
3. 实时监控告警 - 使最近的事件告警排名更高
2.5.3 混合检索
EnsembleRetriever - 集合检索器
•场景:结合语义+关键词搜索
ContextualCompressionRetriever-上下文压缩
•场景:过滤低相关性片段
三. 代码实战
说完了技术,接下来就真正尝试两个个例子,走一遍RAG全流程。
3.1 构建一个简单的员工工作指南检索系统
需求背景:我现在要给一个企业做员工工作指南的检索系统,方便员工查阅最新资讯。里面包含.pdf,.docx,.txt三种文件。
技术点:
•使用FAISS做向量存储,MultiQueryRetriever和RetrievalQA做增强检索
•构建一个chain做问答
目录结构:
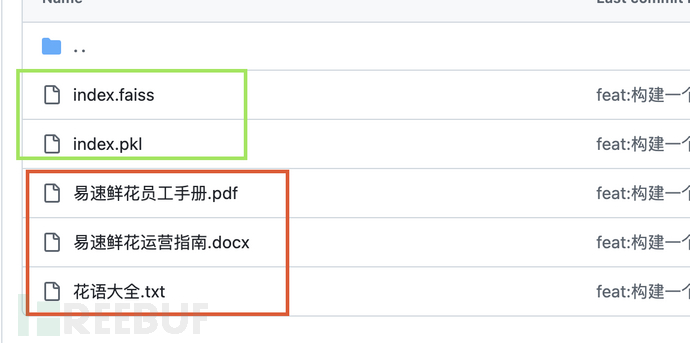
三个需要加载的文档, index.faiss和index.pkl是我已经做好向量化的文件,如果不想自己做向量化或者想省一些token,可以直接读取这两个文件。代码段如下:
# 如果已经有embedding文件,直接加载,不要重新处理了,节省token
embedding = OpenAIEmbeddings(model="text-embedding-ada-002",chunk_size=1000)
vector_store_1 = FAISS.load_local(
folder_path="./docs", # 存放index.faiss和index.pkl的目录路径
embeddings=embedding, # 必须与创建时相同的嵌入模型
index_name="index", # 可选:若文件名不是默认的"index",需指定前缀
allow_dangerous_deserialization=True # 显式声明信任
)
print(f"已加载 {len(vector_store_1.docstore._dict)} 个文档块")
print(vector_store_1)运行方式2种:
1.用 jupyter工具,直接运行Langchain_QA.ipynb这个文件,可以单步调试。我运行的结果也可以直接看到
2.用python脚本,直接运行Langchain_QA.py这个文件
cd translatorAssistant/basic_knowledge/员工手册的检索系统
python Langchain_QA.py
示例问题可以尝试:
"应聘人员须提供什么资料"
"Rose的花语是什么"结果界面:


3.2 读取网页的blog并进行多轮对话来查询
需求背景:我现在要读取 https://lilianweng.github.io/posts/2023-06-23-agent/ 这个blog的内容,并对里面内容进行多轮对话的检索
技术点:
•使用WebBaseLoader来加载网页内容
•使用rlm/rag-prompt来构建rag的prompt提示词模版
•使用ConversationBufferMemory来做记忆存储,进行多轮对话
•构建stream_generator支持流式输出
目录结构:
和上面结构差不多,docs里面是向量化好的文件,.ipynb可以单步调试并且能看我运行的每一步结果,.py是最后整个python文件
运行方式:和上面示例一样
运行结果:
多轮对话的的prompt:
最后结果:
四.企业级RAG
上面的内容是作为RAG的基础知识,但是想做企业级别的RAG,尤其是要做 产品资讯助手这种基于知识库和用户进行问答式的交流还远远不够。总流程没有区别,但是每一块都有自己特殊处理地方:
我通过读取一些企业级RAG的文章,大致整理一下这种流程,但是真实使用时候,还是需要根据我们自己业务文档,使用的场景和对于回答准确率要求的情况来酌情处理。
4.1 文本加载和文本清洗
企业级知识库构建在预处理这部分的处理是重头戏。因为我们文档是多样性的,有不同类型文件,文件里面还有图片,图片里面内容有时候也是需要识别的。另外文档基本都是产品或者运营来写,里面有很多口头语的表述,过多不合适的分段/语气词,多余的空格,这些问题都会影响最后分割的效果。一般文本清洗需要做一下几步:
•去除杂音:去掉文本中的无关信息或者噪声,比如多余的空格、HTML 标签和特殊符号等。
•标准化格式:将文本转换为统一的格式,如将所有字符转为小写,或者统一日期、数字的表示。
•处理标点符号和分词:处理或移除不必要的标点符号,并对文本进行适当的分词处理。
•去除停用词:移除那些对语义没有特别贡献的常用词汇,例如“的”、“在”、“而”等。
•拼写纠错:纠正文本中的拼写错误,以确保文本的准确性和一致性。
•词干提取和词形还原:将词语简化为词干或者词根形式,以减少词汇的多样性并保持语义的一致性。
4.2 文本分割
除了采取上面的基本分割方式,然后还可以结合层次分割优化不同粒度的索引结构,提高检索匹配度。
补充一下多级索引结构:
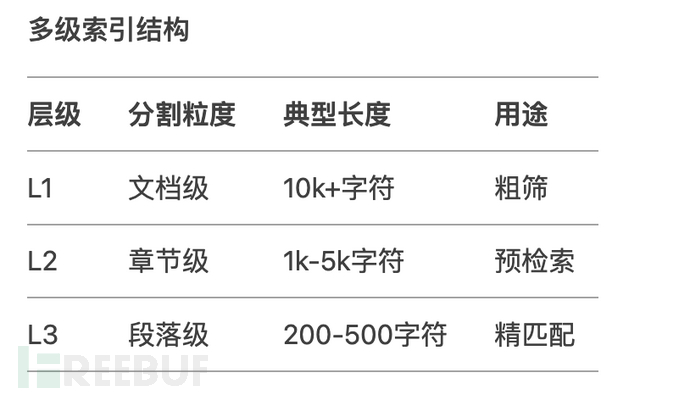
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3")
]
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers)
chunks = splitter.split_text(markdown_doc)4.3 向量存储
在企业级存储一般数据量都很大,用内存缓存是不现实的,基本都是需要存在数据库中。至于用什么数据库,怎么存也根据文本类型有变化,例如:
•向量数据库:向量存储库非常适合存储文本、图像、音频等非结构化数据,并根据语义相似性搜索数据。
•图数据库:图数据库以节点和边的形式存储数据。它适用于存储结构化数据,如表格、文档等,并使用数据之间的关系搜索数据。
4.4 向量检索
在很多情况下,用户的问题可能以口语化形式呈现,语义模糊,或包含过多无关内容。将这些模糊的问题进行向量化后,召回的内容可能无法准确反映用户的真实意图。此外,召回的内容对用户提问的措辞也非常敏感,不同的提问方式可能导致不同的检索结果。因此,如果计算能力和响应时间允许,可以先利用LLM对用户的原始提问进行改写和扩展,然后再进行相关内容的召回。
4.5 内容缓存
在一些特定场景中,对于用户的问答检索需要做缓存处理,以提高响应速度。可以以用户id,时间顺序,信息权重作为标识进行存储。
还有一些关于将检索信息和prompt结合时候,如何处理等其他流程,这里不多讲,讲多了头疼。。。
总结
本文介绍了RAG的基础过程,在langchain框架下如何使用,再到提供两个个例子进行了代码实践,最后又简要介绍了企业级别RAG构建的内容。最后希望大家能有所收获。
码字不易,如果喜欢,请给作者一个小小的赞做鼓励吧~~
参考文献
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 1753 文章数
- 91 关注者