


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
国家太空安全是国家安全在空间领域的表现。随着太空技术在政治、经济、军事、文化等各个领域的应用不断增加,太空已经成为国家赖以生存与发展的命脉之一,凝聚着巨大的国家利益,太空安全的重要性日益凸显[1]。而在信息化时代,太空安全与信息安全紧密地结合在一起。
2020年9月4日,美国白宫发布了首份针对太空网络空间安全的指令——《航天政策第5号令》,其为美国首个关于卫星和相关系统网络安全的综合性政策,标志着美国对太空网络安全的重视程度达到新的高度。在此背景下,美国自2020年起,连续两年举办太空信息安全大赛“黑掉卫星(Hack-A-Sat)”,在《Hack-A-Sat太空信息安全挑战赛深度解析》一书中有详细介绍,本文介绍了Hack-A-Sat黑掉卫星挑战赛的AES加密通信链路侧信道攻击leaky这道赛题的解题过程。
题目介绍
My crypto algorithm runs in constant time, so I'm safe from sidechannel leaks, right?
Note: To clarify, the sample data is plaintext inputs, NOT ciphertext
Given files: leaky-romeo86051romeo.tar.bz2
题目很短,使用netcat连接上主办方给出的链接地址后,会得到更多的信息,如下所示:
Hello, fellow space enthusiasts!
I have been tracking a specific satellite and managed to intercept an interesting
piece of data. Unfortunately, the data is encrypted using an AES-128 key with ECB-Mode.
Encrypted Data:
7972c157dad7b858596ecdb798877cc4ed4b03d6822295954e69b7ecebb704af08c054a03a374f8bdaa18ff16ba09be2b6b25f1ef73ef80111646de84cd3af2514501e056889e95c680f7d199b6531e9dd6ee599aeb23835327e6e853a9a40a9f405bd1443e014363ea46631582b97c3d3f83f4e1101da2557f9b03808a61968
Using proprietary documentation, I have learned that the process of generating the
AES key always produces the same first 6 bytes, while the remaining bytes are random:
Key Bytes 0..5: 97ca6080f575
The communication protocol hashes every message into a 128bit digest, which is encrypted
with the satellite key, and sent back as an authenticated ACK. This process fortunately
happens BEFORE the satellite attempts to decrypt and process my message, which it will
immediately drop my message as I cannot encrypt it properly without the key.
I have read about "side channel attacks" on crypto but don't really understand them,
so I'm reaching out to you for help. I know timing data could be important so I've
already used this vulnerability to collect a large data set of encryption times for
various hash values. Please take a look!
上述信息很长,从中可以分析出如下关键信息:
(1)这是一道密码破译的题目,使用的加密算法是ECB模式的AES-128,AES是高级加密标准(Advanced Encryption Standard),后文会有介绍。
(2)可知密钥的前6个字节是97ca6080f575。
(3)已经知道了加密后的密文,要获取该密文对应的明文,该明文应该就是flag值。
(4)应该会用到AES侧信道攻击,并且该攻击利用了加解密时间信息。
(5)在给出的压缩文件中,有一个test.txt,其中有100 000条数据,每一行包括两部分,前一部分是明文字符串,后一部分是使用AES加密该明文字符串的时间(时间的单位未知,但是这个也不重要,不影响解题),部分数据示例如下:
ed74cd51ab28e765d1e98965e86ba749,10584
ea0c914e1ff97edbe3bd46228f53771e,10656
3e8d4ed226d2ffea86fcf8be22af3e33,10704
3bd7f7bb63745fc45940220e417a116d,10632
99c5843576a344f0d8ec990795912a38,10632
34239b24eef47313a14e0a55767810dd,10632
7b9ae4bdb410862d12de1d94cd40853a,10656
f54c322e63f3b169fdfb4b161decc9b6,10680
91359a6820ecadafd2e616aa2c0baa42,10680
c4ce053a2df7f883d24905856df2b180,10656
......
(6)参考以前的挑战题,知道明文的前几个字节是“flag”。
总的来说,这道挑战题就是已知加密算法是AES,还已知密钥的部分字节、明文信息的部分字节,并且已经有了大量的加密测试数据,要求使用侧信道攻击的方式,获取正确的密钥。
编译及测试
为了检验下载的源代码是否正确,可以先编译并测试一下。进入hackasat2020的leaky目录下,查看challenge、solver目录下的Dockerfile,发现其中用到的是python:3.7-slim,为了加快题目的编译进度,在leaky目录下新建一个文件sources.list,内容如下:
deb https://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb-src https://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb https://mirrors.aliyun.com/debian-security/ bullseye-security main
deb-src https://mirrors.aliyun.com/debian-security/ bullseye-security main
deb https://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb-src https://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb https://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
deb-src https://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
将sources.list复制到leaky、challenge、solver目录下,修改challenge、solver目录下的Dockerfile,在所有的FROM python:3.7-slim下方添加:
ADD sources.list /etc/apt/sources.list
在所有的pip命令后方添加指定源:
打开终端,进入leaky所在目录,执行命令:
sudo make build
使用make test命令进行测试,如果结果如图6-26所示,说明题目设计、代码编写正确。
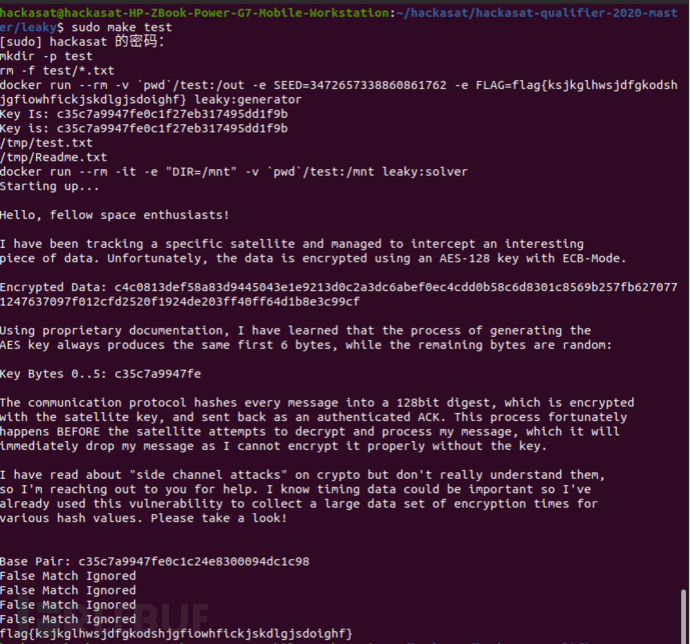 图6-26 leaky挑战题的测试结果
图6-26 leaky挑战题的测试结果
相关背景知识
1.侧信道攻击
侧信道攻击(Side Channel Attack,SCA),又称边信道攻击,其核心思想是通过加密软件或硬件运行时产生的各种泄露信息获取密文。所谓侧信道,就是与主信道相对的,加密信息通过主信道进行传输,但在密码设备进行密码处理时,会通过侧信道泄露一定的功耗、电磁辐射、热量、声音等信息,泄露的这些信息又随着设备处理的数据及进行的操作的不同而有差异(例如,输入0输出0肯定比输入1输出0耗能少,少了由1到0的转化过程;条件分支指令肯定比算术运算指令耗能少,这是由其硬件决定的)。攻击者通过分析信息之间的这种差异性来得出设备的密钥等敏感信息。侧信道攻击本质上是利用设备能量消耗的数据依赖性和操作依赖性。通常的方式有针对密码算法的计时攻击、能量分析攻击、电磁分析攻击等,这类新型攻击的有效性远高于密码分析的数学方法,因此给密码设备带来了严重的威胁。
在分析本挑战题给出的提示信息时,分析出“应该会用到AES侧信道攻击,并且该攻击利用了加解密时间信息”,本节采用的是AES缓存碰撞攻击,属于侧信道攻击的一种,具体原理会在下文介绍。
2.计算机存储结构简介
现在的计算机的存储结构分为硬盘、内存、缓存,缓存还分为一级、二级,为了简化描述,本书就不区分一级缓存、二级缓存,统一称为缓存。计算机存储的简单模型如图6-27所示。处理器要获取指定地址的数据,会首先尝试从缓存读取,如果在缓存中没找到,就会到内存找,如果在内存中也没找到,最后就会到硬盘中找,找到后,会将数据读取到内存,并进一步读取到缓存,下次再找该地址的数据时,就可以直接从缓存找到了,这称为缓存命中。因此,第一次读取一个指定地址的数据时会比较慢,但是紧接着读取同样地址的数据就直接从缓存读取了,因此会快很多。
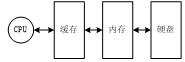 图6-27 计算机存储的简单模型
图6-27 计算机存储的简单模型
当然,缓存的价格高于内存,内存的价格高于硬盘,所以缓存的容量小于内存,内存的容量小于硬盘。因此,多个硬盘地址对应一个内存地址,多个内存地址对应一个缓存地址。刚刚读取到缓存的数据,在过一段时间后,有可能被新读取的其他地址的数据覆盖,此时如果读取该数据,又会重复之前的过程。
3.AES加密算法
AES是美国联邦政府采用的一种区块加密标准,是一种对称加密算法。对称加密,即加密与解密用的是同样的密钥。AES因其运算速度快、安全性高的优点,用于替代原先的DES(Data Encryption Standard,数据加密标准),已经被广泛使用。AES加密、解密过程如图6-28所示,左边是加密过程,右边是解密过程,加密、解密是对称的。从图6-28中可以发现,加密、解密需要进行多轮计算,根据密钥长度不同,AES分为AES-128、AES-192、AES-256,密钥长度不同,导致计算轮数不同。对于AES-128,密钥为128位,即16字节,每次对明文的16字节加密,解密也是每次对密文的16字节解密。加密、解密过程有10轮运算。AES加密每轮运算的过程如图6-29所示。每轮对16字节进行运算,由4层组成:字节代换层(Byte Substitution Layer)、ShiftRows层、MixColumn层、密钥加法层(Key Addition Layer)。
AES在软件层面和硬件层面都已经有了很多种实现方式。其中AES设计者提议的一种快速软件实现方式——查表法得到广泛应用。查表法的核心思想是将字节代换层、ShiftRows层和MixColumn层融合为查找表,每个表的大小为256条,每条为4字节,一般称为T盒(T-box)或T表。加密过程有4个表(Te),解密过程有4个表(Td),共8个。每轮操作都通过16次查表产生。虽然每轮就要经历16次查表,但这不仅简化了矩阵乘法操作,而且T表一般是通过编写程序提前算出的,然后作为一个常量数组,硬编码在AES的软件实现代码中,对于计算机而言是非常简单高效的查表和按位运算。于是,每轮的计算可以使用如下公式表示。
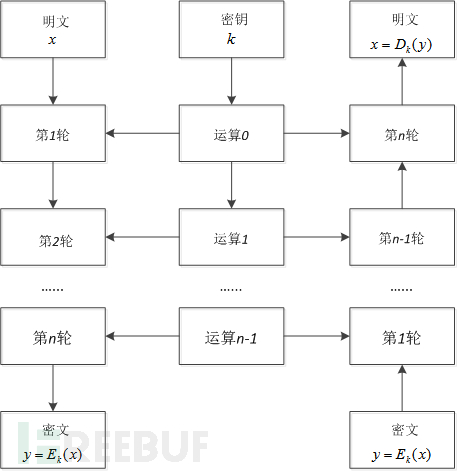 图6-28 AES加密、解密过程
图6-28 AES加密、解密过程
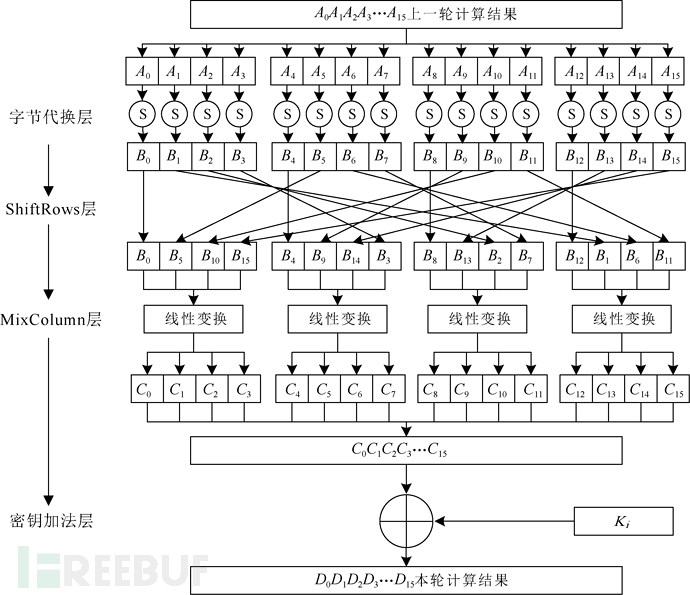 图6-29 AES加密每轮运算的过程
图6-29 AES加密每轮运算的过程
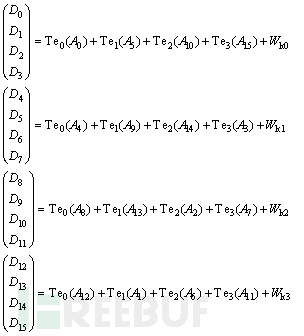
从公式中可以发现,使用A0、A4、A8、A12查找时使用的都是Te0表,使用A5、A9、A13、A1查找时使用的都是Te1表,使用A10、A14、A2、A6查找时使用的都是Te2表,使用A15、A3、A7、A11查找时使用的都是Te3表,将使用同一个Te表的那4字节称为一个家族(family)。
4.AES缓存碰撞攻击原理
假设明文为P,大小为16字节,第i字节为Pi,密钥为K,大小也为16字节,第i字节为Ki,对于第一轮计算,查找表的序号是Pi⊕Ki,如表6-1所示。假如P0⊕K0等于P4⊕K4,那么这两次查表将查找到的是同一个内存地址,根据计算机存储结构的工作原理,由于已经将P0⊕K0对应的数据从内存读取到了缓存,所以再次读取P4⊕K4对应数据时,将直接从缓存读取,时间将大大节省。如果出现这种情况,那么由于已知P0、K0、K4,因此就可以计算得到对应的P4。同样,可以依次计算推测得到其他的字节。
表6-1 第一轮查找表的序号
T表 | Te0 | Te1 | Te2 | Te3 |
序号 | P0⊕K0 | P5⊕K5 | P10⊕K10 | P15⊕K15 |
P4⊕K4 | P9⊕K9 | P14⊕K14 | P3⊕K3 | |
P8⊕K8 | P13⊕K13 | P2⊕K2 | P7⊕K7 | |
P12⊕K12 | P1⊕K1 | P6⊕K6 | P11⊕K11 |
从挑战赛题目可知,目前有100 000组明文数据,其中有对每组明文数据进行AES加密耗费的时间,并且已知密钥的前6字节,根据上述原理,尝试使用密钥的第0字节,推测密钥的第4字节,以验证上述分析是否成立。验证步骤如下:
(1)对100 000组数据,每组数据的第0字节与已知密钥的第0字节进行异或运算,得到结果数组Set0;
(2)假设密钥的第4字节为x(x可能的范围是0x00~0xff,共256种可能),那么对100 000组数据,每组数据的第4字节与x进行异或运算,得到结果数组Set1;
(3)对比Set0、Set1,可以得到其中相同的元素的序号集,这个序号集称为碰撞数据集CollisionSet,不相同的元素的序号集称为非碰撞数据集non-CollisionSet;
(4)将测试数据中,non-CollisionSet中对应明文的加密时间取一个均值non-CollisionSetMeanTime,将测试数据中,CollisionSet中对应明文的加密时间取一个均值CollisionSetMeanTime;
(5)将non-CollisionSetMeanTime减去CollisionSetMeanTime,得到一个时间差;
(6)对于密钥的第4字节的所有256种可能值,重复第2~6步,得到256个时间差;
(7)取出时间差绝对值最大的前10个对应的猜测值,其中有密钥的第4字节对应的值。
按照上述步骤,编写程序,如下:
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import numpy as np
from tqdm import tqdm_notebook
import matplotlib.pyplot as plt
import itertools
# 存储的是密钥的前6字节
aes_key_prefix = bytearray.fromhex('c35c7a9947fe')
# 读入测试数据
f = open('test.txt', 'r')
data = f.readlines()
f.close()
ntraces = len(data)
pt = np.zeros((ntraces, 16), dtype='uint8')
time = np.zeros((ntraces))
for idx, line in enumerate(data):
data = line.strip().split((','))
pt[idx] = bytearray.fromhex(data[0]) # pt中存储明文数据
time[idx] = int(data[1]) # time中存储计算时间,单位可以精确到ns
# 将测试数据中每一行的明文的第0字节与已知密钥的第0字节进行异或运算,结果存储在labels_ref中
labels_ref = np.zeros((ntraces), dtype='uint8')
for i in range(ntraces):
labels_ref[i] = pt[i,0] ^ aes_key_prefix[0]
labels_candidates = np.zeros((ntraces), dtype='uint8')
timediff = np.zeros((256))
# 这里的tqdm是Python中专门用于进度条美化的模块,通过在非while的循环体内嵌入tqdm,可以得到
# 一个能更好展现程序运行过程的提示进度条# 将密钥的第4字节的256个可能的情况依次与明文的第4字节进行异或运算,结果存储在labels_candidates中
for kguess in tqdm_notebook(range(256)):
for i in range(ntraces):
# 对每一种可能性都会与每一组明文的第4字节进行亦或异或运算,
labels_candidates[i] = pt[i,4] ^ kguess
# 下面是对每一行明文进行分析,
# 如果该明文第4字节与当前kguess(密钥的第4字节的猜测值)的异或值等于
# 该明文第0字节与已知密钥第0字节异或值的明文,则输出这一行的序号collision_idx = np.where(labels_ref == labels_candidates)[0]
# 计算当前kguess(密钥的第4字节的猜测值),假如上一步得到的是“异或值相同明文”,那么就使用
# 测试数据中所有“异或值不相同明文”的加密时间的均值减去“异或值相同明文”的均值timediff[kguess] = np.mean(np.delete(time, collision_idx)) - np.mean(time [collision_idx])
# 打印出前10个时间差值最大的kguess
print(np.argsort(np.abs(timediff))[::-1][0:10])
# 打印出已知密钥的第4字节,与上面打印出来的10个值进行对比,可以发现第4个就对应上了
print('Key byte 4:', aes_key_prefix[4])
所有的计算结果如图6-30所示,其中横轴是密钥的第4字节的0~255可能的值,纵轴是在每种可能值时,计算出来的加密时间差,可见有一个明显的峰值,表示时间差很大。
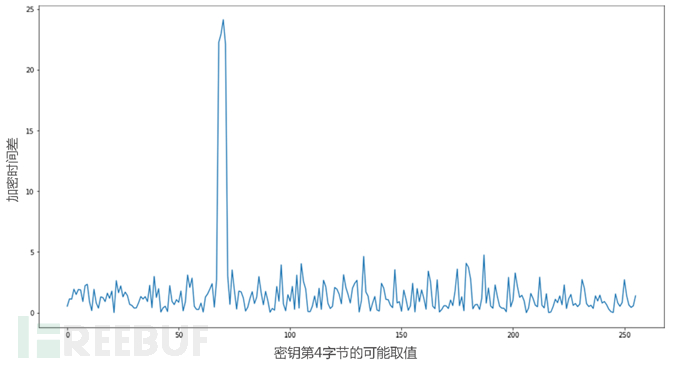 图6-30 当密钥的第4字节依次取0~255时,分别对应的加密时间差
图6-30 当密钥的第4字节依次取0~255时,分别对应的加密时间差
时间差最大的前10个值如下:
[ 70 69 68 71 187 133 179 105 96 180]
可以发现其中第4个猜测结果是71(十六进制为0x47),正是已知密钥的第4字节0x47。因此,可以证明AES缓存碰撞攻击能够用于本挑战题的解答。
题目解析
AES缓存碰撞攻击可以用于题目解答,就是按照6.3.3节推测密钥第4字节的方式,依次推测密钥的其他字节。将上述推测密钥第4字节的过程称为密钥推测函数keysearch,其函数定义keysearch(l_ref, targets),如下:
labels_all = np.zeros((16, ntraces, 256), dtype='uint8')
# 将每一行明文的前16字节都与每一种可能的密钥进行异或运算,密钥一共有256种可能;结果存储在
# labels_all中,labels_all是一个多重数组,第一层以16字节为序号,第二层以明文的行数为序号,
# 第三层以可能的密钥为序号,#所以labels_all[b,i,k]就是第i行明文的第b字节与可能密钥k异或的结果
for i in tqdm_notebook(range(ntraces)):
for b in range(16):
for k in range(256):
labels_all[b,i,k] = pt[i][b] ^ k
#keysearch就是将上面验证阶段的代码封装成一个函数,只是此时不用再单独计算异或值了,
#因为前面已经全部计算了
def keysearch(l_ref, targets):
timediff = np.zeros((256))
for byte_target in targets:
for k_t in range(256):
l_tar = labels_all[byte_target,:,k_t]
collision_idx = np.where(l_ref == l_tar)[0]
timediff[k_t]=np.mean(np.delete(time, collision_idx))-np.mean(time [collision_idx])
# 设置一个门限
if np.max(np.abs(timediff)) > 10:
print('Found candidate values for key byte', byte_target)
# 取出前4个最有可能性的结果
print(np.argsort(np.abs(timediff))[::-1][0:4], np.max(np.abs(timediff)))
其中,l_ref是已知密钥的某字节,由该字节推测与该字节在一个家族中的其余字节。已知密钥的前6字节,所以可由密钥的第0字节推测密钥的第4、8、12字节,由密钥的第1字节推测密钥的第5、9、13字节,由密钥第2字节推测密钥的第6、10、14字节,由密钥的第3字节推测密钥的第7、11、15字节;由密钥的第4字节推测密钥的第8、12字节;由密钥的第5字节推测密钥的第9、13字节。
# 已知密钥的前字节
l_ref_0 = labels_all[0,:,aes_key_prefix[0]]
l_ref_1 = labels_all[1,:,aes_key_prefix[1]]
l_ref_2 = labels_all[2,:,aes_key_prefix[2]]
l_ref_3 = labels_all[3,:,aes_key_prefix[3]]
l_ref_4 = labels_all[4,:,aes_key_prefix[4]]
l_ref_5 = labels_all[5,:,aes_key_prefix[5]]
# 参考AES中的家族概念,第0、4、8、12是一个家族;第1、5、9、13是一个家族;第2、6、10、14是一
# 个家族;第3、7、11、15是一个家族;所以这里通过已知的密钥的第0、4字节获取第8、12字节的可能值;# 通过已知的密钥的第1、5字节获取第9、13字节的可能值;通过已知的密钥的第2字节获取第6、10、14字
# 节的可能值;通过已知的密钥的第3字节获取第7、11、15字节的可能值;keysearch(l_ref_0, [4,8,12])
keysearch(l_ref_4, [0,8,12])
keysearch(l_ref_1, [5,9,13])
keysearch(l_ref_5, [1,9,13])
keysearch(l_ref_2, [6,10,14])
keysearch(l_ref_3, [7,11,15])
第一轮推测结果如下,此处只取了前4个最有可能的结果。
Found candidate values for key byte 4
[70 69 68 71] 24.123295412107836
Found candidate values for key byte 0
[194 193 192 195] 24.123295412107836
Found candidate values for key byte 8
[38 37 36 39] 26.50988030157714
Found candidate values for key byte 9
[235 234 233 232] 27.92000637561432
Found candidate values for key byte 14
[31 29 28 30] 24.38328817946058
Found candidate values for key byte 7
[31 30 29 28] 26.25190649225442
Found candidate values for key byte 15
[155 154 152 153] 25.824877112238028
可知,推测出了密钥的第7、8、9、14、15字节的可能值,但还有密钥的第6、10、11、12、13字节没有推测出来,可继续使用推测出来的新的字节推测未知字节,如下:
# 这里使用新猜测出来的密钥的字节,继续进行运算
l_ref_7 = labels_all[7,:,31]
l_ref_8 = labels_all[8,:,38]
l_ref_9 = labels_all[9,:,235]
l_ref_14 = labels_all[14,:,31]
l_ref_15 = labels_all[15,:,155]
# 下面使用第7字节推测第11字节,使用第8字节推测第12字节,以此类推
keysearch(l_ref_7, [11])
keysearch(l_ref_8, [12])
keysearch(l_ref_9, [13])
keysearch(l_ref_14, [6,10])
keysearch(l_ref_15, [11])
第二轮推测结果如下,此处只取了前4个最有可能的结果。
Found candidate values for key byte 13
[220 221 223 222] 25.277842895970025
Found candidate values for key byte 10
[50 48 51 49] 24.61651797495142
可知,新推测出了密钥的第10、13字节的可能值,但还有密钥的第6、11、12字节没有推测出来,可继续使用推测出来的新的字节推测未知字节,如下:
# 还有第56字节没有结果,继续使用新得到的第10字节的结果推测第6字节
l_ref_10 = labels_all[10,:,50]
keysearch(l_ref_10, [2,6,14])
第三轮推测结果如下,此处只取了前4个最有可能的结果。
Found candidate values for key byte 14
[31 29 30 28] 24.61651797495142
可知,只是推测出了密钥的第14字节的可能值,而这个结果前文已经得到了,所以密钥的第6、11、12字节仍然还没有推测得到。这里将家族的范围扩大,用密钥的任一字节使用keysearch函数推测其余15字节的值。
l_ref_0 = labels_all[0,:,aes_key_prefix[0]]
l_ref_1 = labels_all[1,:,aes_key_prefix[1]]
l_ref_2 = labels_all[2,:,aes_key_prefix[2]]
l_ref_3 = labels_all[3,:,aes_key_prefix[3]]
l_ref_4 = labels_all[4,:,aes_key_prefix[4]]
l_ref_5 = labels_all[5,:,aes_key_prefix[5]]
l_ref_7 = labels_all[7,:,31]
l_ref_8 = labels_all[8,:,38]
l_ref_9 = labels_all[9,:,235]
l_ref_10 = labels_all[10,:,50]
l_ref_13 = labels_all[13,:,220]
l_ref_14 = labels_all[14,:,31]
l_ref_15 = labels_all[15,:,155]
keysearch(l_ref_0, range(16))
keysearch(l_ref_1, range(16))
keysearch(l_ref_2, range(16))
keysearch(l_ref_3, range(16))
keysearch(l_ref_4, range(16))
keysearch(l_ref_5, range(16))
keysearch(l_ref_7, range(16))
keysearch(l_ref_8, range(16))
keysearch(l_ref_9, range(16))
keysearch(l_ref_10, range(16))
keysearch(l_ref_13, range(16))
keysearch(l_ref_14, range(16))
keysearch(l_ref_15, range(16))
第四轮推测结果如下,此处只取了前4个最有可能的结果。
Using byte 0 as reference
/usr/local/lib/python3.8/dist-packages/numpy/core/fromnumeric.py:3440: RuntimeWarning: Mean of empty slice.
return _methods._mean(a, axis=axis, dtype=dtype,
/usr/local/lib/python3.8/dist-packages/numpy/core/_methods.py:189: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
Found candidate values for key byte 4
[70 69 68 71] 24.123295412107836
Using byte 1 as reference
Found candidate values for key byte 10
[51 49 50 48] 23.517249124646696
Using byte 2 as reference
Found candidate values for key byte 14
[31 29 28 30] 24.38328817946058
Using byte 3 as reference
Found candidate values for key byte 7
[31 30 29 28] 26.25190649225442
Found candidate values for key byte 15
[155 154 152 153] 25.824877112238028
Using byte 4 as reference
Found candidate values for key byte 0
[194 193 192 195] 24.123295412107836
Found candidate values for key byte 8
[38 37 36 39] 26.50988030157714
Using byte 5 as reference
Found candidate values for key byte 9
[235 234 233 232] 27.92000637561432
Found candidate values for key byte 12
[150 148 149 151] 25.77075236406381
Using byte 7 as reference
Found candidate values for key byte 3
[153 152 155 154] 26.25190649225442
Using byte 8 as reference
Found candidate values for key byte 4
[71 68 69 70] 26.50988030157714
Using byte 9 as reference
Found candidate values for key byte 5
[254 255 252 253] 27.92000637561432
Found candidate values for key byte 13
[220 221 223 222] 25.277842895970025
Using byte 10 as reference
Found candidate values for key byte 1
[93 95 92 94] 23.517249124646696
Found candidate values for key byte 14
[31 29 30 28] 24.61651797495142
Using byte 13 as reference
Found candidate values for key byte 9
[235 234 232 233] 25.277842895970025
Using byte 14 as reference
Found candidate values for key byte 2
[122 120 121 123] 24.38328817946058
Found candidate values for key byte 10
[50 48 51 49] 24.61651797495142
Using byte 15 as reference
Found candidate values for key byte 3
[153 152 154 155] 25.824877112238028
Found candidate values for key byte 6
[13 14 15 12] 25.987920521583874
最终,推测出了密钥的第6、12字节的值,现在只剩下第11字节还没有推测结果。密钥所有字节的推测结果如表6-2所示。
表6-2 密钥所有字节的推测结果
密钥字节序号 | 候 选 值 | 密钥字节序号 | 候 选 值 |
0 | 0xc3 | 8 | [38 37 36 39] |
1 | 0x5c | 9 | [235 234 232 233] |
2 | 0x7a | 10 | [50 48 51 49] |
3 | 0x99 | 11 | |
4 | 0x47 | 12 | [150 148 149 151] |
5 | 0xfe | 13 | [220 221 223 222] |
6 | [13 14 15 12] | 14 | [31 29 30 28] |
7 | [31 30 29 28] | 15 | [155 154 152 153] |
整个解空间大小减少到了,因为已知部分明文,所以可以使用暴力破解法,通过穷举所有的可能性对挑战题给出的密文进行解密,对比已知的部分明文,最终确定正确的密钥。暴力破解的主要代码如下:
# 这里没有使用brute工具,而是直接编写了一个软件,原理也是穷举法,利用已知flag的前面几个字母进行
# 对比,得到最终的密钥
flag_ct = bytearray.fromhex('c4c0813def58a83d9445043e1e9213d0c2a3dc6abef0ec4cdd0b 58c6d8301c8569b257fb6270771247637097f012cfd2520f1924de203ff40ff64d1b8e3c99cf')
ct_bf = flag_ct[0:16]
_11 = range(256)
_6 = [13, 14, 15, 12]
_7 = [30, 31, 29, 28]
_8 = [38, 37, 36, 39]
_9 = [235, 234, 233, 232]
_10 = [50, 51, 48, 49]
_12 = [150, 148, 149, 151]
_13 = [220, 221, 223, 222]
_14 = [31, 29, 30, 28]
_15 = [155, 154, 152, 153]
%%time
for i in itertools.product(_6,_7,_8,_9,_10,_11,_12,_13,_14,_15):
key = aes_key_prefix + bytearray(i)
cipher = AES.new(key, AES.MODE_ECB)
pt = cipher.decrypt(ct_bf)
if pt == b'flag':
print('Key recovered:', key.hex())
Break
本书使用Intel i7-10750H处理器、32GB内存的计算机进行暴力破解,用时9min21s。结果如下:
Key recovered: c35c7a9947fe0c1f27eb317495dd1f9b
CPU times: user 9min 21s, sys: 323 ms, total: 9min 21s
Wall time: 9min 21s
由于AES是对称加密算法,所以其加密、解密密钥是一样的,使用得到的密钥对密文进行解密,最终可以得到flag值。
- 0 文章数
- 0 关注者