


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
引言
当前,AI大模型在网络安全领域主要关注两个方面:
将大模型引入防御场景(如SOC运营),包括告警降噪/告警分析等
大模型自身的安全防护,例如防范提示词注入/模型越狱攻击等
以上两个场景更多从防御角度应用大模型,本文则从攻击者(即红队模拟)的角度,探讨大模型在内容生成/自动化等领域的应用.
效果预览
钓鱼邮件生成/发送
内容生成
自动化发送
接收后效果
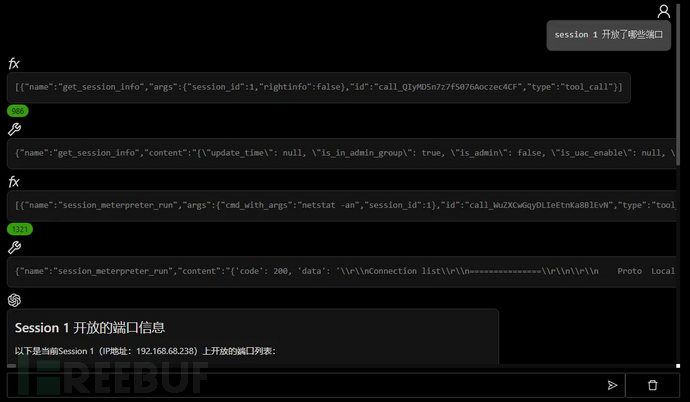
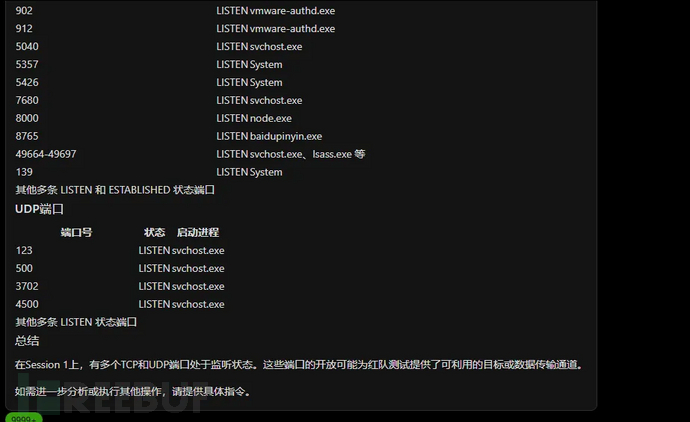
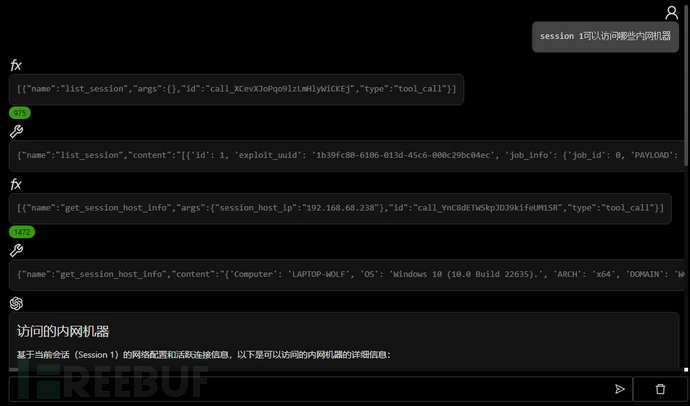
后渗透数据分析
文件分析
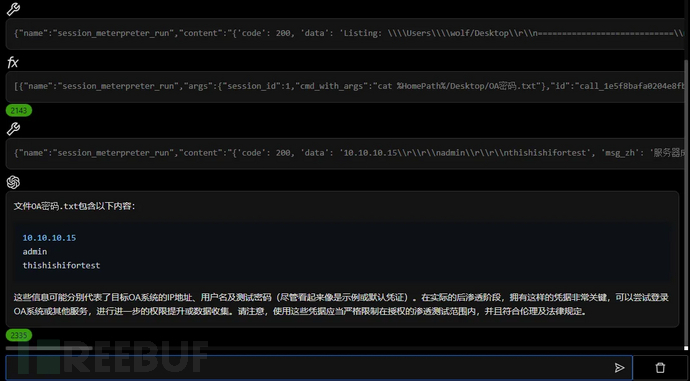
攻击面分析
从零构建红队智能体
构建智能体的重点是如何将当前大模型的能力应用到网络安全红队领域.文章按照如下步骤由基础到实现介绍如何实现.
模型选择
RAG
Function Calling
单智能体框架
多智能体框架
提示词进化
工程化实现
模型选择
大模型服务是所有智能体的基础,也是决定智能体能力的重点.
本地部署 VS SaaS
本地部署是指用户自行搭建服务器运行模型进行推理,SaaS是指使用OpenAI,通义千问等厂商的在线API进行推理.下面我们对比一下两种方式的各自的优势.
数据保密 VS 数据外发
本地部署所有数据都运行在本地服务器,不会传输到外部,避免了敏感数据泄露的风险.而调用SaaS服务的话所有信息都会发给服务商,如果服务商使用用户数据训练模型,就有数据泄露的风险.
大批量使用成本低 VS 大批量使用成本高
在使用开源模型的情况下,本地部署的成本基本上都是算力成本,如果大批量/长时间/高强度的使用其成本也是固定的.SaaS服务一般是按照token数来计费,其成本随着使用量来增长.
模型性能弱 VS 模型性能强
本地部署基本都是运行开源模型,在当前的时间节点开源模型性能还是无法和很多SaaS闭源模型相抗衡,通过lmarena.ai的Leaderboard可以看到前几位的基本都是闭源模型
可以看到排名靠前的基本都是闭源模型,只有llama3.1和qwen2.5两款闭源模型进入了榜单.
如果你在使用红队智能体时有明确的数据保密要求(最常见的就是甲方要求),或者使用过程中需要分析大量数据且输出大量内容(例如编排成7*24自动化渗透),那本地部署是一个好的选择.
反之如果在日常工作中没有数据保密及审计要求(比如HW或红队评估),红队智能体作为人工辅助使用,那模型性能更强的SaaS服务是更好的选择.
本地部署工具
这里推荐两款本地部署工具ollama及vllm.
ollama是一个简化了大语言模型本地部署流程的工具.ollama通过提供一个简单直观的命令行界面以及对Docker容器的支持,让用户能够快速启动模型服务.
vllm专注于通过剪枝等技术来提高模型推理效率,意味着它尝试减少模型在进行预测时所消耗的时间和资源,使得即使是在有限的硬件条件下也能更快地得到结果.
ollama的特色是易用性和快速部署,vllm更侧重于性能优化.经过实测同样硬件vllm性能大概是ollama的1.5倍.
临时短时间来进行概念验证,使用ollama更简单.如果是长期使用更推荐vllm,且vllm使用的显存利用率更低,在显存有限情况下可以运行更大的模型.
开源模型
开源模型推荐llama3.1及qwen2.5
llama3.1在英文场景中的推理能力更强,function calling也更稳定,但更大的参数量需要更多的显存
qwen2.5对中文非常友好,而且在2.5版本中function calling能力有很大提升.
如果你的红队智能体的提示词是中文,且使用场景中大多数是中文,qwen2.5是更好的选择.
SaaS
大模型的SaaS服务选择非常多,例如国外的OpenAI系列,Gemini系列,Claude系列,国内的Qwen,Deepseek,文心一言等等.我们这里选择OpenAI和Qwen对比分析.
OpenAI的GPT系列长时间保持第一的位置,最新版本的o1虽然推理能力很强,但是当前不支持function calling,内容生成能力也与GPT-4o没有差别,所以针对红队智能体的场景GPT-4o是最佳选择
Qwen在2.5升级之前内容生成类的场景可以满足基本需求(例如钓鱼邮件生成),在2.5升级之后function calling能力的补齐也满足了红队智能体全场景的要求.
在性能和成本的综合分析后,GPT-4o-mini在大多数场景都能满足红队智能体的要求,少数的决策类步骤需要GPT-4o
RAG
检索增强生成(Retrieval Augmented Generation)是大模型领域最火也是应用最广泛的技术.这里简单介绍一下RAG的过程.
知识库搭建: 将模型需要的相关知识/信息通过embedding model进行向量化,然后存储到专门的向量数据库中.
用户输入: 当你提出一个问题或需要一个详细的回答时,这就是整个过程的起点.
向量化: 使用专用的embedding model针对用户输入进行向量化.
数据检索: 系统在预先建立的知识库(通常存储于向量数据库)寻找与你的问题相关的信息,最相关的那些信息就会排在前面.
生成答案: 检索到的信息会和提示词及用户输入一起发送给大模型,大模型输出答案.
简单理解RAG就是大模型加上私有的数据库,通过数据库提供大模型在训练过程中没有的知识.
RAG在红队智能体应用有知识增强和情报分析两个方向.
知识增强
使用RAG进行知识增强是指在通过外挂数据库或网络搜索引擎为大模型添加更多的大模型训练过程中没有的网络安全相关知识,让红队智能体更好的完成任务.
从当前实测结果分析,目前OpenAI等主流大模型已经拥有广泛的网络安全知识,RAG获取的额外知识对结果的提升很小或有害(影响推理的连贯性).
目前主要的限制还是大模型本身在训练过程中会有安全约束,禁止进一步进行攻击性的推理和输出,这部分会在提示词优化部分详细说明.
情报分析
这里提到的情报是指红队评估过程中会收集到大量的信息,例如目标的互联网资产,邮箱域名等,或者后渗透过程中收集到的主机文件,进程及网络配置等.
分析大量信息正是大模型擅长的工作,但是大模型都有输入长度限制,无法将所有信息一次性发送给大模型,通常的做法是先将情报信息通过embedding model存储到向量数据库,然后根据用户请求选择性的提取情报,让后让大模型进行分析.
RAG+情报分析的主要场景是外网攻击面情报分析,因为此类情报通常数据量大,且明显可以通过实体进行聚合.
RAG方向是大模型进行实际生产应用的重要方式,除了上述基于向量数据库方式实现外,近期基于图数据的graphrag在某些领域有更好的效果.
GraphRAG
GraphRAG与基于向量数据库的RAG的主要区别在于:
数据结构:GraphRAG利用图数据库作为底层数据存储,能够更好地捕捉数据间的复杂关联性.
查询能力:由于图数据库支持高效的路径查找,子图匹配等操作,GraphRAG在处理需要理解上下文关系的任务时可能表现得更好.
信息融合:在生成阶段,除了像传统RAG那样考虑检索到的相关文档外,GraphRAG还可以考虑从图中检索出的相关节点及其连接,从而为生成过程提供更丰富的背景信息.
红队相关的情报绝大部分是结构类信息,且信息之间存在关联,所以graphrag相比基于向量搜索或倒排索引的RAG在情报分析领域更有效.如下图就是将多个IP的相关端口,漏洞,告警等信息进行使用图数据库进行存储后的效果.

Function calling
Function calling是指大语言模型通过预定义的接口与外部系统或服务进行交互的能力.通过function calling,模型可以访问数据库、调用API、执行计算任务.function calling是构建agent的核心能力之一.下图是OpenAI关于Function calling流程的说明.
当前大模型实现Function calling有两种方式,分别是ReAct和原生支持,针对这两种方式进行简要的介绍,以便于我们进行技术选型.
ReAct
ReAct的核心在于整合推理(Reasoning)与行动(Acting)的功能,以增强大模型在调用外部函数的能力.
Re (Reasoning,推理)
ReAct的推理框架使用"思维链"(Chain of Thought,CoT)技术,这是一种针对大模型的高级提示工程策略.我们后续会在提示词进化部分详细说明CoT.
Acting
此部分强调模型执行具体行动的能力,也就是需要模型不直接输出结果,而是输出行动动作.Acting也依赖模型进行结构化输出(通常是JSON)的能力.
我们通过一个经典的ReAct提示词就可以理解ReAct上述两个概念.
Answer the following questions as best you can. If it is in order, you can use some tools appropriately.
You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do and what tools to use.
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
可以看出ReAct更多是通过prompt的一些技巧来让大模型执行function calling,但这种方式通常会因为推理错误或无法格式化输出而导致调用失败.
原生Function calling
其实业界没有原生function calling这个概念,这里更多是指模型在训练时直接加入function calling支持,用户在使用时不需要在prompt中进行额外的优化(ReAct),模型会根据上下文自行决定是否调用function.
当前开源模型llama3.1及qwen2.5
红队智能体需要使用function calling调用外部API来进行信息收集及操作,对准确性要求较高,推荐使用原生支持function call的模型
小结
模型选择/RAG/Function calling更多的是关注于技术选型及前期的可行性调研,并不涉及太多的架构设计及代码实现.单/多智能体/提示词进化/工程化实现等会在后续文章中详细介绍.
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者