


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 伏念
伏念- 关注
 本文由
伏念 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
伏念 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
系列文章:
机器学习几种包的使用方法
因为针对一些同学的机器学习基础不好我下面对机器学习几种包简单描述一下:
pandas库是机器学习里的数据分析库我们可以把它简单看做execl
sklearn库是机器学习里必须要用到的包,里面集成多种计算方法包括无监督学习、监督学习等
matplotlib库是python绘图库(就是给你作图画画用的)
nmupy是python的数组函数库内置各种数学函数可以对数据进行矩阵运算以及n维数组的运算,想快速学习数学知识的同学直接看这个库的官方文档即可,该库配合matplotilb可以进行直观得展示
对dns.log数据进行机器学习算法
导入相关库
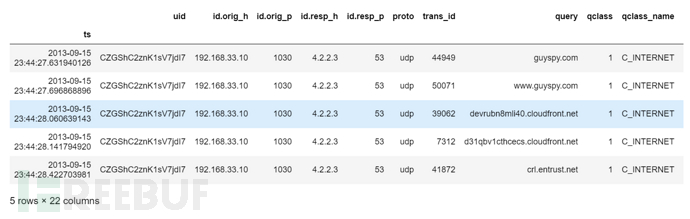
 获取zeek数据集并输出数据
获取zeek数据集并输出数据
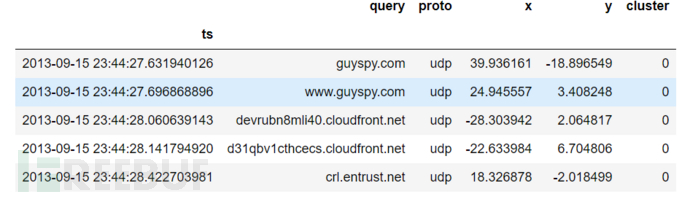
使用Pandas可以高效计算数据得指标,这里我们使用P化运算andas/Numpy的矢量来计算查询长度![]()
由于DNS数据记录的是数值以及文本所以我们需要一种方法进行统一的运算,zat有一个DataFrameToMatrix类,该类处理数值数据和文本数据具备许多细节和机制,我们将在下面使用。

然后使用 zat scikit-learn transformer类将Pandas DataFrame 转换为 numpy ndarray(矩阵)
使用zat DataframeTomatrix类处理分类数据在发送到转换器之前进行显式转换

现在我们有了一个numpy ndaray matrix,接下来就可以进行sklearn
现在我们开始scikit学习了,下面的示例只是一个简单的内容,即KMeans和TSNE映射

绘制机器学习结果
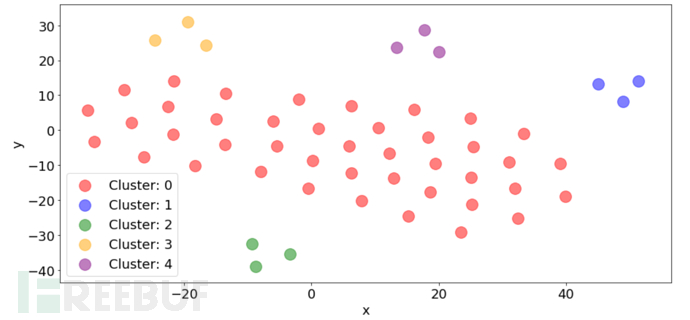
让我们调查5个DNS数据群集
我们将大量功能放入了聚类算法。特征既是数字的又是文本的。集群是否“做了正确的事”?首先,请注意以下几点:
显然,我们正在处理少量的Zeek DNS数据
这是一个展示转换如何工作的示例(从Zeek到Pandas到Scikit)
DNS数据是真实数据,但对于本示例和其他示例,我们故意引入了其它的东西
我们知道KMeans中的K应该是5 :)
好的,所有这些警告都将让我们看看聚类如何对数字数据和分类数据进行合并集群详细
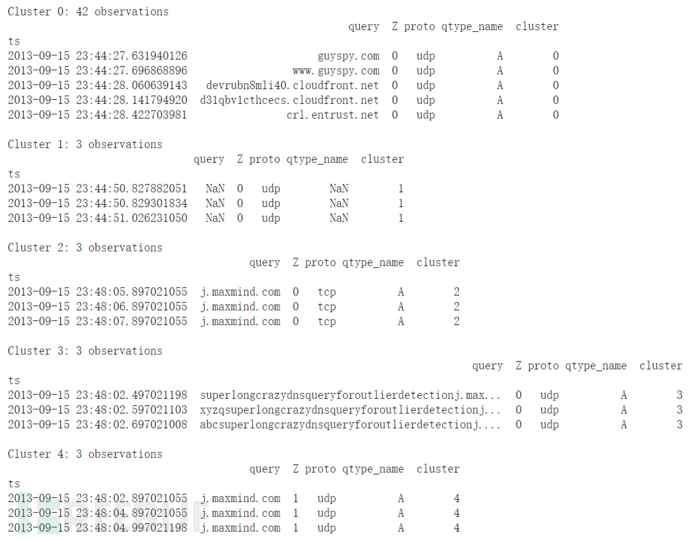
群集0:(42个观察结果)看起来像是“正常” DNS请求
群集1:(11个观察结果)所有查询均为“-”(Zeek for NA /未找到/等)
集群2:(6个观察结果)协议是TCP而不是普通的UDP
群集3:(4个观察结果)所有DNS查询都异常长
群集4:(4个观测值)保留的Z位设置为1(要求为0)
数值+范畴= AOK
通过我们的示例数据,我们已经成功地从Zeek日志到Pandas到scikit-learn。几个群集都很有意义,从调查和威胁搜寻的角度来看,将数据群集使用PCA进行降维可能会派上用场,具体取决于你的样例

总结
下一篇将简单介绍一下如何使用sprark处理zeek大批量数据集
已在FreeBuf发表 4 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 图灵
图灵
 安全渗透与测试
安全渗透与测试
 日志审计与APT
日志审计与APT






- 4 文章数
- 41 关注者