


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 腾讯安全科恩实验室
腾讯安全科恩实验室- 关注
导语
在NeurIPS 2020中,腾讯安全科恩实验室使用AI算法解决二进制安全问题的《CodeCMR: Cross-Modal Retrieval For Function-Level Binary Source Code Matching》论文成功入选。本论文首次提出了基于AI的二进制代码/源代码端到端匹配算法,与传统算法相比效果非常出色,准确率大幅提升。本论文成果为逆向分析领域提供了新的思路,大大提升工业部署效率。最新论文研究成果也将应用于腾讯安全科恩实验室研发的代码检索工具BinaryAI,使用体验请关注:http://github.com/binaryai/sdk。
关于NeurIPS会议
机器学习和计算神经科学领域的NeurIPS会议是人工智能领域最具影响力的顶级学术会议之一,备受学者们的关注。国际顶级会议NeurIPS 2020将于2020年12月7日-12日在线上举行。据统计,NeurIPS 2020收到投稿9454篇,创历史最高纪录,接收论文1900篇,论文接收率仅有历史最低的20.1%。
背景
论文链接:CodeCMR: Cross-Modal Retrieval For Function-Level Binary Source Code Matching
在人工智能顶级学术会议AAAI 2020中,腾讯安全科恩实验室利用图神经网络解决二进制程序函数相似性分析问题的技术得到了广泛关注。在此基础上,本次研究方向扩展到二进制代码与源代码的交叉领域,进一步实现腾讯安全科恩实验室在AI+安全新兴方向中的全新探索与突破。
二进制代码-源代码匹配是信息安全领域的重点研究方向之一。在给定二进制代码的情况下,逆向分析研究人员希望找到它对应的源代码,从而提升逆向分析的效率和准确率。但由于源代码和二进制代码的差异性,在此领域的研究较少。B2SFinder[1]和BinPro[2]等传统算法提取源代码和二进制代码的字符串、立即数等特征进行匹配。然而,函数级别的源代码与二进制代码的特征非常少,匹配准确率不高。另一方面,设计合适的特征需要大量的专家经验。
图1展示了一个函数的源代码与二进制代码。从图1中可以看出,除了字符串和立即数特征,代码中隐藏的语义特征也很关键。因此,本文希望设计一种端到端模型,可以自动提取代码间的语义特征,从而提升匹配的准确率。
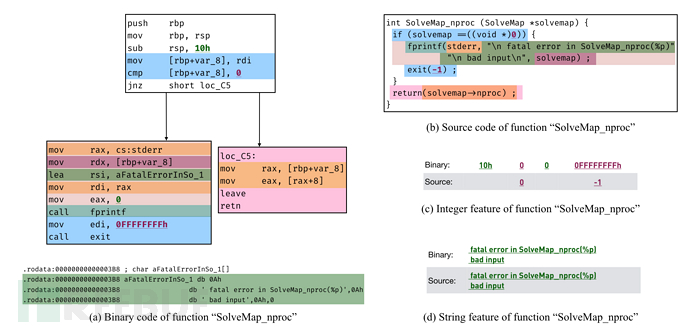 图1 - 二进制代码与对应的源代码
图1 - 二进制代码与对应的源代码
模型
这是一个二进制代码-源代码间的检索任务,我们把两种代码当作两个模态的输入,即可类比到图文互搜等跨模态检索场景。因此,我们设计了如图2所示的CodeCMR框架,在跨模态检索领域中,这是一种比较常见的结构[3, 4]。在计算最终向量之前,两个模态之间没有信息传递,因此在实际应用时可以预先计算向量,可以节省大量的线上计算时间以及存储空间。
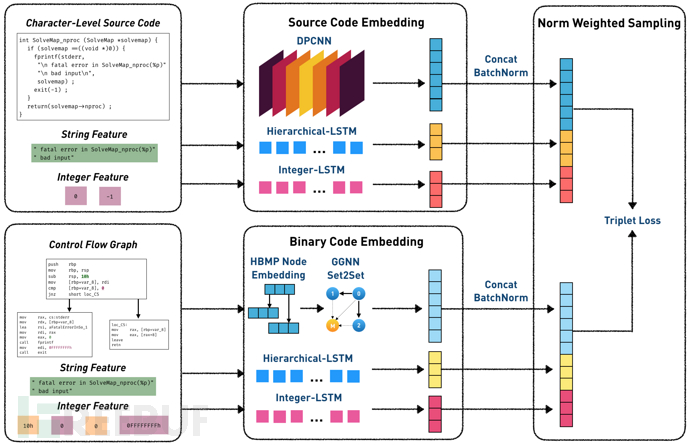
图2 - CodeCMR整体框架
整体结构
模型的输入有源代码特征和二进制代码特征两个部分。其中源代码特征是字符级别的源代码、从源代码中提取的字符串和立即数;二进制代码特征是控制流图、二进制代码的字符串和立即数。首先将三个输入(语义特征、字符串特征、立即数特征)分别用不同模型计算得到向量,再用拼接+BatchNorm的方式得到代码向量,最后用triplet loss[5]作为损失函数。
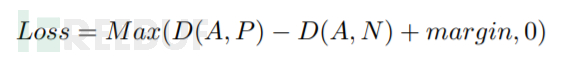
在这个基础框架上,有许多可以改进的创新点,例如使用预训练模型做语义融合、使用adversarial loss对齐向量等,对此我们将在后文讨论。
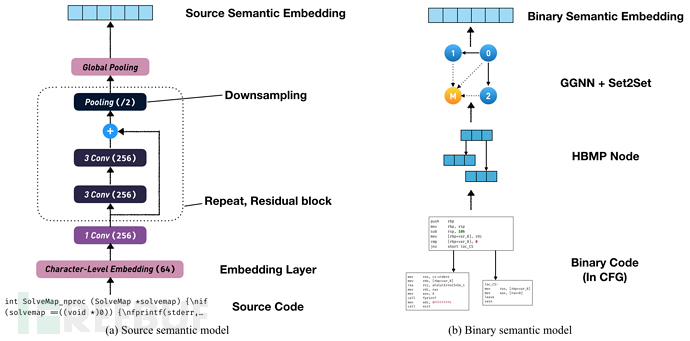
图3 - 源代码与二进制代码的语义模型
语义模型
如图3所示,对于字符级源代码,我们使用的是DPCNN模型[6];对于二进制控制流图,我们使用的是端到端的GNN模型。在函数级别,字符级源代码的输入通常在4096以上,DPCNN的效果远优于TextCNN和LSTM。对于控制流图,我们没有使用BERT预训练的node embedding作为输入[7],而是采用了端到端训练的方式,取得了更好的效果。
在这个阶段,本文使用的是DPCNN和GNN,但ASTNN等树模型也同样值得尝试。由于输入是函数级别的代码,缺少#define、#include等重要信息,需要设计合适的编译工具将源代码转化为AST。相比之下,我们直接将文本作为输入的优点是无需额外的专家经验,健壮性强。
立即数、字符串模型
对于源代码与二进制代码的立即数和字符串,我们同样设计了模型进行匹配。
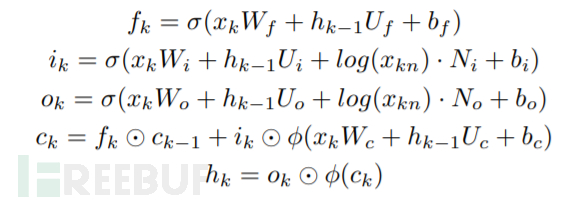
对于立即数,我们设计了一种Integer-LSTM。它的输入有integer token和integer number两个。integer number作用在LSTM的输入门和输出门,从而控制信息流动。
对于字符串,我们使用的是层次模型,先用LSTM模型得到每个字符串的向量,再使用sum pooling的方法得到字符串集 合的向量。
Norm weighted sampling
在得到源代码与二进制代码的向量后,我们设计了一种采样方法。在metric learning领域中,损失函数和采样方法是十分重要的两个模块。为了解决hard样本在训练早期收敛到局部极小值的问题,[5]提出了semi-hard采样方法。然而,[8]指出这种采样方法可能会在某个时间段停止训练,从而提出了distance weighted sampling采样方法解决这个问题:
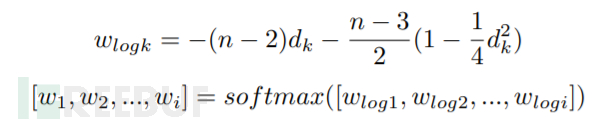
distance weighted sampling可以在分布中选择各个概率的样本,而semi-hard、hard、uniform等采样方法只能选择特定分布的样本。在此基础上,本文提出了一个改进,即增加一个超参数s,帮助调整概率的分布,从而适应不同的任务和数据集。
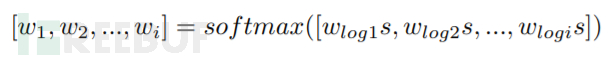
实验
数据集与评测指标
本文分别用gcc-x64-O0和clang-arm-O3作为两种组合方式,制作了两个30000/10000/10000的训练/验证/测试集,并使用recall@1和recall@10作为评测指标。数据集已公开在https://github.com/binaryai。
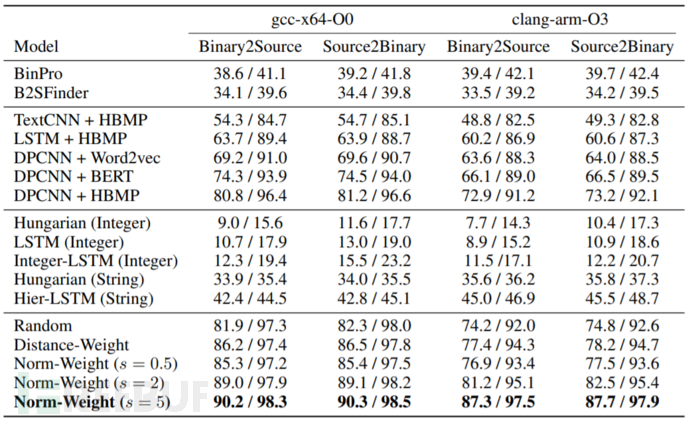
表1 - 实验结果
实验结果
如表1所示,本文提出的方法与传统方法相比有巨大提升,这一发现符合我们的预期,说明代码间隐含的语义特征十分重要。在语义模型中,DPCNN+HBMP取得了最优的效果,说明在二进制侧端到端训练优于预训练的node embedding。与随机采样和distance weighted采样方法相比,norm weighted采样效果更好。图4的train/valid loss曲线也证明了这一点,当s=5时norm weighted sampling的train loss更高但valid loss更低,这表示采样到更合适的样例pair。
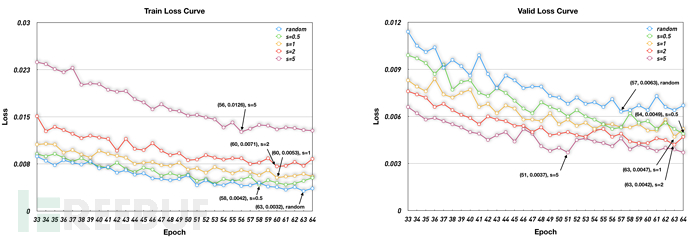
图4 - 训练与验证的损失函数曲线
讨论与总结
讨论
基于CodeCMR框架,有很多值得尝试的创新。
1)code encoder。ASTNN、Tree-LSTM、transformer等模型可能也同样有效。
2)其它损失函数和采样方法,如AM-softmax、Circle loss等。
3)对抗训练以及其它的跨模态检索领域的方法。
4)预训练算法。在获得最终向量前两个模态没有信息融合,因此在两个模态分别单独预训练或用跨语言模型的方法融合训练,均是值得尝试的。
总结
本文针对二进制代码-源代码匹配任务提出了CodeCMR框架,成功地利用了源代码与二进制代码间的语义特征。与传统方法相比,取得了很大的突破。
参考文献
- Yuan Z, Feng M, Li F, et al. B2SFinder: Detecting Open-Source Software Reuse in COTS Software[C]//2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2019: 1038-1049.
- Miyani D, Huang Z, Lie D. Binpro: A tool for binary source code provenance[J]. arXiv preprint arXiv:1711.00830, 2017.
- Wang H, Sahoo D, Liu C, et al. Learning cross-modal embeddings with adversarial networks for cooking recipes and food images[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 11572-11581.
- Wang B, Yang Y, Xu X, et al. Adversarial cross-modal retrieval[C]//Proceedings of the 25th ACM international conference on Multimedia. 2017: 154-162.
- Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823.
- Johnson R, Zhang T. Deep pyramid convolutional neural networks for text categorization[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. 2017: 562-570.
- Yu Z, Cao R, Tang Q, et al. Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(01): 1145-1152.
- Wu C Y, Manmatha R, Smola A J, et al. Sampling matters in deep embedding learning[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2840-2848.
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)





- 28 文章数
- 36 关注者