


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 xssle
xssle- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
HTTP走私漏洞分析
1.HTTP简介:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。。HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
2.漏洞描述:
HTTP Request Smuggling最早是在2005年由Watchfire记录的,但是由于其利用条件比较苛刻,很长一段时间,Web层面的漏洞如雨后春笋般冒了出来,就像之前的不被重视的xss一样,HTTP Request Smuggling同样被忽略了。但大神们总是能带来神奇的体验,利用此漏洞成功拿到了近70K$的奖金,这不仅让许多互联网大厂重视了起来,也让该漏洞走进了安全爱好者的视野。
3.名词释义:
在解释枯燥的原理之前,为了让大家更好的理解下边的内容,先对三个术语进行一下解释。这三类技术的发展也从侧面反映了互联网技术的进步,所有技术的进步都是以进步为前提,安全总是考虑的不够全面,这其中的风险,已经有了很多血的教训。
Persistent Connection(持久连接,也就是长连接)
为啥要给大家解释长连接呢?因为这和漏洞原理有关。
举一个可能不太恰当的例子,我正在家里一个人看电影,突然我的小伙伴史奴比给我打电话告我今天晚上有好事找我,我顿时来了兴趣,正当我期待之情顺着电话线传到他那边之时,电话被挂断了,好么继续看电影,没过一会又打来了,告我晚上要请我吃饭,好么,没说完又挂了。隔了几分钟又打来了,不是为了这顿饭我可能都把她拉黑了,这次告了我晚上几点,陆陆续续折腾了七八通电话,这件事终于搞定了。为了饭,忍了!
那么为啥她不能一次性说完呢?持久的通话,或者和我有一个持久的连接把所有的信息都传输给我,再挂电话。
HTTP 运行在 TCP 连接之上,也存在TCP三次握手的特点,慢启动等特点,科学家们为了尽可能提高HTTP的性能,长连接便由此诞生了。HTTP 协议加入了相应的机制。通过 Connection: keep-alive 这个头部来实现,服务端和客户端都可以使用它告诉对方在发送完数据之后不需要断开 TCP 连接。
对于非持久连接,浏览器可以通过连接是否关闭来界定请求或响应实体的边界;而对于持久连接,这种方法显然不奏效。如果我已经发送完所有数据,但浏览器并不知道这一点,它无法得知这个打开的连接上是否还会有新数据进来,只能傻傻地等了。
为了解决这个问题我们引入Content-length。
Content-length(实体长度)
接着上个例子,史奴比打来电话告我给它五分钟时间,噼里啪啦说了一大堆,我勉强听懂了,那么开始的这个五分钟就可以理解为一个内容长度的衡量标准。
浏览器可以通过 Content-Length 的长度信息,判断出响应实体已结束。那如果 Content-Length 和实体实际长度不一致会怎样?通常如果 Content-Length 比实际长度短,会造成内容被截断;如果比实体内容长,会造成 pending。
在进行 WEB 性能优化时,有一个重要的指标叫 (Time To First Byte)TTFB,它代表的是从客户端发出请求到收到响应的第一个字节所花费的时间。大部分浏览器自带的 Network 面板都可以看到这个指标,越短的 TTFB 意味着用户可以越早看到页面内容,体验越好。可想而知,服务端为了计算响应实体长度而缓存所有内容,跟更短的 TTFB 理念背道而驰。但在 HTTP 报文中,实体一定要在头部之后,顺序不能颠倒,为此我们需要一个新的机制:不依赖头部的长度信息,也能知道实体的边界。
接着我们再引入一个新的概念。
Transfer-Encoding: chunked(分块编码)
主角终于再次出现了,Transfer-Encoding 正是用来解决上面这个问题的。历史上 Transfer-Encoding 可以有多种取值,为此还引入了一个名为 TE 的头部用来协商采用何种传输编码。但是最新的 HTTP 规范里,只定义了一种传输编码:分块编码(chunked)。
分块编码相当简单,在头部加入 Transfer-Encoding: chunked 之后,就代表这个报文采用了分块编码。这时,报文中的实体需要改为用一系列分块来传输。每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(\r\n),也不包括分块数据结尾的 CRLF。最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
4.漏洞原理:
从HTTP / 1.1开始,支持通过TCP或SSL / TLS套接字发送多个HTTP请求。服务器解析标头以计算出每个结束的位置以及下一个开始的位置。
就其本身而言,这是无害的。但是,现代网站由系统链组成,所有系统都通过HTTP进行通信。这种多层体系结构接收来自多个不同用户的HTTP请求,并通过单个TCP / TLS路由连接它们。
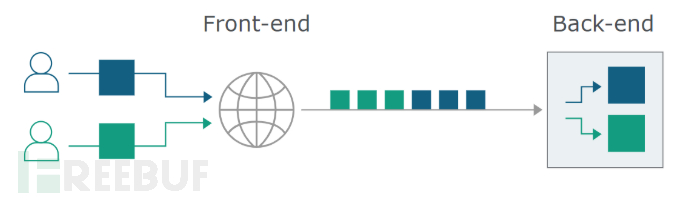
这意味着突然之间,后端服务器与前端服务器(后端服务器之前对请求进行预处理的服务器或者理解为请求的中转站)就每个消息的结束位必须要达成一致。否则,攻击者可能能够发送一个模糊不清的请求,该请求被后端解释为一个完整的请求加上残缺的下一个请求。
注意这种情况前端发送的是一个完整的请求,当这个请求到达后端时,后端和前端对于请求结束认证 的方式不一致导致后端认为后一个残缺的请求需要和下一个正常的请求进行拼接。就像下面这个图。
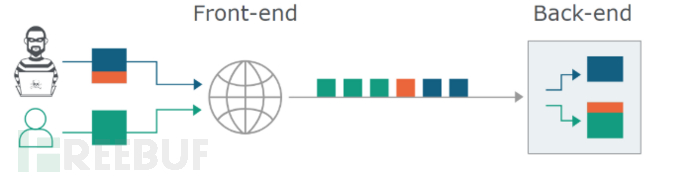
这使攻击者能够在下一个合法用户的请求开始时添加任意内容。在整个HTTP请求内容中,被走私的内容将被称为“前缀”,并以橙色突出显示。
让我们想象一下,前端优先考虑第一个内容长度标头也就是Content-length标头,而后端优先考虑第二个内容长度标头也是Content-length但在真实的环境这种CL-CL情况非常少见。举一个简单的例子

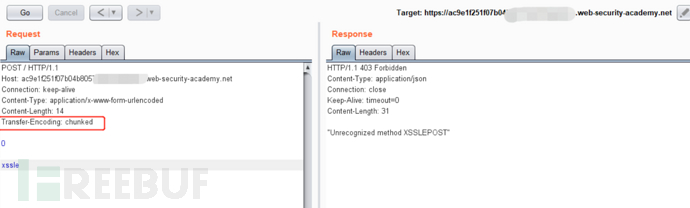
在后台,前端将蓝色和橙色数据转发到后端,后端仅在发出响应之前读取蓝色内容。这会使后端套接字充满橙色数据。当合法的绿色请求到达时,橙色内容会附在下一个正常请求之前,从而导致意外的响应。
在此示例中,注入的“ G”将破坏绿色用户的请求,并且他们很可能会获得“未知方法GPOST”的响应。
本文中的每种攻击都遵循这种基本格式。《 Watchfire》论文描述了一种称为“向后请求走私”的替代方法,但这依赖于前端和后端系统之间的对于请求结束不同认证的操作,才会导致该种漏洞。
在现实生活中,双重内容长度技术很少起作用,因为许多系统明智地拒绝具有多个内容长度标头的请求。相反,我们将使用分块编码来攻击系统-这次我们有了RFC 2616规范:
如果收到的消息同时带有一个Transfer-Encoding头域和一个Content-Length头域,则后者必须被忽略。
由于该规范允许同时使用Transfer-EncodingA: chunked和Content-length处理请求,因此很少有服务器拒绝此类请求。每当我们找到一种在链中的一台服务器中隐藏Transfer-Encoding标头的方法时,它都会退回到使用Content-Length的方式,并且可以使整个系统不同步。
我们在前边也提到了对于分块编码的解释,因为Burp Suite之类的工具会自动将分块的请求/响应缓冲到常规消息中,以便于编辑。这也导致了一下问题。
许多安全测试人员都不知道可以在HTTP请求中使用分块编码,原因有两个:
1.Burp Suite会自动解压缩分块的编码,以使邮件更易于查看和编辑。
- 2.浏览器通常不会在请求中使用分块编码,通常只能在服务器响应中看到。
在分块消息中,主体由0个或更多块组成。每个块均由块大小,后跟换行符(\ r \ n)和块内容组成。消息以大小为0的块终止。这是使用块编码的简单去同步攻击:
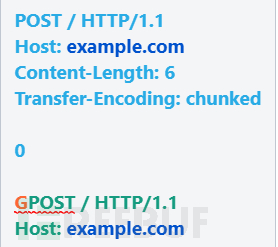
我们并没有在这里隐藏Transfer-Encoding标头,因此,此漏洞利用将主要在前端根本不支持分块编码的系统上起作用。
如果后端不支持分块编码,则需要翻转偏移量: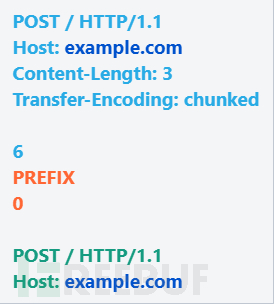
如果前端服务器和后端服务器都拥有这些特点,除非服务器对这些特点进行了纠正,否则就会构成重大威胁。
5.漏洞利用:
这里对三种类型漏洞进行利用,这里演示过程利用的是burp官方给出的环境,自行申请。
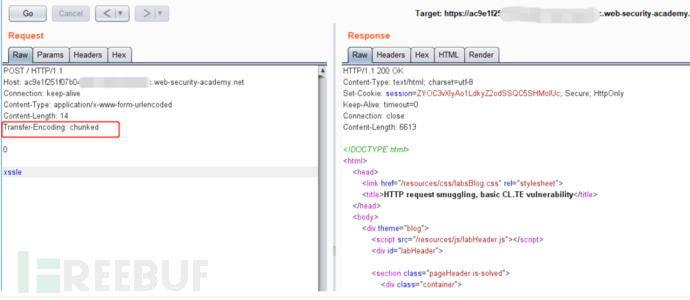
CL.TE: 前端: Content-Length,后端: Transfer-Encoding
前端服务器处理Content-Length标头,并确定请求主体的长度为14个字节,直到xssle的末尾。该请求被转发到后端服务器。
后端服务器处理Transfer-Encoding标头,因此将消息正文视为使用分块编码。它处理第一个块,该块声明为零长度,因此被视为终止请求。接下来的字节xssle未被处理,后端服务器会将其视为序列中下一个请求的开始。
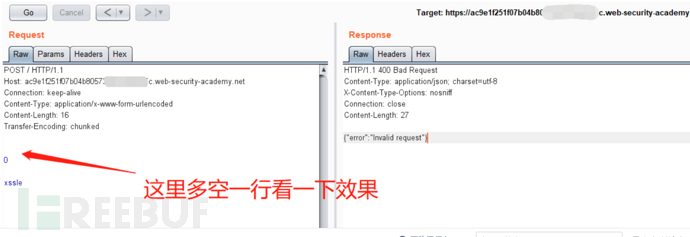
 块与块之间为什么要这样写呢?我们来试一试其他的写法
块与块之间为什么要这样写呢?我们来试一试其他的写法
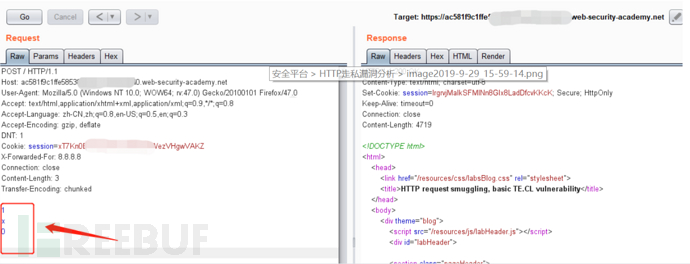
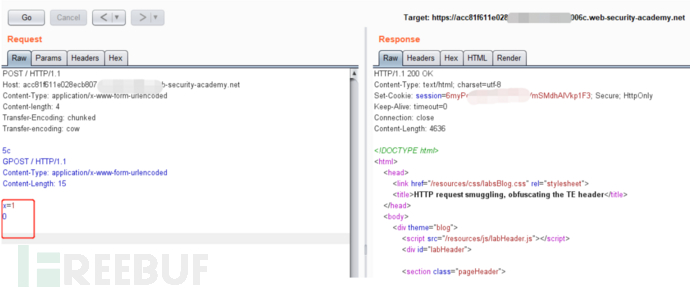
TE.CL: 前端: Transfer-Encoding,后端: Content-Length
注意:
- 如果使用Burp Repeater发送此请求,您首先需要转到Repeater菜单,并确保未选中“ Update Content-Length”选项。您需要在末尾0之后包含尾随序列\ r \ n \ r \ n。
前端服务器处理Transfer-Encoding标头,因此将消息正文视为使用分块编码。它处理第一个块,声明为1个字节长,直到l之后的行的开始。它处理第二个数据块,该数据块的长度为零,因此被视为终止请求。该请求被转发到后端服务器。
后端服务器处理Content-Length标头,并确定请求正文的长度为3个字节,直到1之后的行的开头。接下来的字节x0未经处理,后端服务器会将其视为序列中下一个请求的开始
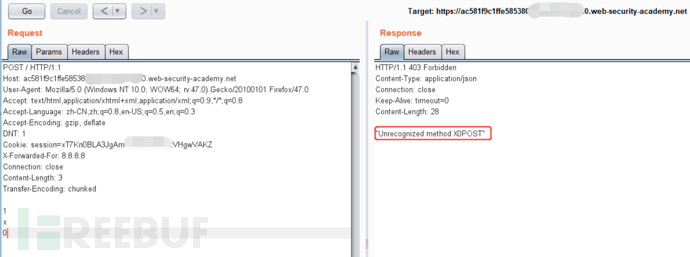 TE.TE: 前端: Transfer-Encoding,后端: Transfer-Encoding
TE.TE: 前端: Transfer-Encoding,后端: Transfer-Encoding
在这里,前端服务器和后端服务器都支持Transfer-Encoding标头,但是可以通过对标头进行某种方式的混淆来诱导其中一台服务器不对其进行处理。
这里列出七种混淆方式
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[space]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
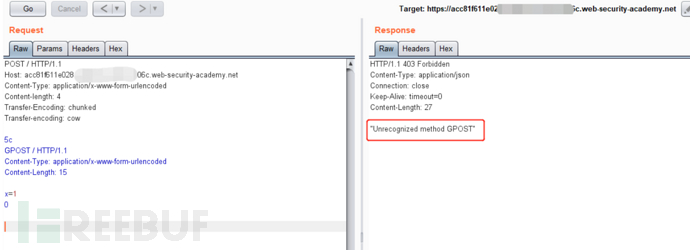 这些技术中的每一种都涉及与HTTP规范的细微差异。实现协议规范的实际代码很少会绝对精确地遵循该规范,并且不同的实现通常会容忍规范的不同变化。要发现TE.TE漏洞,必须找到Transfer-Encoding标头的某些变体,以便仅前端服务器或后端服务器之一对其进行处理,而另一服务器将其忽略。
这些技术中的每一种都涉及与HTTP规范的细微差异。实现协议规范的实际代码很少会绝对精确地遵循该规范,并且不同的实现通常会容忍规范的不同变化。要发现TE.TE漏洞,必须找到Transfer-Encoding标头的某些变体,以便仅前端服务器或后端服务器之一对其进行处理,而另一服务器将其忽略。
6.漏洞的检测:
这里我们利用的是burp给出的线上实验环境,那我究竟该如何去检测这种漏洞而又不会影响正常用户发起的请求?
检测请求走私漏洞的一种明显方法是发出一个模棱两可的请求,然后发出一个正常的“受害者”请求,然后观察后者是否收到意外响应。但是,这极易受到干扰。如果另一个用户的请求在我们的受害者请求之前命中了中毒的套接字,那么他们将获得损坏的响应,我们将不会发现该漏洞。这意味着在流量很大的实时站点上,如果不利用过程中的大量真实用户,就很难证明存在请求走私行为。即使在没有其他流量的站点上,各种终止连接的应用程序也会造成误报。
为了解决这个问题,研究人员开发了一种检测策略,该策略使用一系列消息使脆弱的后端系统挂起并超时连接。该技术几乎没有误报,可以**可能导致误报的应用程序,而且最重要的是几乎没有影响其他用户的风险。
假设前端服务器使用Content-Length标头,而后端使用Transfer-Encoding标头。我将这种定位简称为CL.TE。我们可以通过发送以下请求来检测潜在的请求走私:
- 如果是CL.TE模式

由于较短的Content-Length,前端将仅转发蓝色文本,而后端将在等待下一个块大小时超时。这将导致明显的时间延迟。
如果两个服务器都处于同步状态(TE.TE或CL.CL),则该请求将被前端拒绝,或者被两个系统无害处理。最后,如果以相反的方式发生同步(TE.CL),则由于无效的块大小'Q',前端将拒绝该消息,而不会将其转发到后端。这样可以防止后端套接字中毒。
我们可以使用以下请求安全地检测TE.CL取消同步:

7.漏洞规则
检测请求走私漏洞的一种明显方法是发出一个模棱两可的请求,然后发出一个正常的“受害者”请求,然后观察后者是否收到意外响应。但是,这极易受到干扰。如果另一个用户的请求在我们的受害者请求之前命中了中毒的套接字,那么他们将获得损坏的响应,我们将不会发现该漏洞。这意味着在流量很大的实时站点上,如果不利用过程中的大量真实用户,就很难证明存在请求走私行为。即使在没有其他流量的站点上。也会因为应用程序意外终止而造成大量的误报。为了减少误报,我们可以配合返回包的响应信息规则。
接下来,我们试着总结一下漏洞规则,可以发现在尝试利用的请求中都会含有如下请求头或者一些变形字段。,这部分可以自行扩展思路。
| Content-Length: Transfer-Encoding: |
8.漏洞防御
在前端服务器通过同一网络连接将多个请求转发到后端服务器的情况下,会出现HTTP请求走私漏洞,并且后端连接所使用的协议有可能会造成边界不统一的风险。防止HTTP请求走私漏洞的一些通用方法如下:
1.禁用后端连接的重用,以便每个后端请求通过单独的网络连接发送。
2.使用HTTP / 2进行后端连接,因为此协议可防止对请求之间的边界产生歧义。
3.前端服务器和后端服务器使用完全相同的Web服务器软件,以便它们就请求之间的界限达成一致。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
 xssle的安全小屋
xssle的安全小屋
 SDL
SDL






- 11 文章数
- 69 关注者