


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 zzwlpx
zzwlpx- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
zzwlpx 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
zzwlpx 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文所指luajit,皆指luajit2.1.0-beta2版本。
一、背景
逆向apk时,得到luajit字节码文件,将反编译luajit的过程记录如下。
本文主要分析ljd反编译工具源码(https://github.com/NightNord/ljd),并参照feicong的luajit字节码分析一文(https://github.com/feicong/lua_re/blob/master/lua/lua_re3.md),制作Luajit字节码文件格式结构图以直观反映luajit字节码文件格式,并对ljd中存在的bug进行修正,说明使用过程中遇到的问题。
二、反编译luajit字节码前期准备
搜集资料,找到两种解决方案。
方案一
将luajit字节码文件用luajit.exe(luajit -bl luajit-byte-path)反编成操作码文件,然后再将操作码文件解析成可读文件。
工具地址:https://github.com/bobsayshilol/luajit-decomp
用autoit编写,下载下来的有打包好的exe文件,简单测试的话可以按如下操作:
1.下载编译字节码文件对应版本的luajit,可以自己编译,编译好后,将luajit.exe及对应的dll、lib等文件及源码目录下的jit文件夹一同拷贝进luajit-decomp目录。
2.将需要测试的luajit字节码文件拷贝至luajit-decomp目录,并重命名为test.lua
3.双击运行,会生成out.lua文件。
反编译效果如下图:
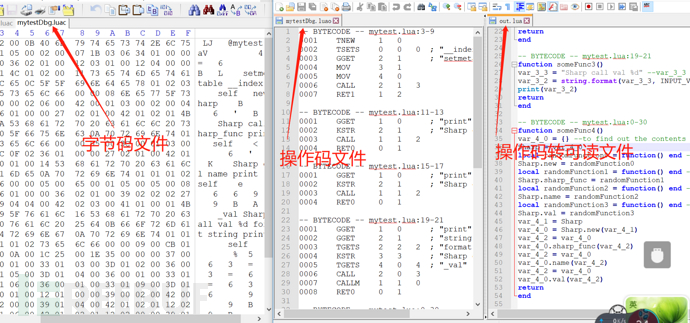 效果不如人意,对此不做具体分析。
效果不如人意,对此不做具体分析。
方案二
分析luajit字节码文件,及对应版本的luajit源码,写反编译工具将字节码直接反编译成luajit源码。我们主要分析这种。
过程中主要参照这三篇文章:
(1)Luajit字节码分析:https://github.com/feicong/lua_re/blob/master/lua/lua_re3.md
(2)Luajit反编译工具:https://github.com/NightNord/ljd
(3)对nightnord的luajit反编译工具ljd的应用经验总结:
https://bbs.pediy.com/thread-216800.htm
三、Ljd源码分析
(1)ljd目录结构说明
 (2)ljd函数调用流程分析
(2)ljd函数调用流程分析
画了一张解析时调用流程图:
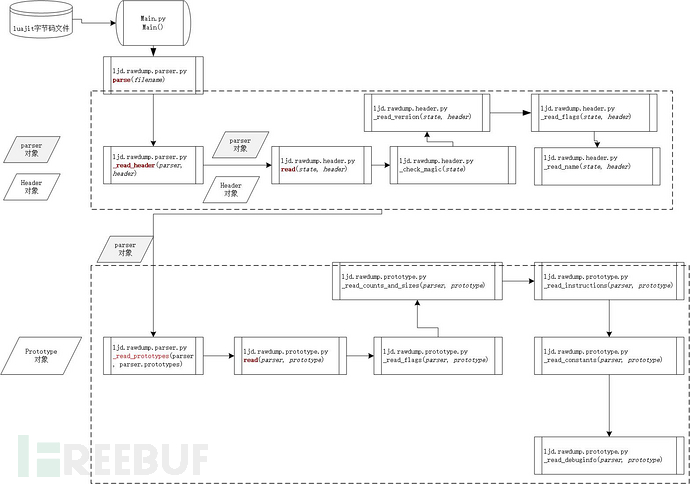
详细分析如下:
Main函数调用ljd.rawdump.parser.parse函数,如下:

parse会生成state对象实例parser和header对象实例header,然后调用_reader_header方法,并将parser和header传进去,如下图:
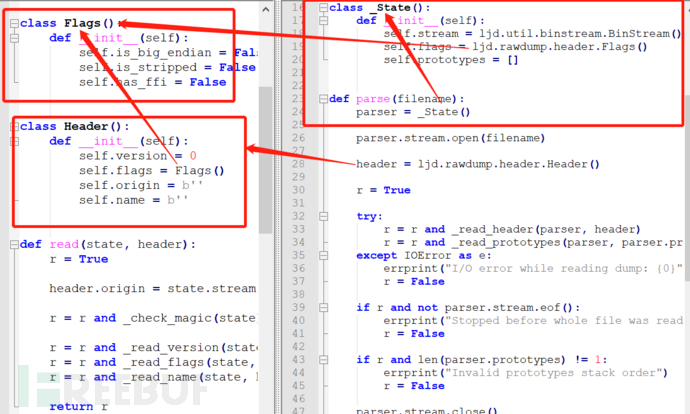
_reader_header调用read函数,如下图:

进入_check_magic、_read_vesion、_read_flags、_read_name函数查看的话,能得到magic为3个字节,version为1个字节,flags大小为1个uleb128,而接下来的源码文件名取决于flags里的is_stripped标志位,如果这个标志位是0,代表有字节码包含调试信息,文件中接下来的字节存放的是源码名称,否则不包含调试信息,接下来的字节内容就是prototypes。
_reader_header方法调用完成之后,会调用_read_prototypes函数,如下图:
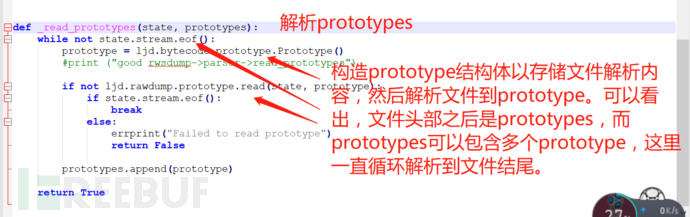
这个函数会循环读取文件字节到prototype对象,我们来看prototype结构:

可以看到里面包含标志、参数数量及操作指令及大小数量、常量、调试信息,但是没看到整个prototype的大小信息及各个字段的字节大小信息。我们接着往下看ljd.rawdump.prototype.read函数:
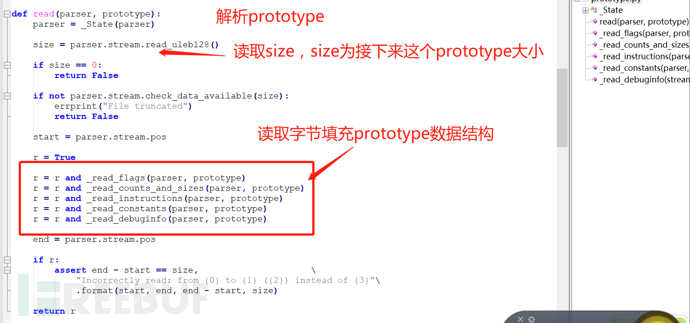 这里我们可以看到在解析prototype之前会先读取size,大小为1uleb128,接着会解析prototype内容,同样进入_read_flags、_read_counts_and_sizes、_read_instructions、_read_constants、_read_debuginfo函数内,可以看到,flag为1字节,arguments_count为1字节,Framesize为1字节,upvalues_counts为1字节,complex_constants_count大小为1uleb128,numeric_constants_count大小为1uleb128,instructions_count大小为1uleb128,接下来的字节还是取决于文件头header的flag中的is_stripped标志位,如果is_stripped标志位是0,则接下来的字节存储的是debuginfo_size大小1uleb128,first_line_numb大小1uleb128,lines_count大小1uleb128,如果是1,则没有debuginfo信息。再然后存储的是操作指令instructions,大小取决于解析出来的instructions_count,然后是常量信息constants,大小取决于解析出来的upvalues_count、complex_constants_count、numeric_constants_count,最后,如果解析出来的debuginfo_size大小不为0,则接下来的字节存储的的debuginfo信息,如果debuginfo_size是0,则此prototype结束,然后循环读取下一个prototype。
这里我们可以看到在解析prototype之前会先读取size,大小为1uleb128,接着会解析prototype内容,同样进入_read_flags、_read_counts_and_sizes、_read_instructions、_read_constants、_read_debuginfo函数内,可以看到,flag为1字节,arguments_count为1字节,Framesize为1字节,upvalues_counts为1字节,complex_constants_count大小为1uleb128,numeric_constants_count大小为1uleb128,instructions_count大小为1uleb128,接下来的字节还是取决于文件头header的flag中的is_stripped标志位,如果is_stripped标志位是0,则接下来的字节存储的是debuginfo_size大小1uleb128,first_line_numb大小1uleb128,lines_count大小1uleb128,如果是1,则没有debuginfo信息。再然后存储的是操作指令instructions,大小取决于解析出来的instructions_count,然后是常量信息constants,大小取决于解析出来的upvalues_count、complex_constants_count、numeric_constants_count,最后,如果解析出来的debuginfo_size大小不为0,则接下来的字节存储的的debuginfo信息,如果debuginfo_size是0,则此prototype结束,然后循环读取下一个prototype。
根据上面的分析,制作下图,以直观反映luajit字节码文件结构:
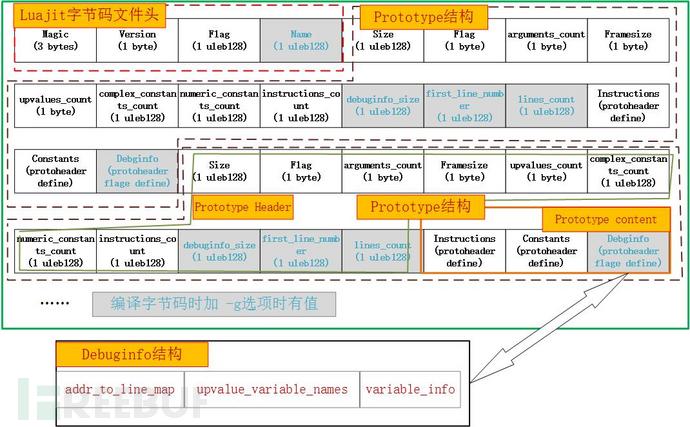
(3)ljd的bug所在
还是需要看一下解析时的调用流程:
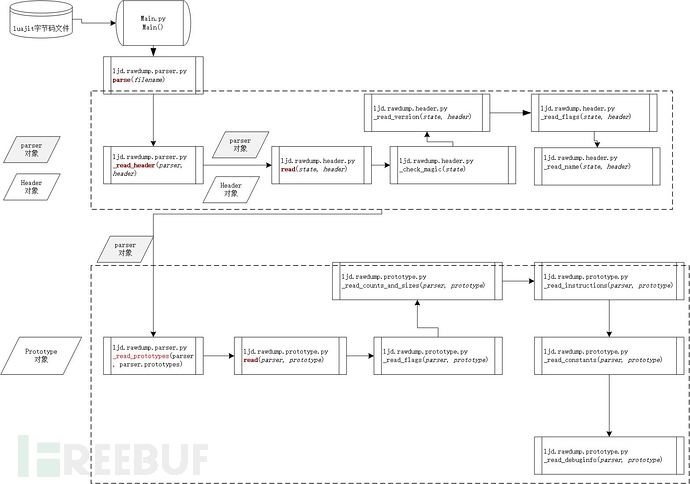
从图中可以很明显的看到,在ljd.rawdump.parser.py中的parser函数中,构造了parser和header对象,然后调用_read_header函数,读取luajit字节码文件的文件头到header对象,接下来调用_read_protoypes函数,并传递parser对象,由ljd.rawdump.prototype中的read负责解析。这是解析luajit字节码的一个宏观过程,我贴一张调试过程中的图,就能明显看到问题所在了,调试1:
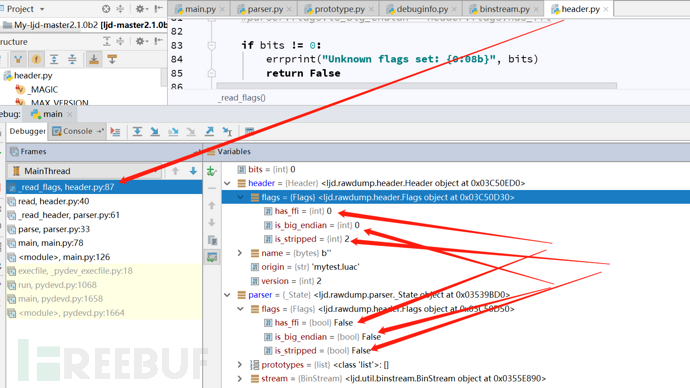
调试二:
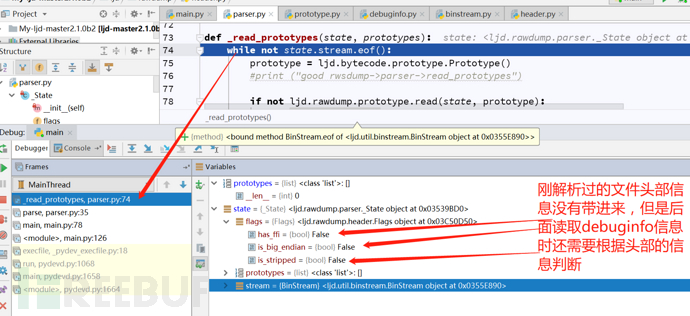
可以明显看出来_read_header函数解析过的header中的flag值没有被带进_read_protoypes函数,而后面读取debuginfo信息时,是需要根据header中的flag值去判断,这里就出现了bug。因为程序默认是读取的带有调试信息的luajit字节码文件,所以当读取带有调试信息的luajit字节码文件,bug不显,但是当读取不带调试信息的luajit字节码文件时,程序就会解析错误。如下:
错误一:
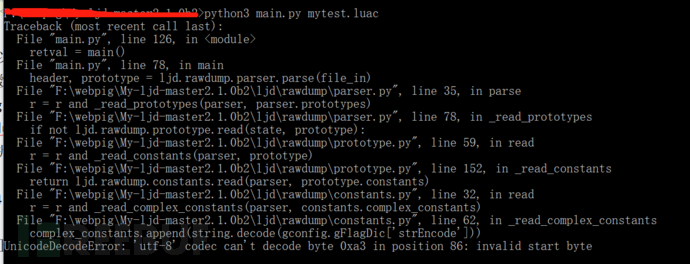
如果此时认为是编码问题的话,你可能会将编码都调成”Unicode-escape”,但是依然会出错。错误二:
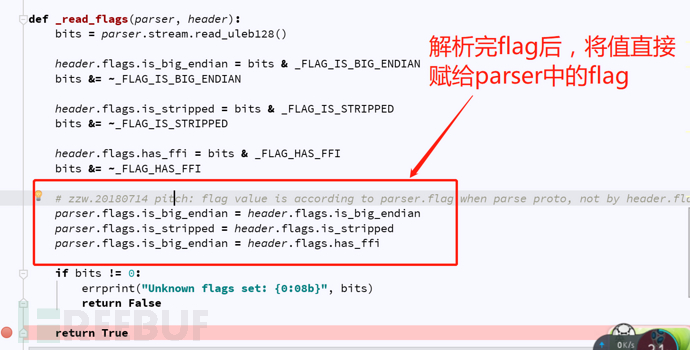
 (4)修正ljd的bug
(4)修正ljd的bug
知道bug原因了,就可以直接动手改了。如图:
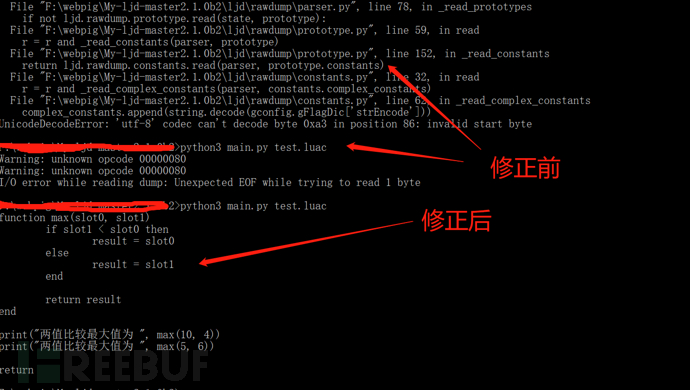
四、结果
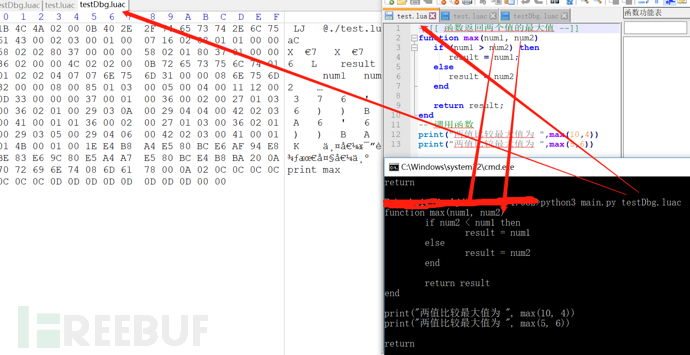
(1)当用LuaJit编译Lua源码时,编译字节码时如果加-g选项,即字节码包含调试信息,反编译时几乎可以完全还原的,还原效果如下图:
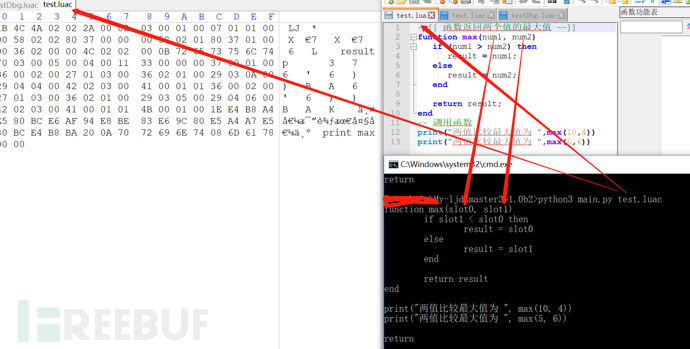
 (2)编译时不加-g选项,即不带调试信息,反编译时,是解析不出函数体内的本地变量名称的,因为字节码文件中就没有变量名称信息,只知道有变量占位符,所以在反编译解析时,只能按照规则重命名命名本地变量,还原效果如下图:
(2)编译时不加-g选项,即不带调试信息,反编译时,是解析不出函数体内的本地变量名称的,因为字节码文件中就没有变量名称信息,只知道有变量占位符,所以在反编译解析时,只能按照规则重命名命名本地变量,还原效果如下图:
(3)修正后源码
修正后的工具源码地址:https://github.com/zzwlpx/ljd
注意事项:工具使用环境python3+,用法:pythonmani.py “path”
Luajit 源码下载地址:http://luajit.org/download.html windows下需要用vs控制台编译。
已在FreeBuf发表 7 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)





- 7 文章数
- 16 关注者