


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
严正声明:本文仅用于技术探讨,严禁用于其他非法途径
0x00 前言
摩尔斯电码(又译为摩斯密码,Morse code)是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号,从而实现通信。
我最早接触的摩尔斯电码是SOS(··· — — — ···),是小时候看一本儿童读物中提到某轮船沉船时发出的求救信号。后来在各种军事题材的影视作品中又频繁接触到了摩尔斯电码,当时就被它的神秘而着迷。
写本文的主要目的是想设计一套系统,帮助听报员解放双耳,实现对音频的摩尔斯电码自动解码。但手头没有现成的摩尔斯电码的音频文件,所以只好先设计一套摩尔斯电码音频发生器,然后再设计一套摩尔斯电码音频解析器。
说干就干,不啰嗦。
0x01 所需材料
摩尔斯电码音频发生器所需材料
1.树莓派
2.USB音箱
摩尔斯电码音频解析器所需材料
1.树莓派
2.USB麦克风
0x03摩尔斯电码音频发生器
摩尔斯电码音频发生器实现起来非常简单。
首先制作两个音频文件:short.wav和long.wav。其中short.wav会发出700HZ的100毫秒时长的音频,代表发出“.”音,long.wav会发出700HZ的300毫秒时长的音频,代表发出“-”音。
再通过编码来控制每个音的播放时间间隔,从而可以按照莫尔斯码表的规则来实现发送文字、单词、句子,最终就可以实现通信了。
下图为摩尔斯电码表。
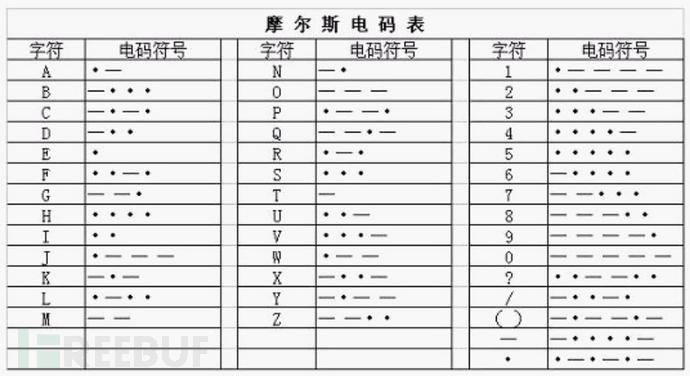
发音规则:
滴=1t,嗒=3t,滴嗒间=1t,字符间=3t,单词间=7t
摩尔斯电码音频发生器的核心代码如下(注:如果需要完整源代码,请在评论区留言,留下你的邮箱,我会一一发送):
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
说明:
1 for -
0 for .
规则:
滴=1t,嗒=3t,滴嗒间=1t,字符间=3t,单词间=7t
"""
from __future__ import print_function
import re, time, datetime, os, sys
import pygame
# Morse dictionnairy.
from morse_dict import *
T = 100 #毫秒
#单位:毫秒
def my_sleep(sleeptime):
begin = datetime.datetime.now()
while True:
end = datetime.datetime.now()
k = end - begin
if (k.total_seconds()*1000) > sleeptime:
break
def get_user_text():
user_text = raw_input("Please enter the message:")
user_text = user_text.lower()
word_list = list(user_text)
return word_list
def play_sound(path):
pygame.mixer.music.load(path)
pygame.mixer.music.play()
while 1:
if not pygame.mixer.music.get_busy():
break
def long_pulse(is_sleep):
play_sound("./audio/long.wav")
if is_sleep == True:
my_sleep(100)
def short_pulse(is_sleep):
play_sound("./audio/short.wav")
if is_sleep == True:
my_sleep(100)
def gap_1t():
#time.sleep(0.1)
my_sleep(100)
def gap_3t():
print(" ",end="") #short gap
#time.sleep(0.3)
my_sleep(300)
def gap_7t():
print(" ",end="\n") #long gap
#time.sleep(0.7)
my_sleep(700)
def play_morse_code(morse_code):
length = len(morse_code)
for i in range(len(morse_code)):
if morse_code[i] == '1':
if i != length-1:
long_pulse(True)
else:
long_pulse(False)
elif morse_code[i] == '0':
if i != length-1:
short_pulse(True)
else:
short_pulse(False)
def play_text(alpha_text):
print("\n===================\nPlaying\n===================\n")
alpha_text = alpha_text.lower()
for letter in alpha_text:
if letter in morse_dict.keys():
morse_code = morse_dict[letter]
play_morse_code(morse_code)
gap_3t()
elif letter == " ":
gap_7t()
else:
print("?",end="")
sys.stdout.flush()
gap_3t()
print("\n")
def test1():
while True:
play_sound("./audio/long.wav")
my_sleep(100)
play_sound("./audio/long.wav")
my_sleep(100)
play_sound("./audio/long.wav")
my_sleep(100)
play_sound("./audio/long.wav")
my_sleep(100)
play_sound("./audio/long.wav")
my_sleep(3000)
text = "11111"
play_morse_code(text)
my_sleep(3000)
def test2():
while True:
text = "I LOVE YOU"
play_text(text)
my_sleep(3000)
if __name__ == '__main__':
pygame.init()
pygame.display.set_mode([300,300])
pygame.mixer.init()
pygame.time.delay(1000) #等待1秒让mixer完成初始化
#test1()
#test2()
text = get_user_text()
play_text(text)0x04 摩尔斯电码音频解析器
摩尔斯电码音频解析器实现起来相对比较困难,需要掌握一些信号处理的知识,重点是掌握FFT变换。
需要用到的知识点
采样频率如何设置?
采样是将一个信号(即时间或空间上的连续函数)转换成一个数值序列(即时间或空间上的离散函数)。香农采样定理指出采样频率必须高于信号频率的两倍,只有这样,原来的连续信号才可以从采样样本中完全重建出来。
本实验中莫尔斯码音频发生器产生的音频频率为700HZ,所以莫尔斯码音频解析器的采样频率应该使用略大于原始音频频率2倍,本文采样频率为1600HZ。
什么是加窗?
在做信号处理时,经常要把时域信号转换为频域信号。为了增强信号的清晰度及抑制频谱泄漏,需要通过加窗来实现,本文使用的窗函数是布莱克曼窗函数(Blackman Window)。
什么是FFT?
FFT (Fast Fourier Transform, 快速傅里叶变换) 是离散傅里叶变换的快速算法。FFT能将时域的数字信号转换为频域信号。
单频信号的频率计算公式?
由快速傅里叶变化的性质可知:当采样频率 (sampling_rate) 确定的情况下,取波形中的 fft_size个数据进行 FFT 变换时,若这 fft_size个数据包含整数个周期, FFT 所计算的结果是精确的。即当被采样频率 f 满足如下公式时,FFT 的计算结果是精确的。
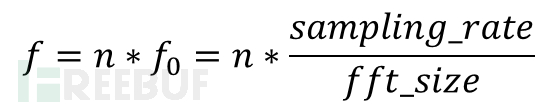
对时域信号进行FFT变换后,会出现fft_size/2(fft_size为你做FFT的信号长度)频谱;由于fft_size值的大小,sampling_rate/fft_size分辨率达不到,会出现大于1个以上比较大的频谱幅度值的。当fft_size值比较大的情况下,对于单频信号,幅度值最大的所对应的频率值就是你的单频信号的频率。
摩尔斯电码音频解析器的核心代码如下(注:如果需要完整源代码,请在评论区留言,留下你的邮箱,我会一一发送):
#!/usr/bin/Python
# -*- coding: UTF-8 -*-
from __future__ import print_function
from sys import byteorder
from array import array
from struct import pack
import pyaudio
import wave
import time
import struct
import sys
import numpy as np
import wiringpi
"""
Rules:
滴=1T,嗒=3T,滴嗒间=1T,字符间=3T,单词间=7T
"""
"""
开发心得:
1.由于实际环境中存在外界干扰,字符间隔的空白期间受到了污染,很难保证为3T。
2.由于实际环境中存在外界干扰,哒(-)可能会被隔断,被识别为两个音。
"""
T = 100 #单位:毫秒
T3 = 3*T #单位:毫秒
THRESHOLD = 300 #阈值
CHUNK = 160
FORMAT = pyaudio.paInt16
RATE = 16000 #采样率
window = np.blackman(CHUNK) # blackman窗
FREQ = 700 #700HZ
HzVARIANCE = 40
SCAMPLE_TIME_ONE_TIME = CHUNK*1000/RATE #每次采样时间 计算结果:10毫秒
CHAR_INTERVAL = 250 # 字符间=3T
letter_to_morse = {
"A" : ".-", "B" : "-...", "C" : "-.-.",
"D" : "-..", "E" : ".", "F" : "..-.",
"G" : "--.", "H" : "....", "I" : "..",
"J" : ".---", "K" : "-.-", "L" : ".-..",
"M" : "--", "N" : "-.", "O" : "---",
"P" : ".--.", "Q" : "--.-", "R" : ".-.",
"S" : "...", "T" : "-", "U" : "..-",
"V" : "...-", "W" : ".--", "X" : "-..-",
"Y" : "-.--", "Z" : "--..", "1" : ".----",
"2" : "..---", "3" : "...--", "4" : "....-",
"5" : ".....", "6" : "-....", "7" : "--...",
"8" : "---..", "9" : "----.", "0" : "-----",
" " : "/"}
def is_silent(sound_data):
"Returns 'True' if below the 'silent' threshold"
return max(sound_data) < THRESHOLD
# important
# 正常情况是字符
def encode(raw_data):
listascii = ""
maximum = 0
icount = 0
# 过滤非电报音
for i in range(len(raw_data)):
if raw_data[i] == '1':
icount += 1
maximum = max(maximum,icount)
elif raw_data[i] == '0':
icount = 0
if maximum < 5:
print("\n--------throw it--------\n")
return
# 打印原始数据
#print("\n-------raw data-------\n")
#print(raw_data);
#print("\n-------raw data-------\n")
# 消除噪音(1/2):消除干扰'1'
i = 0
j = 0
temp_list = list(raw_data)
while i < len(temp_list):
if temp_list[i] == '0':
i += 1
continue
for j in range(i,len(temp_list)):
if temp_list[j] != temp_list[i]:
break
#
if j-i <= 5:
for k in range(i,j):
temp_list[k] = '0'
else:
i = j
i += 1
raw_data=''.join(temp_list)
#print("\n-------clean jam(1/2)-------\n")
#print(raw_data);
#print("\n-------clean jam(1/2)-------\n")
# 消除噪音(1/2):消除干扰'0'
temp_raw_data = raw_data[0]
last_number = raw_data[0]
for i in range(1,len(raw_data)):
if raw_data[i] != last_number:
temp_raw_data += '#'
last_number = raw_data[i]
temp_raw_data += raw_data[i]
#print(temp_raw_data)
list1 = temp_raw_data.split("#")
#print("\n-------modified data-------\n")
#print(list1)
#print("\n-------modified data-------\n")
# 生成嘀嗒序列
for i in range(len(list1)):
line = list1[i]
if line[0] == '1':
if len(list1[i]) >= 20 and len(list1[i]) < 100: #200-1000 ms dah, throws values > 100
listascii += "-"
elif len(list1[i]) < 20 and len(list1[i]) > 5: #50-200ms is dit
listascii += "."
if line[0] == '0':
if len(list1[i]) >= 20 and len(list1[i]) < 60: #200-600 ms 字符间隔
listascii += "#"
listascii = listascii.split("#")
listascii = [i for i in listascii if(len(str(i))!=0)]
#print("\n-------dida data-------\n")
#print(listascii)
#print("\n-------dida data-------\n")
stringout=""
for i in range(len(listascii)):
bFind = False
for letter,morse in letter_to_morse.items():
if listascii[i] == morse:
stringout += letter
bFind = True
if bFind == False:
stringout += '?'
if listascii[i] == "":
stringout += " "
if stringout != " ":
print(stringout,end="")
sys.stdout.flush()
def record():
num_silent = 0
snd_started = False
oncount = 0
offcount = 0
status = 0
timelist = ""
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=1,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("##############START##############")
while True:
sound_data = stream.read(CHUNK, exception_on_overflow = False)
if byteorder == 'big':
sound_data.byteswap()
#r.extend(sound_data)
sample_width = p.get_sample_size(FORMAT)
#find frequency of each chunk
indata = np.array(wave.struct.unpack("%dh"%(CHUNK), sound_data))*window
#take fft and square each value
fftData = abs(np.fft.rfft(indata))**2
# find the maximum
which = fftData[1:].argmax() + 1
silent = is_silent(indata)
# signal frequency
if silent:
thefreq = 0
elif which != len(fftData)-1:
y0,y1,y2 = np.log(fftData[which-1:which+2:])
x1 = (y2 - y0) * .5 / (2 * y1 - y2 - y0)
# find the frequency and output it
thefreq = (which+x1)*RATE/CHUNK
else:
thefreq = which*RATE/CHUNK
#print(thefreq)
#check frequency
if thefreq > (FREQ-HzVARIANCE) and thefreq < (FREQ+HzVARIANCE):
timelist += "1"
num_silent = 0
#print("1")
else:
timelist += "0"
num_silent += 1
#print("0")
if num_silent*SCAMPLE_TIME_ONE_TIME > CHAR_INTERVAL and "1" in timelist:
encode(timelist)
timelist = ""
# 10秒内无声,进行复位
if num_silent*SCAMPLE_TIME_ONE_TIME > 10*1000:
print("reset")
num_silent =0
timelist = ""
#print (timelist)
print("##############END##############")
#print(num_silent)
p.terminate()
if __name__ == '__main__':
#提高优先级
#注意:需要以root权限运行
wiringpi.piHiPri(1)
record()
备注:需要在无外声干扰的屋子里进行,否则解析过程可能会不准确。
0x05 结尾
冲杯咖啡,坐在屋子里。将摩尔斯电码音频发生器和摩尔斯电码音频解析器放在一起,听着耳边响起的滴答声,看着音频解析器的屏幕输出的文字,那一刻仿佛时间都静止了,不禁感叹——编码真美妙。
0x06 题外话
电报如果明文传送肯定是要被监听到的,只有通过加密才能保证信息的安全。
加密的方式有千万种,而敬爱的周恩来总理,在年轻时亲手策划并创建了一个从未被破译过的加密方式———“豪密”,值得大家了解及学习一下。
给大家找到了一篇详细介绍了“豪秘”的文章,请移步阅读。
https://wenku.baidu.com/view/f184eaa00912a2161579297b.html
最后,推荐一部与电报相关的二战电影 ——— 《模仿游戏》。

*本文原创作者:xutiejun,本文属于FreeBuf原创奖励计划,未经许可禁止转载
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者