


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
前言
单纯的通过单个编码,在WebShell检测引擎中会检测编码,并将其进行解码
这里主要是使用在JSP页面中支持的编码进行多次不同的编码进行混淆
混淆绕过
embed encoding
主要是Y4tacker师傅的研究成果进行一些代码上面的复现
针对编码的探测主要集中在generateJava方法(通过jsp页面生成等价的servlet页面)中
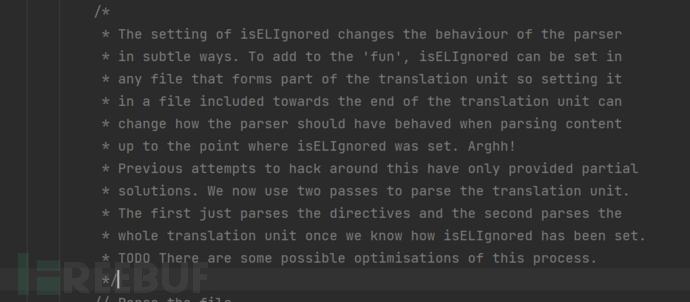
根据注释的内容我们可以明白主要是通过两步
step1: 首先解析jsp中的所有指令
step2: the whole translation unit
指令的解析集中在ParserController#parseDirectives
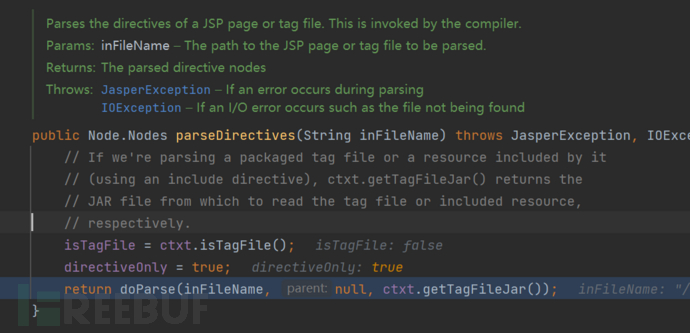
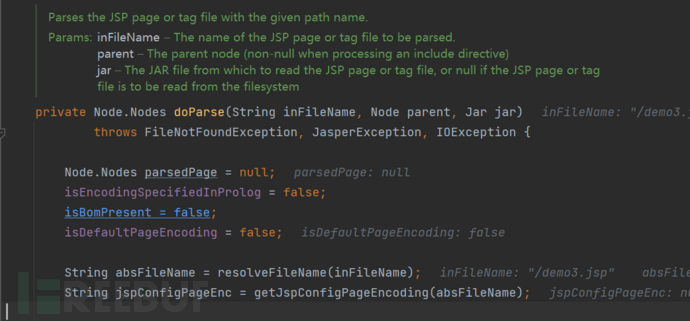
我们这仅关注一些关于编码的内容
这里的jspConfigPageEnc变量,是通过getJspConfigPageEncoding方法中Jsp config中获取的,也就是在web.xml中的<page-encoding>标签中的内容

之后就是通过determineSyntaxAndEncoding来探测我们需要处理的是标准的JSP语法还是通过XML语法编写的jsp页面,并且获取他们所使用的编码
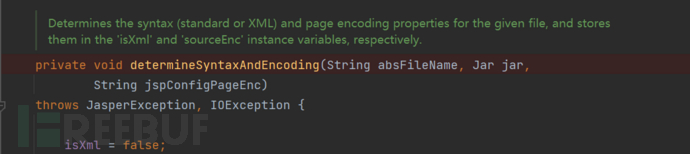
并通过isXml和sourceEnc分别来保存探测的结果,默认不是xml格式
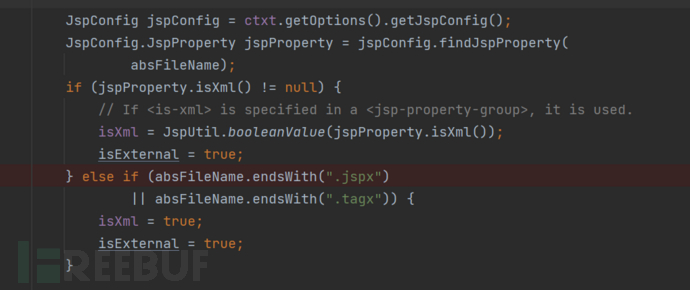
可以通过在jsp config中的<is-xml>来判断,或者通过.jspx / .tagx这两个后缀作为标志
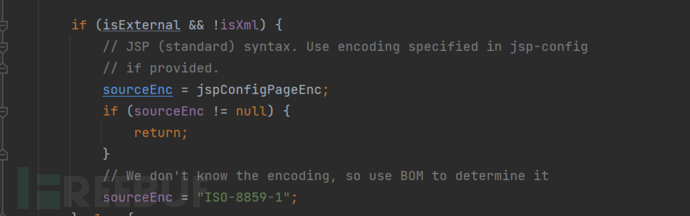
如果是JSP语法格式,就从jsp-config中获取特定的编码,如果在jsp-config中并没有指定具体的编码,将在后面通过BOM进行探测
https://en.wikipedia.org/wiki/Byte_order_mark#Byte_order_marks_by_encoding
上面是通过jsp-config中的配置进行编码的获取的
而如果没有如上面的后缀,只是一个简单的.jsp后缀,而且也没有在jsp-config中使用<is-xml>标签进行显示的指明
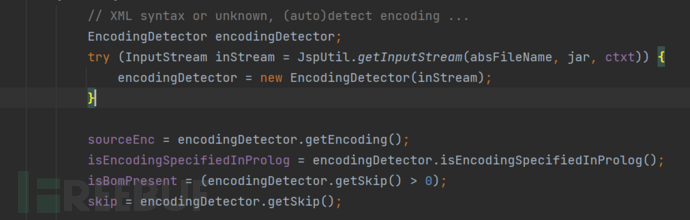
将会通过EncodingDetector进行编码的自动探测
在Y4tacker师傅中,环境是tomcat 8.0.50版本的,是通过XMLEncodingDetector类对象进行自动探测的,该类在高版本中被遗弃甚至移除
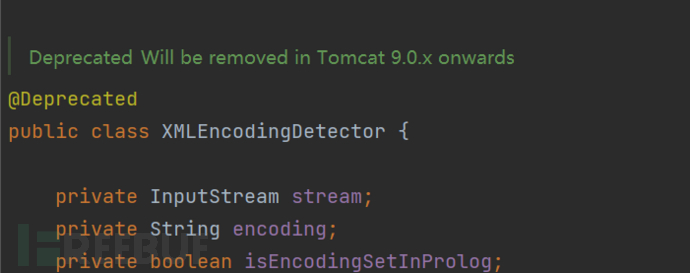
但是不影响,我们关注EncodingDetector
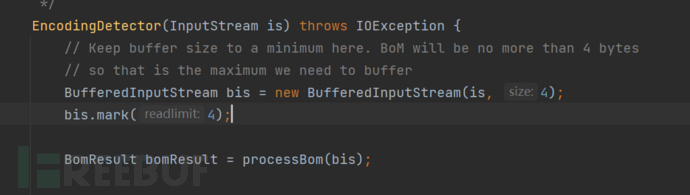
对于auto detect核心是通过processBom进行BOM的解析
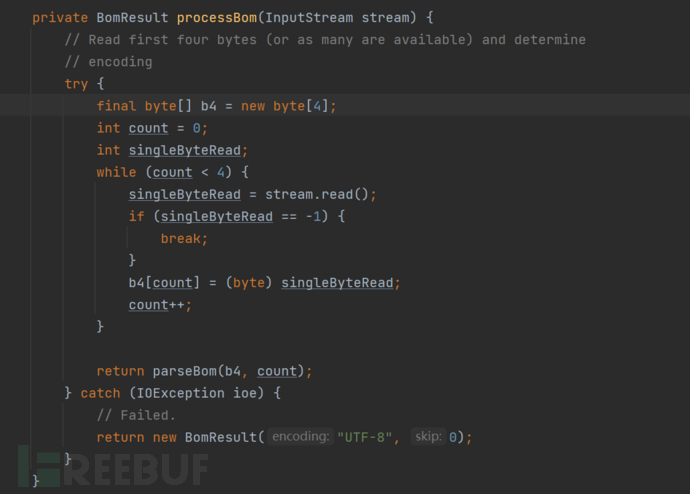
通过stream流中的前四个字节进行编码的判断,如果探测失败,默认是UTF-8编码
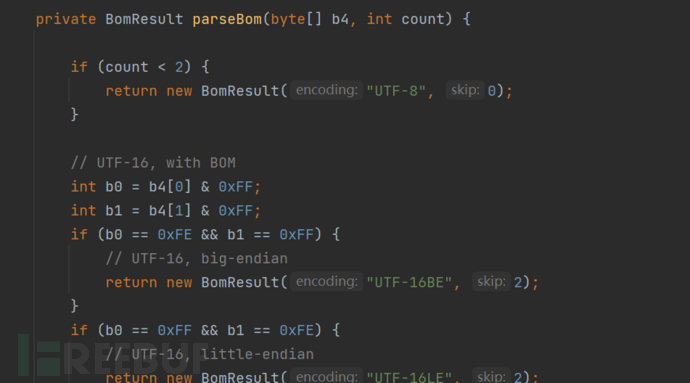
支持有很多编码--UTF-16BE / UTF-16LE / UTF-8 / ISO-10646-UCS-4 / CP037 ......等等
通过BOM探测失败,默认为UTF-8编码
以上就是第一处的编码的解析,即通过BOM对stream流进行探测
紧接着就是就是通过XML形式的语法,通过获取他的encoding属性值
这里主要是逻辑是:
如果在
<?xml encoding='xx'中存在有编码的指定,优先是选择encoding中的编码当然如果没有该属性值,则还是指定为前面通过BOM判断出的编码
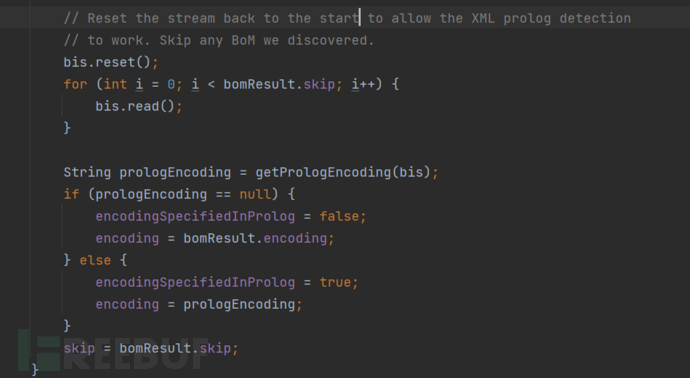
而对于encoding的值的获取
 已在FreeBuf发表 0 篇文章
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者