


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
一、前言
最近在开发一款安服仔偷懒专用的工具,里面有个功能模块需要用到指纹,想着直接调开源的指纹库,但是数据量并不是很多,就想着自己整合下指纹库,然后看了一圈发现好像没什么人详细解释如何去获得一个网站的指纹,更多的是推荐那些现成的工具,网站那些,就想着自己搞下指纹捕获,整理个自己的指纹库,顺便整理下指纹捕获的思路,有兴趣的铁子可以学下,然后新漏洞出来的时候可以去搞指纹提交,有些站就在收指纹,常规操作的话就是自己手工慢慢找出指纹。
进阶版的话,可以结合脚本自动化捕获或者训练算法去自动化捕获,二者的区别在于脚本只能根据你写死的规则来捕获,误差较大,而训练算法的话能在脚本的基础上提高一截的成功率,用哪种方式各有好处吧,见仁见智。
二、指纹提取
先讲下指纹提取的思路。所谓指纹就是一个系统所具有的独有的特征,根据该特征,我们就可以识别出这款应用的通用框架或组件等,大部分的指纹提取方式有以下几种:
站点首页源码
数据包header
站点图标hash值
2.1首页源码指纹提取
例如:Discuz这一个CMS,在正常情况下他会显示不同样式的界面,可能是这样:
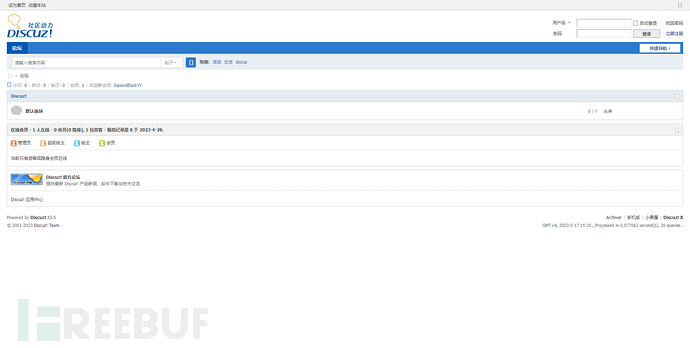
也可能是这个样子,这里打了个码,大佬们别在意这些,能看出来不一样就行。
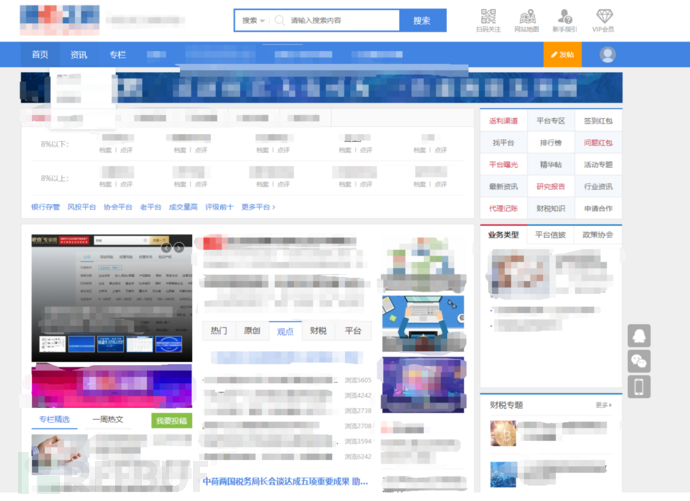
表面上看这两个网站没有多少相似的地方,可以说几乎不一样,找指纹就是在这两个不同网站中找出相同点,这个过程也就是指纹提取。
指纹提取通常需要我们查看网页源码,图标,数据包,静态文件内容与hash或者特有的url路径等,例如上述两个网站,查看下源码。
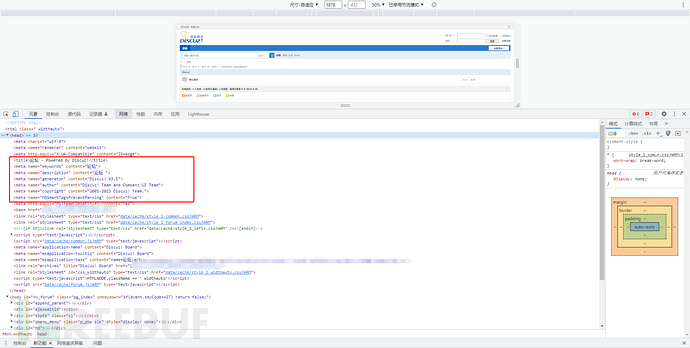
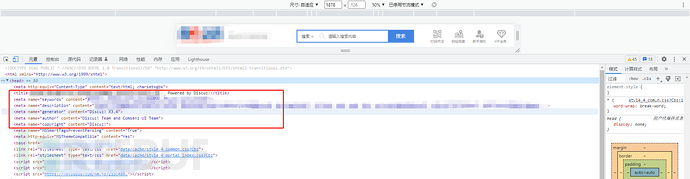
两个网站中都有一个代码块存在Discuz这个单词,在<meta name="generator" content="Discuz! X3.*" />这一行。其中,第一个网站是3.5,而第二个网站是3.4 。但是在<title>中也存在Discuz这个单词,以及下面的<meta name="copyright" content="Discuz!">,<meta name="author" content="Discuz! Team and Comsenz UI Team">这两行代码也存在Discuz。
那么如何判断一个指纹是大部分网站特有且容易提取,不会被其他数据所干扰的便成了指纹提取中及其重要的一件事,这个后面会说如何科学的获取大部分网站都有的指纹,当我们选取<meta name="generator" content="Discuz! X3.4">这条代码作为指纹时,一条识别Discuz框架的指纹就产生了,那就是源码含有:<meta name="generator" content="Discuz!,接下来只需要在搜索引擎中查找源码中存在该数据的资产,就能相同CMS的站点,需要注意几个点:
1、这个不是百分百准确的,通过这种方式在搜索引擎找出来的不一定都是准确的, 有可能是蜜罐或者BC之类的,这类站点会在源码处写上多个指纹特征,增加被找到的可能性
2、如果要增加匹配成功率可以通过添加不同的代码行来增加,例如上述例子里面的Discuz,如果在3.4版本中出现了一个新漏洞,而3.5版本没漏洞,那么除了最主要的<meta name="generator" content="Discuz! X3.4">这句代码外,再对比其他有差距的代码作为次要指纹进行对比或者对其他静态文件进行指纹匹配。
3、一般来说我们直接访问过去会显示首页,但是在网络加载的时候可能不是这样的,如果页面存在跳转的话在自动化捕获这块就有点困难,需要去判断是什么跳转是301,302还是JS跳转,匹配的话直接以跳转时出现的页面或者HTTP Response中的HTML为主体都可以。
这里给出两个小demo,一个是单纯获取页面代码,一个是除了获取代码外还可以获取到特定的元素,根据需要来使用
#1、只是获取了网页的源代码
import requests
url = '' # 将URL替换为你要获取源代码的网页地址
response = requests.get(url)
# 获取网页源代码
html_code = response.text
# 打印网页源代码
print(html_code)
#2、获取了网页的源代码并使用BeautifulSoup来解析它,这可以更轻松地提取、处理和搜索网页中的特定元素。
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url=''
r = requests.get(url, headers=headers)
html = r.content.decode('utf-8', 'ignore')
my_page = BeautifulSoup(html, 'lxml')
print(my_page)2.2数据包header指纹提取
首页数据包的header,可匹配首页响应中的Header内容,通常在头部字段中存在一些特殊的字段,通过匹配对比返回数据包中的字段获取指纹,且通过数据包可确定是否使用代理或缓存,可以通过 Header 中 Via 字段做简要判断,部分开发会在开发时在Cookie 部分定义自己的 Cookie 字段,如 JeecmsSession=“xxxxx” 或者 cookies=“phpcms_xxxx”

例如上图所示的cookie字段,rememberMe,那么我们可以判断这个站点大概率是使用了shiro,使用工具验证下:
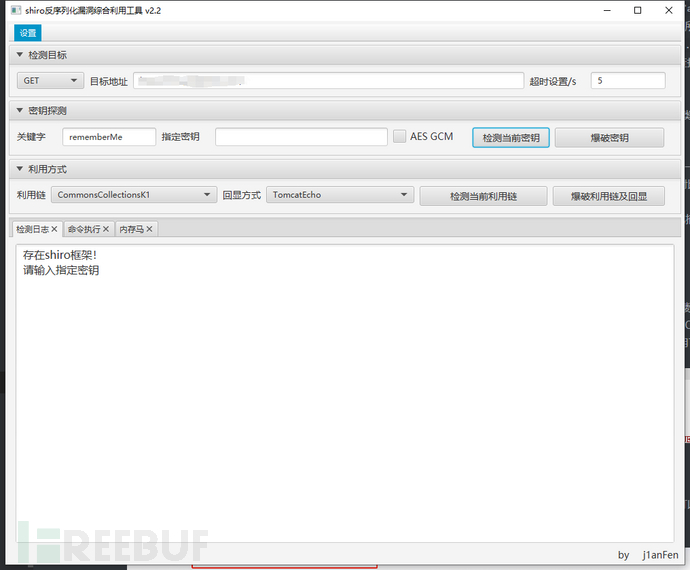
这里附上一个获取返回数据包headers头部的小demo,获取完headers头部就可以通过对比headers的不同来判断headers处是否有我们要的指纹了。
import requests
url = '' # 将URL替换为你要获取数据包头部的网页地址
response = requests.get(url)
# 获取数据包头部信息
headers = response.headers
# 打印头部信息
print(headers)
2.3站点图标hash值
一般网站站点title处都会有固定的图标以及他们使用的框架和组件也可能会使用相同的图标,通过站点图标的hash值可以获取到那些没有改图标的站点,但是有个特点就是版本不会对上,所以还需要进一步判断该站点是否是我们想要的网站,有没有存在漏洞。
获取站点图标hash可以通过以下代码
import mmh3
import sys
import codecs
import requests
url = "https://目标站点/favicon.ico"
re = requests.get(url,verify = False)
ico=codecs.encode(re.content,"base64")
hash=mmh3.hash(ico)
print(hash)
三、评价标准
当我们获取到一定量的指纹之后,怎么去判断我们的指纹是不是真的好用,准确率有多高呢,这里就涉及到一个评价标准的知识点,目前指纹和POC编写评价体系主要依赖于两个指标:精确率(precision)和召回率(accuracy),精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),即P=TP/(TP+FP)
| 实际值预测值 | 正 | 负 |
|---|---|---|
| Positive | TP | FP |
| Negative | FN | TN |
召回率表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN),即R=TP/(TP+FN),简单来说,精确率就是指纹匹配的结果有多少准确匹配的,有多少是误报的,误报的越多,精确率越低,而召回率就是用来评价有多少本来应该被匹配出来的结果,但是被漏掉了,召回率越高,漏报率越低。
在匹配指纹时,我们当然希望漏报率和误报率越低越好,让精确率和召回率都趋近100%,所以需要有个用来衡量精确率和召回率的指标,在这里我选用的是F-score。
F-score是综合考虑精确率与召回率的一个指标,精确率只是表示了预测的精准程度,而召回率反映了判定比例。在同一个数据集合中精确率和召回率两者之间相互制约,一般情况下,提升精确率,就意味着召回率的下降,两者之间存在负相关的关系F-score的计算公式。

其中Precision表示精确率,Recall表示召回率,Predict_true表示预测正确的各个类的数据,class_Testtext表示测试数据集中各个类的数目,predict_class_Testtext表示预测结果中各个类的数目。
当精确率与召回率重要性不一致时,可以使用广义F-score进行度量,广义F-score计算公式如下图所示:
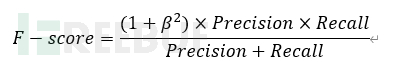
其中β表示对于精确率与召回率的重要性比重,一般情况下,选择β=1,即精确率和召回率同等重要,当β>1,表示召回率重要性强于精确率率,当β<1,表示精确率的重要性强于召回率。这里采用F-score进行度量模型效果,即选取β=1时的广义F-score,精确率和召回率同等重要,除此之外除了使用F- score进行度量,还根据空精确率和测试数据集的精确率进行判断。
当召回率与精确率不高的情况下,我们可以通过选取一个特殊独有的js或css文件名或一个特殊独有的color数值添加至我们的指纹中做一个并集的匹配操作,这样可以将指纹的召回率与精确率提高至一定程度。
四、总结
综上所述,我们最常用的指纹捕获方式就是这些:站点首页源码、数据包header、站点图标hash值。其实还有别的方式,例如静态文件内容和静态文件的hash等方式,只要是网站上的特有文件或代码,hash都可以作为指纹,但是像文件这种我们需要额外发起一次请求去获取文件,容易被抓到,所以并不推荐这种做法。其实指纹捕获并不难,重点是如何保证我们所获取的指纹的准确率和召回率,还有就是以什么样的衡量指标作为评价标准。
这篇文章主要讲一些指纹捕获的基础知识以及如何通过代码去捕获,并且在捕获完成之后如何去判断我们所获取的指纹能够准确识别资产,后续会写自动化指纹捕获的研究过程,既如何通过代码和有效样本进行自动化指纹捕获。
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者