


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 猫蛋儿安全团队
猫蛋儿安全团队- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
前言介绍
前几天刷着刷着微博,看着某大佬在微博上推荐了一款名为mitmproxy的工具,然后评论区引起共鸣,于是赶紧向大佬们学习,下到本地学一学。发现这玩意真好用啊,除了基本的代理功能,会点python网络编程就能搞点好玩的东西出来。本文通过使用mitmproxy代理,使用python编写插件,实现了对jeecg-boot精准的被动打击,点点鼠标,漏洞自己就出来了。

在学习过程中,本文参考了一系列参考文章,仅以传播学习知识为目的,如有侵权,请联系作者删除。
本文大体的写作流程如下:
mitmproxy的介绍:讲讲这玩意是啥,能干啥mitmproxy的使用: 讲讲这玩意咋安装,咋能跑起来mitmproxy被动漏洞探测实战:都写文章了,不得吹点牛逼吗?以最近遇到的站点为例,实现对特定漏洞的被动扫描,包含指纹识别,依托现实场景下的url修改,漏洞探测。说白了,这工具我用着好在哪,抓包的request,response都可以快速自定义修改,判断,非常好用。
工具简介
问:Mitmproxy,就是mitm+proxy嘛,mitm是啥? 答:Man-in-the-middle,就是中间人呗,proxy是啥,代理呗。实际上,这就是个代理,就是转发请求的。比如 A(网站)客户要访问B(网站),现在A有了C(mitmproxy),A先把请求发给mitmproxy,mitmproxy替A请求B网站,然后C把返回包拿回来给A看。 你可能会问,这不是脱裤子放屁吗,有什么意义呢?当然有,比如你不能想去某p站看小视频,但是被拦截掉了,你可以让mitmproxy出国帮你看,这就实现了"爬墙的功能"。比如你可以适时的拦截请求包,修改数据,引发服务器的特定行为,等等等等。以上的案例都是基于正向代理的情况说明的,此时如果不明白可以去学一下,透明代理、反向代理、上游代理、SOCKS 代理等。 问:这工具好在哪,比别的代理优势在哪?
答:可以使用python快速开发插件,对请求包,返回包的修改、提取等等等等。
工具使用
1.环境安装首先需要安装好 python,版本需要不低于 3.6,且安装了附带的包管理工具 pip。不同操作系统安装 python 3 的方式不一,参考 python 的下载页,这里不做展开。这里有坑:python pip链接啊,环境变量配置啊等等。如果不会安装或者不会debug,那就百度:如何在XXX系统安装python3,python3 pip3软连接,python3环境变量配置,pip换源... 现在你已经有python3环境了,pip也已经搞好了。那安装就很简单:在 linux 中:
sudo pip3 install mitmproxy在 windows 中,以管理员身份运行 cmd 或 power shell:
pip3 install mitmproxy在 mac中,在命令行直接输入:brew install mitmproxy当然,还有其他方式的安装,详情可以参考官方文档。
证书安装: 跟burp差不多,添加证书信任就行了,不加也不耽误事。
运行:
安装完mitmproxy后,系统中将拥有 mitmproxy、mitmdump、mitmweb 三个命令,我们可以拿 mitmproxy 测试一下安装是否成功,执行:
mitmproxy --version 显示是这样的,那就装好了。mitmproxy默认监听端口和burp相同,开在8080,也可以使用-p参数指定。以8081端口为例,访问百度后,可以看到所有的请求都可以看到。
显示是这样的,那就装好了。mitmproxy默认监听端口和burp相同,开在8080,也可以使用-p参数指定。以8081端口为例,访问百度后,可以看到所有的请求都可以看到。 "猫的睾丸人可以吃吗?","猫咪的睾丸能给猫吃吗?",我擦,你们是个人??继续讲,然后这就像个编辑器是的,用上下,鼠标可以点进特定的包看,下面有选择啊,重放啊,改包啊,等等功能。完了改个包贼麻烦,是一级级改的:
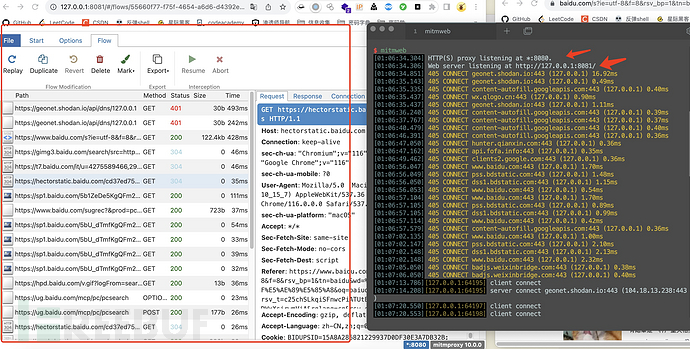
"猫的睾丸人可以吃吗?","猫咪的睾丸能给猫吃吗?",我擦,你们是个人??继续讲,然后这就像个编辑器是的,用上下,鼠标可以点进特定的包看,下面有选择啊,重放啊,改包啊,等等功能。完了改个包贼麻烦,是一级级改的: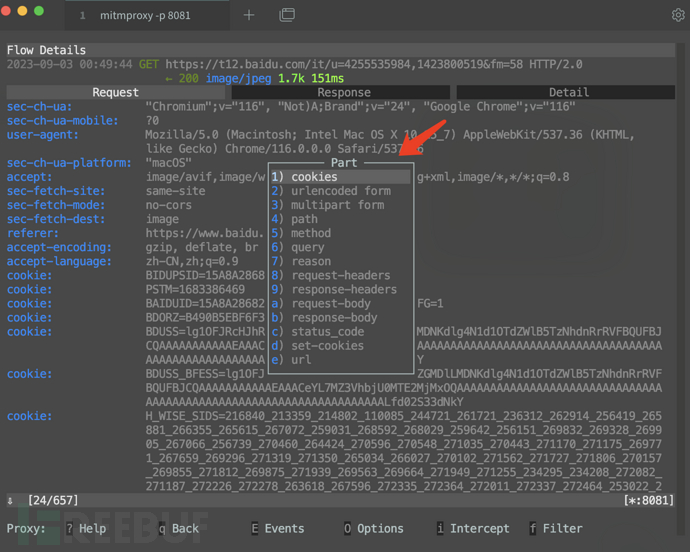 内心OS:这tm哪好?跟burpsuite差了十万八千里!然后去玩了玩mitmweb:简单点,就是,mitmproxy的网页版。默认监听本地的8080端口,网页版在访问127.0.0.1:8081端口就能看到流量了,如图,还行,该有的功能都有,比较简洁,那我为啥不用burp?
内心OS:这tm哪好?跟burpsuite差了十万八千里!然后去玩了玩mitmweb:简单点,就是,mitmproxy的网页版。默认监听本地的8080端口,网页版在访问127.0.0.1:8081端口就能看到流量了,如图,还行,该有的功能都有,比较简洁,那我为啥不用burp?
漏洞被动探测实战
完成了上述工作,我们已经具备了操作 mitmproxy 的基本能力,接下来要讲的,才是mitmproxy真正强大的地方:迅速编写定制脚本。脚本的编写需要遵循 mitmproxy 规定的套路,这样的套路有两个,使用时选其中一个套路即可。第一个套路是,编写一个 py 文件供 mitmproxy 加载,文件中定义了若干函数,这些函数实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的函数,形如:
import mitmproxy.http
from mitmproxy import ctx
num = 0
def request(flow: mitmproxy.http.HTTPFlow):
global num
num = num + 1
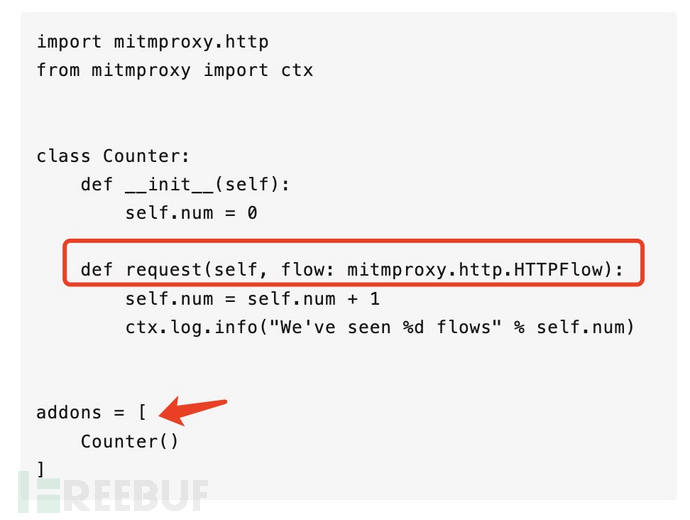
ctx.log.info("We've seen %d flows" % num)第二个套路是,编写一个 py 文件供 mitmproxy 加载,文件定义了变量 addons,addons 是个数组,每个元素是一个类实例,这些类有若干方法,这些方法实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的方法。这些类,称为一个个 addon,比如一个叫 Counter 的 addon:
import mitmproxy.http
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow: mitmproxy.http.HTTPFlow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
addons = [
Counter()
]这里强烈建议使用第二种套路,直觉上就会感觉第二种套路更为先进,使用会更方便也更容易管理和拓展。况且这也是官方内置的一些 addon 的实现方式。
我们将上面第二种套路的示例代码存为 addons.py,再重新启动 mitmproxy:
mitmweb -s addons.py当浏览器使用代理进行访问时,就应该能看到控制台里有类似这样的日志:
Web server listening at http://127.0.0.1:8081/
Loading script addons.py
Proxy server listening at http://*:8080
We've seen 1 flows
……
……
We've seen 2 flows
……
We've seen 3 flows
……
We've seen 4 flows
……上述的脚本估计不用我解释相信大家也看明白了,就是当 request 发生时,计数器加一,并打印日志。这里对应的是 request 事件,那拢共有哪些事件呢?不多,也不少,这里详细介绍一下。
事件针对不同生命周期分为 5 类。“生命周期”这里指在哪一个层面看待事件,举例来说,同样是一次 web 请求,我可以理解为“HTTP 请求 -> HTTP 响应”的过程,也可以理解为“TCP 连接 -> TCP 通信 -> TCP 断开”的过程。那么,如果我想拒绝来个某个 IP 的客户端请求,应当注册函数到针对 TCP 生命周期 的 tcp_start事件,又或者,我想阻断对某个特定域名的请求时,则应当注册函数到针对 HTTP 声明周期的 http_connect事件。其他情况同理。
针对 HTTP 生命周期
def http_connect(self, flow: mitmproxy.http.HTTPFlow):(Called when) 收到了来自客户端的 HTTP CONNECT 请求。在 flow 上设置非 2xx 响应将返回该响应并断开连接。CONNECT 不是常用的 HTTP 请求方法,目的是与服务器建立代理连接,仅是 client 与 proxy 的之间的交流,所以 CONNECT 请求不会触发 request、response 等其他常规的 HTTP 事件。
def requestheaders(self, flow: mitmproxy.http.HTTPFlow):(Called when) 来自客户端的 HTTP 请求的头部被成功读取。此时 flow 中的 request 的 body 是空的。
def request(self, flow: mitmproxy.http.HTTPFlow):(Called when) 来自客户端的 HTTP 请求被成功完整读取。
def responseheaders(self, flow: mitmproxy.http.HTTPFlow):(Called when) 来自服务端的 HTTP 响应的头部被成功读取。此时 flow 中的 response 的 body 是空的。
def response(self, flow: mitmproxy.http.HTTPFlow):(Called when) 来自服务端的 HTTP 响应被成功完整读取。
def error(self, flow: mitmproxy.http.HTTPFlow):(Called when) 发生了一个 HTTP 错误。比如无效的服务端响应、连接断开等。注意与“有效的 HTTP 错误返回”不是一回事,后者是一个正确的服务端响应,只是 HTTP code 表示错误而已。
问:讲了这么多,啥意思?答:就是给了你几个接口,这些接口分别会在发生特定事件的时候执行,执行的内容呢,你可以自己diy,以request为例,flow字面意思就是流,直接理解为mitmproxy的流量,在request里,你可以自己diy,例子中是在请求的时候计数,并打印到日志中。addons是加载"插件"的地方。
jeecg-boot精准被动漏洞探测实战
最近打攻防的时候遇到了一个jeecg-boot的站点,就以此为例,使用mitmproxy完成jeecg漏洞被动探测,这个组件有好多漏洞,接口未授权,SQL注入,ssti模板注入,jdbc代码执行等等。
真实场景下:
1、业务的路由会变化,不一定在jeecg-boot的目录下。2、真实的接口隐藏在js里,发起登陆操作后才会看到。
1 -带来了什么问题? 传统的扫描器明明通过指纹识别识别到这是个jeecg-boot的站点,但是根本打不了,路径都不对。。。
2 -带来了什么问题? 传统扫描器打偏,那只能手动找接口,手工去抓包,手工去打漏洞,极其繁琐。

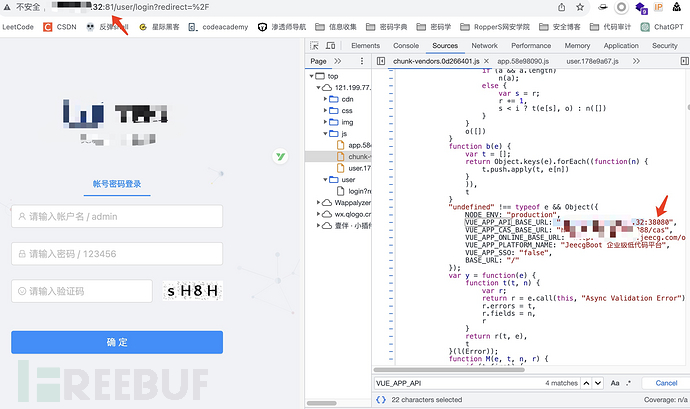
需求这不就来了么?
1、我们前期信息搜集,找到了一个jeecg-boot的站点。2、mitmproxy帮我们去自动寻找接口在哪里。3、找到接口后,mitmproxy帮我们自动实现漏洞验证4、而我们在此过程中做了什么?只是点开了这个网站而已!
我们要做三件事
1、指纹识别,确定jeecg-boot站点2、正则匹配,提取真实jeecg-boot接口3、找到接口后,写入文件,打印,漏洞发包尝试利用。。。

这里直接给出代码,代码仅仅实现了一个demo,只在访问jeecg-boot过程中,抓取了真正的后台路径,然后分别添加几个sql注入路径,未授权访问并写入csv文件,如果需要漏洞利用,可以在抓取后,发送对应的web请求,判断返回包即可。
使用mitmproxy -s 开启脚本

随便点点网页,回头看看文件:
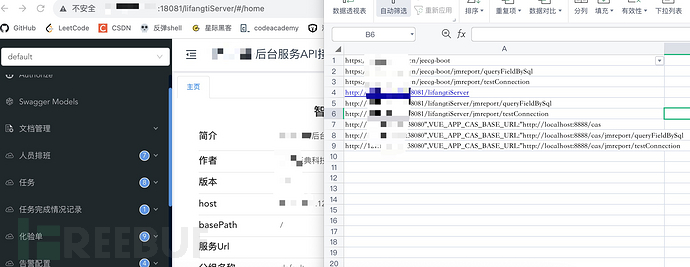
漏洞这不就来了么.....demo代码在github/MD-SEC的库里哦
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
![[ZJCTF 2019]NiZhuanSiWei 超详题解](https://image.3001.net/images/20230915/1694761790_6504033eed8777f476faf.png!small)





- 1 文章数
- 1 关注者