


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

深入fastjson源码命令执行调试
 青青草原羊真香
青青草原羊真香- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
深入fastjson源码命令执行调试
写作背景
之前写过一篇fastjson漏洞文章,但是当时在复现利用链的过程中一直没有弹出计算器,而且利用链的代码单步调试也没有给出来,这次我要通过底层代码把漏洞实现过程展现出来。
fastjson漏洞demo
上次不是没有弹出计算器吗,这次我先把可以弹出计算器的漏洞demo先讲解一下。
- 创建一个普通类Person
import java.util.Properties;
//创建一个普通类
public class Person {
private String name;
private int age;
private String sex;
private Properties properties;
public Person() {
System.out.println("构造方法");
}
//Setter Getter方法
public String getName() {
System.out.println("getName");
return name;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
public int getAge() {
System.out.println("getAge");
return age;
}
public String getSex(){
System.out.println("getAddress");
return sex;
}
public Properties getProperties() throws Exception {
System.out.println("getProperties");
Runtime.getRuntime().exec("open -a /System/Applications/Calculator.app");
return properties;
}
}- 反序列化测试
import com.alibaba.fastjson.JSON;
public class Demo {
public static void main(String[] args){
String jsonstring ="{\"@type\":\"com.FastjsonDemo.Person\",\"age\":18,\"name\":\"lili\",\"address\":\"china\",\"properties\":{}}";
//JSON.parseObject() 方法将 jsonstring 字符串解析并转换为一个通用的 Object 对象
Object obj = JSON.parseObject(jsonstring, Object.class);
System.out.println(obj);
}
}- 测试结果
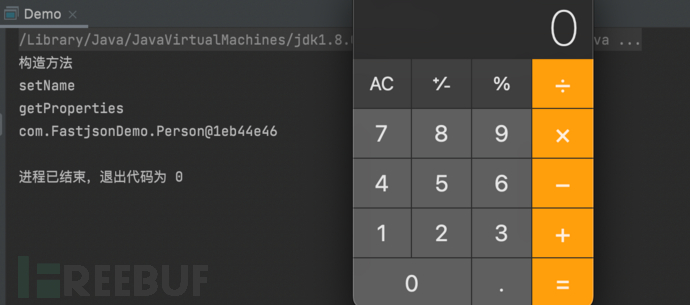
代码调试讲解
- 我们在JSON.parseObject位置处打上断点
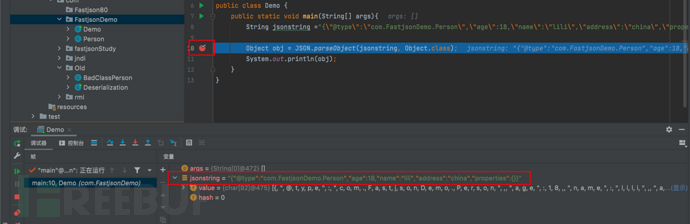
- f7步入,进入到parseObject(String text, Class<T> clazz)方法中,text为要解析的JSON字符串;clazz为要转换的目标类型,Class<T>中的T为范型参数,表示要转换成的具体类型。在这个方法的实现中,它再次调用自己,通过递归无限循环调用自身。
public static <T> T parseObject(String text, Class<T> clazz) {
return parseObject(text, clazz);
}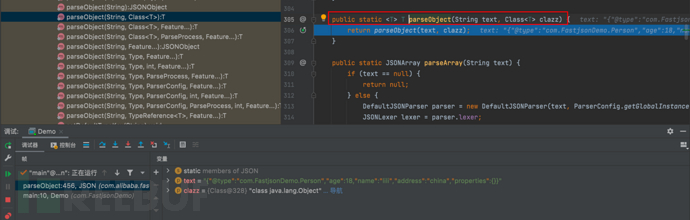
- f7继续步入,进入parseObject(String json, Class<T> clazz, Feature... features)方法,这里又是一个重载方法,接受了三个参数:一个JSON字符串json、目标类型的Class<T>对象clazz和可选的特性(features)数组。在方法的实现中,它掉用了另一个重载的'parseObject'方法,将解析过程委托给它。这个新的重载方法接受了更多的参数,包括:ParserConfig对象、ParseProcess对象以及默认的解析特性(DEFAULT_PARSER_FEATURE)。
public static <T> T parseObject(String json, Class<T> clazz, Feature... features) {
return parseObject(json, clazz, ParserConfig.global, (ParseProcess)null, DEFAULT_PARSER_FEATURE, features);
}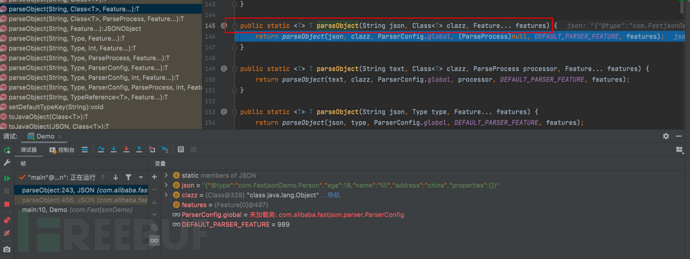
- f7步入到 public static <T> T parseObject(String input, Type clazz, ParserConfig config, ParseProcess processor, int featureValues, Feature... features) {...}方法中
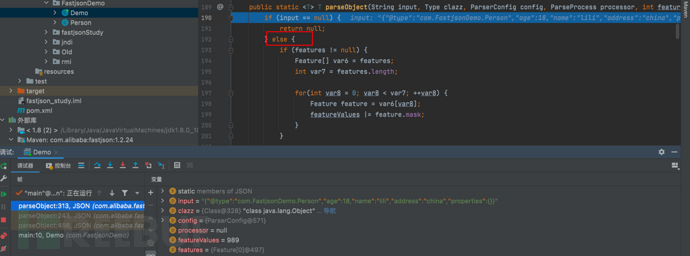
- 我们详细看一下这段代码,目的是将输入的input字符串解析为指定类型 'clazz' 的java对象。
public static <T> T parseObject(String input, Type clazz, ParserConfig config, ParseProcess processor, int featureValues, Feature... features) {
//input为{"@type":"com.FastjsonDemo.Person","age":18,"name":"lili","address":"china","properties":{}}
if (input == null) {
return null;
} else {
//features为Feature[0]@497
if (features != null) {
Feature[] var6 = features;
//定义特性数组长度var7
int var7 = features.length;
for(int var8 = 0; var8 < var7; ++var8) {
//获取当前索引var8位置的特性对象,并将其复制给变量feature
Feature feature = var6[var8];
//使用按位或操作符(|=)将当前特性的掩码(feature.mask)与featureValues进行按位或运算,并将结果重新赋值给featureValues
featureValues |= feature.mask;
}
}
//创建一个DefaultJSONParser对象parser,用于解析JSON字符串。这个对象使用传入的输入字符串、配置对象config和特性值featureValues进行初始化。
DefaultJSONParser parser = new DefaultJSONParser(input, config, featureValues);
//处理解析过程中的处理器processor,此时processor为null
if (processor != null) {
if (processor instanceof ExtraTypeProvider) {
parser.getExtraTypeProviders().add((ExtraTypeProvider)processor);
}
if (processor instanceof ExtraProcessor) {
parser.getExtraProcessors().add((ExtraProcessor)processor);
}
if (processor instanceof FieldTypeResolver) {
parser.setFieldTypeResolver((FieldTypeResolver)processor);
}
}
//解析JSON字符串并得到解析结果对象
T value = parser.parseObject(clazz, (Object)null);
//处理解析结果中的后续任务
parser.handleResovleTask(value);
//关闭解析器
parser.close();
//返回解析结果对象
return value;
}
}- 跟着f8步过代码
- 首先执行循环
for(int var8 = 0; var8 < var7; ++var8) {
Feature feature = var6[var8];
featureValues |= feature.mask;
}- 随后跳转创建DefaultJSONParser对象
DefaultJSONParser parser = new DefaultJSONParser(input, config, featureValues);
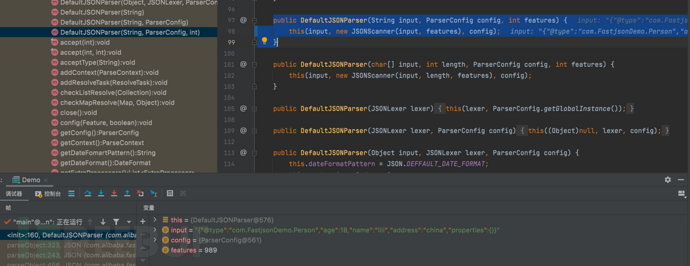
- 继续执行processor的判断,因为processor为空,跳过判断
if (processor != null) {...}- 随后进行解析JSON字符串并得到解析结果对象
这里是使用解析器parser对JSON字符串进行解析,并将解析结果赋值给变量value。解析的目标类型由参数clazz指定,该方法返回了一个泛型类型T的对象。
T value = parser.parseObject(clazz, (Object)null);
- 直接f8跳转下一步,可以发现计算器被弹出来,造成命令执行
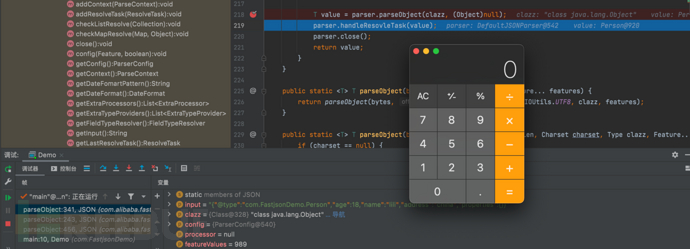
- 重点调试parser.parseObject(clazz, (Object)null)代码
T value = parser.parseObject(clazz, (Object)null);
- f7步入代码
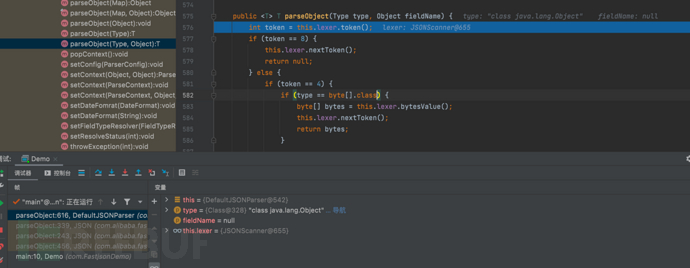
public <T> T parseObject(Type type, Object fieldName) {
//获取当前JSON的token类型
int token = this.lexer.token();
if (token == 8) {//如果当前token是JSON的null值(8代表null)
this.lexer.nextToken();//跳过null值解析
return null;
} else {
if (token == 4) {//如果当前token是JSON的字符串值(4代表字符串)
if (type == byte[].class) {//判断期望类型是否为 'byte[]'
byte[] bytes = this.lexer.bytesValue();//如果是,获取字节数组值
this.lexer.nextToken();//跳过字符串值的解析
return bytes;//返回字节数组值
}
if (type == char[].class) {//判断其我想是否为 'char[]'
String strVal = this.lexer.stringVal();
this.lexer.nextToken();
return strVal.toCharArray();//将字符串转换为字符数组并返回
}
}
//以上都不满足,根据期望类型获取相应的'ObjectDeserializer',并使用它来解析
ObjectDeserializer derializer = this.config.getDeserializer(type);
try {
return derializer.deserialze(this, type, fieldName);//通过config(ParserConfig对象)获取相应类型的反序列化器,并调用deserialze方法进行解析。该方法会根据给定的JSON类型和字段名,将当前解析器作为参数,返回解析后的Java对象。
} catch (JSONException var6) {
throw var6;
} catch (Throwable var7) {
throw new JSONException(var7.getMessage(), var7);
}
}
}- 初始化token值为12
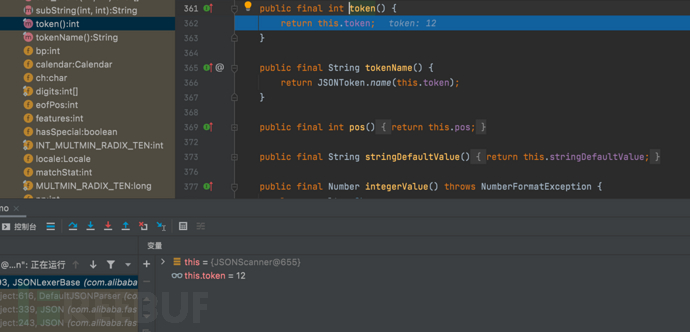
- 不满足if循环。会步入ObjectDeserializer derializer = this.config.getDeserializer(type);
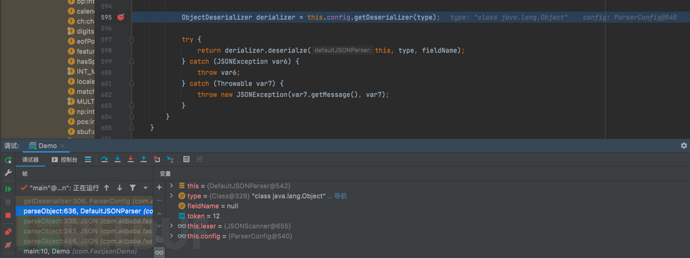
- 分析这段代码实现细节
ObjectDeserializer derializer = this.config.getDeserializer(type);
- f7步入,这段代码是 'ParseConfig' 类中的 'getDeserializer(Type type)'方法,目的是根据给定的类型(Type)获取相应的反序列化器(ObjectDeserializer)。初始 derializers 为默认值IdentityHashMap@659,derializer的值为null。随后进行一个缓存类型的判断:(1)如果类型type属于 'Class' 类型,调用 getDeserializer(Class, Type)方法,传入类型(Class)和类型(Type)进行处理;(2)如果类型(Type)是ParameterizedType类型,获取原始类型(RawType)。随后做了一个三元运算符判断:如果原始类型是Class类型就调用getDeserializer(Class, Type)方法,对传入原始类型(Class)和类型(Type)进行处理;否则就递归调用getDeserializer(Type)方法,对传入原始类型(RawType)进行处理。(3)其他情况就返回默认的反序列化器 'JavaObjectDeserializer.instance'。
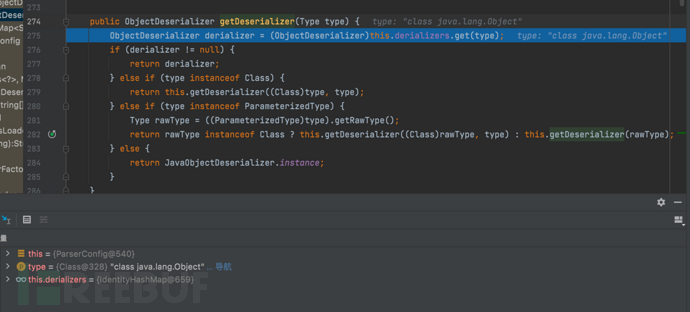
- f7继续步入后是一段基于身份比较hash映射的 'get' 方法
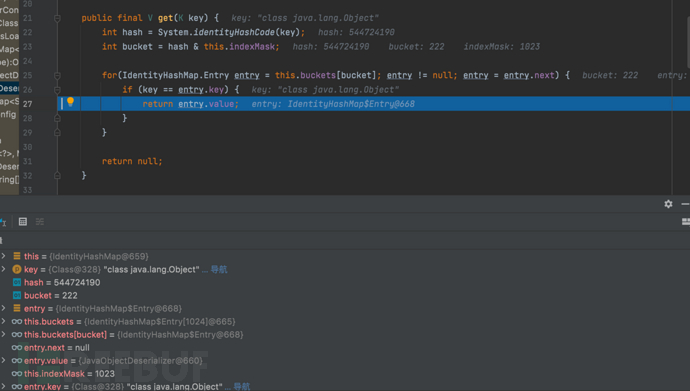
- 最终获取的derializer值为JavaObjectDeserializer@660
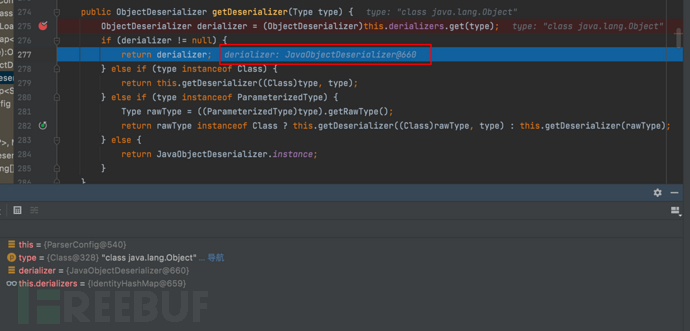
- 返回反序列化器具体值:当前对象DefaultJSONParser@542、类型type为Object对象、fieldName字段名为null、config属性值为ParseConfig@540
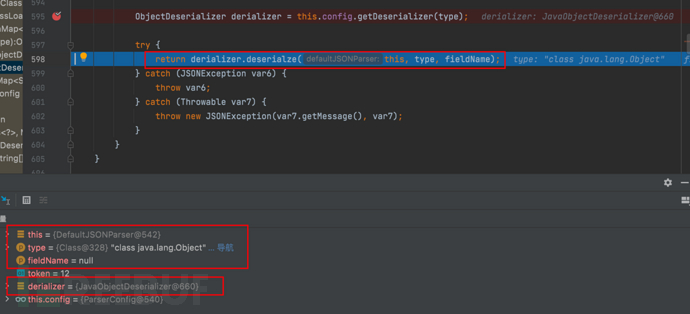
- 返回值的具体实现可以f7继续步入查看
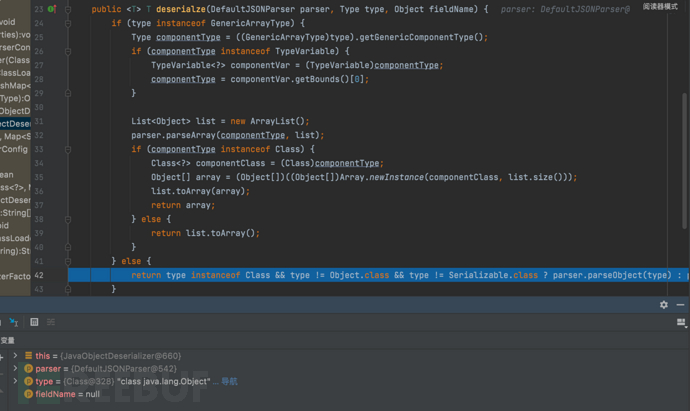
- 底层是一个JSON解析器的 'parse' 方法,lexer的初始化默认值为JSONScanner@655
public Object parse(Object fieldName) {
JSONLexer lexer = this.lexer;
switch(lexer.token()) {
case 1:
case 5:
case 10:
case 11:
case 13:
case 15:
case 16:
case 17:
case 18:
case 19:
default:
throw new JSONException("syntax error, " + lexer.info());
case 2:
Number intValue = lexer.integerValue();
lexer.nextToken();
return intValue;
case 3:
Object value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
lexer.nextToken();
return value;
case 4:
String stringLiteral = lexer.stringVal();
lexer.nextToken(16);
if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) {
JSONScanner iso8601Lexer = new JSONScanner(stringLiteral);
try {
if (iso8601Lexer.scanISO8601DateIfMatch()) {
Date var11 = iso8601Lexer.getCalendar().getTime();
return var11;
}
} finally {
iso8601Lexer.close();
}
}
return stringLiteral;
case 6:
lexer.nextToken();
return Boolean.TRUE;
case 7:
lexer.nextToken();
return Boolean.FALSE;
case 8:
lexer.nextToken();
return null;
case 9:
lexer.nextToken(18);
if (lexer.token() != 18) {
throw new JSONException("syntax error");
}
lexer.nextToken(10);
this.accept(10);
long time = lexer.integerValue().longValue();
this.accept(2);
this.accept(11);
return new Date(time);
case 12:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return this.parseObject((Map)object, fieldName);
case 14:
JSONArray array = new JSONArray();
this.parseArray((Collection)array, (Object)fieldName);
if (lexer.isEnabled(Feature.UseObjectArray)) {
return array.toArray();
}
return array;
case 20:
if (lexer.isBlankInput()) {
return null;
}
throw new JSONException("unterminated json string, " + lexer.info());
case 21:
lexer.nextToken();
HashSet<Object> set = new HashSet();
this.parseArray((Collection)set, (Object)fieldName);
return set;
case 22:
lexer.nextToken();
TreeSet<Object> treeSet = new TreeSet();
this.parseArray((Collection)treeSet, (Object)fieldName);
return treeSet;
case 23:
lexer.nextToken();
return null;
}
}- f8步过,进入到case12。这里首先创建了一个新的JSONObject对象,并启用了Feature.OrderedField特性(这个特性是用于指示是否保留JSON对象中字段的顺序);随后调用了当前对象的parseObject方法,将刚刚创建的object对象作为参数传递进去,并传递fileName作为另一个参数。
case 12:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return this.parseObject((Map)object, fieldName);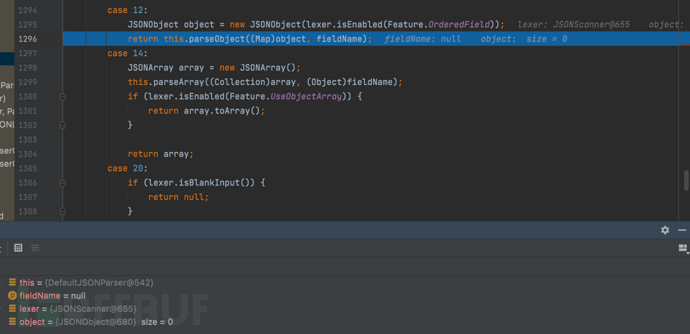
- 继续f7步入,查看parseObject反序列化的具体实现
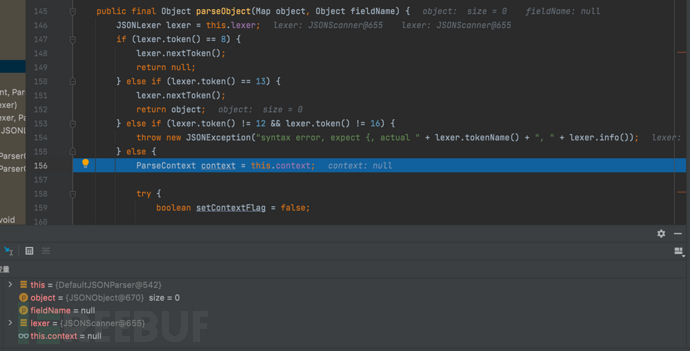
- 底层对key做了个判断
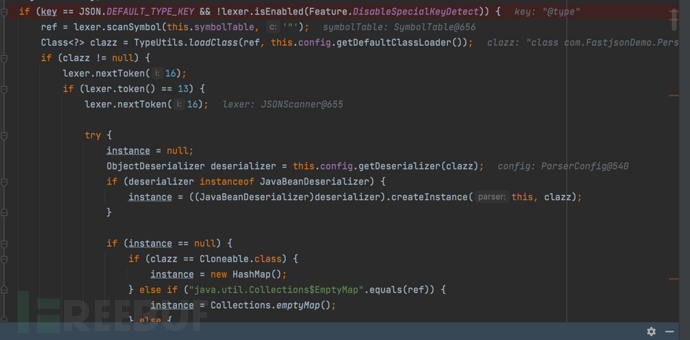
- 继续步过可以在底层发现从当前对象的配置中获取一个用于指定类 'clazz' 的反序列化器,这个clazz就是我们要反序列化的Person类。
ObjectDeserializer deserializer = this.config.getDeserializer(clazz);
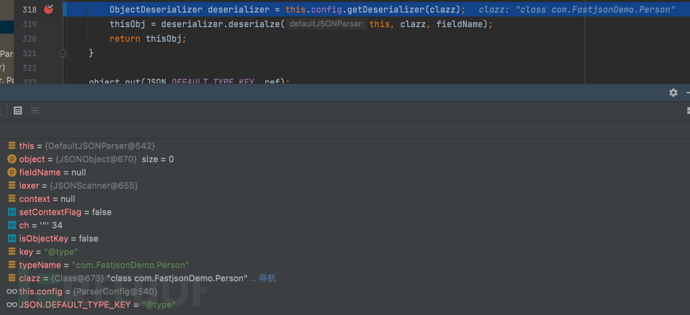
- 回到getDeserializer代码的实现位置,这里我们重新带入要反序列化的type(Person类)
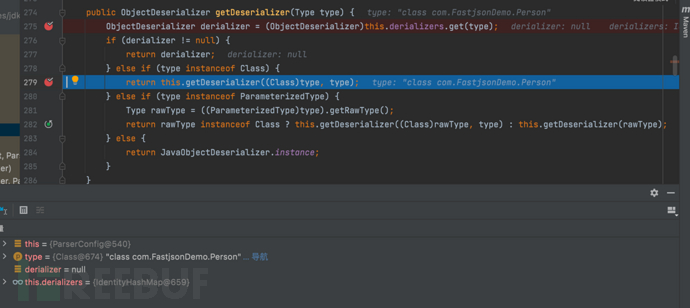
- f8步过,依然是要从当前对象的配置中获取与指定类 'clazz'相关联的反序列化器 ObjectDeserializer
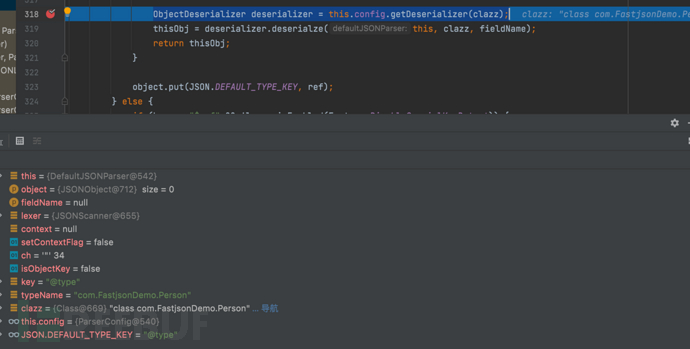
- f8步过查看 thisObj = deserializer.deserialze(this, clazz, fieldName); 的具体实现
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName) {
return this.deserialze(parser, type, fieldName, 0);
}
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName, int features) {
return this.deserialze(parser, type, fieldName, (Object)null, features);
}- 相当于对Person类做一遍和Object类一样的调试,这里的token值为16
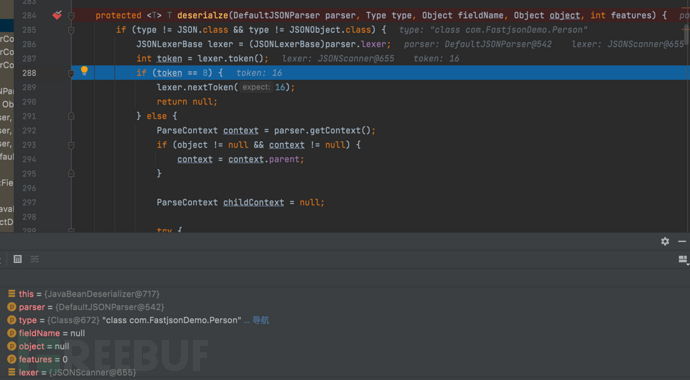
- f8步过token=16的循环体
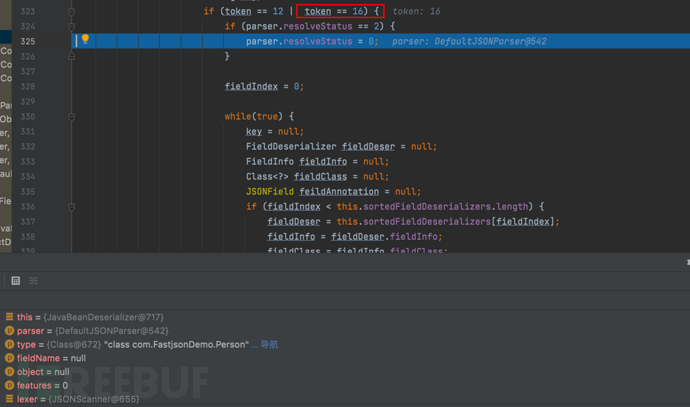
- 继续步过走到自增fieldIndex
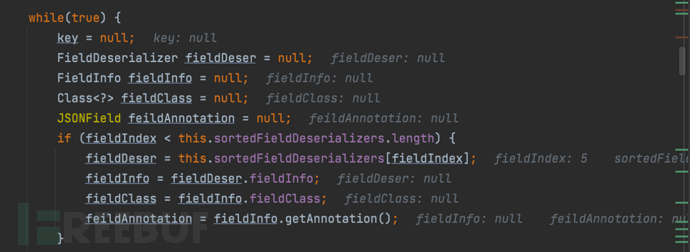
- 通过多次递增,直到fileIndex为5
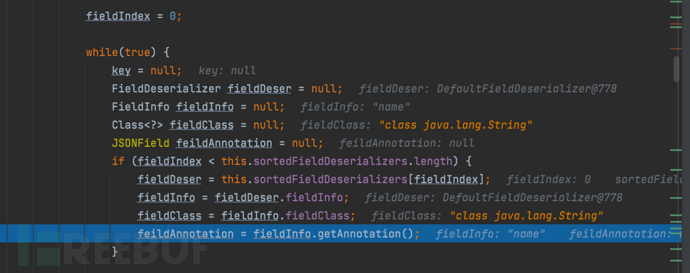
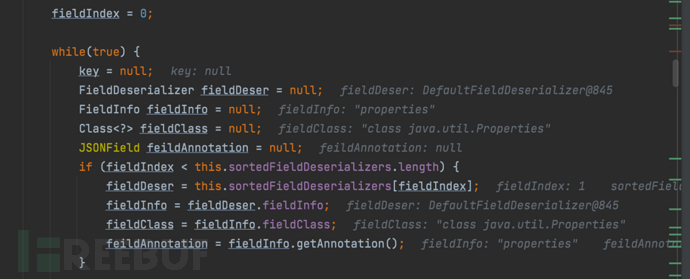
......
- 再看这段代码,判断当前解析操作是否成功,只要解析成功即可弹出计算器
boolean match = this.parseField(parser, key, object, type, fieldValues);
- 仔细查看代码的实现过程
public boolean parseField(DefaultJSONParser parser, String key, Object object, Type objectType, Map<String, Object> fieldValues) {
//创建了一个JSONLexer对象,并将其初始化为 'parser'对象的 'lexer'属性
JSONLexer lexer = parser.lexer;
//smartMatch方法用于根据提供的字段名key匹配对应的字段解析器
FieldDeserializer fieldDeserializer = this.smartMatch(key);
//创建一个mask的整型变量,并设置为 'Feature.SupportNonPublicField.mask'的值
int mask = Feature.SupportNonPublicField.mask;
if (fieldDeserializer == null && (parser.lexer.isEnabled(mask) || (this.beanInfo.parserFeatures & mask) != 0)) {
if (this.extraFieldDeserializers == null) {
ConcurrentHashMap extraFieldDeserializers = new ConcurrentHashMap(1, 0.75F, 1);
Field[] fields = this.clazz.getDeclaredFields();
Field[] var11 = fields;
int var12 = fields.length;
//遍历当前类声明的字段,对每个字段进行一下操作:(1)获取字段名并检查是否已存在对应的字段解析器;(2)检查字段的修饰符,判断是否为非公共字段和非静态字段;(3)如果满足条件,则将字段添加到extraFieldDeserializers中。
for(int var13 = 0; var13 < var12; ++var13) {
Field field = var11[var13];
String fieldName = field.getName();
if (this.getFieldDeserializer(fieldName) == null) {
int fieldModifiers = field.getModifiers();
if ((fieldModifiers & 16) == 0 && (fieldModifiers & 8) == 0) {
extraFieldDeserializers.put(fieldName, field);
}
}
}
this.extraFieldDeserializers = extraFieldDeserializers;
}
Object deserOrField = this.extraFieldDeserializers.get(key);
if (deserOrField != null) {
if (deserOrField instanceof FieldDeserializer) {
fieldDeserializer = (FieldDeserializer)deserOrField;
} else {
Field field = (Field)deserOrField;
field.setAccessible(true);
FieldInfo fieldInfo = new FieldInfo(key, field.getDeclaringClass(), field.getType(), field.getGenericType(), field, 0, 0, 0);
fieldDeserializer = new DefaultFieldDeserializer(parser.getConfig(), this.clazz, fieldInfo);
this.extraFieldDeserializers.put(key, fieldDeserializer);
}
}
}
//如果fieldDeserializer为空,继续判断:
if (fieldDeserializer == null) {//如果lexer未启用Feature.IgnoreNotMatch,抛出异常
if (!lexer.isEnabled(Feature.IgnoreNotMatch)) {
throw new JSONException("setter not found, class " + this.clazz.getName() + ", property " + key);
} else {//否则调用'parser.parseExtra(object,key)'方法,将额外的字段解析给 object
parser.parseExtra(object, key);
return false;//false表示未成功解析字段
}
} else {//filedDeserializer不为空,通过下列方法将解析器移到字段值的冒号位置,并解析字段值
lexer.nextTokenWithColon(((FieldDeserializer)fieldDeserializer).getFastMatchToken());
((FieldDeserializer)fieldDeserializer).parseField(parser, object, objectType, fieldValues);
return true;//返回true表示成功解析
}
}- 此时fieldDeserializer不为空
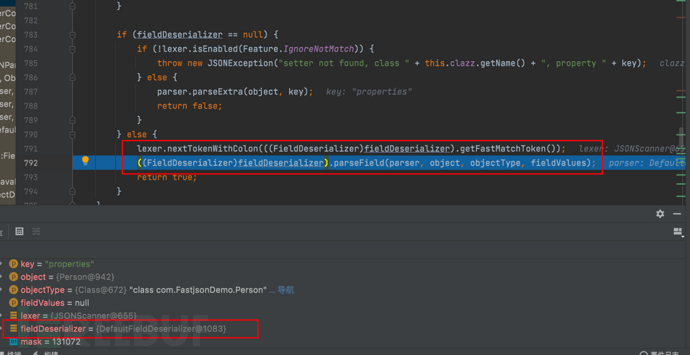
- 跟进 ((FieldDeserializer)fieldDeserializer).parseField(parser, object, objectType, fieldValues); 最后使用字段值的反序列化器从解析器中解析字段的值
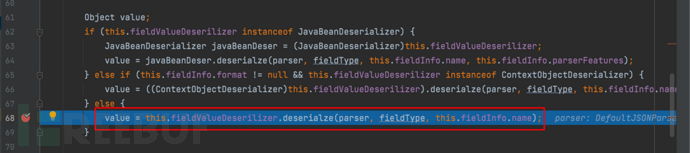
- 继续步过,将解析得到的字段值 value 设置到目标对象 object 的对应字段上
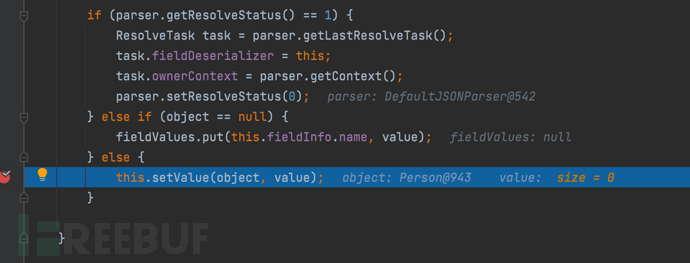
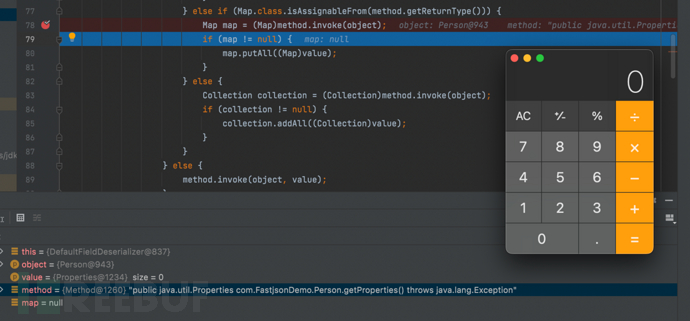
- 跟进setValue,可以清晰的看见通过反射调用了Person类的getProperties() throws Exception
写作感悟
- 调试的过程,底层其实就是先对Object进行反序列化,再对具体的Person类进行反序列化,中间有一些重复的过程,当然底层有很多过程其实很难一个个去分析出来,重点一定要先自己先调试完,自己多走几遍可能就知道它流程了。
- 这篇文章写了大概得有四五天,其实调试什么的就是跟着代码往下走,不会的代码就查询。这里就是给出了我在调试过程中遇到的情况,也是想告诉大家代码审计、代码调试就是一个耐心的活。
免责声明
1.一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
本文为 青青草原羊真香 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
被以下专辑收录,发现更多精彩内容
+ 收入我的专辑
+ 加入我的收藏
相关推荐





青青草原羊真香 LV.4
这家伙太懒了,还未填写个人描述!
- 9 文章数
- 9 关注者
php代码审计篇二——ZbzCMS
2023-10-16
php代码审计学习笔记-xhcms
2023-09-28
java反射探讨
2023-09-07
文章目录