


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
0x00
有个大佬说过,渗透的本质就是信息收集,在边界突破的阶段,信息收集是前置条件,经过多年实战攻防的积累,现在信息收集已经形成了标准化的流程,因此我们在尝试建设自动化信息收集工具。
防守方大部分的防守力量都会放到边界的web系统上,对于移动端的暴露面通常容易疏忽,所以对于移动资产的收集就十分重要,下面介绍一下公众号搜索方法。
0x01 企业信息查询
常见的企业信息查询网站有天眼查、企查查、爱企查、启信宝、小蓝本等,可以直接登录平台去查询,以天眼查为例:
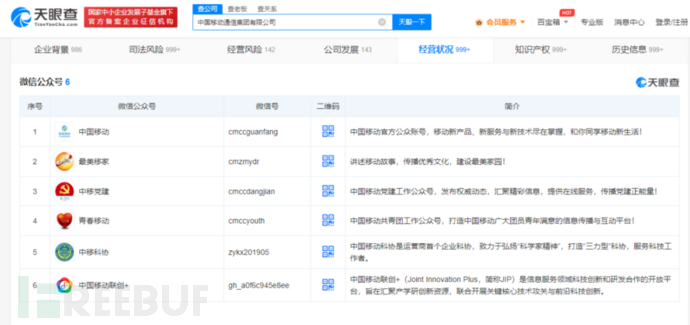
可以使用脚本直接从通过前端获取数据,不仅仅是公众号,其他信息也可以获取,但是自从攻防演练开始后,这些企业信息查询网站都增强了反爬虫机制,频率过高就会弹出验证码,从前端获取数据反爬虫对抗有一定技术门槛。
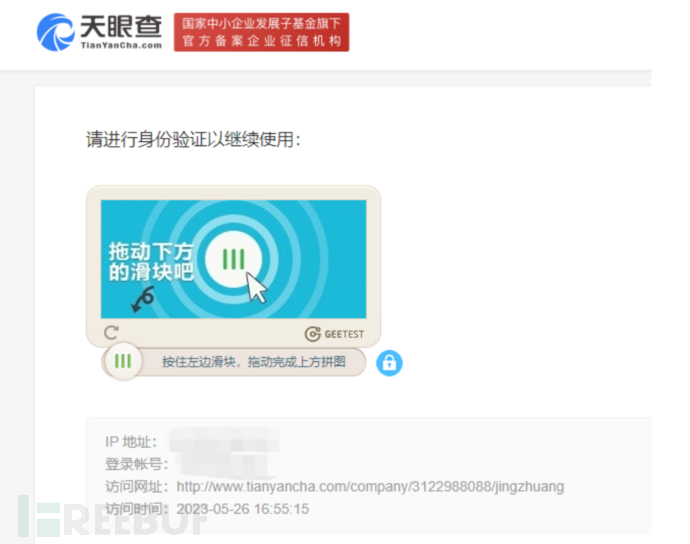
除了直接查询,平台基本都会提供api接口调用,可以免去反爬绕过的问题,缺点就是要氪金,如果是大批量查询的话,还不便宜,但优点是使用方便。
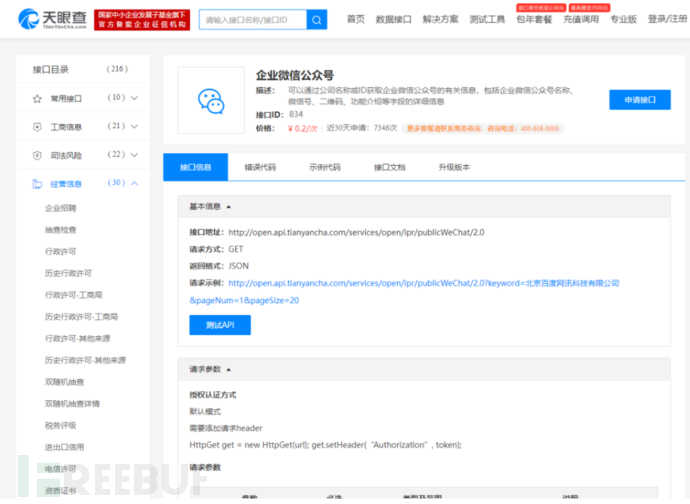
代码实现也比较简练,官方的api文档中也有代码demo。
# https://open.tianyancha.com/open/834
def GetWechatOfficialAccount(self, keyword, pageNum=1, pageSize=20):
url = "http://open.api.tianyancha.com/services/open/ipr/publicWeChat/2.0?keyword=%s&pageNum=%s&pageSize=%s" % (keyword, pageNum, pageSize)
headers={'Authorization': {天眼查Token}}
try:
response = requests.get(url, headers=headers)
except Exception as err:
logger.error(str(err))
return None
data = response.json()0x02 通过搜索引擎搜索
平时根本不用搜狗搜索,读《张朝阳:重新出发》这本书的时候,才知道搜狗搜索和微信有合作,可以直接搜索公众号,可以考虑通过搜索引擎的接口来批量获取公众号信息。
通过搜狗搜索获取的结果要比天眼查获取的结果多,直接get请求就可以获取:https://weixin.sogou.com/weixin?type=1&s_from=input&query={关键字}&ie=utf8&_sug_=n&_sug_type_=&page={页数}
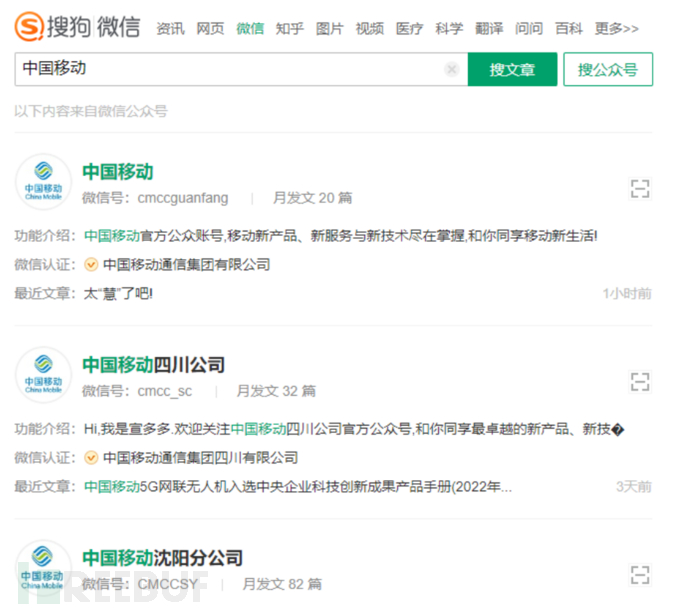
但是跑着跑着,就遇到了搜狗的antispider。
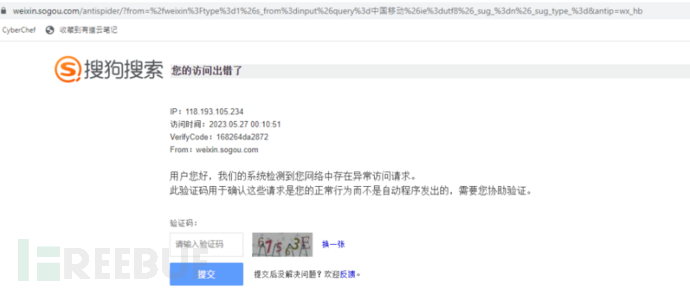
遇到反爬一般有3种对抗方法:
硬钢验证码
更换IP
修改请求cookie绕过
这里我没有采用绕验证码,尝试了更换IP,发现还是提示有验证码,因此断定搜狗反爬虫机制是通过http请求头中特殊的cookie字段实现的频率检测。
访问搜狗微信搜索会返回如下cookie:

| Cookie: IPLOC=CN1100; SUID=EA69C1767450A00A000000006470DB3F; cuid=AAEAYHYPRQAAAAqgIy28JwAAvgU=; SUV=1685117759828180; ABTEST=6|1685117772|v1; SNUID=64E44CFB8D88711683B617DE8E7C80C3 |
经过测试,发现修改SNUID就可以绕过反爬,那么就可以通过不停访问搜狗的网站获取新的SNUID实现绕过反爬。
由于搜狗首页有很多功能,我们访问一个不会限制频率的页面搜狗视频,发现也可以正常获取SNUID。
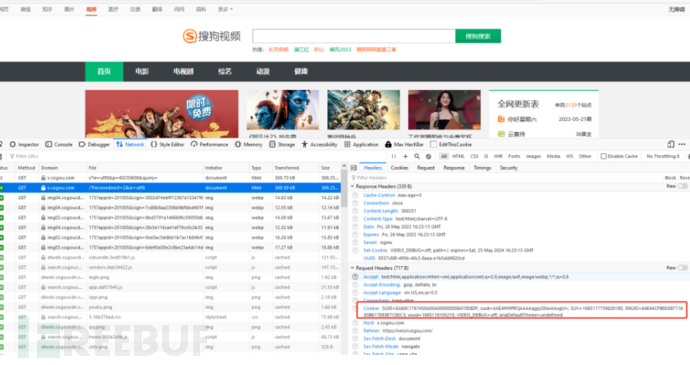
至此问题可以解决了,通过公众号搜索接口搜索目标的公众号,当触发反爬机制后,访问搜狗视频获取新的SNUID,即可继续使用公众号搜索接口。
我使用了fake_useragent库来生成随机UA,代码如下:
import urllib.parse
import requests
from lxml import etree
from fake_useragent import UserAgent
import time,sys,os,math,json,random
#生成随机UA
ua = UserAgent(browsers=["chrome", "edge", "internet explorer", "firefox", "safari"])
global_headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "SUID=10800C75492CA20A000000006145E582; SUV=1641002706609755; ssuid=8628497906; IPLOC=CN1200; cuid=AAERmghDQwAAAAqgHl6xlgAASQU=; ABTEST=0|1684314665|v1; JSESSIONID=aaaXmp_IROcwx7NZRDDEy; PHPSESSID=snjidnapfi0p1lsac6jgb8huu1; SNUID=8A0A5AACD7DD2C295C858FD2D8397552; ariaDefaultTheme=undefined",
"Referer": "https://weixin.sogou.com",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": ua.random,
"sec-ch-ua": '"Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"X-Forwarded-For": "110.242.68.66"
}
#https://weixin.sogou.com/weixin?query=%E6%B8%A4%E6%B5%B7%E9%93%B6%E8%A1%8C&_sug_type_=&s_from=input&_sug_=n&type=1&ie=utf8&page=2
#将中文转为url编码
def Chinese2Url(chinese_context):
return urllib.parse.quote(chinese_context)
#获取页面的公众号名称
#页面编号为1,返回获取的数量和第1页公众号列表
#页面编号大于1,返回当页的公众号列表
def GetWechatofficialAccount(keyword_url, headers=global_headers, page=1):
url = "https://weixin.sogou.com/weixin?query="+keyword_url+"&_sug_type_=&s_from=input&_sug_=n&type=1&ie=utf8&page=" + str(page)
xpath_get_official_account = "//li/div/div[2]/p[1]/a/text()"
rep = requests.get(url, headers=headers)
if "请输入验证码" in rep.text:
headers = GetNewCookieHeaders()
rep = requests.get(url, headers=headers)
#更新全局变量,headers和代理
global global_headers
global_headers = headers
req = requests.get(url, headers=headers)
response = rep.text.replace("<em><!--red_beg-->","").replace("<!--red_end--></em>","")
etree_obj = etree.HTML(response)
wechat_official_account = etree_obj.xpath(xpath_get_official_account)
if('<img src="/new/pc/images/bg_404_2.png"' in response):
print("No result")
sys.exit()
if(page == 1):
xpath_get_page_num = "//div[@class='mun']/text()"
item_num = etree_obj.xpath(xpath_get_page_num)[0].replace("找到","").replace("约","").replace("条结果","")
print("item number is %s" % item_num)
return int(item_num),wechat_official_account
else:
return wechat_official_account
def GetNewCookieHeaders():
headers = global_headers
cookie_split = headers["Cookie"].split("; ")
for item in cookie_split:
if "SNUID" in item:
cookie_split.remove(item)
cookie_split.append("SNUID=%s" % GetSougoCookie()["SNUID"])
break
headers["Cookie"] = "; ".join(cookie_split)
return headers
def GetSougoCookie():
# 搜狗视频url,获取新的SNUID
url = "https://v.sogou.com/?forceredirect=2&ie=utf8"
rst = requests.get(url=url,
headers=global_headers,
allow_redirects=False)
cookies = rst.cookies.get_dict()
print("Get new cookie SNUID %s" % cookies["SNUID"])
return {"SNUID":cookies["SNUID"]}
if __name__ == '__main__':
keyword_url = Chinese2Url("中国移动")
item_num,wechat_official_account = GetWechatofficialAccount(keyword_url,headers=global_headers,page=1)
page_num = 10
if item_num < 100:
page_num = math.ceil(item_num/10)
if page_num > 1:
page = 2
while (page <= page_num):
wechat_official_account = sum([wechat_official_account,GetWechatofficialAccount(keyword_url,headers=global_headers,page=page)],[])
print("page = %s" % page)
page += 1
wechat_official_account = list(set(wechat_official_account))
print(wechat_official_account)效果如下

如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者