


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
当你打开浏览器,在地址栏输入一个网址(如https://www.baidu.com),按下回车,浏览器很快就会为你加载出你想要的页面。那么你有没有想过,从你按下回车,到看到最终的页面,浏览器都做了哪些工作(不管你认为它是简单还是复杂,它可能都比你想象的复杂的多!)?
下面我们就从浏览器完整加载和渲染一个网页的过程入手,一步步介绍浏览器的运行机制。
1. 域名解析
知识铺垫 - 域名系统简介
域名系统(英文:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网(来自百度百科)。
为什么需要域名系统?
这就要先说一下我们如何在整个互联网中找到一台主机(你可以先简单理解为一台电脑,实际上这并不准确)了。
根据IP协议(这里指IP v4)的规定,我们使用一个32位长的由二进制数字(0和1)构成的字符串来唯一标识一台主机。为了书写简便,我们以8位为一组,这样就得到4组二进制数,每组的8位二进制转换为十进制后,就是一个0-255之间的数字。因此,这个32的0和1构成的字符串就可以写成4个0-255之间的数字,我们用.连接起来,就得到了形如192.168.1.1这样的一个地址,这个地址我们就称为IP地址。
按照协议,我们必须提供一台主机的IP地址,才可以在整个网络中找到该主机(如百度的服务器)。但是对于每个互联网用户来说,IP地址不仅冗长,而且毫无含义,因此难以记忆。为了解决这个问题,互联网的奠基者设计了域名系统。
所谓域名系统,本质上就是一个用来维护IP地址和网址对应关系的分布式服务系统。比如现在百度希望用户通过 www.baidu.com来访问自己的网站,那么百度就可以向专门的域名注册机构去申请这个网址,并提交自己的IP地址,这样该机构就会在专有的DNS服务器上保存这个对应关系(实际过程远比这复杂得多,如多级域名的管理等)。现在你只需要访问DNS服务器,告诉它你想访问www.baidu.com这个网站(终于不用记住那个难记的IP地址了),你就可以得到百度服务器的实际IP地址,从而访问百度的服务器了。
域名解析完整流程
域名的注册与浏览器无关,但是域名的解析(将网址解析为IP地址)却与浏览器息息相关。
比如我们现在在地址栏输入了百度首页的网址,那么浏览器想要访问这个网站,就必须先查出这个网址对应的IP地址。查询过程主要分以下几步:
- 搜索浏览器的DNS缓存,查询是否有该网址的缓存记录。浏览器会将之前较短时间内访问过的网站的IP地址保存在专有的缓存区中,目的是减少下次查询所需的时间,但缓存时间较短,数量有限。
- 如果搜索失败,那么浏览器会向本地DNS域名服务器发起域名解析请求(使用UDP网络协议),去最近的DNS域名服务器查询该网址的IP。
- 如果上述查询仍然失败(本地DNS服务器不可能保存所有网络主机的IP地址),浏览器就会通过运营商直接向根域名服务器发起查询请求。根域名服务器会根据网址中的一级域名(如上述网址的com,就是一级域名),查询出其对应的服务器地址,并将该地址返回给运营商(之后的解析将全部由运营商代理完成)。
- 运营商根据一级域名的DNS服务器地址,访问该服务器(如com对应的DNS服务器),查询二级域名对应的服务器地址,得到二级域名(如baidu.com)对应的DNS服务器地址。
- 经过上述查询,运营商已经查到了该网址的注册商(百度)的服务器地址,运营商向该服务器发起查询请求,就可以得到最终的IP地址。
- 运营商将查到的IP地址返回回来。至此,浏览器就拿到了上述网址对应的IP地址。
注意:并不是所有的网址解析都需要经过上述所有步骤,一旦在某一步拿到了完整的IP地址,解析过程将立即结束。
现在浏览器终于拿到了访问网站所需的IP地址!接下来就是真正的访问过程了。
2. 建立连接
这个步骤主要是当前主机与服务器之间建立TCP连接。
浏览器得到了服务器的IP地址后,就需要与服务器之间建立一个通信链路,所有的数据都将通过这条通信链路来传递。为了在网络中正确地传输数据,互联网的建设者需要考虑大量的问题,比较典型的如数据丢失处理、网间路由跳转、数据流的编码与解码等等等等。为此web标准化组织制定了大量的网络协议,用于保证数据能在网络间正确地传输。
目前web中广泛采用的是TCP/IP协议族,其中TCP是一个传输层协议,用于保障两台主机之间的通信(IP协议主要用于处理数据在网络之间的路由跳转,如路由器就是一个典型的运行IP协议的设备,由于偏向于底层,这里不再详述)。两台主机建立TCP连接需要经过一个称为三次握手的过程(以我们的主机连接服务器为例):
- 主机根据刚才获得的服务器的IP地址,向服务器发送一个请求,希望与服务器建立TCP连接。
- 服务器收到我们的主机发送的请求后,回复一条确认消息,表示收到我们的连接请求,同意进行TCP连接。
- 我们收到服务器的反馈消息之后,再次发送确认请求,表示我们的主机确认与服务器建立TCP连接。
经过这三步(也称为三次握手),我们的主机就与服务器建立了一个可靠的TCP连接,这个连接会一直持续到双方四次挥手(过程与建立连接类似)断开连接结束。在连接建立期间,由于TCP协议提供的保障,我们在两台主机之间发送的所有信息都将被正确传输(主要依赖TCP强大的纠错机制,以及下层多个网络协议提供的服务)。
现在我们的主机与服务器之间已经建立了一条通信链路,我们可以在这条链路上收发数据。浏览器将基于这条链路,通过http协议(应用层协议,是协议族最高层的协议之一)实现与服务器的消息通信。这里我们不再对http协议展开讲解(可能需要单独的文章介绍)。我们可以先这样简单地理解http协议:浏览器将需要发送的数据,按照一定的格式封装起来,然后添加一系列关于这些数据的描述,最后打成包交给TCP协议去进行网间传递。服务器收到这个数据包,按照同样的规则打开,读取其中的数据和相关描述,这样就借助http协议完成了一次通信。服务器向主机发送消息也是同样的机制。
下面我们来看一下,浏览器是如何在TCP通信链路的基础上,向服务器请求网页文件的。
3. 请求资源
在讲解浏览器请求资源的过程之前,我们需要先了解一下浏览器结构。
浏览器结构
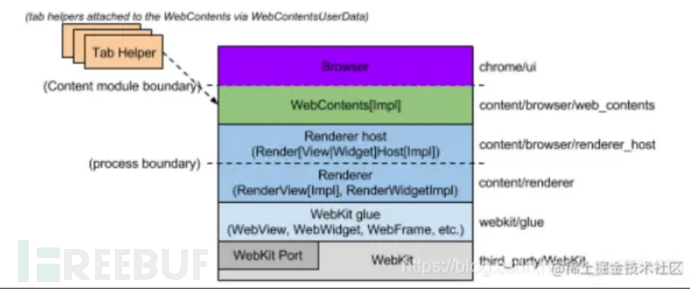
Chromium浏览器的结构如下(图片引自罗升阳的网页加载系列文章,以下关于浏览器结构的理解均参考自该系列文章,详情请见 https://blog.csdn.net/luoshengyang/article/details/50414848 ):
从下往上来看,Chromium总共分以下几层(引用自上述博客):
- WebKit:网页渲染引擎层,定义在命令空间WebCore中。Port部分用来集成平台相关服务,例如资源加载和绘图服务。WebKit是一个平台无关的网页渲染引擎,但是用在具体的平台上时,需要由平台提供一些平台相关的实现,才能让WebKit跑起来。
- WebKit glue:WebKit嵌入层,用来将WebKit类型转化为Chromium类型,定义在命令空间blink中。Chromium不直接访问WebKit接口,而是通过WebKit glue接口间接访问。WebKit glue的对象命名有一个特点,均是以Web为前缀。
- Renderer/Renderer host:多进程嵌入层,定义在命令空间content中。其中,Renderer运行在Render进程中,Renderer host运行在Browser进程中。
- WebContents:允许将一个HTML网页以多进程方式渲染到一个区域中,定义在命令空间content中。
- Browser:代表一个浏览器窗口,它可以包含多个WebContents。
- Tab Helpers:附加在WebContents上,用来增加WebContents的功能,例如显示InfoBar。
这里的Webkit(一个开源项目)和Webkit glue(对webkit的封装层)我们称为Webkit层,提供了诸如HTML引擎、JavaScript引擎(webkit默认的js引擎是JavaScript Core,Chrome就是将这里的引擎替换成了其自主研发的V8引擎)等一系列的底层引擎;Renderer/Renderer host和WebContents称为Content层,主要负责网页的渲染;Brower和Tab Helpers称为浏览器层,主要负责与服务器的通信等。
下面我们就来看一下,浏览器是如何下载网页的。
网页资源的下载
Chromium在加载一个网页前,会在Browser进程中创建一个Frame Tree,这个Frame Tree代表了我们接下来要加载的网页。如果该页面内部嵌有子网页(iframe),Browser进程就会在这个Frame Tree下面添加子节点,用于描述子网页。
当Frame Tree创建完毕之后,Browser进程就会通过一个专用的IPC通道向Content层发送消息通知Render进程。然后Render进程将进行一系列的初始化工作,最主要的是创建一个Render Tree,Render进程之后会通过该树完成网页的渲染。Render Tree初始化完毕后,会通过上述IPC通道告知Browser层,此时Browser进程和Render进程都已准备就绪,可以准备进行网页下载了!
Browser进程根据地址栏中的网址,解析出需要加载的文件路径。
注意:完整的网址应该包括协议类型、域名/IP地址、端口号、要加载的文件地址,如https://www.baidu.com:80/xxx/xxx.html 。协议类型和域名/IP不再解释。端口号是主机中一个进程的标识,同一个服务器可能同时向外提供多个服务,每个服务我们用端口号来区别。文件地址指的是我们需要加载的网页相对于该网站根目录的路径。
但是我们并不需要输入如此多的信息,省略的协议类型浏览器会自动补全;端口号默认是80端口;而对于文件地址,每个服务都会对外提供一个默认入口文件(通常命名为index.html),我们省略了文件地址时,就会加载这个默认的文件。所以我们通常只需要输入域名或者IP地址即可。
Browser进程现在会封装出一个http请求,向服务器请求这个文件,请求中会携带大量的参数,这里不再赘述。服务器收到该请求后,找到对应的文件,将其返回给浏览器。浏览器会将下载到的文件临时保存在Browser层的一块缓冲区中,并通过IPC通道向Render进程发送消息,通知其读取该文件。
4. DOM树和CSSOM树的构建
DOM树的构建
HTML文件的解析并不是Render进程自身完成的,而是交给了更加底层的Webkit层。
Webkit层的HTML引擎拿到html文件之后,首先对文件进行标记化。由于数据在网络中传输只能是0、1的形式,虽然数据经过主机处理,会被转化为一系列的字符串,但这些字符串并不能直接操作。引擎需要先将这些字符一个个读取出来,转换为html标记。比如有一段字符串是这样的:
"<p>123</p>"
html引擎会把这个字符串提取出来,识别为一个HTML标记,用于后续构建DOM树使用。
将一个标签标记化后,HTML引擎就会将其挂到一棵DOM树上。这棵树有一个默认的根节点,就是Document节点。随后,引擎将从html标记开始添加,并将其作为根节点的唯一子节点。html节点下面会有head节点和body节点,这两个元素又将成为html节点的两个直接子元素。如对于下面的HTML页面:
<!DOCTYPE html>
<html>
<head>
<title>标题</title>
</head>
<body>
<p>123</p>
</body>
</html>
经过HTML引擎的处理,文件会被处理成下面的结构:
现在你可以通过JavaScript提供的DOM接口,来访问这棵树上的节点,执行相关DOM操作。
CSSOM树的构建
在构建DOM的过程中,我们可能会遇到一些特殊的标签,如<script>、<link>、<style>等,遇到script标签表示内部是一些JavaScript代码或一个外部脚本,这里放到后面再讲解。如果遇到<link>标签,那通常意味着这里会有一个外部的样式文件,浏览器将根据标签里写的路径,封装http请求,下载该文件。如果遇到<style>标签,说明里面写的是一些样式。这时候Webkit中的CSS引擎就会启动,开始构建CSSOM树。所谓的CSSOM树,其实就是一棵样式树,这棵样式树上挂载了大量的节点,用来描述body中每一个元素的样式(包括body自身)。
当我们对一个节点添加了多个同样的样式定义时,比如
<style>
p{
color:red;
}
p{
color: green;
}
</style>
这时候浏览器会以后面的样式为准,将段落的颜色设置为绿色。这也是样式最基本的覆盖规则。当然,样式的优先级规则相当复杂,这里我们简单总结如下:
样式优先级:浏览器默认 < 一般用户声明(外部css文件) < 一般作者声明(内部style标签定义的样式) < 内联样式 < 加了!important标记的声明。其中外部css样式与内部style定义的样式的优先级并不固定,这主要取决于哪个标签放在后面(通常我们会将<link>标签放在<style>前面,所以造成了上述规则,本质上还是哪个在后面哪个优先)。
此外优先级还需要考虑到选择器结构问题。这里我们只给出一种简单的计算方法,选择器中有一个id选择器,权重加100;有一个类名选择器,权重加10;有一个标签选择器,权重加1。一个选择器的权重越大,该选择器的优先级就越高。这里就不再举例了。
脚本的解析
实际上脚本的执行不属于DOM树和CSSOM树的构建过程,那为什么要放在这里来讲呢?
主要是因为JavaScript脚本具备直接操作DOM的能力!因此任何地方出现的脚本都有可能改变当前DOM树的结构。如下面的代码:
...
<body>
<div id="div">
<p>123</p>
</div>
<script>$("#div").remove()</script>
</body>
我们解析到div标签时,遇到了一段脚本,该脚本用于移除id为div的标签对象。如果我们在构建DOM树时不予执行,等到DOM树构建完毕再去执行脚本,js引擎需要操作的可能就是一棵有上千个节点的庞大DOM树,如果有许多这样的脚本,执行引擎就可能不堪重负。为了避免这种情况,浏览器会停止DOM树和CSSOM树的构建,将执行权限交给JavaScript引擎,等其执行完毕后才会继续进行构建。这样我们就可以在DOM树没那么庞大的时候及时进行处理。
注意:通常我们不会在首次构建DOM树的时候直接操作它,而且会将所有的脚本文件放在文档底部,这样浏览器可以不中断地进行DOM树和CSSOM树的构建(DOM树和CSSOM树是网页渲染的基础,它们的构建速度对网页的渲染速度影响甚大)。
通过上面的构建,我们得到了渲染页面需要的最基本“原料” - DOM树和CSSOM树,我们将用它们一步步合成最终的网页(注意,是一步步,也就是说还早着呢~)。下面我们先来看DOM树和CSSOM树是如何被Render进程使用的。
Render Object Tree/Render Layer Tree的构建
Render Object Tree
得到了上述的DOM树和CSSOM树后,我们就可以开始准备进行网页渲染过程了。首先,我们需要先从DOM树中把需要渲染到网页上的标签对象提取出来(显然,DOM树里的head标签是不需要渲染的,因为它只包含对网页的描述),然后从CSSOM树中提取标签对应的样式,构成一棵Render Object Tree。这棵树包含了所有需要渲染的DOM节点,以及这些节点的样式。浏览器将以这棵树为基础,进行网页的渲染。
Render Layer Tree
实际上仅仅有Render Object Tree我们还是无法完成网页的渲染。因为在css中我们有z-index的概念,还有相当多的特殊变换,如2D/3D变换。我们需要借助计算机图形处理中图层的概念,对这棵树进行一定的改造,才能渲染出这些特殊的样式(同样更是为了网页重绘时的性能考虑)。
为此,我们需要将Render Object Tree的各个元素进行图层化处理,得到一棵Render Layer Tree。之所以称为Layer(层) Tree,就是因为树中的每个节点都表示一个图层,它是浏览器进行渲染的最小单元。浏览器会将网页视为一层层覆盖的图层(如同PS中的图层),每个图层在渲染时是相互独立的,浏览器通过将这些图层进行合并,得到最终网页。当出现以下10中情况之一,Render进程就需要新建一个图层了:
- position不等于static;
- 设置了透明度、遮罩、滤镜或混合模式等;
- 设置有剪切路径;
- 有2D或3D转换(matrix、translate、scale、rotate、skew、perspective);
- 隐藏背面(backface-visibility:hidden);
- 设置有倒影(box-reflect);
- 设置有列宽和列数;
- z-index不等于auto;
- 设置了不透明度、变换或者动画等;
- 剪切移除内容(overflow:hidden)。
- 注意,Render进程并不会为Render Object Tree上的每个节点都创建一个图层,不属于上述10种情况的元素将与其父元素共用一个图层。
得到Render Layer Tree之后,我们离渲染出网页就更近一步了!
渲染过程
在得到Render Layer Tree后,我们已经具备了渲染网页的基本条件。我们只需要将该树上的每个图层渲染出来,经过合成,就可以得到最终的网页了。不过我们只是准备好了渲染网页所需的原材料,那么我们该如何让他们正确地显示在网页上呢?
我们需要借助Layer Compositing - 一种现代UI框架常见的渲染机制,它的基本原理就是先分别绘制每个图层,然后进行图层混合。它主要有三个任务:
- 确定哪些内容应该在哪些Composited Layer上绘制。执行完该步骤,我们会得到对Render Layer Tree的新描述 - Graphics Layer Tree,它的每一个节点仍然是一个图层,但是可以被直接绘制出来。
- 绘制每一个Composited Layer。现在我们真正把每个图层都绘制出来了!
- 将绘制好的每个Composited Layer输出到一个图形缓冲区中,设置每个图层的渲染顺序,这个图形缓冲区中的内容就是最终要绘制到页面上的网页!
最终,Chromium的CC模块从图形缓冲区中取出数据,绘制整个页面,网页就呈现在了你的面前!
后续 - 网页的重绘和重排
页面绘制出来后,事情并没有结束。因为我们的脚本可能随时会响应用户操作来更新页面,那么页面是如何更新的呢?
先从重绘说起,如果一个页面元素只是出现了样式上的变化(比如颜色变为了黑色),而它的位置和尺寸没有发生变化,那么显然我们不需要重新绘制整个页面(因为它对周围元素没有造成任何影响)。由于我们的绘制是以图层为基本元素的,所以我们需要重新绘制该元素所在的图层,那么要实现这个目的,我们需要做哪些事呢?
我们需要从CSSOM树开始更新。首先将CSSOM树上该节点的颜色替换为新的值,然后去Render Object Tree上更新节点样式。后面就是按照之前的步骤,重新生成和绘制该图层。最后将该图层输出到图形缓冲区即可。注意,这里我们完全没有处理该图层以外的其他图层。
对于重排(也叫回流),浏览器的工作量就会比较大了。触发重排的原因可能是我们改变了一个元素的尺寸,或者直接增加或删除了一个元素(这时候我们甚至还需要修改DOM树),某些情况下当前页面上每个图层的位置都会发生改变(这与元素所在的位置有关,也有可能受影响的只是它自己)。浏览器就需要对受影响的其他元素进行重新定位和渲染,这会严重消耗网页的性能。所以我们需要尽量避免网页的重排。
总结
实际的浏览器运行机制远比本文的描述复杂得多,由于技术能力有限,这里就没办法展开讲解了。如有兴趣,可以参考下面的链接,里面是罗升阳老师对浏览器运行机制更加详细的讲解(本文有相当多的内容参考自该系列文章)。最后感谢罗老师的精彩讲解!
参考资料
Chromium网页加载过程简要介绍和学习计划
Chromium的Render进程启动过程分析
Chromium网页Frame Tree创建过程分析
Chromium网页URL加载过程分析
Chromium网页DOM Tree创建过程分析
Chromium网页Render Object Tree创建过程分析
Chromium网页Render Layer Tree创建过程分析
Chromium网页Graphics Layer Tree创建过程分析
Chromium硬件加速渲染的OpenGL上下文绘图表面创建过程分析
作者:刘杰
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者