


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
0x1 背景
随着应用越来越多,每天大量的代码变更会带来很多潜在的安全风险,如果这些风险没有被挖掘出来带病上线,那我们暴露出去的风险就会越来越多,如何在代码变更后及时的感知到这些风险成为非常重要的事情,只有及时的感知,才能确保风险能得到检测和确认,而目前我们尚没有这样的机制来确保代码变更产生风险时第一时间展示出来并布置更多的跟进处理措施,这样就会不断的有新的风险暴露出去。
0x2 及时全面
当src又又收到外部白帽子提交的漏洞时,复盘大会上我们该怎么说呢?
这个功能点/api不知道啥时候上线的
这个功能点当时测试的没问题啊(测试case、测试流量都在呢,那这个为什么没测试到?每个请求对应测试的是哪个类型的漏洞)
这个漏洞修复了啊,代码不知道啥时候回滚了,orz
这个当时活太多没来得及测,orz
自动化工具没有覆盖这个漏洞的检测能力(那么我们的自动化检测工具提供了哪些测试能力能列出来吗,这块的检测能力有改进空间吗?)
以上回复基本都是因为没测到、没来的及测,总结下就是两个很关键的点没有得到保障
测试覆盖度
测试时效性
综上,当应用更新时只有及时全面的进行安全测试才能确保应用是相对安全的,那么及时和全面就分别对应测试时效性和测试覆盖度
0x201 测试覆盖度
先说下测试覆盖度,安全测试和业务(质量)测试(QUALITY ASSURANCE)同学的工作性质有点类似,如果有个功能点或者api没测试到根据墨菲定律这个点就很容易会出现问题,那么如何避免这个问题呢,那就是需要有平台有数据来量化测试覆盖度,这个平台有多少api,测试了多少,测试了多少不同类型的case,测试覆盖度依赖于以上数据。
0x202 测试时效性
如果每次研发同学发布了新的代码,安全同学如果都是一年以后来检查这些代码有没有新的风险那安全检测的意义好像就变低了,当然现实中是不可避免的人力不足,比如一个安全同学负责成百上千个应用的安全,如果没有好用的自动化工具那么安全同学其实是很难应付的过来,安全测试的时效性就很难保障,目前集团有非常棒的扫描平台来支持我们做白盒扫描/黑盒扫描,同时目前iast模式的灰盒测试也在推广中了,这些都是非常棒的实践。
0x3 风险度量
度量的目的是让我们能够清楚的知道我们的工作重点应该在哪里,不能为了度量而度量,度量或者分析后面应该跟进很多安全动作,比如新增了接口就需要及时的进行安全测试,这样就能确保每个新增api及时的得到安全测试,这样就能覆盖全部的api,同时保证了时效性。要确保覆盖度,最重要的一点就是我们需要知道我们的分子、分母分别是什么。不同的应用对外提供服务的方式不一样,基于目前B/S、C/S架构来讲,目前绝大多数风险在S端对应的后端应用上,目前对公网开放应用绝大多数还是通过rest-api的方式提供服务,后端服务除了api还有大量的rpc接口,目前来看webx、springboot、nodejs等框架类应用普及率越来越高,那么我们就拿webx为例来分享下如何做到应用风险可见,那我们思考下,一个应用在merge代码的时候可能会带来哪些安全问题,针对使用最多的java应用,我总结了两点
1 更新了pom文件,引入/消除了新的存在问题的二/三方组件
2 api或者api代码调用链发生了变化
理论上只要我们分析出以上两个变更就可以非常清楚的知道一次commit到底会不会带来新的风险,对于一些特殊场景,比如api下线,不仅仅意味着风险的消亡,同样意味着我们需要去更新我们的资产库标记相应的api已下线。
0x301 覆盖率中的变化的分母
要确保一个应用中的api/rpc接口全部得到测试,我们就需要获取到一个应用中包含的全部api/rpc接口,这是我们计算测试覆盖度的分母,而且随着应用代码的迭代这个分母是变化的,这个分母的变化就会带来风险。
pom里更新组件带来的问题目前基于漏洞库已经基本上覆盖掉了,那我们说下第二点 api层面的变更和api调用链的变化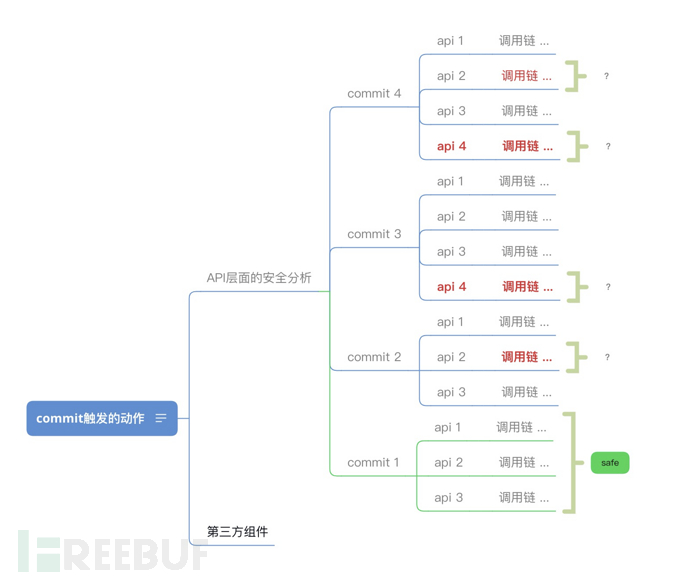
从上图我们举个栗子来讲,先从commit1和commit2来讲下,假设commit1的时候我们通过自动化、人工确认应用是相对安全的了,那我们标记应用当前的状态是 safe,当监控到应用有merge时,也就是应用处于commit2状态时我们通过自动化分析发现api还是3个,但是api2的调用链上某个方法发生了变化,这时候我们就需要标注出当前应用因为代码更新新增的风险是 api2的调用链上某个方法发生变更了,这时候就需要我们去确认是否有新增风险。
再比如commit2到commit3 ,新增了一个api4,这时候 新增的这个api4 就是需要我们去关注的风险。
按照上面的逻辑,我们应该可以把新增的风险梳理出来,主要是防止新增风险慢慢变成存量风险,不积硅步无以至千里,哎,好像不大应景。。。
就像前面说的一个应用对外提供服务基本就两种方式,一个是rest-api,一个是rpc接口,也就是对一个应用而言除去运行环境下,暴露的攻击面就是各种接口了, 这就是一个应用全部的分母,也就是我们保护的对象。
想要梳理一个应用包含哪些api/rpc接口方法有很多,基于流量、AST分析、插桩、swagger插件都是可以的,从源码层面分析最简单的应该是基于AST来获取,针对常规的springboot项目或者pandoraboot项目,通过AST很容易分析出其中的api变化,当然如果做的精致一些可以基于源码输出类似swagger组件输出一样的数据,接口、入参名、入参类型、返回类型、返回如果是一个对象、对象的属性有哪些,这些信息对安全测试而言同样都是非常有用的信息。
0x302 谁来保证分子
要想保证分子是更加接近分母就需要思考以下问题,
这个应用有多少api?(资产库)
这些api测试了吗?
2.1 谁测试的?
2.2 什么时候测试的?
2.3 测试时候的代码和现在的代码一样吗?也就是现在的api还是当时的api吗?不会更新了吧?不会回滚了吧?
2.4 测试记录还在吗?(怎么证明你测了!!!)
2.5 测试了哪些姿势?(这么敏感的接口居然没测试过越权?自动化工具不支持?)代码更新以后风险能感知到吗?
感知到以后需要哪些能力支持我们去自动化确认这些风险?黑盒、白盒、人工、iast
当前最实际的问题是线上运行的成千上万的应用中包含的漏洞该怎么挖掘出来,同时怎么防止新增风险变成存量风险。这两个问题中更重要的应该是怎么防止新增风险变成存量风险,否则我们就会陷入一直在处理存量风险的困境。那么让新增风险可见就变成了一个非常紧急且重要的事情。要实现风险可见需要几个关键点。
风险可见的关键点:
自动化分析是否有新增api
自动化分析原有api调用链以及调用链上各个方法是否有变更
而要实现第二点就需要把每个api对应的调用链和调用链上的各个方法统一存储进来方便进行比对。
0x4 新增风险分析实践
此图为在猿辅导打工时团队产出的脑图(手动感谢andr01la、l4yn3liu、T00ls01)
基于上图拿内部某个应用进行实践,通过实践我们可以输出代码变更时是否有新的api产生,是否有api对应的调用链的变化
0x401 基于ast分析api/rpc接口
0x40101 rest-api
使用AST梳理api可以根据类或者方法注解进行查找,最常见的注解为以下几类
a. @Controller
b. @RestController
c. @ResourceMapping
e. servlet-mapping方式映射url和java类
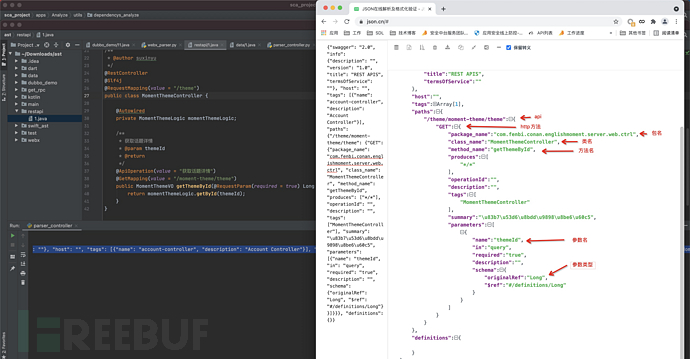
比如针对以下代码通过分析注解也可以获取到类似swagger的数据输出
package com.xxx.xxxx.xxxx.server.web.ctrl;
import ... ...;
@RestController
@Slf4j
@RequestMapping(value = "/theme")
public class MomentThemeController {
@Autowired
private MomentThemeLogic momentThemeLogic;
/**
* 获取话题详情
* @param themeId
* @return
*/
@ApiOperation(value = "获取话题详情")
@GetMapping(value = "/moment-theme/theme")
public MomentThemeVO getThemeById(@RequestParam(required = true) Long themeId) {
return momentThemeLogic.getById(themeId);
}
}
0x40102 hsf/dubbo
同样的道理hsf/dubbo接口也可以使用ast分析获取到,此处就不举例子了
0x402 调用链关系获取
条条大路通罗马,获取调用链的方式有很多种,现在我用codeql简单的拿某个api演示下获取调用链以后可以做哪些事情
从某个api开始分析
@Verify
@RequestMapping(value = "/contract/buy/quxxxxyxeail.json",
produces = MediaType.APPLICATION_JSON_UTF8_VALUE)
public Object queryInfoByEmail(HttpServletRequest request, HttpServletResponse response) throws
TradeCreateaException {
ContractCaontext contraactContext = ContractContaextUtil.buildaContractContext(request);
TradxxeContractPartixxcipantDto retVal= queryxxxxmail.execute(contractContext);
ContraxactContextUtil.outputContractResp(request, contractContext);
return retVal;
}
/contract/buy/queryInfoByEmail.json对应的入口方法是queryInfoByEmail,从该方法做为开始我们通过codeQL获取其调用链上的各个方法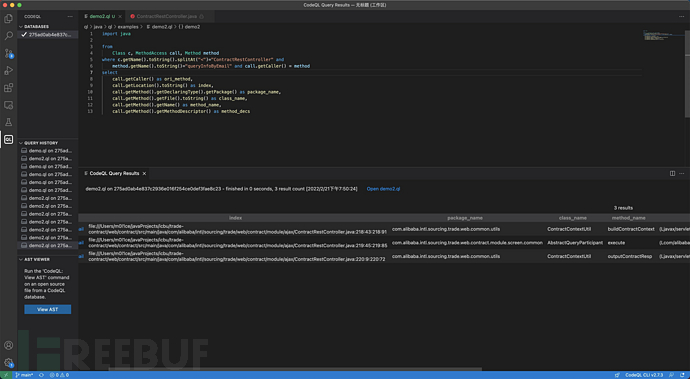
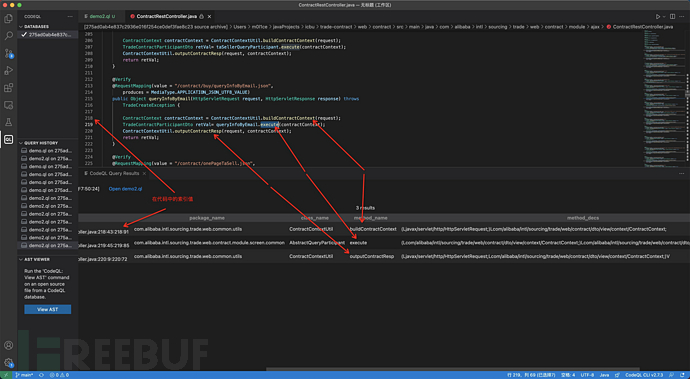
以上我们通过批量、递归操作就可以获取到一个api对应的入口方法开始其中调用链上的各个方法和在代码中的索引值,知道了索引值也就可以从源码中获取到每个方法的代码块和调用位置,就可以获取到类似以下的信息
如此就可以获取到某个应用某个commitid下api对应的调用链信息和每个方法的具体代码了,当应用被更新时,重新执行以上流程就可以获取到在新的commitid下api信息以及调用链信息,对信息进行比对就可以获取到差异,而风险就存在于变化之中。
0x403 产品化
以上我们可以获取到api以及api调用上的变化,那么这些变化就是需要确认的风险点,通过产品或者平台将这些信息展示出来我们就可以很直观的看到风险点,下一步就是确认这些风险是否是需要进一步处理的,最原始的方法就是人工确认,最起码这就有了一个可以做动作的入口。同时如果通过自动化手段可以把api、api调用链变化信息、调用链中每个方法的源码、api测试样例都能在一套平台里展示出来,那都将极大的提升审查漏洞、复核漏洞的效率。
0x5 需要的能力
0x501 API发现能力
一部分通过AST解析获取代码中的api,另一部分来自于流量清洗获取。 这两种方式各有优劣,ast准确率高但是缺少请求样例,流量中解析需要做归一化处理,如果处理不好一个应用下就变成了有十几万API,优势就是有请求样例(request、response),如果ast和流量解析出来的请求能统一起来,那么我们就可以获取到指定应用下有多少api、api入口类和方法、请求样例、对应的响应样例,这样一个应用下基础信息就有了。后续每个api会透出什么信息、是哪类敏感信息就都可以做了。
0x502 检测能力量化
不管是所谓的大厂还是小厂,真正接触过后才知道很多应用其实是根本没有做过安全测试的,有些是没有流量触发不了扫描,有些是post接口担心影响业务不敢扫,假如有了前面的api列表信息,并且黑盒能够标注哪些做过检测了,检测的漏洞类型是什么都记录下来,那么我们就可以很清晰的知道咱们应用哪些漏洞类型还没有做检测,没有做的检测就需要我们黑白盒、安全运营工程师一起努力来打造、提升检测能力;另一方面外部提交漏洞时也可以快速的复盘知道这个api我们内部到底有没有测试到这个api、何时、何人测试的。
0x503 接口变更感知能力
前面同样铺垫过了,所有的变化都是需要能被感知到的,并且需要有能力检测到哪些变更会带来风险,带来的风险需要谁去判断是否真正存在漏洞,谁来卡点?是统一在一个平台比如soc处理,还是需要安全工程师来回切换,比如接口是mtop发布然后就需要去mtop看接口信息、看入参、出参?
是不是可以根据过往数据来分析呢?比如新增了一个api返回的数据类型和另一个已发布接口的数据类型是一样的,比如都是某个Order类型的对象,那是不是就可以作为参考呢?
0x6 总结
以上是最近在安全运营工作中在遇到一些迷惑之处的思考,大佬们有其他意见和建议也可以在下方留言或者wx(m0l1ce)
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者