


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
1、基础理论介绍
1.1、数据库类型
数据库现在比较常见,很多企业都会使用数据库来管理存储数据,常见的数据库划分类型有,关系型数据库和非关系型数据库;
关系型数据库
采用了关系模型来组织数据的数据库,简单来说,关系模型就是二维表格模型,而一个关系型数据库就是由二维表及其之间的练习所组成的一个数据组织;
非关系型数据库
指非关系型的,分布式的,且一般不保证遵循ACID原则的数据库存储系统,以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,不局限于固定的结构,可以减少一些实践和空间来开销,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合;
1.2、常用的关系型数据库
MySQL是由瑞典MySQL AB公司开发,目前属于Oracle旗下的产品,是目前应用最广泛的开源关系数据库;
SQL Server 2000年12月微软发布了SQL Server 2000,该软件可以运行于
Windows NT/2000/xp等多种操作系统之上,是支持客户机/服务器结构的数据库管理系统,它可以帮助各种规模的企业管理数据;Access这款数据库是由微软发布的,通常利用ASP技术在IIS上运行,但是由于Access是小型数据库,在很多的使用上都有着局限性;
Oracle 是1983年推出的世界上第一个开放式商品化关系型数据库管理系统,它采用标准的SQL结构化查询语句,支持多种数据类型,提供面向对象存储的数据支持,具有第四代语言开发工具,支持Unix,Windows NT等多种平台;
1.3、常用的非关系型数据库
Redis 是一个开源的键值存储,支持主从式复制,事务,Pub/Sub,Lua脚本;
Memcached一个开源,高新能,分布式内存缓存系统,旨在通过减少数据库负载来加速动态web应用程序;
MongDB 是一个面向文档的开源NoSQL数据库,MongoDB使用JSON之类的文档来存储任何数据;
Hbase 是谷歌为Big Table数据库设计的分布式非关系数据库;
1.4、二者的区别与练习
关系型数据库最大的优点就是事务的一致性,这个特性,使得关系型数据库中可以适用于一切要求一致性比较高的系统中,比如:银行系统;
关系型数据库为了维护一致性所付出的巨大的代价就是读写性能比较差,对于并发读写能力要求极高的应用,关系型数据库无法应付,所以必须用一种新的数据结构存储来替代关系型数据库;
非关系型数据库无事务处理,没有保证数据的完整性和安全性,合适处理海量数据,但是不一定安全;
2、基础环境搭建
2.1、MySQL数据库的搭建
1)快速启动mysql数据库
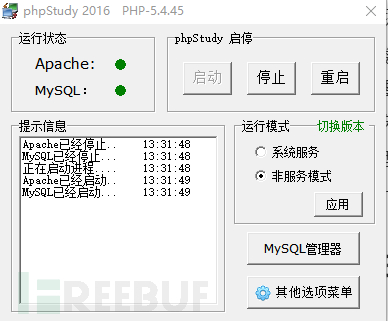
phpstudy是一个php调式环境的程序集成包,PHP+Mysql+Apache,phpstudy已经集成好了各种版本的mysql和php多个版本,非常方便;
完成下载后,直接选择好版本,直接启动;
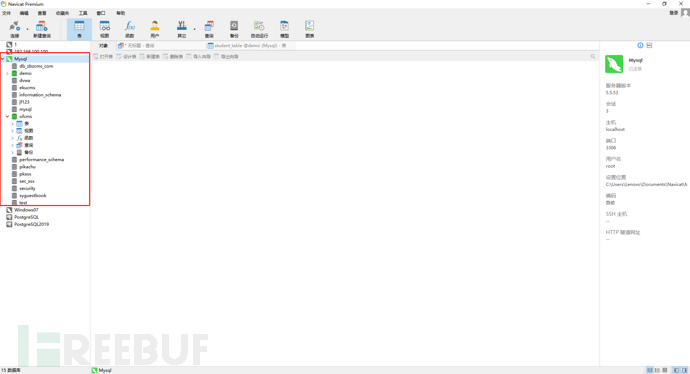
2)使用navicat连接mysql服务后可进行相关操作,连接成功后,打开数据库,可以打开数据表,也可以执行相关的SQL命令;
2.2、MySQL数据库配置
按照步骤来,就可以成功安装MySQL数据库;
MySQL允许远程连接
mysql>GRANT ALL PRIVILEGES ON .TO ‘root’@‘%’ IDENTIFIED BY‘密码’ WITH GRANT OPTION; mysql>flush privileges
MySQL开启日志记录,找到MySQL的配置文件my.ini,在[Mysqld]中port参数下方添加一行记录:
log=”C:/ENV/PHPstudy/PHPTutorial/MySQL/data/mysql50_log.txt”保存后重启数据库,此时会在指定的路径下新增一个日志文件;
3、在线SQL练习平台
3.1、SQL Fiddle
http://sqlfiddle.com/,SQL Fiddle支持MySQL,SQL Server,SQLite等主流的SQL引擎,在这里可以选择练习的数据库及其版本号;
3.2、SQLZOO
https://sqlzoo.net/,SQLZOO包括了SQL学习的教程和参考资料,支持SQL Server,Oracle,MySQL,DB2,PostgreSQL等多个数据库引擎;
3.3、SQL Bolt
https://sqlbolt.com/SQLBolt 是一个适合小白学习 SQL 的网站,这里由浅及深的介绍了 SQL 的知识,每一个章节是一组相关的 SQL 知识点,且配备着相应的练习;
4、SQL语法学习
SQL(Structured Query Language:结构化查询语言)用于管理关系数据库管理系统(RDBMS),可以访问和处理数据库,包括数据库插入,查询,更新和删除;
提示:SQL对大小写不敏感
分号:分号是在数据库系统中分割每条SQL语句的标准方法,这样可以在对服务器的相同请求中执行一条以上的语句;
4.1、SELECT查询
SELECT语句用于从数据库中选取数据;
语法格式:SELECT column_name FROM table_name;或SELECT * FROM table_name;
参考链接:https://www.runoob.com/sql/sql-select.html
4.2、WHERE语句
WHERE语句用于过滤记录;
语法格式:SELECT column_name FROM table_name WHERE column_name operrator calue;
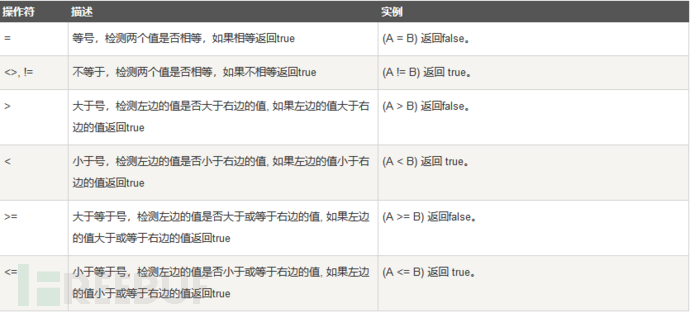
没有使用where之前的查询结果:select * from users;
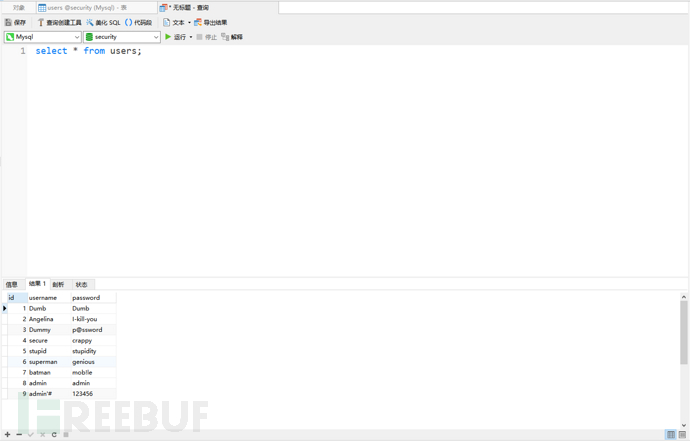
使用了where进行查询:select * from users where id = '1';
参考链接:https://www.runoob.com/mysql/mysql-where-clause.html
4.3、UNION联合查询
UNION用于合并两个或者多个SELECT语句的结果集,并消去表中任何重复行,UNION内部的SELECT语句必须拥有相同数量的列,列也必须拥有相似的数据类型,同时,每条SELECT语句中的列的顺序必须相同;
参考链接:https://www.runoob.com/sql/sql-union.html
4.4、ORDER BY关键字
ORDER BY关键字用于对结果集进行排序,默认按照升序进行排列,如果需要按照降序对记录进行排列。您可以使用DESC关键字;
语法结构:SELECT column_name FROM table_name ORDER BY column_name ASC|DESC;
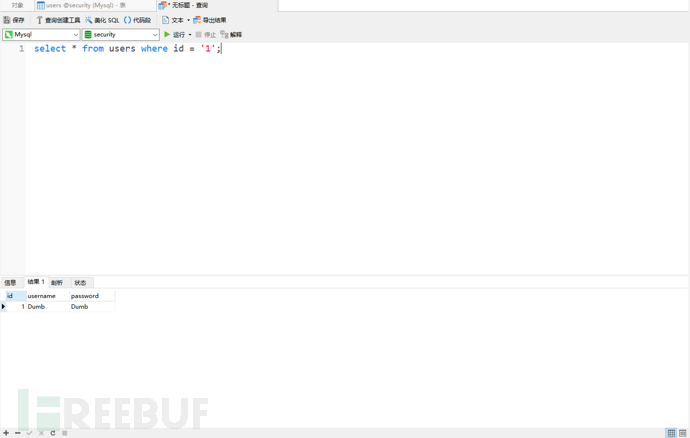
1)我们首先按照升序进行排列:SELECT * FROMusersORDER BY id ;
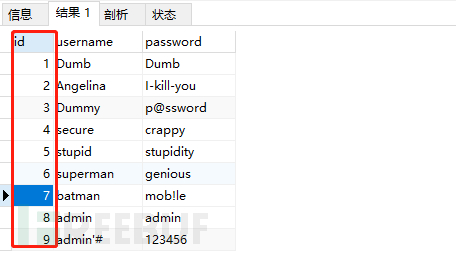
2)我们接下来按照降序排列:SELECT * FROMusersORDER BY id DESC;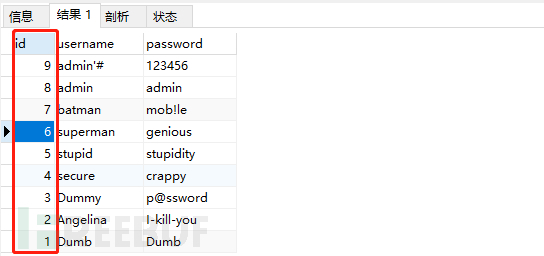
3)select * from student_table oeder by if(1=1,3,4);当表达式成立执行后者,不成立执行前者;
这里看的不是很清楚;
4)提示:if语句返回的是字符类型,不是整形;
select * from student_table order by if(1=1,student_age,student_tele);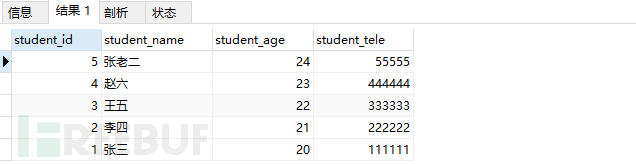
参考链接:https://www.runoob.com/sql/sql-orderby.html
4.5、like模糊查询
like操作符用于在where子句中搜索列中的指定模式,"%"符号用于在模式的前后定义通配符(默认是字母);
基本语法:select column_name(s) from table_name where column_name like pattern;
例如:select * FROM student_table where student_name LIKE '%张%';
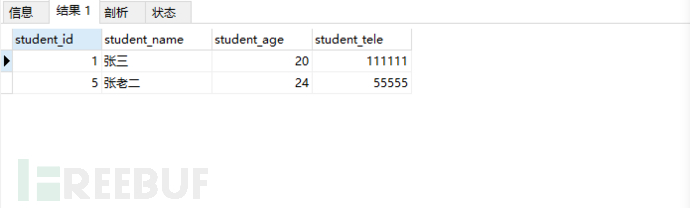
解读:在demo数据库中,student_table表中student_name字段模糊查找,带有张字的字段;
参考链接:https://www.runoob.com/mysql/mysql-like-clause.html
4.6、in关键字
in操作符通常来说在where子句中规定多个值;
语法格式:select cloumn_name(s) from table_name where column_name in(value1,value2...);
例如:选取student_id 为 "1"和"2"的所有信息:select * FROM student_table where student_id in(1,2);

参考链接:https://www.runoob.com/sql/sql-in.html
4.7、group by分组查询
group by 语句通常结合一些聚合函数来使用,根据一个或多个列对结果集进行分组;
常用的集合函数包括:
count()-计数
sum()-求和
avg()-平均数
max()-最大值
min()-最小值
参考链接:https://www.runoob.com/mysql/mysql-group-by-statement.html
4.8、数据库常见函数
1)聚焦函数
avg:返回指定字段的数据的平均值
count:返回指定字段的数据的行数(记录数量的)
max:返回指定字段的数据的最大值
min:返回指定字段的数据的最小值
sum:返回指定字段的数据之和
2)处理字符串的函数
合并字符串函数:concat(str1,str2,str3...)
比较字符串大小函数:strcmp(str1,str2)
获取字符串字节数函数:length(str)
获取字符串字符数函数:char_length(str)
字母大小写转换函数:大写:upper(x),ucase(x);小写lower(x),lcase(x)
字符串查找函数:find_in_set(str1,str2),field(str1,str2,str3...),locate(str1,str2),position(str1 in str2),nstr(str1,str2)
获取指定位置的字串:elt(index,str1,str2,str3....),left(str,n),rigth(str,n),substring(str,index,len)
字符串去空函数:ltrim(str),rtrim(str),trim()
字符串替换函数:insert(str1,index,len,str2),replace(str,str1,str2)
3)处理实践日期的函数
获取当前日期:curdate(),current_date()
获取当前时间:curtime(),current_time()
获取当前日期时间:now()
从日期中选择出月份数:month(date),monthname(date)
从日期中选择出周数:week(date)
从日期中选择出年数:year(date)
从时间中选择小时数:hour(time)
从时间中选择分钟数:minute(time)
从时间中选择出今天是周几:weekday(date),dayname(date)
4)处理数值函数
绝对值函数:abs(s)
向上取整函数:ceil(x)
向下取整函数:floor(x)
取模函数:mod(x,y)
随机数函数:rand()
四舍五入函数:round(x,y)
数值截取函数:truncate(x,y)
5)与安全相关的函数
获取当前用户:(1)select user(); (2)select current_user(); (3)select current_user; (4)select system_user(); (5)select session_user();
获取当前数据库:(1)select database(); (2)select schema();
获取所有数据库:select schema_name from information_schema.schemata;
获取服务器主机名:select @@HOSTNAME;
查询用户是否由读写权限:
SELECT grantee, is_grantable FROM information_schema.user_privileges WHERE privilege_type = ‘file’ AND grantee like ‘%username%’;
SELECT file_priv FROM mysql.user WHERE user = ‘root’;(需要root用户来执行)
注释:(1)单行注释:- (2)多行注释://
字符串截取:select substr('abc',2,1);
MySQL特有的写法:/!SQL语句/:这种格式里面的SQL语句可以被当成正常的语句执行,当版本号大于!后面的一串数据,SQL语句则执行;
空格被过滤编码绕过:
%20,%09,%0a,%0b,%0c,%0d,%a0 %a0UNION%a0select%a0NULLor,and绕过:or可以使用||代替,and可以使用&&代替;
union select 被过滤:(1) union(select(username)from(admin)); :union和select之间用(代替空格;
select 1 union all select username from admin; :union和select之间用all,还可以用distinct3;
select 1 union%a0select username from admin; :同样的道理%a0代替了空格;
select 1 union/!select/username from admin;
select 1 union/hello/username from admin; 注释代替空格;
关键字where被过滤使用limit来代替(limit被用于强制 SELECT 语句返回指定的记录数)
limit绕过:使用having函数(having:在聚合后对组记录进行筛选,类似于where作用,经常与grop by使用)
having函数绕过:group_concat():将相同的行组合起来
5、SQL注入漏洞
在输入的字符串中注入SQL语句,如果应用相信用户的输入而对输入的字符串没有做过滤处理,那么这些注入进去的SQL语句就会被数据库误认为是正常的SQL语句而被执行;
5.1、万能密码绕过
若输入:select * from admin where username='$username' and password='$password'若输入'or 1=1 #
则后端变成:select * from admin where username='' or 1=1 # 'and password='$ password'
5.2、常见的注入点
应用程序和数据交互的地方:
Authentication(认证页面)
Search Fields(搜索页面)
Post Fields(Post请求)
Get Fields(Get请求)
HTTP Header(HTTP头部)
Cookie
5.3、数据库特性
information_schema.schemata 存放所有数据库名,schema_name为数据库名字段
information_schema.tables 存放所有数据库的表名,table_schema存放数据库名, table_name字段存放表名
information_schema.columns 存放所有数据库表的所有列名,table_schema 库名, table_name表名,column_name列
6、SQL注入审计
执行对象是SQL的执行者,目前常用的执行对象接口有三种:Statement,PreparedStatement和CallableStatement;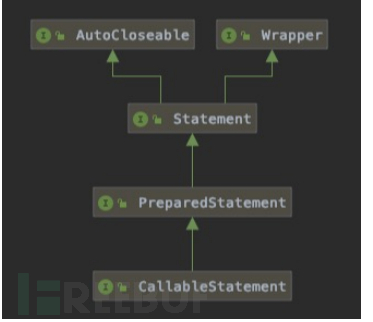
6.1、Statement
Statement主要用于执行静态SQL语句,即内容固定不变的SQL语句;
Statement每执行一次都要对传入的SQL语句编译一次,效率低下;
1)案例一:直接拼接变量;
staticvoidsearch1() {
Scannersc=newScanner(System.in);
Stringname=sc.nextLine();
// String name = "zhangsan";
StringsqlString="select * from student_table where student_name = '"+name+"'";
System.out.println(sqlString);
Connectionconn=Conn.open();
try
{
ResultSetrs=null;
Statementstmt=conn.createStatement();
rs=stmt.executeQuery(sqlString);
while(rs.next()){
System.out.println("student_id:"+rs.getInt("student_id") +"\t"
+"student_name:"+rs.getString("student_name") +"\t"
+"student_age:"+rs.getString("student_age") +"\t"
+"student_tele:"+rs.getString("student_tele") +"\t");
}
}catch(SQLExceptione) {
e.printStackTrace();
} finally{
Conn.close(conn);
}
}
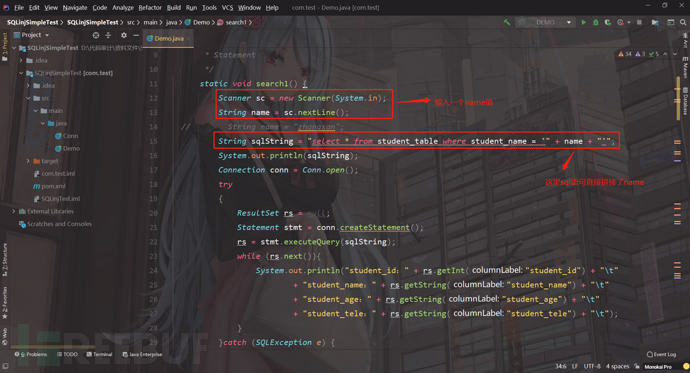
接下来运行打开search(),进行调试

我们首先打开数据库,看一看数据库的数据;
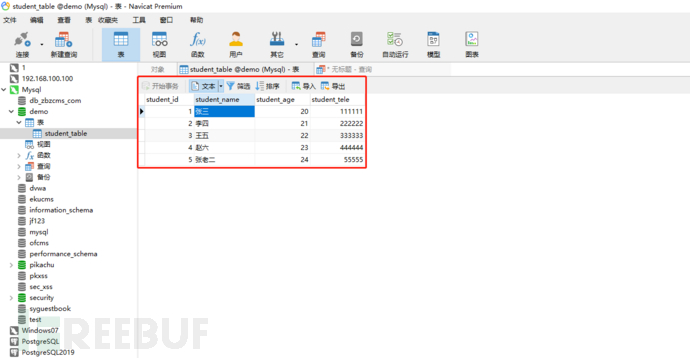
运行程序,正常情况下,我们对照数据库,输入张三,数据库帮我们查出张三的信息;
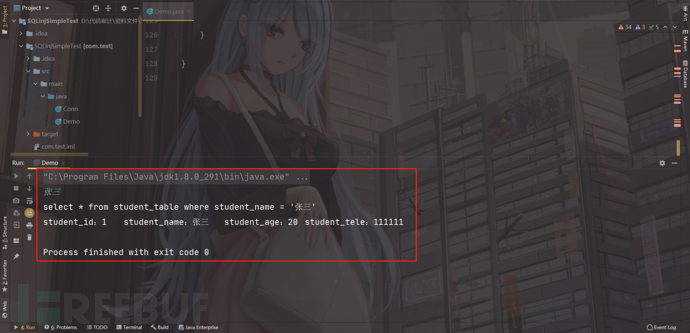
但是由于他使用了+进行拼接,我们输入' or 1=1 #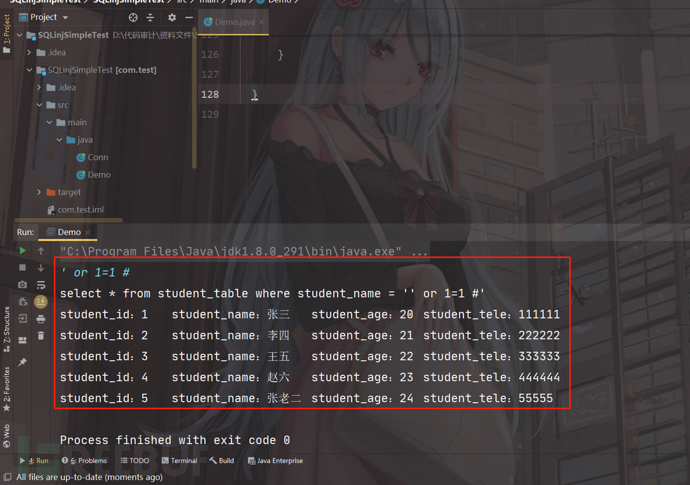
它查出来了全部的信息,这就说明存在SQL注入;
6.2、PreparedStatement(预编译)
1)案例二:PreparedStatement是预编译参数化查询执行SQL语句的方式;
代码如下:
staticvoidsearch2() {
Stringsql="select * from student_table where student_name = ?";
System.out.println("sql语句:"+sql);
Connectionconn=Conn.open();
try{
ResultSetrs=null;
PreparedStatementpstmt=(PreparedStatement) conn.prepareStatement(sql);
Scannersc=newScanner(System.in);
Stringname=sc.nextLine();
pstmt.setString(1, name);
// pstmt.setString(1, "tom");
rs=pstmt.executeQuery();
System.out.println(pstmt);
while(rs.next()) {
System.out.println("student_id:"+rs.getInt("student_id") +"\t"
+"student_name:"+rs.getString("student_name") +"\t"
+"student_age:"+rs.getString("student_age") +"\t"
+"student_tele:"+rs.getString("student_tele") +"\t");
}
} catch(SQLExceptione) {
e.printStackTrace();
} finally{
Conn.close(conn);
}
}
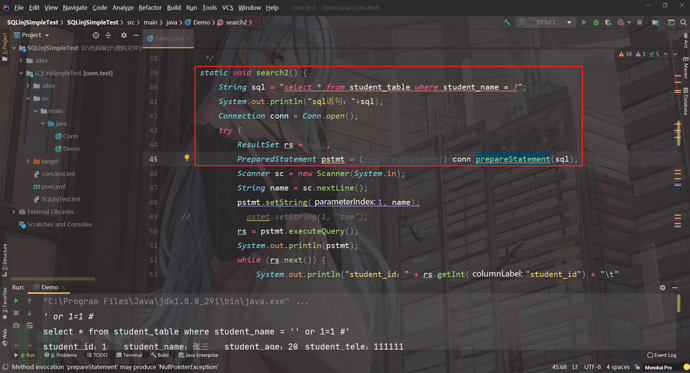
Stringsql="select * from student_table where name = ?"
Connectionconn=open();
PreparedStatementpstmt=(PreparedStatement) conn.prepareStatement(sql); //对占位符进行初始化
pstmt.setString(1, "tom"); pstmt.executeQuery();
正常情况下,输入张三进行查询:
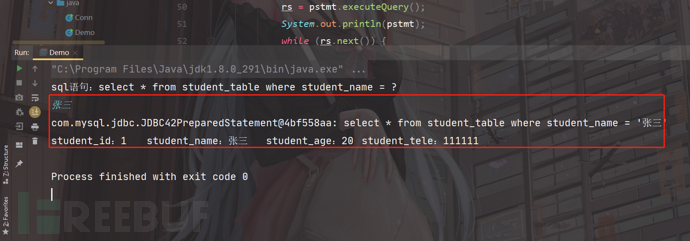
我们接着输入' or 1=1 #
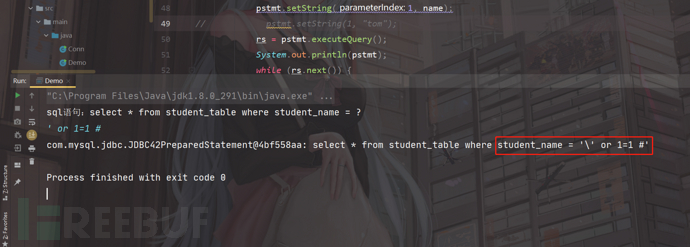
很明显可以看出来,这里有一个反斜杠,被转义了,使得不能正常执行语句;
6.3、like模糊匹配
代码如下:
staticvoidsearch3() {
Scannersc=newScanner(System.in);
Stringsql="select * from student_table where student_name like ";
Connectionconn=Conn.open();
try{
ResultSetrs=null;
Stringname=sc.nextLine();
System.out.println(sql);
PreparedStatementpstmt=(PreparedStatement) conn.prepareStatement(sql+"'%"+name+"%'");
rs=pstmt.executeQuery();
System.out.println(pstmt);
while(rs.next()) {
System.out.println("student_id:"+rs.getInt("student_id") +"\t"
+"student_name:"+rs.getString("student_name") +"\t"
+"student_age:"+rs.getString("student_age") +"\t"
+"student_tele:"+rs.getString("student_tele") +"\t");
}
} catch(SQLExceptione) {
e.printStackTrace();
} finally{
Conn.close(conn);
}
}
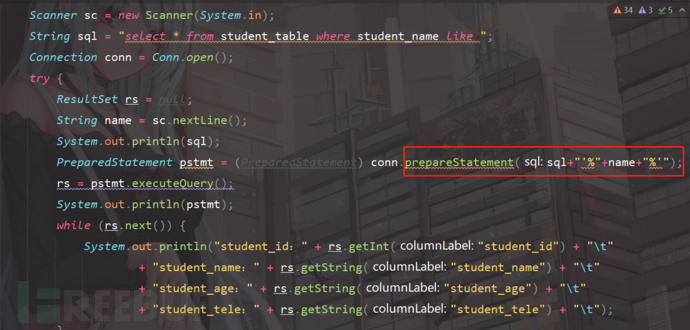
直接在预编译这里进行模糊匹配,输入"张",查看结果;
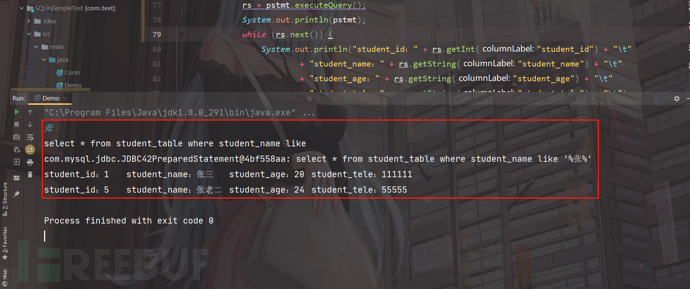
可以正常进行模糊匹配,并且可以看到,查询的结果正常;
不正常的情况,我们输入' or 1=1 #
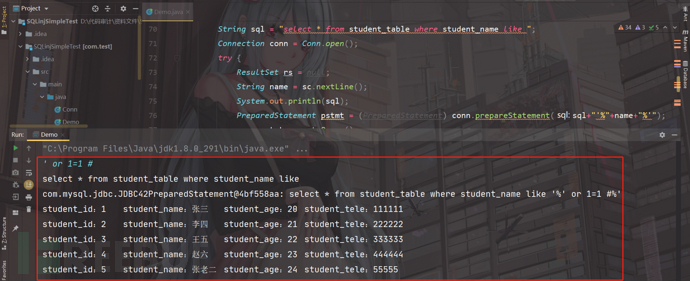
全部查询了出来,虽然这里使用了prepareStatement,但是在后面的括号里面做了,拼接(sql+"'%"+name+"%'"),预编译直接没有起到效果,直接导致存在SQL注入;
6.4、对like关键字进行预编译
代码如下:
staticvoidsearch4() {
Scannersc=newScanner(System.in);
Stringsql="select * from student_table where student_name like "+"'%"+"?"+"%'";
Connectionconn=Conn.open();
try{
ResultSetrs=null;
PreparedStatementpstmt=(PreparedStatement) conn.prepareStatement(sql);
Stringname=sc.nextLine();
pstmt.setString(1, name);
rs=pstmt.executeQuery();
System.out.println(pstmt);
while(rs.next()) {
System.out.println("student_id:"+rs.getInt("student_id") +"\t"
+"student_name:"+rs.getString("student_name") +"\t"
+"student_age:"+rs.getString("student_age") +"\t"
+"student_tele:"+rs.getString("student_tele") +"\t");
}
} catch(SQLExceptione) {
e.printStackTrace();
} finally{
Conn.close(conn);
}
}
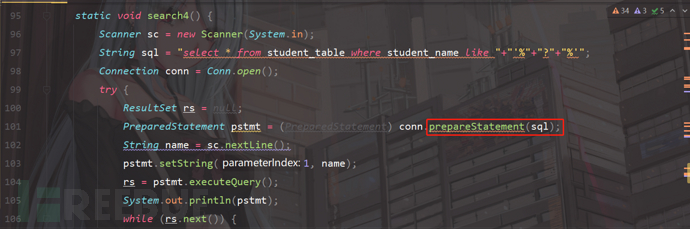
我们继续输入"张进行模糊匹配";
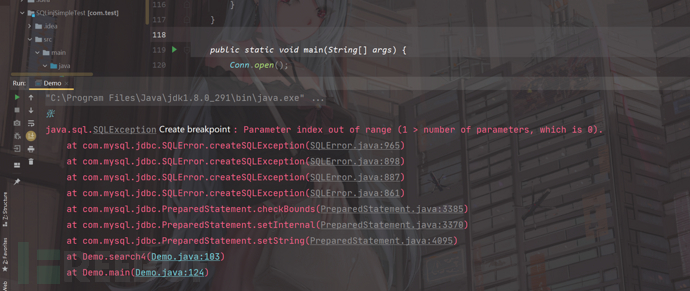
程序直接报错了;说明like关键字进行模糊匹配的时候,不能使用预编译,只能进行拼接;
7、MyBatis框架介绍
7.1、MyBatis了解
MyBatis是一款优秀的持久层框架,它支持定制化SQL,存储过程以及高级映射,MyBatis避免了几乎所有的JDBC代码和手动设置参数及其获取结果集,MyBatis可以使用简单的XML或者注解来配置和映射原生类型,接口Java和POJO (Plain Old Java Objects,普通老式Java对象)为数据库中的记录。
官方教程:https://mybatis.org/mybatis-3/zh/getting-started.html
7.2、MyBatis基本使用-基于xml实现
实现类Student各个参数与数据库中目标表的列名--对应,包括参数名,参数类型;
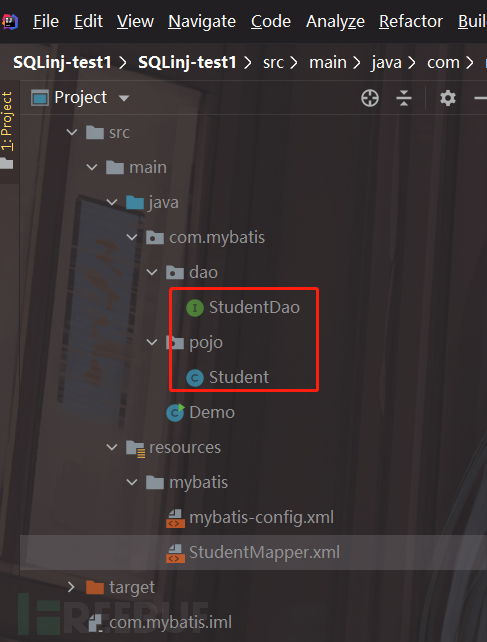
1)Dao接口文件:
packagecom.mybatis.dao;
importcom.mybatis.pojo.Student;
importorg.apache.ibatis.annotations.Param;
importjava.util.List;
publicinterfaceStudentDao{
publicList<Student>selectStudent(@Param("name")Stringname);
// public List selectStudent(@Param("list")List list);
}
2)Mapper xml SQL语句映射文件:
<?xmlversion="1.0"encoding="UTF-8"?>
<!DOCTYPEmapper
PUBLIC"-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mappernamespace="mybatis.dao.StudentDao">
<selectid="selectStudent"resultType="mybatis.pojo.Student">
select*fromstudent_tablewherestudent_name=#{name}
</select>
</mapper>
3)MyBatis xml 配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- <properties resource="config.properties"/>-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/Demo?useSSL=false" />
<property name="username" value="root" />
<property name="password" value="root" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mybatis/StudentMapper.xml"/>
</mappers>
</configuration>4)事务管理器(transactionManager)
5)数据源(dataSource)类型有三种:
UNPOOLED:这个数据源的实现只是每次被请求时打开和关闭连接,有点慢,但是对那些数据库连接可用性要求不高的简单应用程序来说,是一个很好的选择,POOLED:这种数据源的实现利用"池"的概念将JDBC连接对象组织起来,避免了创建新的连接实例时所必须的初始化和认证时间,JNDI:这个数据源的实现是为了能在如EJB或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个JNDI上下文的引用;
6)测试类
package com.mybatis; import com.mybatis.dao.StudentDao; import com.mybatis.pojo.Student; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import java.io.IOException; import java.io.InputStream; import java.util.ArrayList; import java.util.Collections; import java.util.List; public class Demo { /** * 从 XML 中构建 SqlSessionFactory,从中获得 SqlSession 的实例,通过 SqlSession 实例来直接执行已映射的 SQL 语句 * @throws IOException */ public static void xmlTest() throws IOException { //1. 读取配置文件 String resource = "mybatis/mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); //2. 创建SqlSessionFactory工厂 SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); //3. 使用SqlSessionFactory工厂生产SqlSession对象 SqlSession session = sqlSessionFactory.openSession(); try { //4. 使用SqlSession创建Dao接口的代理对象 StudentDao studentMapper = session.getMapper(StudentDao.class); //5. 使用代理对象执行方法 // List<Integer> list = new ArrayList<Integer>(); // list.add(1); // list.add(3); // List<Student> student = studentMapper.selectStudent(list); // List<Student> student = studentMapper.selectStudent("student_age"); // String name = "'' or 1 = 1 #"; String name = "'张三'"; List<Student> student = studentMapper.selectStudent(name); // List<Student> student = studentMapper.selectStudent("%' or 1=1#"); // List<Student> student = studentMapper.selectStudent("1,2,3"); for (Student s: student) { System.out.println(s); } } finally { session.close(); inputStream.close(); } } public static void main(String[] args) throws IOException { xmlTest(); } }
7.3、MyBatis注入问题
1)动态SQL
动态SQL是mybatis的主要特性之一,在mapper中定义的参数传到xml中之后,在查询之前mybatis会对其进行动态解析,Mybatis框架中,接收用户参数有两种方式:
通过$(param)方式
通过#(param)方式
#{ }会自动传入值加上单引号,而${ }不会;
2)我在这里将张三传入,name参数中;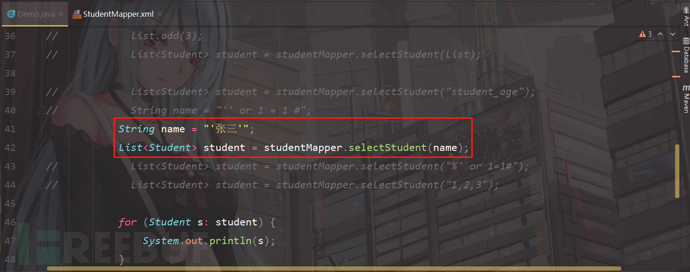
StudentMapper.xml
<selectid="selectStudent"resultType="com.mybatis.pojo.Student">
select*fromstudent_tablewherestudent_name=${name} orderbystudent_name
</select>

传入张三,正常查询;

我们传入'' or 1=1 #;
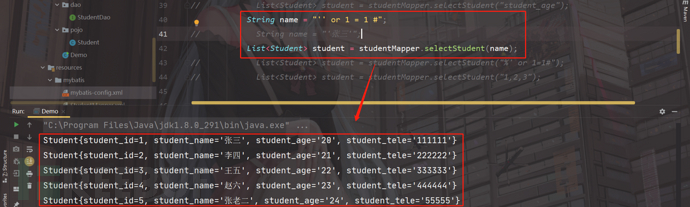
全部查出,产生了SQL注入;
3)对于含有sql关键字后边的变量不能直接使用预编译处理;
我们首先打开代码:
Stringname="'张三'";
List<Student>student=studentMapper.selectStudent(name);
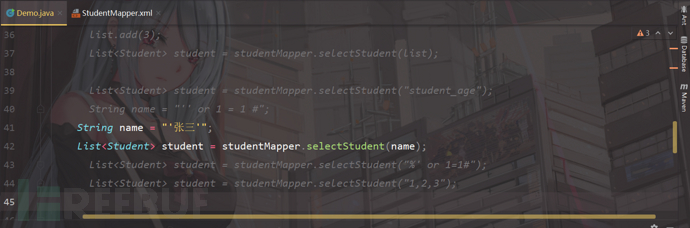
打开StudentMapper.xml
<!--对于含有sql关键字后边的变量不能直接使用预编译处理-->
<selectid="selectStudent"resultType="com.mybatis.pojo.Student">
select*fromstudent_tableorderby'#{name}'
</select>

运行后直接报错:
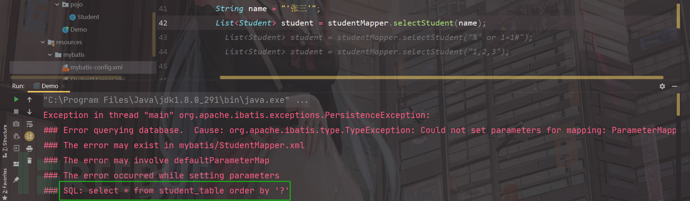
结论:对于含有sql关键字后面的变量不能直接使用预编译处理;
4)对于不含有sql关键字后边的变量能直接使用预编译处理
我们打开测试代码
String name = "张三"; List<Student> student = studentMapper.selectStudent(name);

我们接着打开StudentMapper.xml
<!--对于不含有sql关键字后边的变量能直接使用预编译处理-->
<select id="selectStudent" resultType="com.mybatis.pojo.Student">
select * from student_table where student_name = #{name}
</select>
正常查询,我们输入"张三",进行查询:
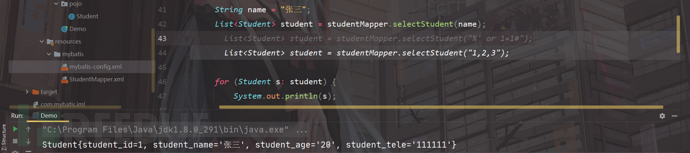
我们输入'' or 1=1 #,进行查询:
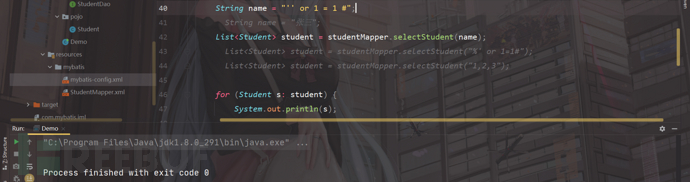
没有结果;
结论:对于不含有sql关键字后边的变量,我们直接可以使用预编译处理;
5)like 使用非预编译
打开测试代码:
Stringname="张三";
List<Student>student=studentMapper.selectStudent(name);

打开StudentMapper.xml下面代码
<selectid="selectStudent"resultType="com.mybatis.pojo.Student">
select*fromstudent_tablewherestudent_namelike'%${name}%'
</select>

我们传入"张",进行测试:
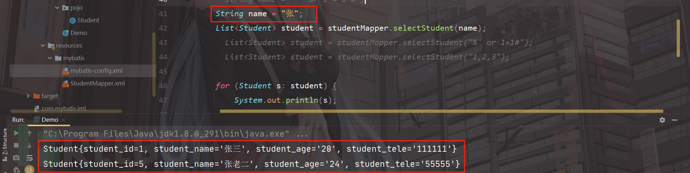
可以进行正常查询;
我们接着输入"%' or 1=1#";
看看执行结果;
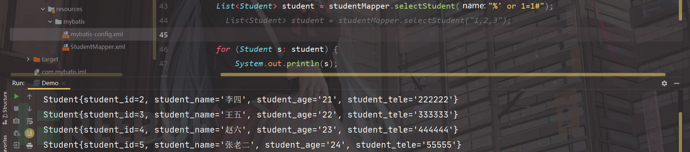
直接产生SQL注入;
6)like 直接按照常规手段预编译
打开StudentMapper.xml下面代码
<!--like直接按照常规手段预编译将导致程序不能执行-->
<selectid="selectStudent"resultType="com.mybatis.pojo.Student">
select*fromstudent_tablewherestudent_namelike'%#{name}%'
</select>

我们执行的时候,直接报错;
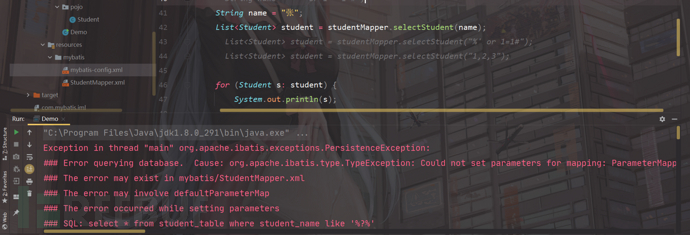
结论:like 直接按照常规手段预编译将导致程序不能执行;
7)like关键字预编译处理的唯一正确的手段
我们首先打开测试代码;
Stringname="张";
List<Student>student=studentMapper.selectStudent(name);

我们接着打开StudentMapper.xml
<selectid="selectStudent"resultType="com.mybatis.pojo.Student">
select*fromstudent_tablewherestudent_namelikeconcat('%',#{name}, '%')
</select>

我们输入"张",显示正常;
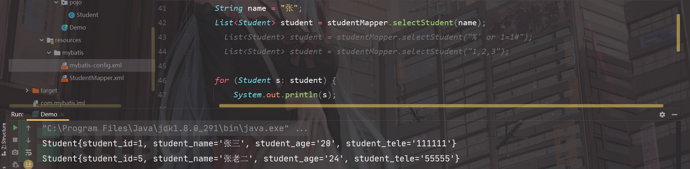
我们输入注入语句"%' or 1=1#",程序没执行出来东西;
8)in关键字未使用预编译:
我们首先打开测试代码:
List<Student>student=studentMapper.selectStudent("1,2,3");
接着我们打开StudentMapper.xml
<selectid="selectStudent"resultType="com.mybatis.pojo.Student">
select*fromstudent_tablewherestudent_idin(${name})
</select>

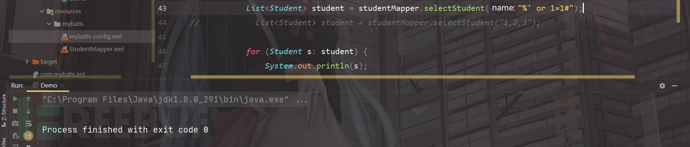
我们运行代码;
 显示正常;
显示正常;
9)in使用预编译
打开测试代码
List<Student> student = studentMapper.selectStudent("1,2,3");
接着我们打开StudentMapper.xml
<!--对于in 关键字的话,直接常规预编译手段将出现异常-->
<select id="selectStudent" resultType="com.mybatis.pojo.Student">
select * from student_table where student_id in (#{name})
</select>
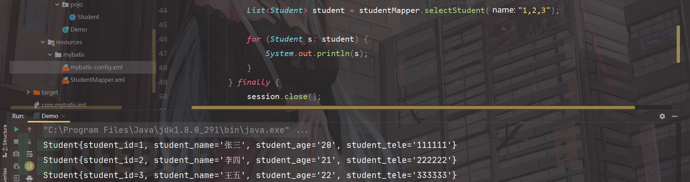
执行程序:
明显看出,我们这里执行的是1,2,3,但是这里只查询到了一条,说明出现了错误;
10)in关键字后变量预编译的合理手段
打开测试代码
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(3);
接着我们打开StudentMapper.xml
<select id="selectStudent" resultType="com.mybatis.pojo.Student">
select * from student_table where student_id in
<foreach collection="list" item="id" index="index" open="(" close=")" separator=",">
#{id}
</foreach>
</select>
我们这里应该传一个list集合,首先我们要更改StudentDao.java
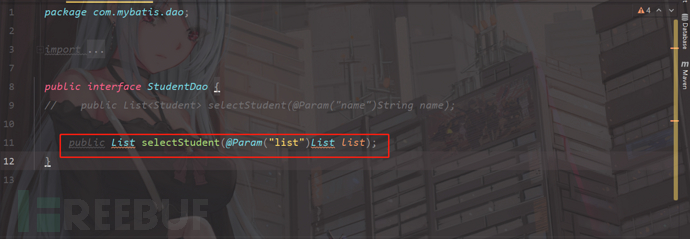
注释掉上面的,我们打开list集合;
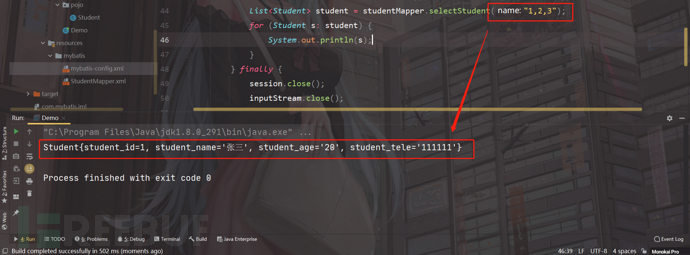
然后运行程序:
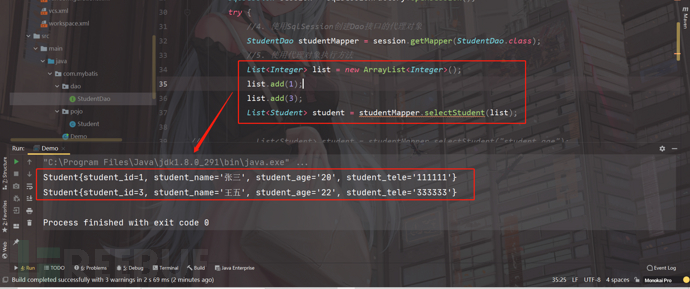
程序可以正常查询;
7.4、总结
容易产生SQL注入漏洞场景有:
1、Like模糊查询: Select * from student where name like ‘%${name}%'
2、in查询:Select * from news where id in (${id})
3、order by、group by 查询: select * from studentwhere id order by ${id}
8、综合案例讲解
8.1、漏洞审计技巧和思路
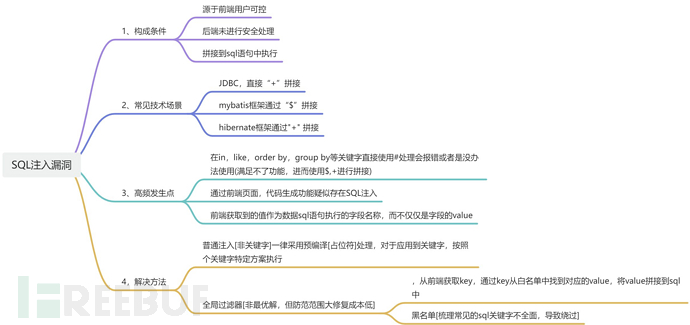
1、需要关注的点:来自于前端的参数且用户可控且未做安全处理直接拼接到SQL中执行;
2、发生场景:
在jdbc技术中直接使用“+”拼接
在mybatis中使用¥符号拼接
在hibernate中使用+
需要特别注意一下将从前端获取到的值作为数据sql语句执行的字段名称,而不仅仅是字段的value
String id = requrst.getParmtmter("id")
3、不常见的sql注入变现形式id= “id = 1”,select * from user where + id拼接之后,select * from user where id=1;假如id被黑客篡改id ‘,会导致注入风险;
4、常见的sql注入变现形式:select * from user where + id1 = $id;
解决方案:
对于必须从前端获取的,梳理一份白名单[key,value],从前端获得key,通过key从白名单中找到对应的value,将value拼接到sql中;
map = {id:id,id2:id,id3:id,id4:id,id5:id,id6:id}
String id = requrst.getParmtment("id")
假如用户在此位置上,注入了id="id’",发现id‘不在白名单的范围内,导致无法继续执行sql语句;
5、因程序员有一定的安全意思,项目中直接拼接比较少,但是在in,like,order by,group by等关键字如何直接使用#等预编译处理,会报错,所以不得不使用拼接,成为了注入的高发点;
6、通过前端页面,代码生成(SQL注入高频爆发点)功能疑似存在SQL注入;
7、定位到后端分析相关SQL的执行过程;
8.2、关于提出针对order by,group by白名单修复意见说明:
1、正常其后应该加的是字段,是因为第一这个字段来自于前端,第二使用了拼接,第三参数来自前端;
2、如果使用了#满足不了功能或者是报错,所以程序员不得已使用了拼接;
3、允许使用了拼接,但是需要通过白名单修复
一般情况下,传的字段并且固定,允许前端来的参数,但是不能直接拼接;
需要在后端匹配与其对应的value,用前端的参数作为key匹配value,最后将value拼接到参数中;
String name = request.getParemeter("name");
String value = map.getKey("name");
String sql = select * from user order by value;
假如,黑客在前端注入了sql脚本,会导致该key找不到value,那就是说没办法发生注入了,直接返回前端传入的参数不合法;
8.3、ofcms1.1.3SQL挖掘
1)第一步调试好环境,来到前端页面
http://localhost:8080/ofcms_admin_war/admin/login.html
后台->系统设置->代码生成->增加表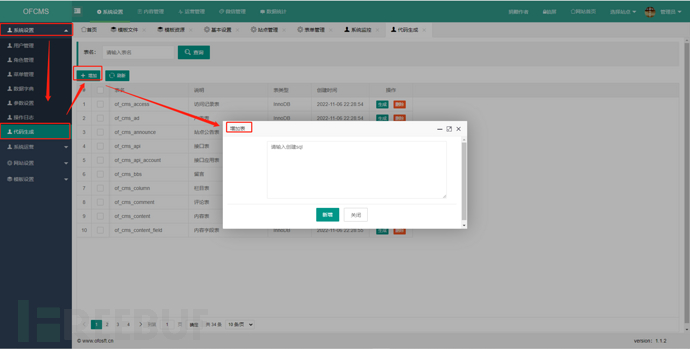
2)定位代码,首先我们点击Network,点击清空请求,我们来到有注入的地方,随便输入几个字母,看它请求的位置;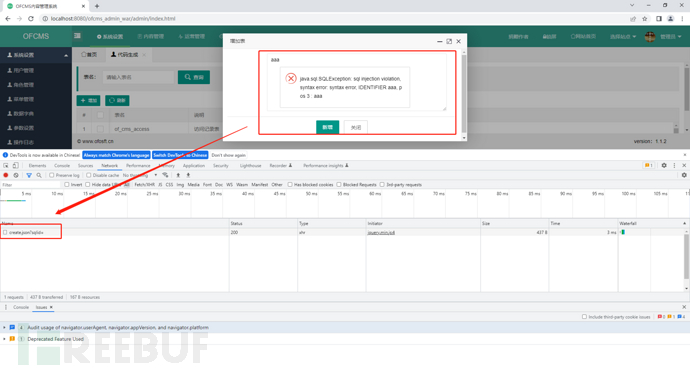
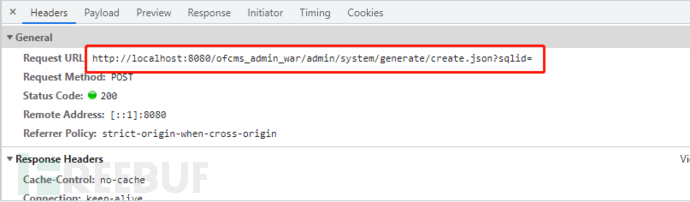
我们找到关键字:create,通过全局搜索(ctrl+shift+r),首先对 controller层对create关键字进行全面检索,找到create方法,调用了sql语句;
3)分析传参处理
在create方法中,先用了getPata()方法,获取用户的输入sql的值,我们多这个方法进行跟踪;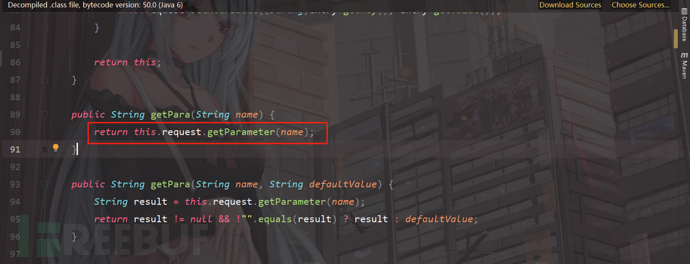
4)发现它来到了Controller.class,getPara方法,就是使用request.getParameter(name)
来获取http协议提交过来的数据,返回String类型的数据;
这里并没有对用户输入的内容进行过滤;
再看create方法,紧接着调用了Db.update(sql),方法执行输入的sql语句,跟进方法;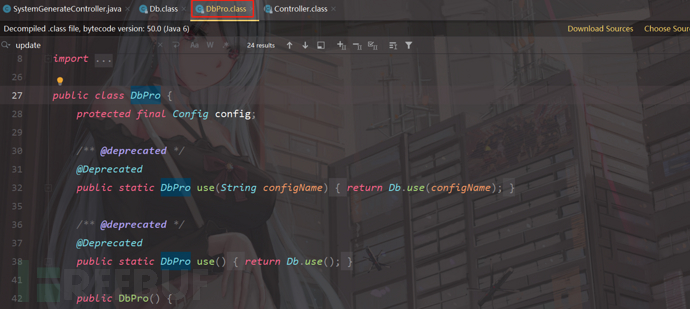 我们跟进到DbPro.class,这时候关键的代码来了,我们发现update这个方法执行了sql语句,接下来就要看它是使用的预编译还是做了拼接;
我们跟进到DbPro.class,这时候关键的代码来了,我们发现update这个方法执行了sql语句,接下来就要看它是使用的预编译还是做了拼接;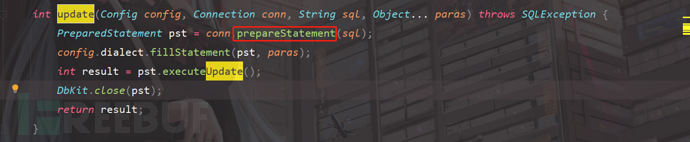
我们看到,这里确实看到了预编译的关键字,使用了预编译,但是我们可以直接输入整条sql语句执行,预编译形同虚设,这里没有使用占位符,所以预编译起不到任何作用;
5)payload
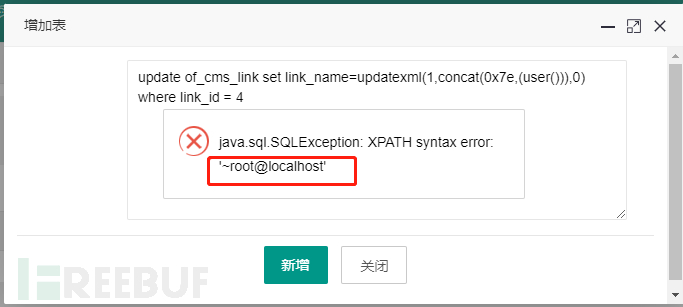
update of_cms_link set link_name=updatexml(1,concat(0x7e,(user())),0) where link_id = 4
6)前端效果
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者