


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
定义
序列化:为了数据的传输,将数据从对象或其他数据结构转为字节流的一个过程;
反序列化:把数据从字节流还原成其原有数据结构的一个过程;
我所理解的网络数据传输是这样的:规定一种数据交换的规则,按其规则将对象转为相应格式后进行传输;当然转换后的数据一般是字节流的形式,因为系统底层其只认识字节流。
就好比 zip、jpg、bmp,系统打开相应格式的文件时为何可以正确打开?因为在系统面前它面对的永远是这些文件的字节流,不同的文件某段字节流都有着不同的含义,每种格式都有其相应的读/写规范。
同理,数据的传输也是如此,不同的数据交换协议对应不同的读/写格式,于是序列化数据也衍生出了多种方式:
xml
yaml
json
Jackson
FastJson
各语言自带的序列化/反序列化
Java 提供的序列化接口-Serializable
...
Protobuf(没用过,暂不太了解)
...
本文的重点在 Java 自带的序列化/反序列化,所以对于其他方式暂时不会太多提及。
应用场景
常见的使用场景:
远程/进程间数据传输(有线协议、web services、不同系统/进程之间通信;如 rmi )
缓存/持久化(数据库、缓存服务器、文件系统、程序未来数据通信)
Tokens(API 认证 tokens 等,如 shiro 的 Remenberme)
一个简单的示例
序列化由 ObjectOutputStream.writeObject(object) 进行,反序列化由 ObjectInputStream.readObject() 进行。
序列化
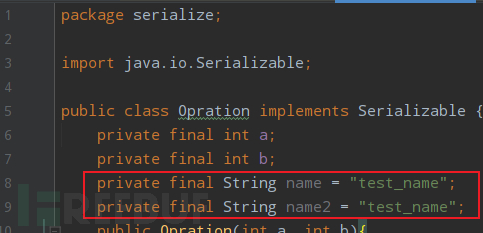
1、待序列化的类Opration。需要实现Serializable或Externalizable接口,否则无法进行序列化或反序列化:
Serializable接口无具体方法,仅为标记作用,用来标识当前类可以被 ObjectOutputStream 序列化,以及被 ObjectInputStream 反序列化;
Externalizable接口与 Serializable 不同的是,默认情况下,它不会序列化任何成员变量,所有的序列化,反序列化工作都需要手动完成。
package serialize;
import java.io.Serializable;
public class Opration implements Serializable {
private final int a;
private final int b;
public Opration(int a, int b){
this.a = a;
this.b = b;
}
public void add(){
int sum = this.a + this.b;
System.out.print(this.a + "+" + this.b + "= " + sum);
}
}
2、进行序列化反序列化的类Sample。
package serialize;
import java.io.*;
import java.util.Arrays;
public class Sample {
/**
* 序列化的具体操作
* @param op 需序列化的对象
* @param path 接收序列化数据的文件位置
*/
public static void writeObjectTest(Object op, String path){
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream(); //字节流对象
FileOutputStream fos = new FileOutputStream(path); //文件流对象
//ObjectOutputStream的形参:序列化后的数据流形式,继承了OutputStream的子类,如字节组数类型ByteArrayOutputStream、文件FileOutputStream
//用文件接收序列化数据
ObjectOutputStream foos = new ObjectOutputStream(fos);
foos.writeObject(op);//序列化对象
foos.close();//关闭流
System.out.println("[+] 序列化数据已写入到文件: " + path);
//以字节流形式接收序列化后数据
ObjectOutputStream boos = new ObjectOutputStream(bos);
boos.writeObject(op);//序列化对象
boos.close();//关闭流
String str = Arrays.toString(bos.toByteArray());
System.out.println("[+] 以字节流形式接收序列化后数据: " + str);
//String str2 = bos.toString();
//System.out.println("[+] 直接打印序列化数据: " + str2);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 反序列化具体操作
* @param path 存有序列化数据的文件
*/
public static void readObjectTest(String path){
try {
//创建文件流读取序列化数据
FileInputStream fis = new FileInputStream(path);
//创建 ObjectInputStream 对象
ObjectInputStream ois = new ObjectInputStream(fis);
//反序列化
Opration op_reader = (Opration) ois.readObject();
//打印反序列化后的对象
System.out.print(op_reader);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String path = "../serTest.ser";
//待序列化的对象
Opration op = new Opration(2, 3);
//序列化
writeObjectTest(op, path);
//反序列化
//readObjectTest(path);
}
}
序列化的具体操作:
实例化Opration之后,用 ObjectOutputStream 进行序列化,其中 ObjectOutputStream 的形参为接收序列化数据的数据流形式,需要是继承了 OutputStream 的子类,如字节组数类型 ByteArrayOutputStream、文件 FileOutputStream 等;为了加深自己的理解,例子中字节流和文件流接收我都试了一遍。
输出:
[+] 序列化数据已写入到文件: serTest.ser
[+] 以字节流形式接收序列化后数据: [-84, -19, 0, 5, 115, 114, 0, 18, 115, 101, 114, 105, 97, 108, 105, 122, 101, 46, 79, 112, 114, 97, 116, 105, 111, 110, -46, -108, -47, -73, 106, -82, 105, -29, 2, 0, 2, 73, 0, 1, 97, 73, 0, 1, 98, 120, 112, 0, 0, 0, 2, 0, 0, 0, 3]
3、本来还有点疑惑 ByteArrayOutputStream 对象自己有个toString方法,为何还要转为字节数据后(bos.toByteArray())再转为字符串(Arrays.toString),打印了一下它自带的toString后被自己蠢到了;它自带的方法是直接输出 ACSII 字符的,但有些字符是不可打印的,因此以字节输出要方便点;虽然被自己蠢到了,还是记录一下吧。(>﹏<)
4、简单介绍一下SerialVersionUID。
SerialVersionUID:8 个字节长,相当于一个类对象的指纹信息,类似于 web 数据包中的签名,直接决定反序列化的成功与否;
之前看到有些文章说 IDE 会自动生成 SerialVersionUID (也可能是我看错了),于是试着手动编译了下未加 SerialVersionUID 的类,然后发现 SerialVersionUID 也会自动生成,遂记录一下
手动编译:
javac .\Opration.java;先编译依赖项
javac -cp .. -encoding UTF-8 Sample.java;在编译执行序列化的类文件,编译时需要注意路径,这里类文件中因为有package,查找文件时是classpath+package+xx.java,所以这里指定 classpath 到上一级目录,避免路径重复出现报错;
cd ..;也是因为package;
java serialize.Sample;有package时要写全限定类名,这也是为什么需要上一步的原因。
如果不显性指定 SerialVersionUID,JVM 会在序列化时根据属性自动生成一个 SerialVersionUID,其根据对象的信息以字节形式封装在一起,然后通过 SHA1 算法得到摘要,取前 8 位按 BigEndian 的字节顺序转换成长整型,得到的值即为最终的 SerialVersionUID;
但在实际开发中,由于代码可能需要重构,所以一般可能都会指定一个固定的 SerialVersionUID 值。
5、用SerializationDumper查看序列化数据;单词全大写的为常量,其值定义在 ObjectStreamConstants 中;
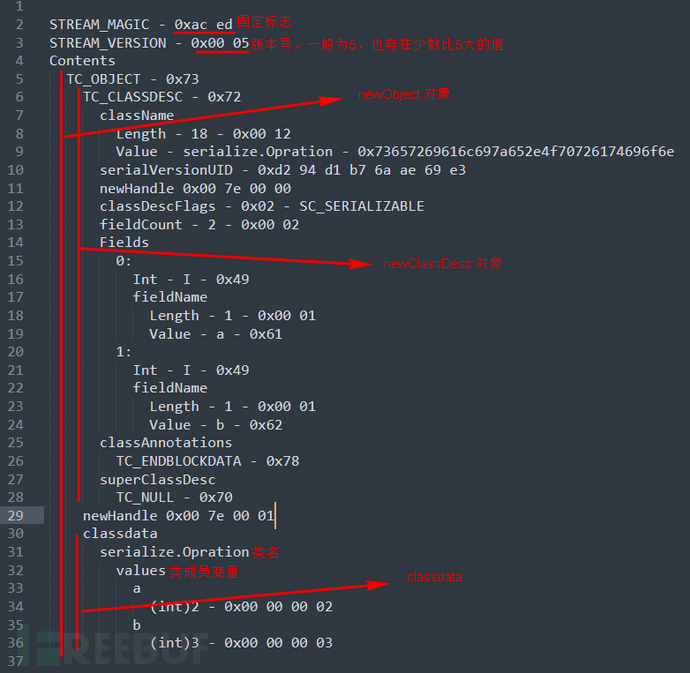
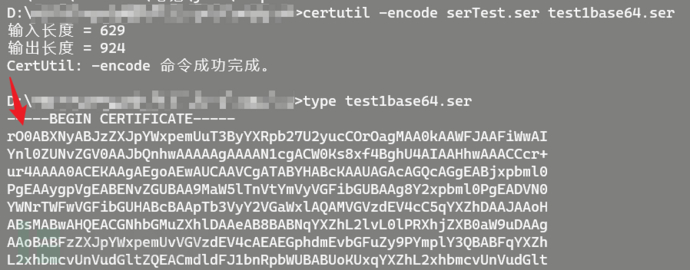
序列化流的特征一般为aced0005,其base64编码后的特征为rO0AB;
序列化数据的各部分组成这里写了个思维导图:
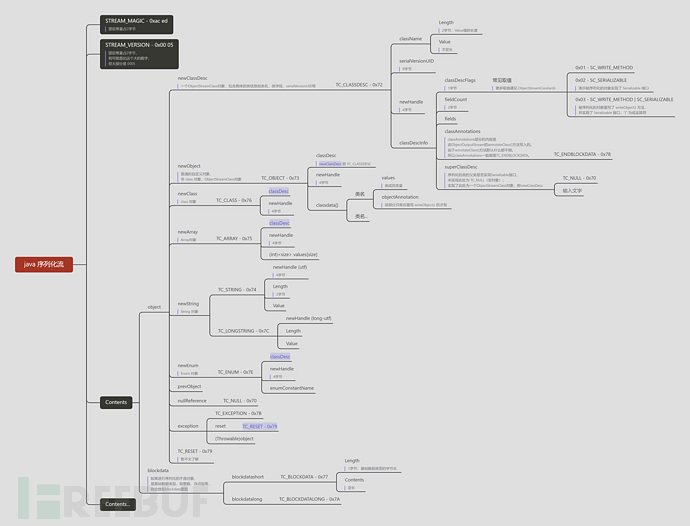
简单介绍下 Handle :句柄,占 4 个字节,序列化流中每个对象都会有个句柄值,当一个对象第一次出现在流中时,会用 newHandle 分配一个句柄值;如果前面出现过该对象,则会用 TC_REFERENCE 标记对象,并用 Handle 指向该对象第一次出现时分配的句柄值;
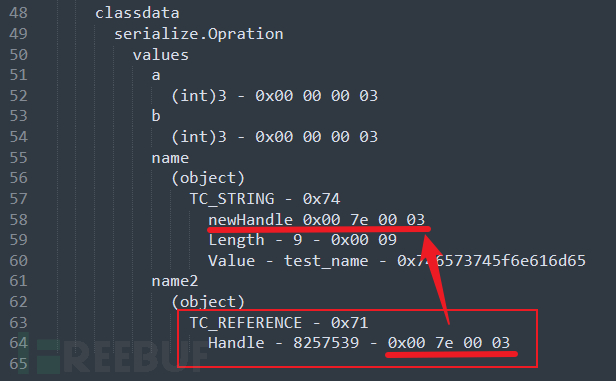
classAnnotations 部分的内容是由 ObjectOutputStream 的 annotateClass() 方法写入的。由于 annotateClass() 方法默认什么都不做。所以 classAnnotations 一般都是TC_ENDBLOCKDATA。
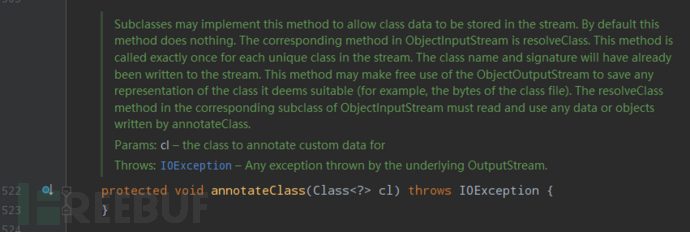
当重写了 writeObject() ,并往流中加了些自定义数据,这些数据在流中体现在哪里呢?
在 classdata -> 类名 -> objectAnnotation 下面

反序列化
简单演示下正常反序列化的情况:
取消反序列化方法调用的注释,然后运行,可以看到打印出的反序列化后的对象;
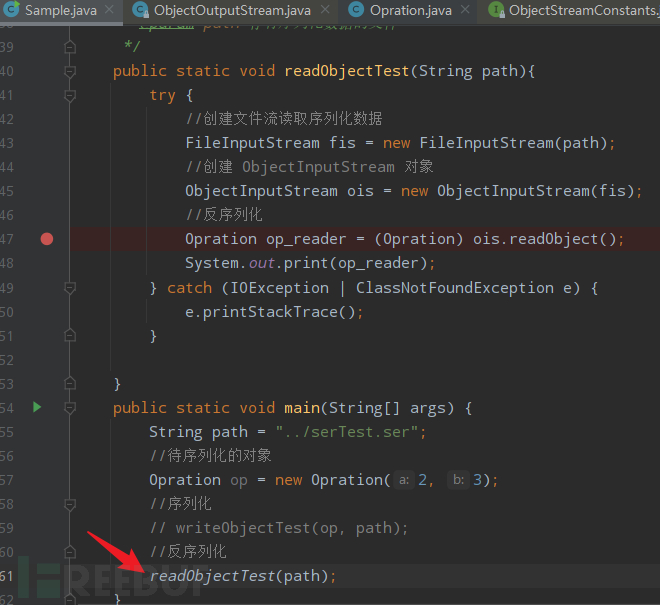

当待序列化对象重写了readObject方法,并执行了一些危险操作时,则可能导致反序列化漏洞。
模拟恶意反序列化
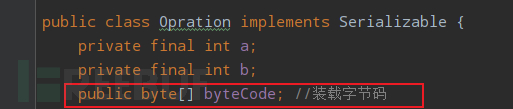
1、Opration中重写了readObject方法,并且存在可利用的危险操作;
这里以readObject方法中用 ClassLoader 的 defineClass 方法加载字节码为例,其中字节码由属性 byteCode 装载,而该属性可控;
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
ois.defaultReadObject();
try {
//用 ClassLoader 的 defineClass 方法加载字节码
Method defineMethod = ClassLoader.class.getDeclaredMethod("defineClass", String.class, byte[].class, int.class, int.class);
defineMethod.setAccessible(true);
//字节码由类属性 byteCode 提供;需要注意的是第二个参数是类名,不知道的情况填 null 也可以
Class exp = (Class) defineMethod.invoke(ClassLoader.getSystemClassLoader(), null, this.byteCode, 0, this.byteCode.length);
//上面加载完后 exp 类不会被初始化,需要手动初始化,触发恶意代码执行
exp.newInstance();
} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException | InstantiationException e) {
e.printStackTrace();
}
}
2、编写一个恶意类 TestExp,用 javac 命令编译成.class文件(javac TestExp.java);
package serialize;
import java.io.IOException;
public class TestExp {
static {
try {
Runtime.getRuntime().exec("calc.exe");
} catch (IOException e) {
e.printStackTrace();
}
}
public TestExp(){
}
}
3、在原来的序列化操作之前先给属性 byteCode 赋值,然后依次执行序列化、反序列化操作;
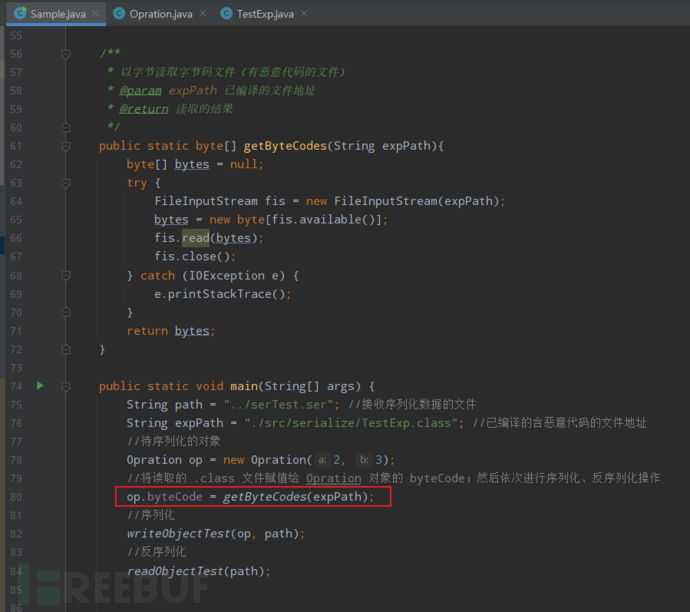
4、反序列化时带入的恶意字节码会被执行。
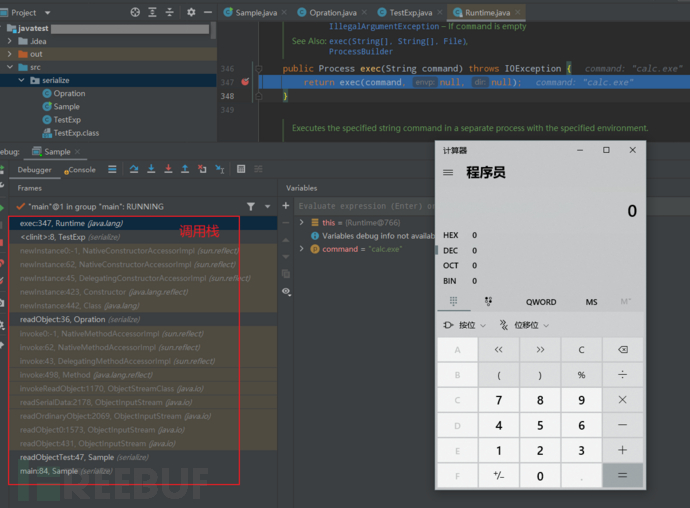
ObjectOutputStream
writeObject(Object obj)
权限修饰符
public
更像一个入口,对于序列化中更细节的实现交给了writeObject0完成。
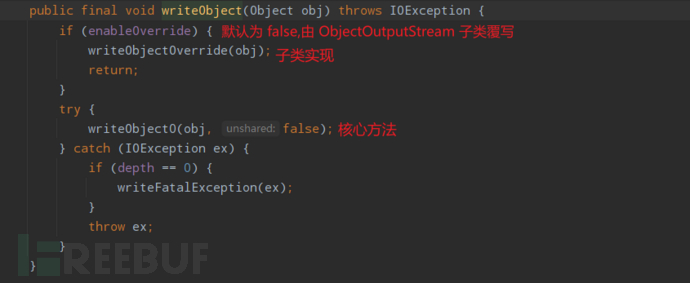
writeUnshared(Object obj)
权限修饰符
public
具体序列化操作同writeObject一样调用writeObject0,与writeObject不同的是其给writeObject0的第二个参数unshared赋值为true;
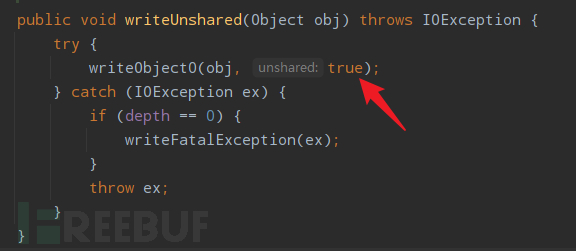
前面提到过,对于第二次写入流的对象会用 TC_REFERENCE 标记对象并用 Handle 指向第一次写入时的 Handle 值,这个的前提是使用默认方法(writeObject)进行序列化;
而writeUnshared的作用(也即unshared的作用)就是对于位于第一层进行序列化的对象第二次写入流时不会用 TC_REFERENCE 标记对象,而是会重新申请内存空间,将该对象再写入一遍。所以unshared值的含义可能就是相同对象第二次写入是否共享内存空间。
而这里为什么重点强调了一下是位于第一层呢,因为如果是一个对象A下面出现了两个同类型或同值的对象B、C,那B、C中后写入的那个对象依旧会用 TC_REFERENCE 标记,即该方法对子对象无效。
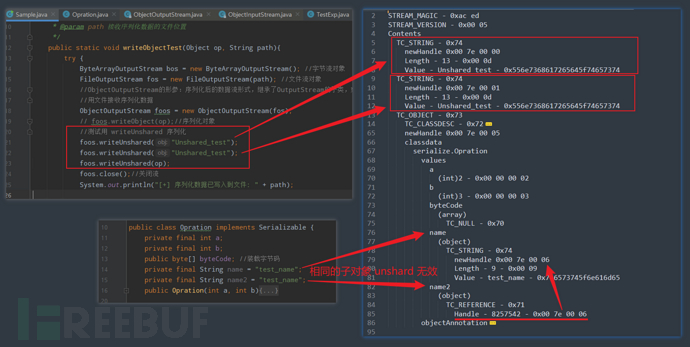
但暂时还不太了解该方法的应用场景。
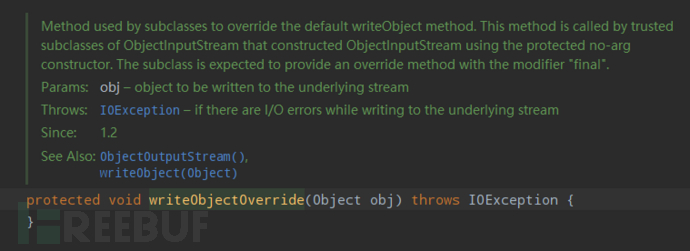
writeObjectOverride(Object obj)
权限修饰符
protected
一个空方法,如果 ObjectOutputStream 的子类需要根据业务需求进行自定义序列化时,便继承该方法并有具体实现,而且覆写 enableOverride 为 true。
writeObject0(Object obj, boolean unshared)
权限修饰符
private
将对象描述为序列化数据的具体实现,writeObject和writeUnshared最终都是通过调用该方法完成序列化;
可以根据其主要注释将其作为 4 个部分来看;
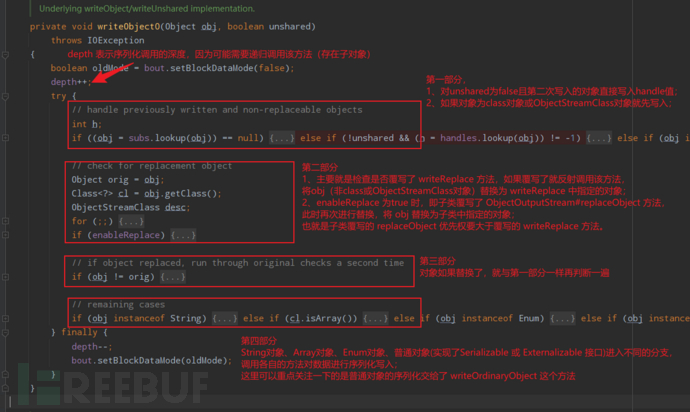
既然讲到了writeObject0,那就顺便来看一看标记了final的writeObject 和readObject重写后是怎么被调用执行的呢?(这里分析下writeObject ,readObject就不具体分析了,大致思路与writeObject 是一样的)


1、首先重写writeObject 的位置肯定是在需要序列化的类中,即普通对象中,因此序列化的时候在writeObject0中最终会进入第四部分的普通对象分支下,由writeOrdinaryObject进行普通对象的序列化写入操作;
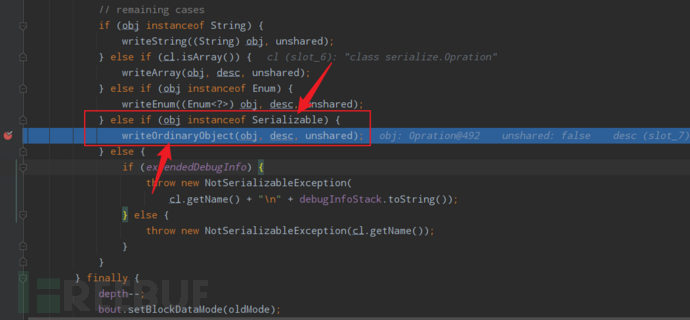
2、进入writeOrdinaryObject,可以看到其向流中写入了普通对象的标志,以及包含类的基本信息的 desc 对象后,又委托给了writeSerialData来继续完成序列化操作;
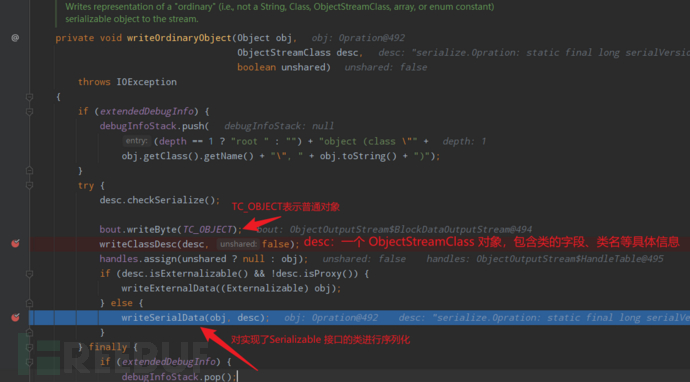
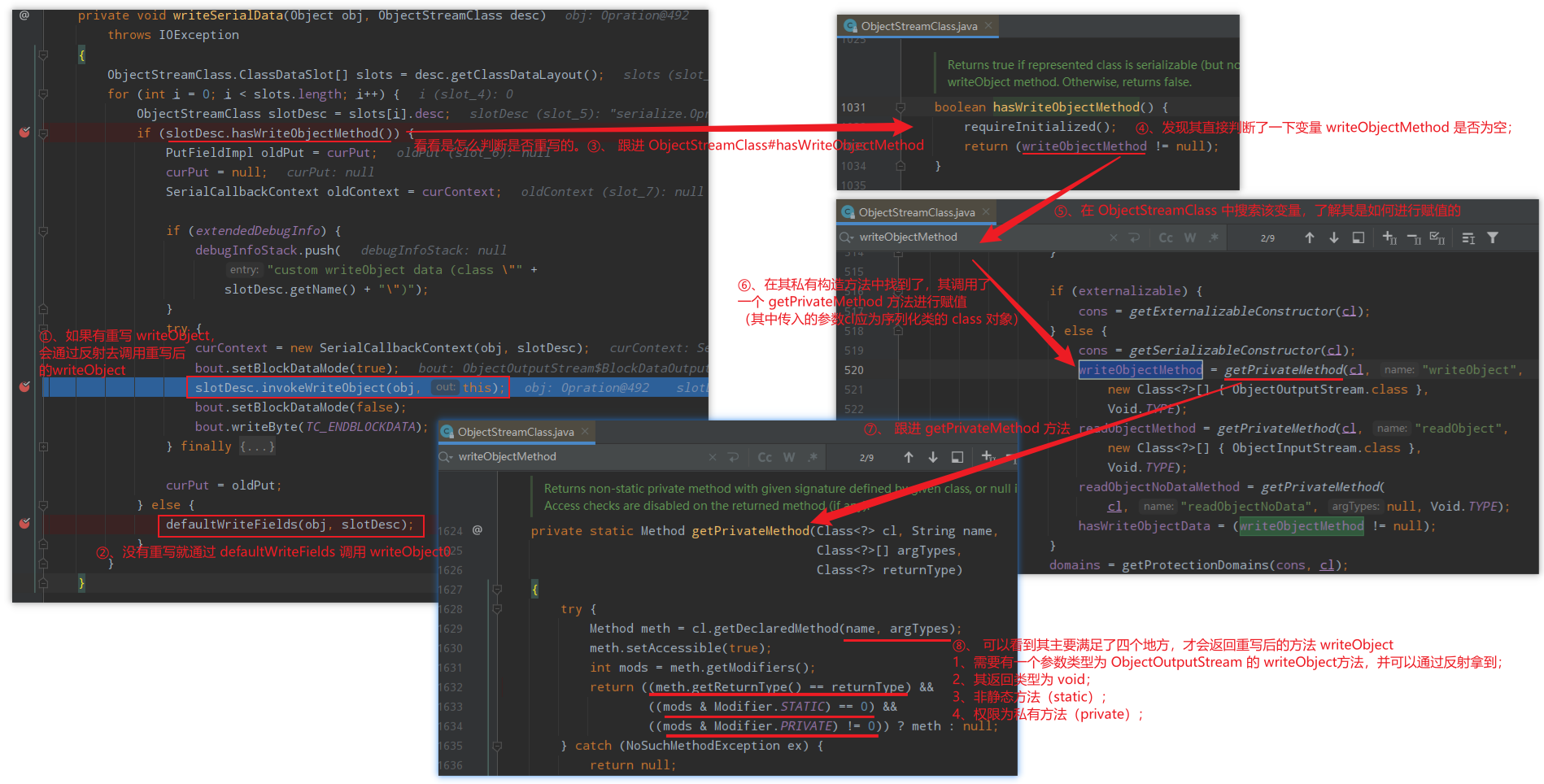
3、进入writeSerialData(后面这一段文字图片里也有,直接看图也行):
里面有个判断是否重写了 writeObject ,如果有重写就进入 if,最后通过反射去调用重写后的 writeObject,没有重写就通过 defaultWriteFields 调用 writeObject0;
跟进 ObjectStreamClass#hasWriteObjectMethod 去看看它是怎么判断是否重写 writeObject 的,发现其直接判断了一下变量 writeObjectMethod 是否为空;
在 ObjectStreamClass 中搜索该变量,了解其是如何进行赋值的,在其私有构造方法中找到了,它调用了一个 getPrivateMethod 方法进行赋值(其中传入的参数 cl 应为序列化类的 class 对象);
跟进 getPrivateMethod 方法,可以看到其主要满足了四个地方,才会返回重写后的 writeObject 方法 :
需要有一个参数类型为 ObjectOutputStream 的 writeObject方法,可以通过反射拿到
其返回类型为 void
非静态方法(static)
权限为私有方法(private)
4、小结
回到刚才的问题
标记了
final的writeObject和readObject重写后是怎么被调用执行的呢?
现在答案出来了:如果按照要求重写了writeObject ,最终会通过反射调用到重写后的writeObject ,否则就通过defaultWriteFields调用默认的writeObject0。
反射调用到重写的writeObject 的调用链:
writeObject -> writeObject0 -> writeOrdinaryObject -> writeSerialData -> ObjectStreamClass#invokeWriteObject
readObject的调用链与writeObject 差不多,一个是写一个是读:
readObject -> readObject0 -> readOrdinaryObject -> readSerialData-> ObjectStreamClass#invokeReadObject
writeReplace
有点像个隐藏方法,其作用就是替换序列化的对象为其指定的对象后进行序列化;
分析writeObject0的时候提到过第二部分会判断是否重写了writeReplace,如果重写就反射调用重写后的writeReplace将要序列化的对象替换为writeReplace指定的对象;
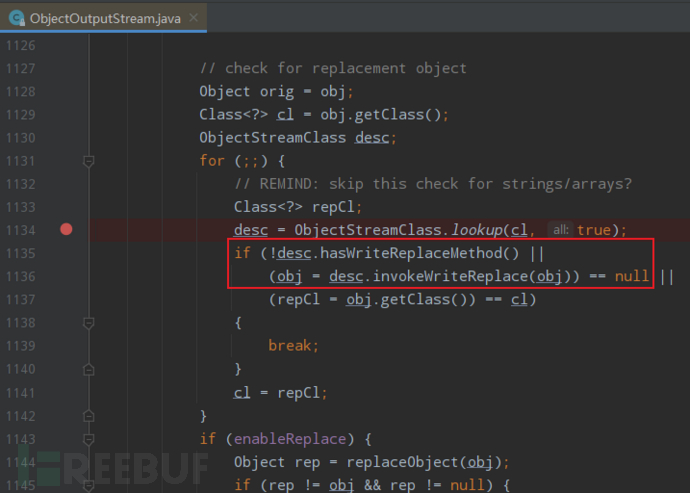
看到这个是不是感觉与调用重写后 writeObject 有点类似?也的确差不多,跟进
hasWriteReplaceMethod 之后可以看到它也是有一个这个变量 writeReplaceMethod;
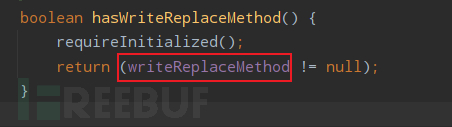
搜索后发现其赋值也是在 ObjectStreamClass 的私有构造方法内,可以注意到 writeObject 与 readObject 相对,writeReplace 与 readResolve 相对;这里先跟进一下 getInheritableMethod 看看重写 writeReplace 需要什么条件;
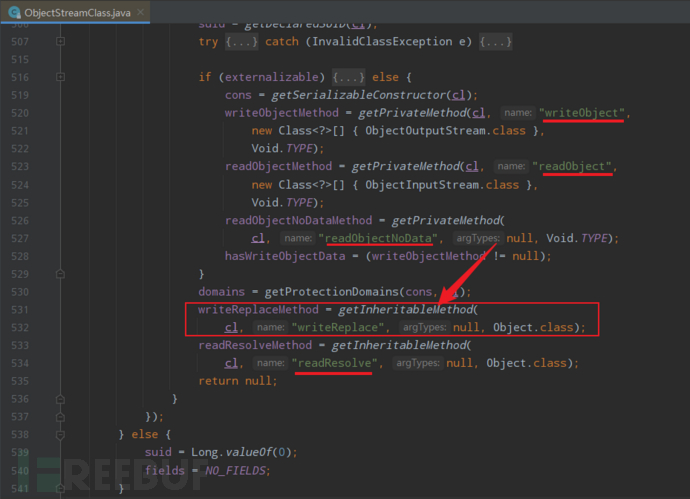
跟进后,可以发现重写 writeReplace 的条件如下:
无参;
返回类型为 Object;
非静态方法或抽象方法;
权限修饰符无限制,private/public/protected 都可。
ObjectInputStream
ObjectInputStream 与 ObjectOutputStream 的实现过程几乎是对称的,一个按照规则去读数据流,一个按照规则去写入流,因此这里对 ObjectInputStream 的相关方法就不多赘述了。
readObject <-> writeObject
readUnshared <-> writeUnshared
readObject0 <-> writeObject0
readObjectOverride <-> writeObjectOverride
readResolve <-> writeReplace (不过需要注意的是 writeReplace 与 readResolve 一般不会一起用,一起用的话 writeReplace 会失效;另还可以通过重写 readResolve 来校验进行反序列化的类)
总结
对本文的一个小结:
对序列化反序列化进行示例演示;
对序列化数据的结构组成进行了简单的学习,并写了一张思维导图;
简单模拟了一次反序列化漏洞的利用;
简单介绍了 ObjectOutputStream 中常用的几个方法(ObjectInputStream 文中未多赘述,其实现与 ObjectOutputStream 大致对称);
简单分析了下是怎么调用到重写后的 writeObject 方法的(readObject 的调用过程也差不多);
待做,下一步学习计划:
cc 链分析;
进一步了解其他反序列化触发点:
| 反序列化类型 | 一些反序列化触发点 | 所在组件 | 学习否 |
|---|---|---|---|
| jdk内置 | ObjectInputStream.readObject | jdk内置 - java.io.ObjectInputStream | √ |
| ObjectInputStream.readUnshared | jdk内置 - java.io.ObjectInputStream | √ | |
| xml | XMLDecoder.readObject | jdk内置 - java.beans.XMLDecoder | - |
| XStream.fromXML | com.thoughtworks.xstream | - | |
| yaml | Yaml.load | org.yaml.snakeyaml.Yaml | - |
| json | ObjectMapper.readValue | jackson - com.fasterxml.jackson.databind.ObjectMapper | - |
| JSON.parseObject | fastJson - com.alibaba.fastjson.JSONObject | - |
参考
https://www.cnblogs.com/piaomiaohongchen/p/16447244.html
https://su18.org/post/ysoserial-su18-1/
https://zone.huoxian.cn/d/1150-java
http://www.hollischuang.com/archives/1140
https://xz.aliyun.com/t/4761
https://paper.seebug.org/1133/
https://paper.seebug.org/792/
https://xz.aliyun.com/t/2041
https://juejin.cn/post/6895434705915609101
https://juejin.cn/post/6854573214077550600
https://juejin.cn/post/6844903765921808397
https://xz.aliyun.com/t/8686
https://docs.oracle.com/javase/8/docs/platform/serialization/spec/protocol.html
https://z.itpub.net/article/detail/0C1A0D0554C079E0D882253855CBB0B9
https://nowjava.com/docs/java-api-11/java.base/java/io/ObjectOutputStream.html
https://www.cnblogs.com/binarylei/p/10987933.html
已在FreeBuf发表 0 篇文章
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf 客服小蜜蜂(微信:freebee1024)
- 0 文章数
- 0 关注者