


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
网络空间搜索引擎是什么?
网络空间搜索引擎是为了解决个人每次进行渗透测试是都要进行的信息收集过程,通过全网扫描的方式,将基础数据进行格式化存储,供安全人员按需搜索使用,提升了安全人员的工作效率。
常用的网络空间搜索引擎:fofa、shodan、zoomeye、censys
常见网络空间搜索引擎介绍
网络空间搜索引擎有哪些
目前国内外的网络空间搜索引擎有 shodan、zoomeye、cnesys、fofa,下面一一介绍。
shodan
Shodan 是目前最为知名的黑客搜索引擎,它是由计算机程序员约翰·马瑟利(John Matherly)于 2009 年推出的,他在 2003 年就提出了搜索与 Internet 链接的设备的想法。发展至今已经变成搜索资源最全,搜索性能最强,TOP1 级别的网络资产搜索引擎。
地址:
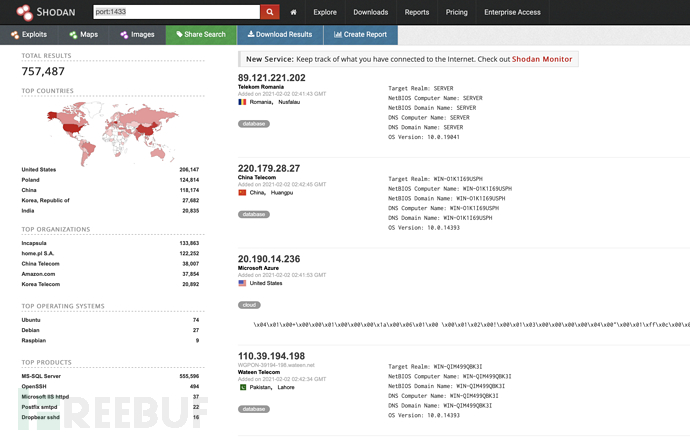
简单语法:
hostname: # 搜索指定的主机或域名,例如 hostname:"google"
port: # 搜索指定的端口或服务,例如 port:"21"
country: # 搜索指定的国家,例如 country:"CN"
city: # 搜索指定的城市,例如 city:"Hefei"
org: # 搜索指定的组织或公司,例如 org:"google"
isp: # 搜索指定的ISP供应商,例如 isp:"China Telecom"
product: # 搜索指定的操作系统/软件/平台,例如 product:"Apache httpd"
version: # 搜索指定的软件版本,例如 version:"1.6.2"
geo: # 搜索指定的地理位置,参数为经纬度,例如 geo:"31.8639, 117.2808"
before/after: # 搜索指定收录时间前后的数据,格式为dd-mm-yy,例如 before:"11-11-15"
net: # 搜索指定的IP地址或子网,例如 net:"210.45.240.0/24"a
zoomeye
ZoomEye 是北京知道创宇公司发布的网络空间侦测引擎,积累了丰富的网络扫描与组件识别经验。在此网络空间侦测引擎的基础上,结合“知道创宇”漏洞发现检测技术和大数据情报分析能力,研制出网络空间雷达系统,为政府、企事业及军工单位客户建设全球网络空间测绘提供技术支持及产品支撑。
ZoomEye 支持公网设备指纹检索和 Web 指纹检索。网站指纹包括应用名、版本、前端框架、后端框架、服务端语言、服务器操作系统、网站容器、内容管理系统和数据库等。设备指纹包括应用名、版本、开放端口、操作系统、服务名、地理位置等。
地址:
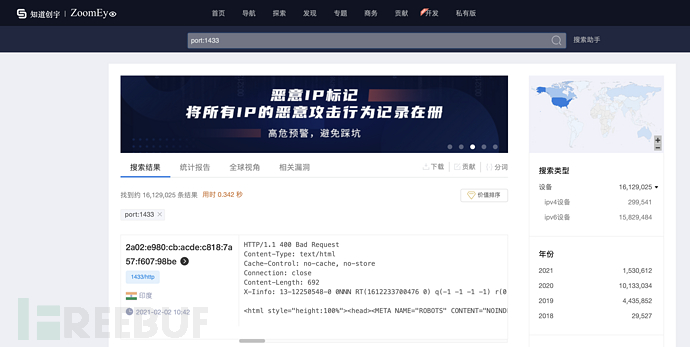
简单语法:
app:nginx # 组件名
ver:1.0 # 版本
os:windows # 操作系统
country:"China" # 国家
city:"hangzhou" # 城市
port:80 # 端口
hostname:google # 主机名
site:google.com # 网站域名
desc:nmask # 描述
keywords:passwd # 关键词
service:ftp # 服务类型
ip:8.8.8.8 # ip地址
cidr:8.8.8.8/24 # ip地址段
censys
Censys 是由密歇根大学的计算机科学家创立,帮助信息安全从业人员发现、监控和分析从互联网访问的设备的平台,Censys 能够扫描整个互联网,每天扫描 IPv4 地址空间,以搜索所有联网设备并收集相关的信息,并返回一份有关资源(如设备、网站和证书)配置和部署信息的总体报告。
地址:
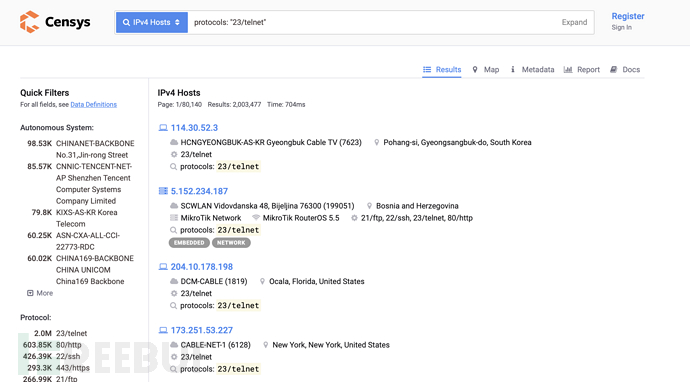
简单语法:
23.0.0.0/8 or 8.8.8.0/24 # 可以使用and or not
80.http.get.status_code: 200 # 指定状态
80.http.get.status_code:[200 TO 300] # 200-300之间的状态码
location.country_code: DE # 国家
protocols: ("23/telnet" or "21/ftp") # 协议
tags: scada # 标签
80.http.get.headers.server:nginx # 服务器类型版本
autonomous_system.description: University # 系统描述
fofa
FOFA 是白帽汇推出的一款网络空间搜索引擎,它通过进行网络空间测绘,能够帮助研究人员或者企业迅速进行网络资产匹配,例如进行漏洞影响范围分析、应用分布统计、应用流行度排名统计等。
地址:
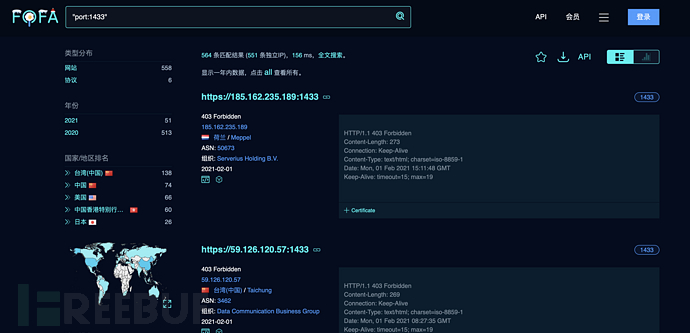
简单语法:
title="abc" # 从标题中搜索abc。例:标题中有北京的网站。
header="abc" # 从http头中搜索abc。例:jboss服务器。
body="abc" # 从html正文中搜索abc。例:正文包含Hacked by。
domain="qq.com" # 搜索根域名带有qq.com的网站。例: 根域名是qq.com的网站。
host=".gov.cn" # 从url中搜索.gov.cn,注意搜索要用host作为名称。
port="443" # 查找对应443端口的资产。例: 查找对应443端口的资产。
ip="1.1.1.1" # 从ip中搜索包含1.1.1.1的网站,注意搜索要用ip作为名称。
protocol="https" # 搜索制定协议类型(在开启端口扫描的情况下有效)。例: 查询https协议资产。
city="Beijing" # 搜索指定城市的资产。例: 搜索指定城市的资产。
region="Zhejiang" # 搜索指定行政区的资产。例: 搜索指定行政区的资产。
country="CN" # 搜索指定国家(编码)的资产。例: 搜索指定国家(编码)的资产。
cert="google.com" # 搜索证书(https或者imaps等)中带有google.com的资产。
小总结
每个平台都有自己的特点和优势,我们可以使用多个平台来补充自己的结果,让搜索的信息更全。
玩转fofa
接下来选择一个搜索引擎进行深入学习,我毅然决然的选择了fofa,为什么呢?因为对它最熟悉也最有感情(因为我冲了会员QAQ)
fofa中常用语法学习
逻辑运算符
●&& :表示逻辑与
●|| :表示逻辑或
用例:
#查找使用coremail并且在中国境内的网站
app="Coremail" && country=CN
#查找title中含有管理后台或者登录后台的网站
title="管理后台" || title="登录后台"
查找使用指定应用的IP
app=”“
用例:
#查找使用Coremail的网站
app="Coremail"
#查找使用Weblogic的网站
app="BEA-WebLogic-Server"
查找使用指定协议的ip
protocol=
#查找使用mssql的ip
protocol=mssql
#查找使用oracle的ip
protocol=oracle
#查找使用redis的ip
protocol=redis
查找开放特定端口的ip
port=”“
#查找开放了1433,3306,3389端口的主机
ports="1433,3306,3389"
#查找只开放了1433,3306,3389端口的主机
ports=="1433,3306,3389"
查找IP或网段的信息
#查找指定ip的信息
ip="220.181.38.148"
#查找指定网段的信息
ip="220.181.38.0/24"
找使用指定css或js的网站
有时候,我们碰到一个使用框架的网站,现在我们想找到所有使用该框架的网站。可以查看源代码,找到这个框架特有的css或js文件,然后将该css或js的路径复制粘贴到 Fofa进行查找。
利用fofa挖掘漏洞的骚操作
⾸先可以利⽤FOFA进⾏漏洞挖掘和安全研究。对于⽩帽⼦挖掘漏洞来讲,信息收集是第⼀步,也是很 重要的⼀步。⽐如挖SRC的时候要进⾏⼦域名收集,绕过cdn查找真实IP等。
找Burpsuite代理
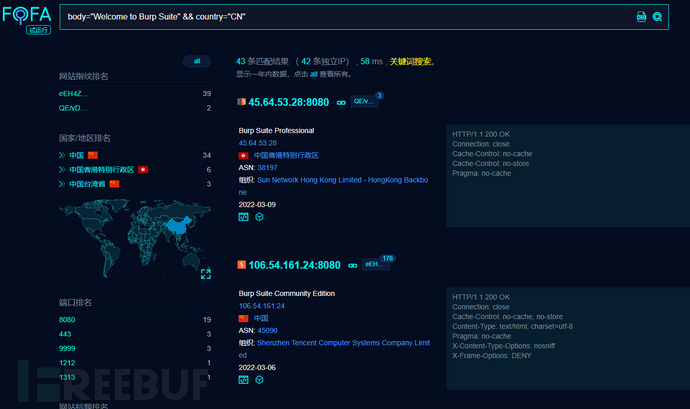
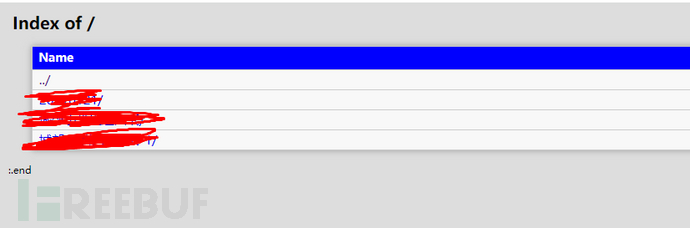
找⽬录遍历漏洞
根据⽬录遍历关键词搜索,可以查到大量的结果。当然这还是在fofa经风波后被阉割的结果,全盛时期数据量更恐怖
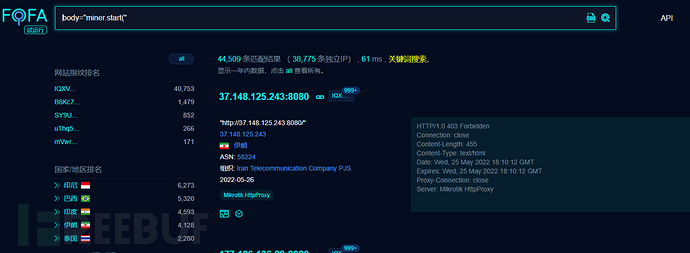
查找被黑网站
黑网站变现的有效途径之一就是js挖矿,我们可以查找挖矿脚本的特征来搜索被黑网站
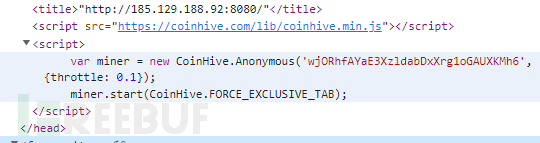
也可以利用黑页的特征查被黑网站,例如查找“HackedBy”,能出一大坨大黑阔入侵完毕后挂的黑页。
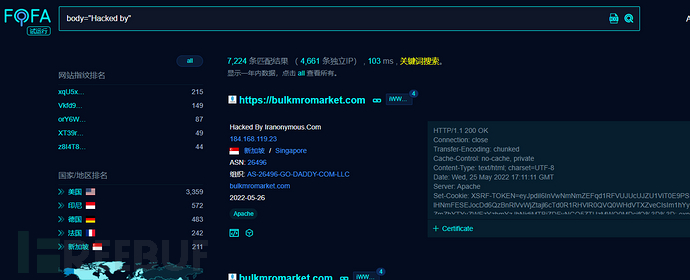
当然 还有一些很骚的操作,但都涉及违法违规,这里不再学习,一定要保持自身的洁身自好~
从fofa到shodan|网络空间引擎是如何获取数据的
shodan的工作原理
shodan通过爬虫从世界各地收集数据,n采集的基本数据单位是b a n n e r。b a n n e r是描述设备所运行服务的标志性文
本信息。对于W e b服务器来说,其将返回标题或者是t e l n e t登陆界面。B a n n e r的内
容因服务类型的不同而相异。
以下这是一个典型的H T T P B a n n e r:
H T T P / 1 . 1 2 0 0 O K
S e r v e r : n g i n x / 1 . 1 . 1 9
D a t e : S a t , 0 3 O c t 2 0 1 5 0 6 : 0 9 : 2 4 G M T
C o n t e n t •T y p e : t e x t / h t m l ;
c h a r s e t = u t f •8
C o n t e n t •L e n g t h : 6 4 6 6
C o n n e c t i o n : k e e p •a l i v e
#上面的b a n n e r显示该设备正在运行一个1.1.19版本的n g i n x W e b服务器软件
除了获取b a n n e r,S h o d a n还可以获取相关设备的元数据,例如地理位置、主机
名、操作系统等信息。大部分元数据可以通过S h o d a n的官网获取,小部分的可以通
过使用A P I编程获取。
如下是shodan获取数据的流程图: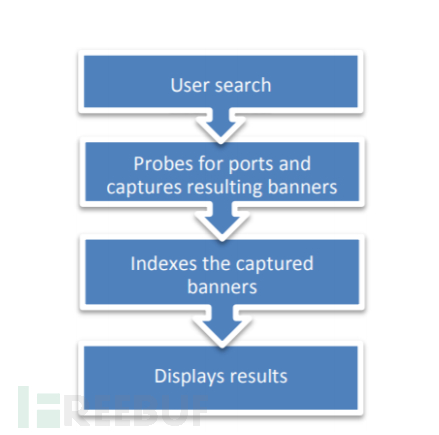
fofa的工作原理
fofa的收录是基于端口扫描的收录,底层原理就类似一个扫全网的zmap加上各种指纹识别的脚本和规则来维护的,基于:IP、端口、指纹、部分域名子域名的关系数据库。
什么样的东西可以被fofa收录
| 例子 | 是否会被收录 | 解释 |
|---|---|---|
| 111.111.111.111:80 | 是 | IP、端口两要素 |
| 111.111.111.111:80/test/test.html | 否 | 仅会收录根目录返回结果,二级目录不会收录,fofa不会进行目录扫描 |
| http://baidu.com:80 | 可能 | 某些特定情况下,可能会扫到baidu.com对应的IP,并且该IP未作针对性防护 |
| http://baidu.com:80/test/test.html | 可能(概率很小) | 唯一一种可能的情况就是/test/目录单独解析到某个IP,或服务由某个IP节点提供 |
上面列举了一些可能被收录的和不会被收录的资产,fofa搜索开始之前就应该了解,自己搜索什么可以搜到东西,而搜索什么不可能找到东西。
原理应用:Title & Header & Body 与 Html search
Title顾名思义就是网站的标题,相应的,header,body对应网站的头部,主体。
假如在渗透测试时我们想搜集某一主体相关的资产,我们可能匹配的是Title & Header & Body 存在主体的名称,如:
title="XX市XX医院"
这一条可以匹配的是标题中含有“XX市XX医”的资产,标题为"XX医院"的某些资产也可能是XX市XX医院的资产,我们就无法获取这部分资产信息。这时我们如何才能最大化的匹配到相关资产呢
title="XX市" && title="XX医院"
这条规则比上面 的规则可以匹配到更多的资产,但是会搜索到目标之外的结果,例如”XX市XX医院与AA医院合作系统“。所以搜索的时候拆分title来搜索可以获得更多的搜索结果和更大的搜索范围,但是可能会带来脏数据。body,header同理。
当我们分别查找title、header、body的关键字的时候总觉得太麻烦,能不能直接搜索一次就包含所有的搜索结果呢?答案是肯定的。
这就需要我们认识html参数。我们来看一下html包含什么
<html>
<head>
<title>首页 - XX管理系统</title>
</head>
<body>
<p>body welcome to my web</p>
<p>user:</p>
<p>pass:</p>
</body>
<footer>版权信息:XX市XX医院<footer>
</html>
上面的代码可以看到,footer里面包含我们的目标关键字,但是fofa中并没有专门搜索footer的语法,那么我们怎么把这个结果搜索到呢? 如下代码就可以了:
"XX市XX医院"
看一眼这个语法,应该不用解释了,过滤掉容易出现辣鸡网站的地区==只要中国的结果==,其中==容易出现辣鸡数据的HK==也进行过滤,会清爽很多。
原理应用:通过api接口的特殊姿势进行资产搜集
有时同一主体的全部资产,会调用有些API接口,直接访问这些api接口会报错:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>MiniGo API</title>
<style type="text/css">
html, body {font-size: 1em; font-family: Arial, Helvetica, sans-serif; padding: 0;margin: 0;}
a, a:hover, a:visited {color: blue;}
ul li {font-size: 14px;}
code {font-size: 14px; font-family: Helvetica, Arial, sans-serif; color:blue; margin: 0 5px; }
div.header { height: 30px; line-height: 30px; background: #159C94;color:white; font-weight: bold; padding:0 0 0 48px;}
div.header img.logo {position: absolute; left: 10px; top: 3px;}
div.header img.hisense {position: absolute; right: 10px; top: 6px;}
div.body {padding: 10px;}
div.alert {vertical-align:middle; border:2px solid red;background: yellow url('/img/alert.png') no-repeat 0 4px; padding: 12px 12px 12px 72px;color:red;min-height: 36px;}
div.alert p {margin: 0;}
div.footer {position: absolute; height: 60px; bottom: 0;left: 0;}
</style>
</head>
<body>
<div class="header"><img class="logo" src="/img/logo.png" width="24" height="24" /> MINIGO 微信小程序<img class="hisense" src="/img/hisense.png"/></div>
<div class="body">
欢迎使用XX WebAPI中间服务,当前版本为V2.0.1.5
</div>
<div class="footer"></div>
</body>
</html>
以上这种情况,我反手就是一个:
"欢迎使用XX WebAPI中间服务,当前版本为V2.0.1.5"
"欢迎使用XX WebAPI中间服务"
通过这种方式,我们能够获取相关主体的:
1. IP资产
2. 关联相关IP段
3. 端口扫描
原理应用:通过证书获取资产
我们肯定都见过这样的页面
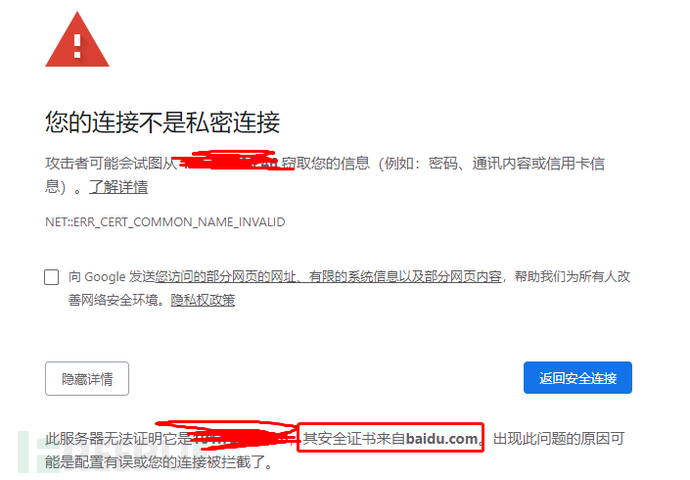
可以看到证书来自baidu.com了吧,百度的资产是不是要使用百度证书?我们就可以这样搜索
cert="baidu.com"
通过以上结果可以得出不光【baidu.com】,属于百度的好多域名都知道了
原理应用:资产搜集CDN绕过
1.通过证书查询方式
cert="baidu.com"
这个可以绕过一部分SSL网站的CDN直接看到真实IP
1.通过某些主页特殊关键字
"百度一下 你就知道"
某些网站没有对IP直接访问做限制,可以直接访问
1.某些特殊接口
比如你访问某个接口给你返回一个
"baidu OK!"
后记
今天我们由浅入深的了解一下关于网络空间搜索引擎的使用方法,搜索原理,收获颇丰,学会了使用网络空间搜索引擎来进行信息搜集服务于我们的渗透测试工作
参考文章
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者